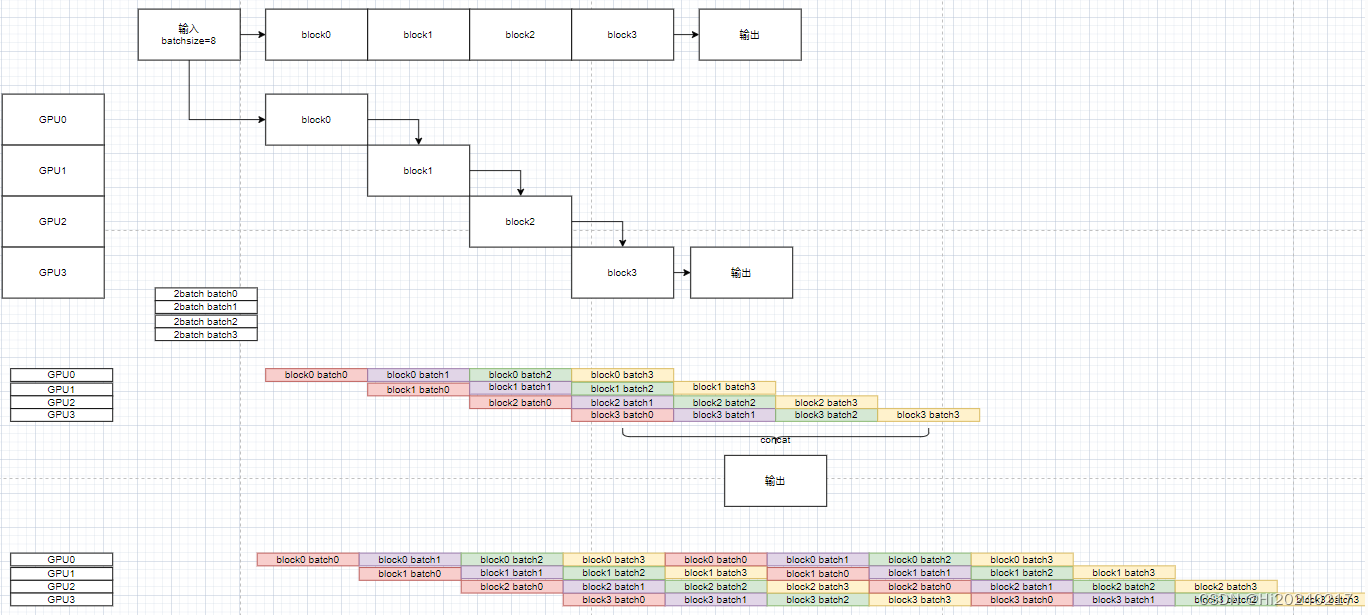
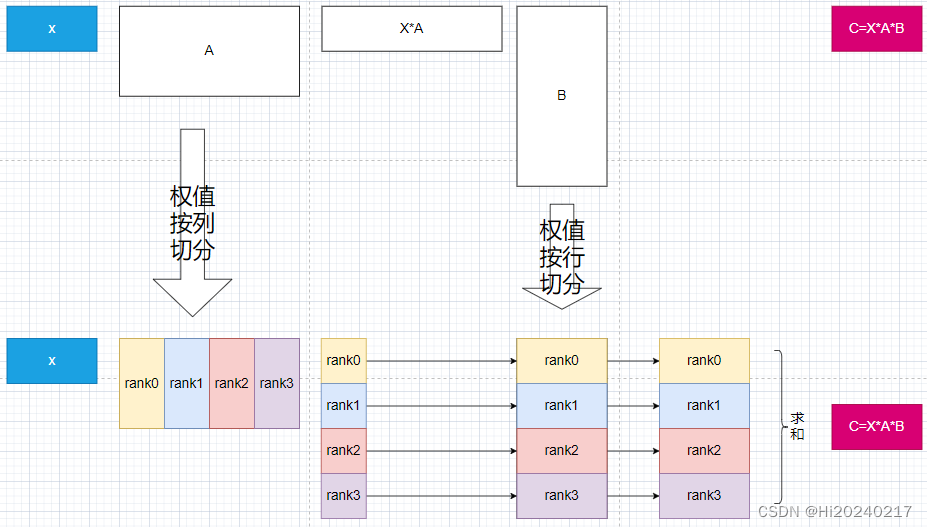
本文演示了tensor并行的原理。如何将二个mlp切分到多张GPU上分别计算自己的分块,最后做一次reduce。
1.为了避免中间数据产生集合通信,A矩阵只能按列切分,算出全部batch*seqlen的部分feature
2.因上面的步骤每张GPU只有部分feature,B矩阵可按行切分,与之进行矩阵乘,生成部分和
3.最后累加每张GPU上的部分和,即最终的结果
以下demo,先运行非分块的版本,然后模拟分块,最后是分布式的实现
一.原理
二.实现代码
# torch_tp_demo.py
import os
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
import torch.distributed as dist
from torch.distributed import ReduceOp
import time
import argparse
parser = argparse.ArgumentParser(description="")
parser.add_argument('--hidden_size', default=512, type=int, help='')
parser.add_argument('--ffn_size', default=1024, type=int, help='')
parser.add_argument('--seq_len', default=512, type=int, help='')
parser.add_argument('--batch_size', default=8, type=int, help='')
parser.add_argument('--world_size', default=4, type=int, help='')
parser.add_argument('--device', default="cuda", type=str, help='')
class FeedForward(nn.Module):
def __init__(self,hidden_size,ffn_size):
super(FeedForward, self).__init__()
self.fc1 = nn.Linear(hidden_size, ffn_size,bias=False)
self.fc2 = nn.Linear(ffn_size, hidden_size,bias=False)
def forward(self, input):
return self.fc2(self.fc1(input))
class FeedForwardTp(nn.Module):
def __init__(self,hidden_size,ffn_size,tp_size,rank):
super(FeedForwardTp, self).__init__()
self.fc1 = nn.Linear(hidden_size, ffn_size//tp_size,bias=False)
self.fc2 = nn.Linear(ffn_size//tp_size, hidden_size,bias=False)
self.fc1.weight.data=torch.from_numpy(np.fromfile(f"fc1_{rank}.bin",dtype=np.float32)).reshape(self.fc1.weight.data.shape)
self.fc2.weight.data=torch.from_numpy(np.fromfile(f"fc2_{rank}.bin",dtype=np.float32)).reshape(self.fc2.weight.data.shape)
def forward(self, input):
return self.fc2(self.fc1(input))
args = parser.parse_args()
hidden_size = args.hidden_size
ffn_size = args.ffn_size
seq_len = args.seq_len
batch_size = args.batch_size
world_size = args.world_size
device = args.device
def native_mode():
print(args)
torch.random.manual_seed(1)
model = FeedForward(hidden_size,ffn_size)
model.eval()
input = torch.rand((batch_size, seq_len, hidden_size),dtype=torch.float32).half().to(device)
for idx,chunk in enumerate(torch.split(model.fc1.weight, ffn_size//world_size, dim=0)):
chunk.data.numpy().tofile(f"fc1_{idx}.bin")
for idx,chunk in enumerate(torch.split(model.fc2.weight, ffn_size//world_size, dim=1)):
chunk.data.numpy().tofile(f"fc2_{idx}.bin")
model=model.half().to(device)
usetime=[]
for i in range(32):
t0=time.time()
out = model(input)
torch.cuda.synchronize()
t1=time.time()
if i>3:
usetime.append(t1-t0)
print("[INFO] native: shape:{},sum:{:.5f},mean:{:.5f},min:{:.5f},max:{:.5f}".format(out.shape,out.sum().item(),np.mean(usetime),np.min(usetime),np.max(usetime)))
result=[]
for rank in range(world_size):
model = FeedForwardTp(hidden_size,ffn_size,world_size,rank).half().to(device)
model.eval()
out=model(input)
torch.cuda.synchronize()
result.append(out)
sum_all=result[0]
for t in result[1:]:
sum_all=sum_all+t
print("[INFO] tp_simulate: shape:{},sum:{:.5f}".format(sum_all.shape,sum_all.sum().item()))
def tp_mode():
torch.random.manual_seed(1)
dist.init_process_group(backend='nccl')
world_size = torch.distributed.get_world_size()
rank=rank = torch.distributed.get_rank()
local_rank=int(os.environ['LOCAL_RANK'])
torch.cuda.set_device(local_rank)
device = torch.device("cuda",local_rank)
input = torch.rand((batch_size, seq_len, hidden_size),dtype=torch.float32).half().to(device)
model = FeedForwardTp(hidden_size,ffn_size,world_size,rank).half().to(device)
model.eval()
if rank==0:
print(args)
usetime=[]
for i in range(32):
dist.barrier()
t0=time.time()
out=model(input)
#dist.reduce(out,0, op=ReduceOp.SUM)
dist.all_reduce(out,op=ReduceOp.SUM)
torch.cuda.synchronize()
if rank==0:
t1=time.time()
if i>3:
usetime.append(t1-t0)
if rank==0:
print("[INFO] tp: shape:{},sum:{:.5f},mean:{:.5f},min:{:.5f},max:{:.5f}".format(out.shape,out.sum().item(),np.mean(usetime),np.min(usetime),np.max(usetime)))
if __name__ == "__main__":
num_gpus = int(os.environ["WORLD_SIZE"]) if "WORLD_SIZE" in os.environ else 1
is_distributed = num_gpus > 1
if is_distributed:
tp_mode()
else:
native_mode()
运行命令:
python3 torch_tp_demo.py --hidden_size 512 \
--ffn_size 4096 --seq_len 512 \
--batch_size 8 --world_size 4 --device "cuda"
torchrun -m --nnodes=1 --nproc_per_node=4 \
torch_tp_demo --hidden_size 512 \
--ffn_size 4096 --seq_len 512 \
--batch_size 8 --world_size 4