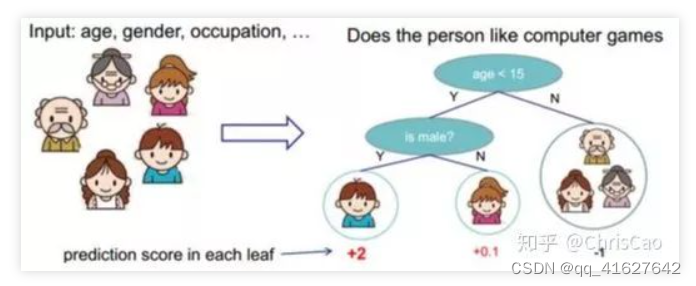
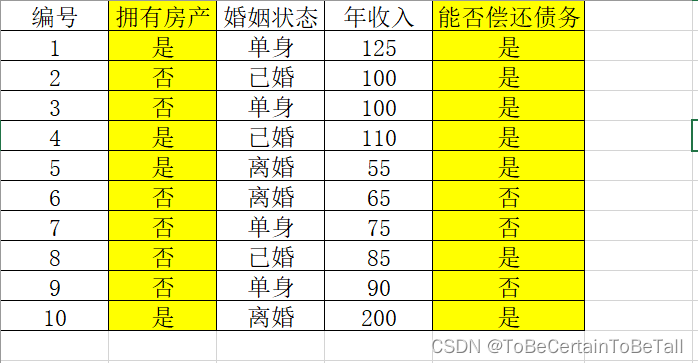
决策树分类算法是一种常用的机器学习算法,下面是一个简单的决策树分类算法的代码示例:
import numpy as np
class Node:
def __init__(self, feature=None, threshold=None, left=None, right=None, label=None):
self.feature = feature # 选择的特征
self.threshold = threshold # 特征的阈值
self.left = left # 左子树
self.right = right # 右子树
self.label = label # 叶节点的类别
class DecisionTreeClassifier:
def __init__(self, max_depth=None):
self.max_depth = max_depth # 决策树最大深度
def fit(self, X, y):
self.n_classes = len(set(y)) # 类别的数量
self.n_features = X.shape[1] # 特征的数量
self.tree = self._grow_tree(X, y) # 生长决策树
def _grow_tree(self, X, y, depth=0):
n_samples_per_class = [np.sum(y == i) for i in range(self.n_classes)]
predicted_class = np.argmax(n_samples_per_class) # 预测的类别
# 如果满足停止生长的条件
if (
depth == self.max_depth or
np.all(y == y[0]) or
np.max(n_samples_per_class) / np.sum(n_samples_per_class) >= 0.95
):
return Node(label=predicted_class)
# 寻找最佳分裂特征和阈值
best_feature, best_threshold = self._best_split(X, y)
# 划分数据集
left_indices = X[:, best_feature] < best_threshold
right_indices = ~left_indices
left = self._grow_tree(X[left_indices, :], y[left_indices], depth+1)
right = self._grow_tree(X[right_indices, :], y[right_indices], depth+1)
return Node(feature=best_feature, threshold=best_threshold, left=left, right=right)
def _best_split(self, X, y):
best_gini = np.inf
best_feature = None
best_threshold = None
for feature in range(self.n_features):
thresholds = np.unique(X[:, feature])
for threshold in thresholds:
gini = self._gini_index(X, y, feature, threshold)
if gini < best_gini:
best_gini = gini
best_feature = feature
best_threshold = threshold
return best_feature, best_threshold
def _gini_index(self, X, y, feature, threshold):
left_indices = X[:, feature] < threshold
right_indices = ~left_indices
gini_left = self._gini_impurity(y[left_indices])
gini_right = self._gini_impurity(y[right_indices])
n_left = np.sum(left_indices)
n_right = np.sum(right_indices)
n_total = n_left + n_right
gini = (n_left / n_total) * gini_left + (n_right / n_total) * gini_right
return gini
def _gini_impurity(self, y):
n_samples = len(y)
if n_samples == 0:
return 0
counts = np.bincount(y)
probabilities = counts / n_samples
gini = 1 - np.sum(probabilities ** 2)
return gini
def predict(self, X):
return np.array([self._traverse_tree(x, self.tree) for x in X])
def _traverse_tree(self, x, node):
if node.label is not None:
return node.label
if x[node.feature] < node.threshold:
return self._traverse_tree(x, node.left)
else:
return self._traverse_tree(x, node.right)
上述代码实现了一个简单的决策树分类器,包含了决策树的生长过程、最佳分裂特征和阈值的选择、基尼指数的计算以及预测等功能。可以通过实例化 DecisionTreeClassifier 类并调用 fit 方法拟合数据,然后使用 predict 方法进行预测。