LRU算法(Least Recently Used,最近最少使用算法)的思想是基于"时间局部性"原理,即在一段时间内,被访问过的数据在未来仍然会被频繁访问的概率较高。
LRU 原理
LRU算法的主要思想是将最近被使用的数据保留在缓存中,而最久未被使用的数据则被替换出去。它维护一个缓存空间,当需要替换数据时,选择缓存中最久未被使用的数据进行替换。
具体实现时,LRU算法通常使用一种数据结构,比如双向链表(Doubly Linked List)和哈希表(Hash Table)的组合来实现。每个节点在双向链表中保存了数据的值,并且通过哈希表提供了快速的数据查找能力。

LRU 局部性场景
尽管LRU算法在许多情况下表现良好,但在某些特定情况下可能无法很好地适应,包括以下几种情况:
突发访问模式(Bursty Access Pattern):如果访问模式发生突变,例如某个数据在一段时间内被频繁访问,然后突然不再被访问,LRU算法可能无法及时将其替换出缓存。这是因为LRU算法仅根据最近使用的时间进行替换决策,而不考虑访问频率的变化。
热点数据(Hotspot Data):当存在少数数据被频繁访问,而其他数据很少被访问时,LRU算法可能无法很好地区分热点数据和冷门数据。即使某个数据被频繁访问,但如果它在缓存中的位置靠后,LRU算法可能会将其替换出去,从而导致频繁访问的数据被频繁地加载到缓存中,影响性能。
数据访问分布不均匀(Skewed Data Access Pattern):如果数据的访问分布不均匀,即部分数据被频繁访问而其他数据很少被访问,LRU算法可能无法很好地利用缓存空间。因为LRU算法只关注最近访问的数据,而不管数据的访问频率。这可能导致一些常用数据无法保持在缓存中,而被替换出去。
在这些情况下,可以考虑其他缓存替换算法,如LFU(Least Frequently Used,最不经常使用算法)或者根据具体需求选择其他算法的变种,以更好地适应实际的数据访问模式。
LRU 实现
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
- 双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的
- 哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置
首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在O(1)的时间内完成 get或者 put 操作。具体的方法如下:
对于
get操作,首先判断 key 是否存在:.- 如果 key 不存在,则返回 -1;
- 如果 key 存在,则 key 对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
对于
put操作,首先判断 key 是否存在:- 如果 key不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
- 如果 key 存在,则与
get操作类似,先通过哈希表定位,再将对应的节点的值更新头value ,并将该节点移到双向链表的头部。
上述各项操作中,访问哈希表的时间复杂度为O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和[在双向链表的头部添加节点」两步操作,都可以在O(1)时间内完成。
在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,以避免对头尾指针额外的操作
public class LRUCache {
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
}
InnoDB LRU 原理
InnoDB将LRU链表分为两个部分,也就是所谓的old区 和 young区。
young区在链表的头部,存放经常被访问的数据页,可以理解为热数据old区在链表的尾部,存放不经常被访问的数据页,可以理解为冷数据
这两个部分的交汇处称为midpoint,分区比例可以使用以下参数设置
show variables like 'innodb_old_blocks_pct';
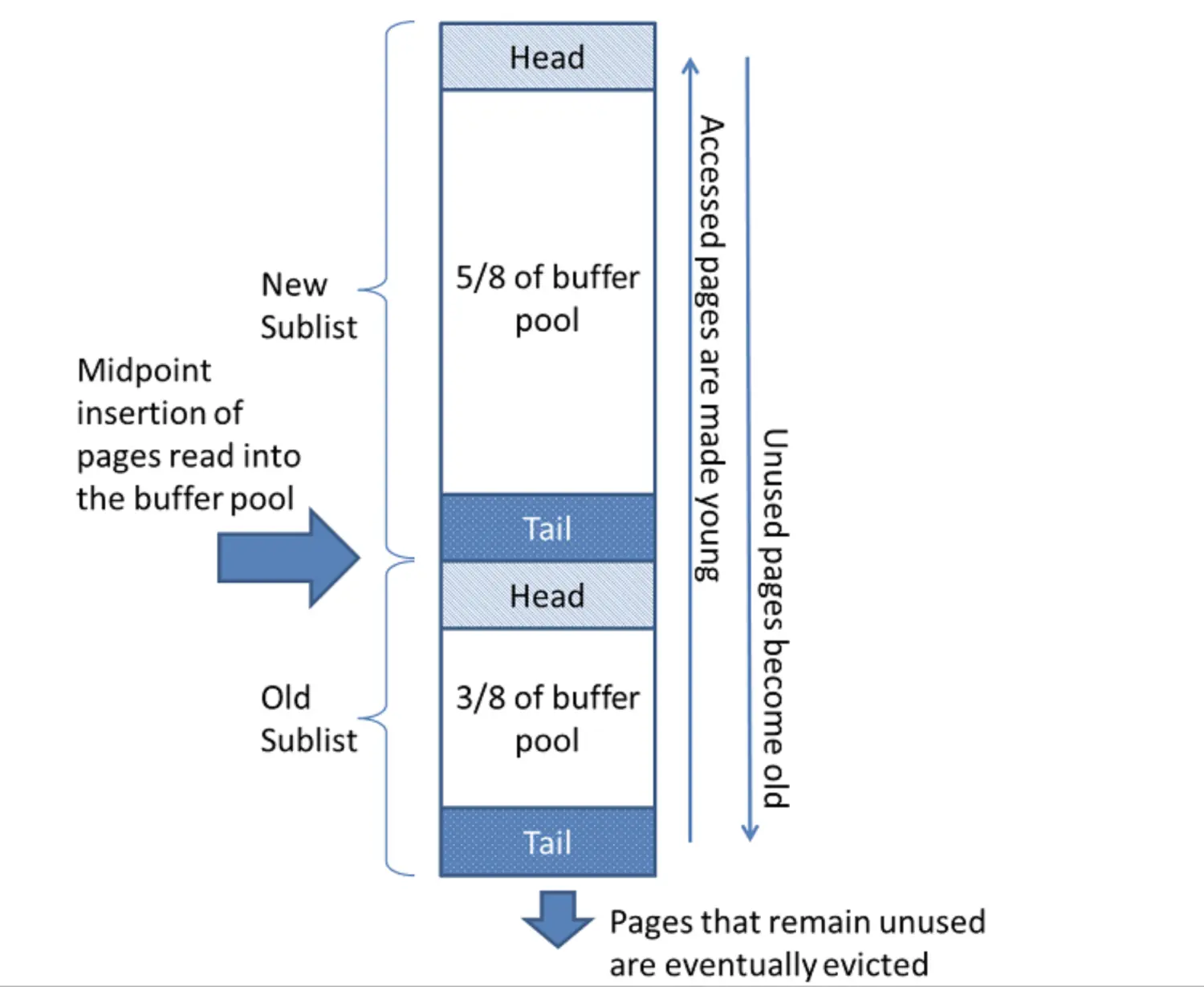
数据页第一次被加载进Buffer Pool时在old区的头部。当这个数据页在old区,再次被访问到,会做如下的判断:如果这个数据页在LRU链表中的old区 存在的时间超过了1秒,就把它移动到young区。
时间设置参数为
innodb_old_blocks_time