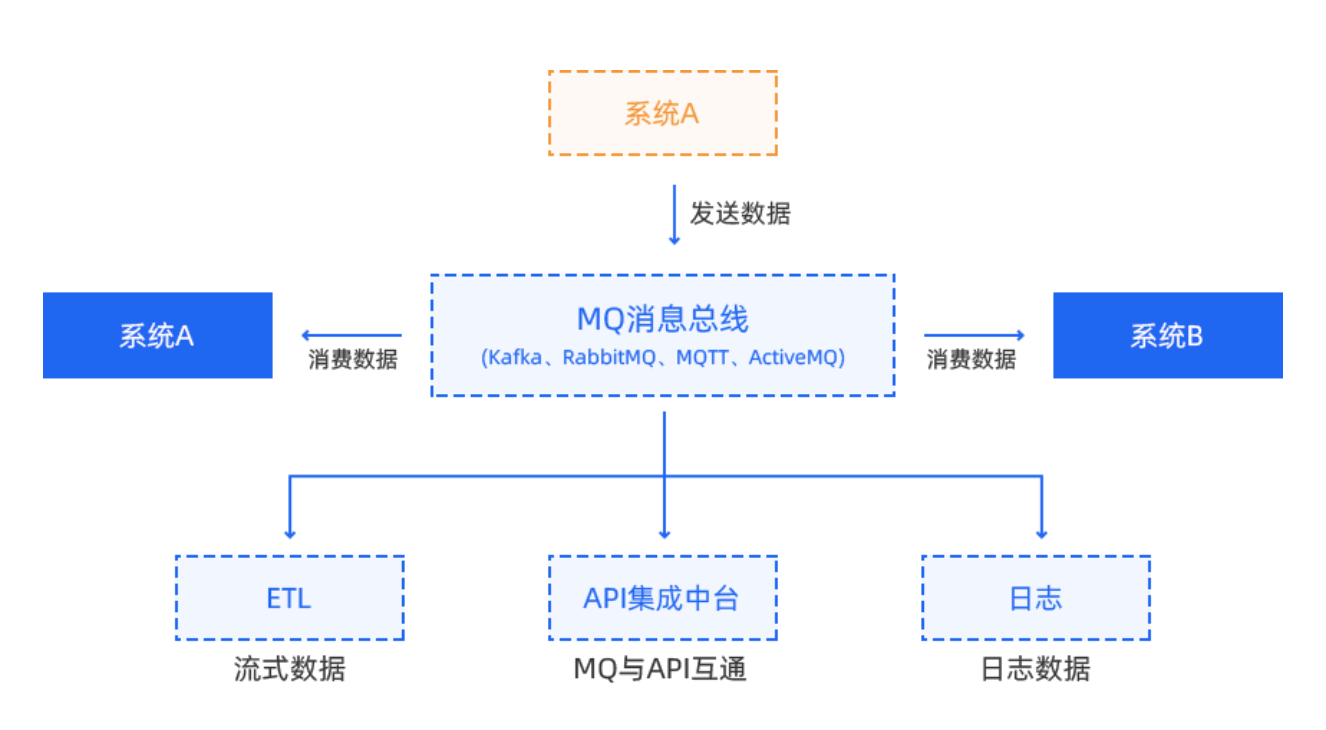
SpringCloud
小知识点
开发技巧积累
一般而言,调用者不应该获悉服务提供者的entity资源并知道表结构关系,所以服务提供方给出的接口文档都都应成为DTO
日期格式问题的处理

把上面的格式进行统一和定制
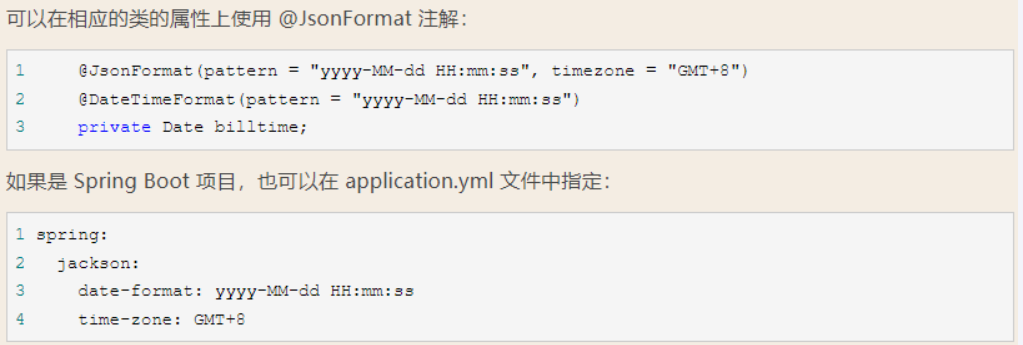
骚戴理解:其实我更喜欢第二种,因为我懒,实际开发中用第一种更多更普遍
/
* 创建时间
*/
@Column(name = "create_time")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date createTime;HTTP请求返回的状态码

统一返回对象
http响应码枚举类
package com.atguigu.cloud.resp;
import lombok.Getter;
import java.util.Arrays;
/
* @auther zzyy
* @create 2023-11-04 11:51
*/
@Getter
public enum ReturnCodeEnum
{
/操作失败/
RC999("999","操作XXX失败"),
/操作成功/
RC200("200","success"),
/服务降级/
RC201("201","服务开启降级保护,请稍后再试!"),
/热点参数限流/
RC202("202","热点参数限流,请稍后再试!"),
/系统规则不满足/
RC203("203","系统规则不满足要求,请稍后再试!"),
/授权规则不通过/
RC204("204","授权规则不通过,请稍后再试!"),
/access_denied/
RC403("403","无访问权限,请联系管理员授予权限"),
/access_denied/
RC401("401","匿名用户访问无权限资源时的异常"),
RC404("404","404页面找不到的异常"),
/服务异常/
RC500("500","系统异常,请稍后重试"),
RC375("375","数学运算异常,请稍后重试"),
INVALID_TOKEN("2001","访问令牌不合法"),
ACCESS_DENIED("2003","没有权限访问该资源"),
CLIENT_AUTHENTICATION_FAILED("1001","客户端认证失败"),
USERNAME_OR_PASSWORD_ERROR("1002","用户名或密码错误"),
BUSINESS_ERROR("1004","业务逻辑异常"),
UNSUPPORTED_GRANT_TYPE("1003", "不支持的认证模式");
/自定义状态码/
private final String code;
/自定义描述/
private final String message;
ReturnCodeEnum(String code, String message){
this.code = code;
this.message = message;
}
//遍历枚举V1
public static ReturnCodeEnum getReturnCodeEnum(String code)
{
for (ReturnCodeEnum element : ReturnCodeEnum.values()) {
if(element.getCode().equalsIgnoreCase(code))
{
return element;
}
}
return null;
}
//遍历枚举V2
public static ReturnCodeEnum getReturnCodeEnumV2(String code)
{
return Arrays.stream(ReturnCodeEnum.values()).filter(x -> x.getCode().equalsIgnoreCase(code)).findFirst().orElse(null);
}
/*public static void main(String[] args)
{
System.out.println(getReturnCodeEnumV2("200"));
System.out.println(getReturnCodeEnumV2("200").getCode());
System.out.println(getReturnCodeEnumV2("200").getMessage());
}*/
}
骚戴理解:代码使用了 Java 8 中的流式操作,即 Arrays.stream(ReturnCodeEnum.values()),将 ReturnCodeEnum 枚举中的所有值转化为流,然后使用 filter() 方法对流中的元素进行过滤,根据传入的 code 值和枚举实例的 getCode() 方法进行比较,找到符合条件的枚举实例。
最后使用 findFirst().orElse(null) 方法来获取匹配的第一个枚举实例,如果没有匹配到则返回 null。因此,这段代码的作用是根据指定的 code 值来获取相应的 ReturnCodeEnum 枚举实例。
统一响应对象
package com.atguigu.cloud.resp;
import lombok.Data;
import lombok.experimental.Accessors;
/
* @auther zzyy
* @create 2023-11-04 11:59
*/
@Data
@Accessors(chain = true)
public class ResultData<T> {
private String code;/ 结果状态 ,具体状态码参见枚举类ReturnCodeEnum.java*/
private String message;
private T data;
private long timestamp ;
public ResultData (){
this.timestamp = System.currentTimeMillis();
}
public static <T> ResultData<T> success(T data) {
ResultData<T> resultData = new ResultData<>();
resultData.setCode(ReturnCodeEnum.RC200.getCode());
resultData.setMessage(ReturnCodeEnum.RC200.getMessage());
resultData.setData(data);
return resultData;
}
public static <T> ResultData<T> fail(String code, String message) {
ResultData<T> resultData = new ResultData<>();
resultData.setCode(code);
resultData.setMessage(message);
return resultData;
}
}Controller层使用
@PutMapping(value = "/pay/update")
@Operation(summary = "修改",description = "修改支付流水方法")
public ResultData<String> updatePay(@RequestBody PayDTO payDTO)
{
Pay pay = new Pay();
BeanUtils.copyProperties(payDTO, pay);
int i = payService.update(pay);
return ResultData.success("成功修改记录,返回值:"+i);
}
@GetMapping(value = "/pay/get/{id}")
@Operation(summary = "按照ID查流水",description = "查询支付流水方法")
public ResultData<Pay> getById(@PathVariable("id") Integer id)
{
Pay pay = payService.getById(id);
return ResultData.success(pay);
}全局异常处理器
package com.atguigu.cloud.exp;
import com.atguigu.cloud.resp.ResultData;
import com.atguigu.cloud.resp.ReturnCodeEnum;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.HttpStatus;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseStatus;
import org.springframework.web.bind.annotation.RestControllerAdvice;
/
* @auther zzyy
* @create 2023-11-04 12:20
*/
@Slf4j
@RestControllerAdvice
public class GlobalExceptionHandler
{
/
* 默认全局异常处理。
* @param e the e
* @return ResultData
*/
@ExceptionHandler(RuntimeException.class)
@ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR)
public ResultData<String> exception(Exception e) {
System.out.println("----come in GlobalExceptionHandler");
log.error("全局异常信息exception:{}", e.getMessage(), e);
return ResultData.fail(ReturnCodeEnum.RC500.getCode(),e.getMessage());
}
}骚戴理解:@ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR) 是Spring框架中的一个注解,用于指定方法的响应状态码。具体地说,这个注解表示当一个方法抛出了异常导致服务器内部出现错误时,将返回HTTP状态码"500 Internal Server Error"。使用这个注解可以告诉客户端请求发生了服务器内部错误,并且可以让开发人员更容易地对错误进行诊断和处理。
CAP理论

CAP 是指分布式环境中的三个基本特性:一致性(Consistency)、可用性(Availability)、分区容忍性(Partition Tolerance)。
- 一致性(Consistency):指数据在多个副本之间能够保持一致的特性。在分布式系统中,如果一个数据副本被修改,那么在一定时间内,系统中的其他副本应该能够获取到最新的修改。这意味着系统会保证所有数据的状态都是一致的。
- 可用性(Availability):指系统提供的服务必须保证可用,即系统对于用户的请求应该能够及时地响应,而不是因为节点故障而导致不可用。在分布式系统中,即使部分节点失效,系统仍需保持可用。
- 分区容忍性(Partition Tolerance):指系统可以继续工作即使系统内部的通信出现故障或者分区,即系统可以容忍节点之间的通信中断或者网络分区。
CAP理论认为在分布式系统中,不可能同时满足一致性、可用性和分区容忍性这三个特性的完全。在面对网络分区时,很难同时保证一致性和可用性。
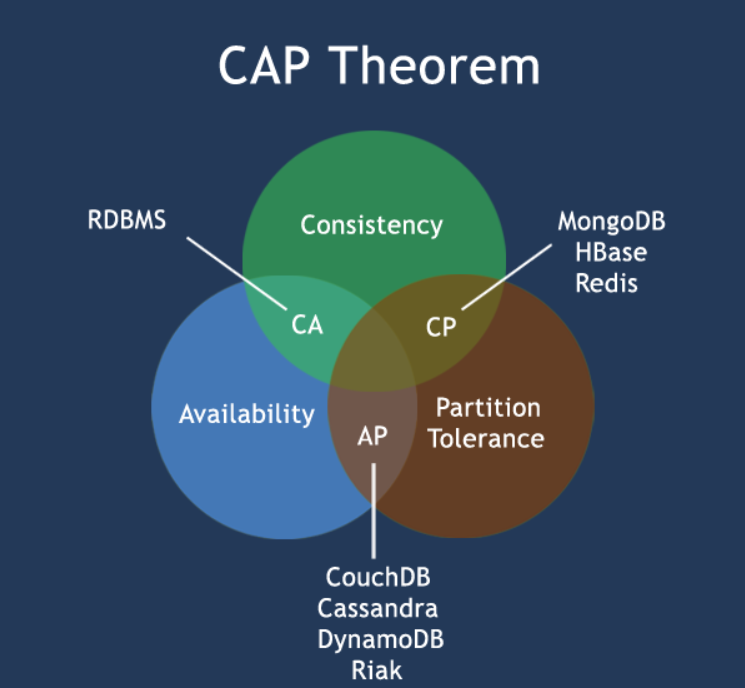
最多只能同时较好的满足两个。CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。


applicaiton.yml和bootstrap.yml
applicaiton.yml是用户级的资源配置项,bootstrap.yml是系统级的,优先级更加高
Spring Cloud会创建一个“Bootstrap Context”,作为Spring应用的`Application Context`的父上下文。初始化的时候,`Bootstrap Context`负责从外部源加载配置属性并解析配置。这两个上下文共享一个从外部获取的`Environment`。
`Bootstrap`属性有高优先级,默认情况下,它们不会被本地配置覆盖。 `Bootstrap context`和`Application Context`有着不同的约定,所以新增了一个`bootstrap.yml`文件,保证`Bootstrap Context`和`Application Context`配置的分离。
application.yml文件改为bootstrap.yml,这是很关键的或者两者共存
因为bootstrap.yml是比application.yml先加载的。bootstrap.yml优先级高于application.yml
Swagger3
骚戴理解:Swagger3只需要知道怎么用和怎么在项目中整合即可,需要知道常用的Swagger3注解的作用和属性
项目中整合Swagger3的步骤
导入依赖
<!-- swagger3 调用方式 http://你的主机IP地址:5555/swagger-ui/index.html -->
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>${swagger3.version}</version>
</dependency>使用swagger3注解
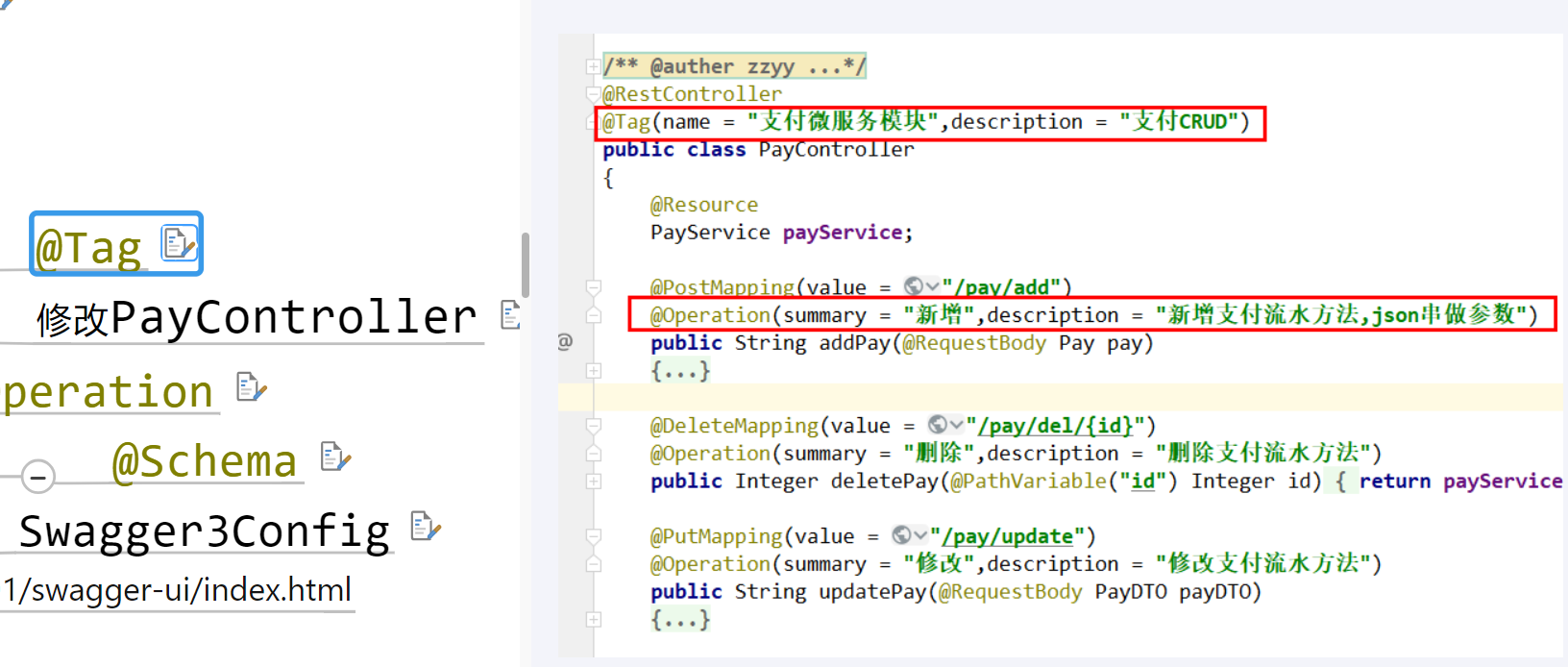
骚戴理解
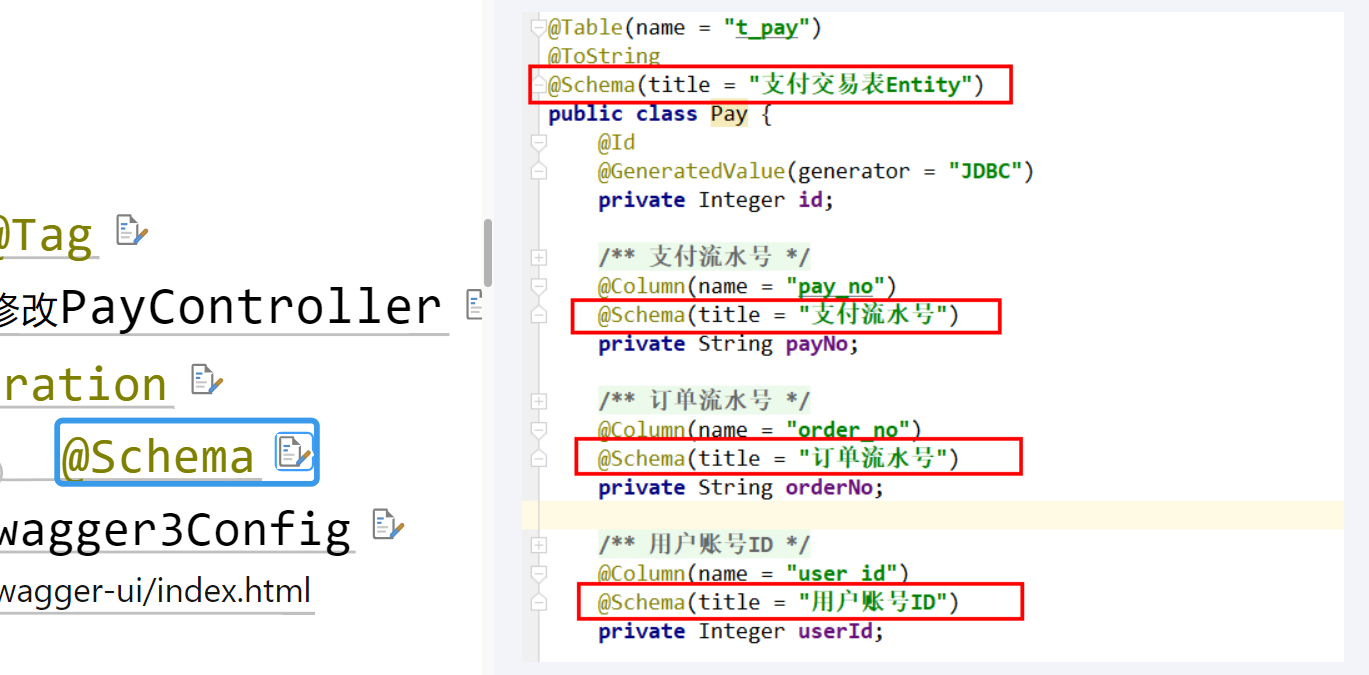
- @ Tab:描述控制器Controller信息,属性有name和description
- @ Operation: 描述控制器Controller接口信息,属性有summary和description
- @ Schema: 描述实体类信息,属性有title
Swagger3的配置类
package com.atguigu.cloud.config;
import io.swagger.v3.oas.models.ExternalDocumentation;
import io.swagger.v3.oas.models.OpenAPI;
import io.swagger.v3.oas.models.info.Info;
import org.springdoc.core.models.GroupedOpenApi;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/
* @auther zzyy
* @create 2023-11-04 10:40
*/
@Configuration
public class Swagger3Config
{
@Bean
public GroupedOpenApi PayApi()
{
return GroupedOpenApi.builder().group("支付微服务模块").pathsToMatch("/pay/").build();
}
@Bean
public GroupedOpenApi OtherApi()
{
return GroupedOpenApi.builder().group("其它微服务模块").pathsToMatch("/other/", "/others").build();
}
/*@Bean
public GroupedOpenApi CustomerApi()
{
return GroupedOpenApi.builder().group("客户微服务模块").pathsToMatch("/customer/", "/customers").build();
}*/
@Bean
public OpenAPI docsOpenApi()
{
return new OpenAPI()
.info(new Info().title("cloud2024")
.description("通用设计rest")
.version("v1.0"))
.externalDocs(new ExternalDocumentation()
.description("www.atguigu.com")
.url("https://yiyan.baidu.com/"));
}
}骚戴理解:这里对微服务的接口进行了分组,按照服务进行分组
- Info:包含了标题、描述和版本号的信息,用于描述API文档的基本信息。这里标题为"cloud2024",描述为"通用设计rest",版本号为"v1.0"。
- ExternalDocumentation:用于定义外部文档信息,包含了描述和URL。在这里描述为"www.atguigu.com",URL为"https://yiyan.baidu.com/"。
访问地址:http://localhost:8001/swagger-ui/index.html
RestTemplate
RestTemplate提供了多种便捷访问远程Http服务的方法,是一种简单便捷的访问restful服务模板类,是Spring提供的用于访问Rest服务的客户端模板工具集
官网地址:RestTemplate (Spring Framework 6.0.11 API)
xxxForObject和xxxForEntity的区别

GET请求方法

POST请求方法

使用
使用restTemplate访问restful接口非常的简单粗暴无脑。(url, requestMap, ResponseBean.class)这三个参数分别代表 REST请求地址、请求参数、HTTP响应转换被转换成的对象类型。
配置类
package com.atguigu.cloud.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
/
* @auther zzyy
* @create 2023-11-04 15:57
*/
@Configuration
public class RestTemplateConfig
{
@Bean
public RestTemplate restTemplate()
{
return new RestTemplate();
}
}骚戴理解:这里要知道bean怎么定义,这个方法名通常是这个对象的首字母小写
Controller层使用
package com.atguigu.cloud.controller;
import com.atguigu.cloud.entities.PayDTO;
import com.atguigu.cloud.resp.ResultData;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.client.RestTemplate;
/
* @auther zzyy
* @create 2023-11-04 16:00
*/
@RestController
public class OrderController{
public static final String PaymentSrv_URL = "http://localhost:8001";//先写死,硬编码
@Autowired
private RestTemplate restTemplate;
/
* 一般情况下,通过浏览器的地址栏输入url,发送的只能是get请求
* 我们底层调用的是post方法,模拟消费者发送get请求,客户端消费者
* 参数可以不添加@RequestBody
* @param payDTO
* @return
*/
@GetMapping("/consumer/pay/add")
public ResultData addOrder(PayDTO payDTO){
return restTemplate.postForObject(PaymentSrv_URL + "/pay/add",payDTO,ResultData.class);
}
// 删除+修改操作作为家庭作业,O(∩_∩)O。。。。。。。
@GetMapping("/consumer/pay/get/{id}")
public ResultData getPayInfo(@PathVariable("id") Integer id){
return restTemplate.getForObject(PaymentSrv_URL + "/pay/get/"+id, ResultData.class, id);
}
}骚戴理解:@RequestBody注解通常是用来接收POST请求中的JSON数据,将请求体中的JSON数据绑定到实体类对象上。因此,对于GET请求来说,不需要使用@RequestBody注解来接收参数
分布式服务发现和配置-Consul
Consul 是一套开源的分布式服务发现和配置管理系统,由 HashiCorp 公司用 Go 语言开发。提供了微服务系统中的服务治理、配置中心、控制总线等功能。这些功能中的每一个都可以根据需要单独使用,也可以一起使用以构建全方位的服务网格,总之Consul提供了一种完整的服务网格解决方案。
它具有很多优点。包括: 基于 raft 协议,比较简洁; 支持健康检查, 同时支持 HTTP 和 DNS 协议 支持跨数据中心的 WAN 集群 提供图形界面 跨平台,支持 Linux、Mac、Windows
禁止使用问题
HashiCorp是一家非常知名的基础软件提供商,很多人可能没听过它的名字,但是其旗下的6款主流软件,Terraform、Consul、Vagrant、Nomad、Vault,Packer 相信不少程序员都听说或使用过,尤其是Consul使用者不尽其数。截止目前为止,从HashiCorp 官网上的声明来看,开源项目其实还是“安全”的,被禁用的只是Vault企业版(并且原因是Vault产品目前使用的加密算法在中国不符合法规,另一方面是美国出口管制法在涉及加密相关软件上也有相应规定。因此这两项原因使得HashiCorp不得不在声明中说明风险)而非其他所有开源产品(Terraform、Consul等)。因此,大家可以暂时放下心来,放心使用
为什么不再使用传统老牌的Eureka?

骚戴理解:其实就两个核心原因,一个是Eureka停更了,另外一个是Eureka需要嵌入到项目里面,单独开一个应用作为注册中心,耦合度太高
Consul作用

Consul使用
首先要下载consul并且启动他,通过consul agent -dev来启动


服务注册
导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
</dependency>配置yml
server:
port: 8001
# ==========applicationName + druid-mysql8 driver===================
spring:
application:
name: cloud-payment-service
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db2024?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&rewriteBatchedStatements=true&allowPublicKeyRetrieval=true
username: root
password: 123456
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
service-name: ${spring.application.name}
# ========================mybatis===================
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.atguigu.cloud.entities
configuration:
map-underscore-to-camel-case: trueserver:
port: 80
spring:
application:
name: cloud-consumer-order
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}主启动类加注解@EnableDiscoveryClient
package com.atguigu.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import tk.mybatis.spring.annotation.MapperScan;
/
* @auther zzyy
* @create 2023-11-03 17:54
*/
@SpringBootApplication
@MapperScan("com.atguigu.cloud.mapper") //import tk.mybatis.spring.annotation.MapperScan;
@EnableDiscoveryClient
public class Main8001
{
public static void main(String[] args)
{
SpringApplication.run(Main8001.class,args);
}
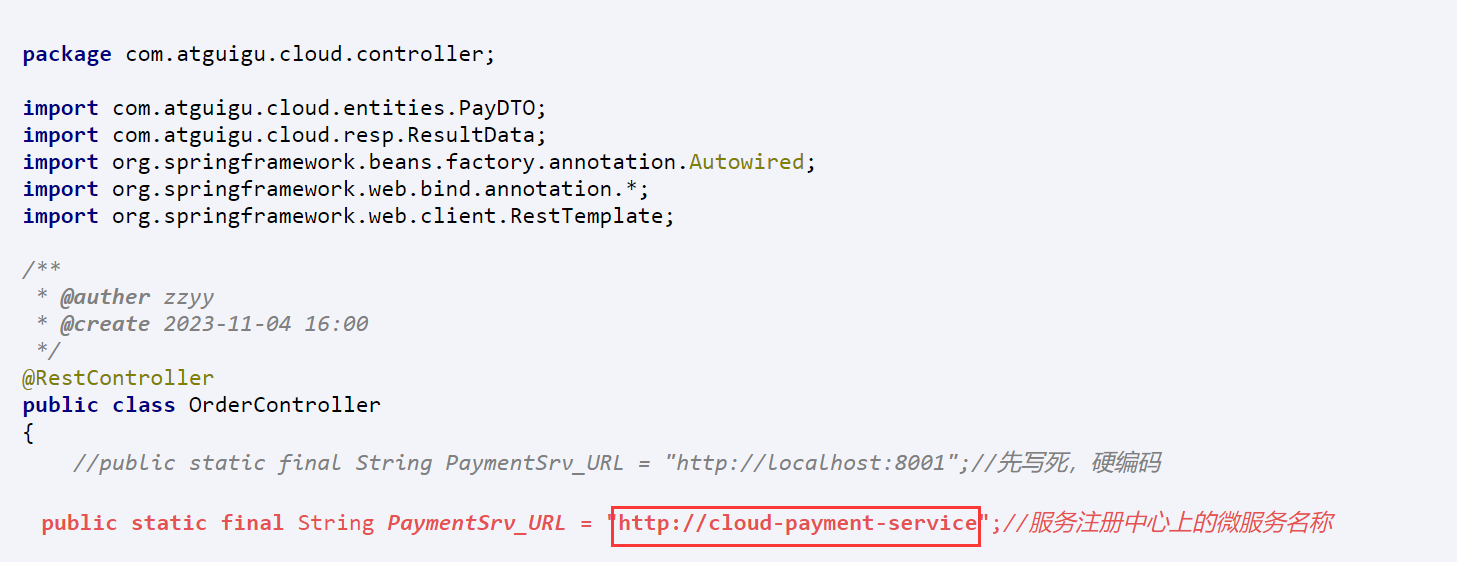
}骚戴理解:消费者和提供者注册到consul的步骤和逻辑几乎是一样的,如果是服务消费者,可以把动态的写url,用服务的名称即可,如下所示

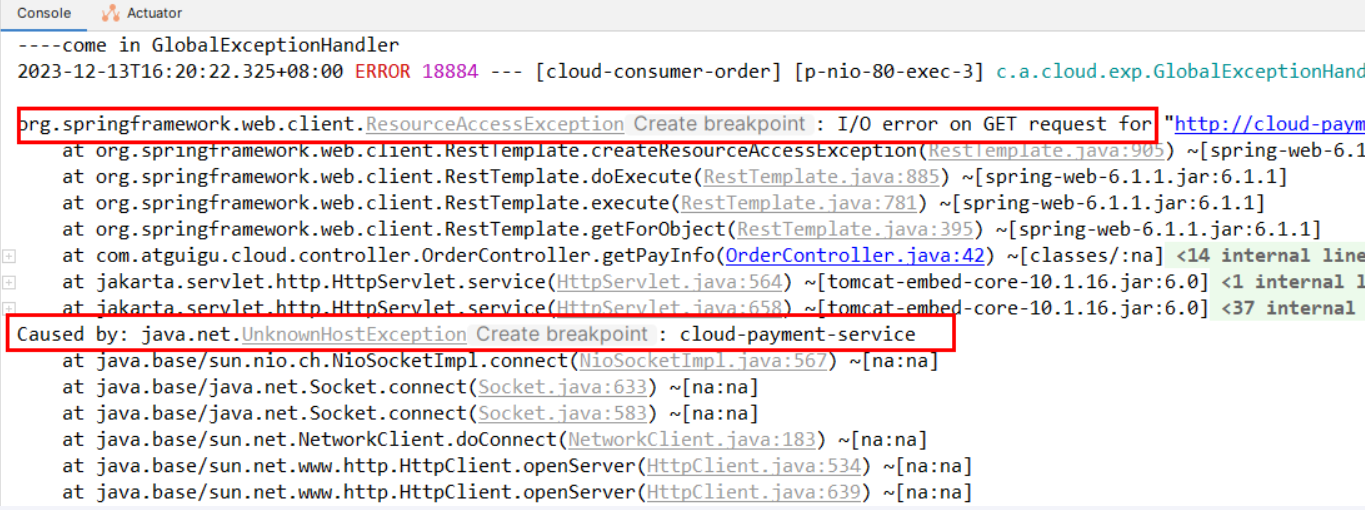
服务消费者注意事项
骚戴理解:在消费者服务里面使用consul去调用已经注册的服务的时候需要注意一个问题,需要在RestTemplete/的这个bean里面添加@LoadBalanced注解来支持consul自带的负载均衡,因为consul默认是自带负债均衡的,它默认你是多个微服务来作为服务提供者,如果不加这个注解,就会报错,报错如下所示
/
* @auther zzyy
* @create 2023-11-04 15:57
*/
@Configuration
public class RestTemplateConfig
{
@Bean
@LoadBalanced
public RestTemplate restTemplate()
{
return new RestTemplate();
}
}
服务配置与刷新
微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务。由于每个服务都需要必要的配置信息才能运行,所以一套集中式的、动态的配置管理设施是必不可少的。比如某些配置文件中的内容大部分都是相同的,只有个别的配置项不同。就拿数据库配置来说吧,如果每个微服务使用的技术栈都是相同的,则每个微服务中关于数据库的配置几乎都是相同的,有时候主机迁移了,我希望一次修改,处处生效。当下我们每一个微服务自己带着一个application.yml,上百个配置文件的管理....../(ㄒoㄒ)/~~
骚戴理解:所以可以用Consul作为配置中心,把通用全局配置信息直接注册进Consul服务器,然后直接从Consul获取
导入依赖
<!--SpringCloud consul config-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>新增bootstrap.yml
spring:
application:
name: cloud-payment-service
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
service-name: ${spring.application.name}
config:
profile-separator: '-' # default value is ",",we update '-'
format: YAML
# config/cloud-payment-service/data
# /cloud-payment-service-dev/data
# /cloud-payment-service-prod/data修改application.yml
server:
port: 8001
# ==========applicationName + druid-mysql8 driver===================
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db2024?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&rewriteBatchedStatements=true&allowPublicKeyRetrieval=true
username: root
password: 123456
profiles:
active: dev # 多环境配置加载内容dev/prod,不写就是默认default配置Consul持久化

@echo.服务启动......
@echo off
@sc create Consul binpath= "D:\devSoft\consul_1.17.0_windows_386\consul.exe agent -server -ui -bind=127.0.0.1 -client=0.0.0.0 -bootstrap-expect 1 -data-dir D:\devSoft\consul_1.17.0_windows_386\mydata "
@net start Consul
@sc config Consul start= AUTO
@echo.Consul start is OK......success
@pause骚戴理解:binpath这个值要根据自己的情况进行修改,配置的就是Consul的启动程序路径和持久化存储文件夹的路径,记得用管理员身份运行
负载均衡服务调用-LoadBalancer
Ribbon
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。
简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。简单的说,就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。我们很容易使用Ribbon实现自定义的负载均衡算法。
LoadBalancer
LB负载均衡(Load Balance)是什么?
简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA(高可用),常见的负载均衡有软件Nginx,LVS,硬件 F5等
spring-cloud-starter-loadbalancer组件是什么
Spring Cloud LoadBalancer是由SpringCloud官方提供的一个开源的、简单易用的客户端负载均衡器,它包含在SpringCloud-commons中用它来替换了以前的Ribbon组件。相比较于Ribbon,SpringCloud LoadBalancer不仅能够支持RestTemplate,还支持WebClient(WeClient是Spring Web Flux中提供的功能,可以实现响应式异步请求)
loadbalancer本地负载均衡客户端 VS Nginx服务端负载均衡区别?
- Nginx是服务器负载均衡,客户端所有请求都会交给nginx,然后由nginx实现转发请求,即负载均衡是由服务端实现的。
- loadbalancer本地负载均衡,在调用微服务接口时候,会在注册中心上获取注册信息服务列表之后缓存到JVM本地,从而在本地实现RPC远程服务调用技术。
骚戴理解:loadbalancer其实就是在微服务被调用的时候去注册中心查询到所有可以用的服务信息,然后把休息存储在本地,最后通过负债均衡算法来决定调用哪个微服务,而Nginx是拦截所有的请求,然后分配给微服务,Spring Cloud的LoadBalancer主要用于微服务架构中实现内部服务实例的选择和负载均衡,而Nginx负载均衡则更多地用于对外部的HTTP请求进行负载均衡
骚戴扩展:“本地负载均衡”是一种在客户端本地实现负载均衡的方式,通常用于微服务架构中的服务调用。在调用微服务接口时,客户端会先从注册中心(如Eureka、Consul等)获取服务实例列表,然后在本地缓存这些信息,并通过负载均衡算法选择要调用的服务实例进行RPC远程服务调用。
具体步骤如下:
1. 注册中心上的微服务实例列表:微服务在启动时会向注册中心注册自己的实例信息,包括主机名、IP地址、端口号等。
2. 客户端通过服务发现:当需要调用其他微服务接口时,客户端会到注册中心查询相应的服务实例列表,并把这些信息缓存在客户端的JVM中。
3. 本地负载均衡:在缓存中保存了服务实例列表后,客户端会根据负载均衡算法(如轮询、随机、加权轮询等)选择要调用的服务实例,这里的负载均衡过程是在客户端本地进行的。
4. RPC远程服务调用:客户端通过缓存的服务实例信息,选择一个服务实例发送RPC请求,请求会通过网络,调用目标服务实例的接口。
5. 容错与重试:如果选中的服务实例不可用,客户端可以根据配置进行容错处理,比如重试其他实例等。
本地负载均衡的好处在于减轻了服务端负载,提高了系统整体的性能和稳定性,同时减少了网络延迟。然而,需要注意的是,由于缓存的存在,在服务实例列表发生变化时,需要客户端主动刷新缓存或者实现缓存的动态更新,以保证调用的准确性和最新性。
loadbalancer使用
只需要在消费者(服务调用端)工程里面引用依赖就行
<!--loadbalancer-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>骚戴理解:由于在消费者里面指定了PaymentSrv_URL的值,也就是服务的名称,然后这个服务可能有很多个微服务,自己就会根据默认的轮询方式进行负债均衡
package com.atguigu.cloud.controller;
import com.atguigu.cloud.entities.PayDTO;
import com.atguigu.cloud.resp.ResultData;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.client.RestTemplate;
/
* @auther zzyy
* @create 2023-11-04 16:00
*/
@RestController
public class OrderController
{
//public static final String PaymentSrv_URL = "http://localhost:8001";//先写死,硬编码
public static final String PaymentSrv_URL = "http://cloud-payment-service";//服务注册中心上的微服务名称
@Autowired
private RestTemplate restTemplate;
@GetMapping(value = "/consumer/pay/get/info")
private String getInfoByConsul()
{
return restTemplate.getForObject(PaymentSrv_URL + "/pay/get/info", String.class);
}
}
实现原理
@Resource
private DiscoveryClient discoveryClient;
@GetMapping("/consumer/discovery")
public String discovery()
{
// 拿到所有的可用服务
List<String> services = discoveryClient.getServices();
for (String element : services) {
System.out.println(element);
}
System.out.println("===================================");
// 根据名称拿到所有的可用服务
List<ServiceInstance> instances = discoveryClient.getInstances("cloud-payment-service");
for (ServiceInstance element : instances) {
System.out.println(element.getServiceId()+"\t"+element.getHost()+"\t"+element.getPort()+"\t"+element.getUri());
}
return instances.get(0).getServiceId()+":"+instances.get(0).getPort();
}负载均衡算法:rest接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标 ,每次服务重启动后rest接口计数从1开始。
List<ServiceInstance> instances = discoveryClient.getInstances("cloud-payment-service");
如: List [0] instances = 127.0.0.1:8002
List [1] instances = 127.0.0.1:8001
8001+ 8002 组合成为集群,它们共计2台机器,集群总数为2, 按照轮询算法原理:
当总请求数为1时: 1 % 2 =1 对应下标位置为1 ,则获得服务地址为127.0.0.1:8001
当总请求数位2时: 2 % 2 =0 对应下标位置为0 ,则获得服务地址为127.0.0.1:8002
当总请求数位3时: 3 % 2 =1 对应下标位置为1 ,则获得服务地址为127.0.0.1:8001
当总请求数位4时: 4 % 2 =0 对应下标位置为0 ,则获得服务地址为127.0.0.1:8002
如此类推......
负债均衡算法

修改负债均衡算法
@Configuration
@LoadBalancerClient(
//下面的value值大小写一定要和consul里面的名字一样,必须一样
value = "cloud-payment-service",configuration = RestTemplateConfig.class)
public class RestTemplateConfig
{
@Bean
@LoadBalanced //使用@LoadBalanced注解赋予RestTemplate负载均衡的能力
public RestTemplate restTemplate(){
return new RestTemplate();
}
@Bean
ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);
}
}骚戴理解:
- @Bean: 声明该方法将返回一个bean,这样Spring容器就会在初始化时调用该方法并将其返回值存储为一个bean供其他组件使用。
- public ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(...): 方法声明了一个名为randomLoadBalancer的bean,并作为一个ReactorLoadBalancer的ServiceInstance泛型。
- loadBalancerClientFactory: 该参数是需要在方法中使用的 LoadBalancerClientFactory。注入此对象意味着您可以在方法内部使用它来获取所需的负载均衡器配置信息。
- environment: 该参数用于获取应用程序的环境属性。通过传递该参数,您可以在方法内部读取配置参数。
- String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME): 该行代码从环境属性中获取负载均衡器的名称。
- return new RandomLoadBalancer(...): 最终该方法返回一个RandomLoadBalancer的实例,它使用了loadBalancerClientFactory和name参数来进行初始化。
服务接口调用-OpenFeign

OpenFeign基本上就是当前微服务之间调用的事实标准
骚戴理解:简单来说就是通过接口+注解的方式声明式去发Http请求,基本上作用就是微服务之间的调用用它来实现,需要注意的是Feign是在客户端使用的,也就是消费者

OpenFeign的使用
导入依赖
<!--openfeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>OpenFeign使用案例
@FeignClient(value = "cloud-payment-service")
public interface PayFeignApi
{
/
* 新增一条支付相关流水记录
* @param payDTO
* @return
*/
@PostMapping("/pay/add")
public ResultData addPay(@RequestBody PayDTO payDTO);
/
* 按照主键记录查询支付流水信息
* @param id
* @return
*/
@GetMapping("/pay/get/{id}")
public ResultData getPayInfo(@PathVariable("id") Integer id);
/
* openfeign天然支持负载均衡演示
* @return
*/
@GetMapping(value = "/pay/get/info")
public String mylb();
}骚戴理解:其实就是加两个注解,OpenFeign默认集成了LoadBalancer
- 主启动类上面配置@EnableFeignClients表示开启OpenFeign功能并激活
- @FeignClient(value = "cloud-payment-service")这个注解声明Feign接口
注意事项
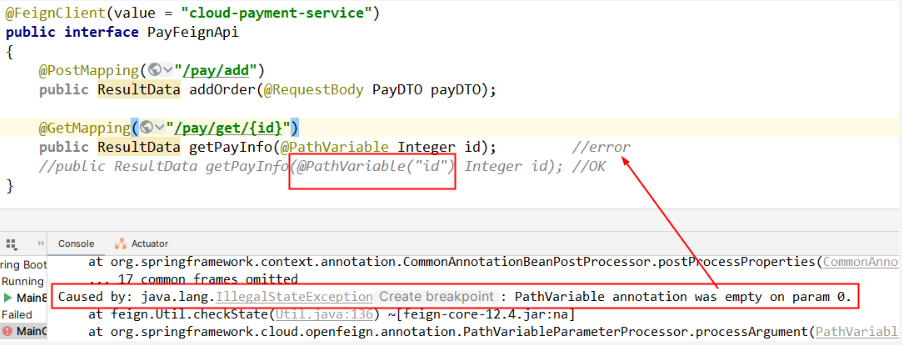
骚戴理解:使用@PathVariable("id")的写法是正确的。原因如下:
1. 在Feign中指定@PathVariable的值可以帮助Feign客户端准确地将参数映射到指定的路径变量。指定@PathVariable("id")告诉Feign客户端应该将方法参数id的值映射到路径中的{id}变量。
2. 另一方面,不指定@PathVariable值的写法,例如getPayInfo(@PathVariable Integer id),虽然在某些情况下可能会被Spring MVC或Spring Boot接受,并且可能能够工作,但这种写法是不够明确和规范的。在较新版本的Spring中,参数名称不会隐式地映射到路径变量,因此建议显式地指定@PathVariable的值。
因此,为了编程规范和清晰性,以及确保Feign客户端的正确映射,应该在Feign接口中使用@PathVariable("id")的写法。
OpenFeign的高级特效
OpenFeign超时控制
默认OpenFeign客户端等待60秒钟,但是服务端处理超过规定时间会导致Feign客户端返回报错。
为了避免这样的情况,有时候我们需要设置Feign客户端的超时控制,默认60秒太长或者业务时间太短都不好
两个关键参数配置:
- connectTimeout 连接超时时间
- readTimeout 请求处理超时时间
骚戴理解:connectTimeout是针对建立连接的最长等待时间,而readTimeout是针对整个请求处理过程的最长等待时间。
OpenFeign超时控制的使用
在消费者服务(客户端)YML文件里需要开启OpenFeign客户端超时控制
全局配置
spring:
cloud:
openfeign:
client:
config:
default:
#连接超时时间
connectTimeout: 3000
#读取超时时间
readTimeout: 3000骚戴理解:全局配置指的是调用的所有微服务都是这个超时时间,例如我A服务调用B服务,A服务调用C服务,那调用BC两个服务的超时时间就统一设置了
指定配置
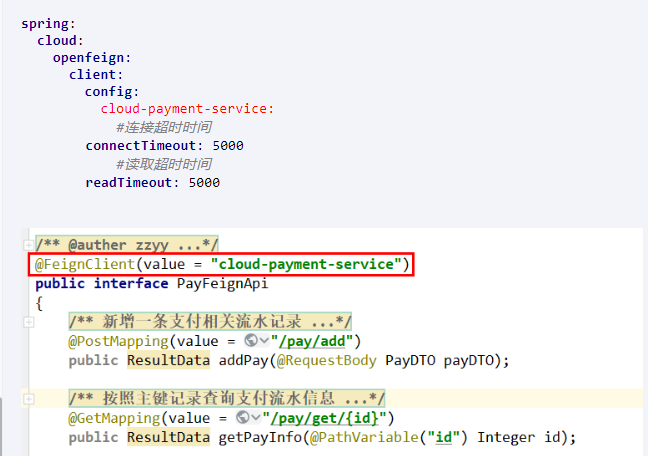
spring:
cloud:
openfeign:
client:
config:
cloud-payment-service:
#连接超时时间
connectTimeout: 5000
#读取超时时间
readTimeout: 5000骚戴理解:指定配置指的是调用的某个微服务是这个超时时间,例如我A服务调用cloud-payment-service服务,那么就是设置这单个cloud-payment-service服务的超时时间,如果超时就进行处理
server:
port: 80
spring:
application:
name: cloud-consumer-openfeign-order
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}
openfeign:
client:
config:
default:
connectTimeout: 4000 #连接超时时间
readTimeout: 4000 #读取超时时间
cloud-payment-service:
connectTimeout: 8000 #连接超时时间
readTimeout: 8000 #读取超时时间骚戴理解:如果全局配置和指定配置都用了,优先指定配置,也就是如上所示的配置,最后超时时间为8s
OpenFeign重试机制
默认情况下会创建Retryer.NEVER_RETRY类型为 Retryer的bean,这将禁用重试。请注意,这种重试行为与Feign默认行为不同,它会自动重试IOExceptions,将它们视为与网络相关的瞬态异常,以及从ErrorDecoder鲁出的任何 RetryableException。
骚戴理解:OpenFeign是Feign的增强和扩展,我一开始以为是同一个东西,只是表达不一样,注意避雷,所以就可以理解上面的那段话了“这种重试行为与Feign默认行为不同”
骚戴扩展:OpenFeign实际上是对Feign的增强和扩展,是Spring Cloud对Feign的重新实现。Feign是一个声明式、模板化的HTTP客户端,它使得编写Web服务客户端变得更加简单。而OpenFeign则是基于Feign的增强版本,提供了更多的功能和对Spring Cloud的集成。
OpenFeign相比于原始的Feign框架具有以下优点和改进:
1. 支持Spring Cloud特性:OpenFeign能够更好地与Spring Cloud整合,例如对Ribbon负载均衡和Hystrix熔断器的支持。
2. 注解支持:OpenFeign支持Spring Cloud中的注解,使得使用OpenFeign更加符合Spring的编程习惯。
3. 改进的性能和稳定性:OpenFeign在性能和稳定性上有一些改进,使得它更适合于生产环境的使用。
因此,尽管OpenFeign和Feign在名字和实现上存在一些差异,但从功能和目的上来说,OpenFeign是对Feign的增强和扩展,提供了更好的特性和与Spring Cloud集成的能力。
OpenFeign重试机制使用
OpenFeign重试机制默认是关闭的,只需要加个配置类改一下就行了
package com.atguigu.cloud.config;
import feign.Retryer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/
* @auther zzyy
* @create 2023-11-10 11:09
*/
@Configuration
public class FeignConfig
{
@Bean
public Retryer myRetryer()
{
//return Retryer.NEVER_RETRY; //Feign默认配置是不走重试策略的
//初始间隔时间为100ms,重试间最大间隔时间为1s,最大请求次数为3(默认1+2)
return new Retryer.Default(100,1,3);
}
}骚戴理解:值得提一嘴的是开启重试机制后,是只返回一个结果,没有我们想看到的过程,目前控制台没有看到3次重试过程,只看到结果,正常的,正确的,是feign的日志打印问题
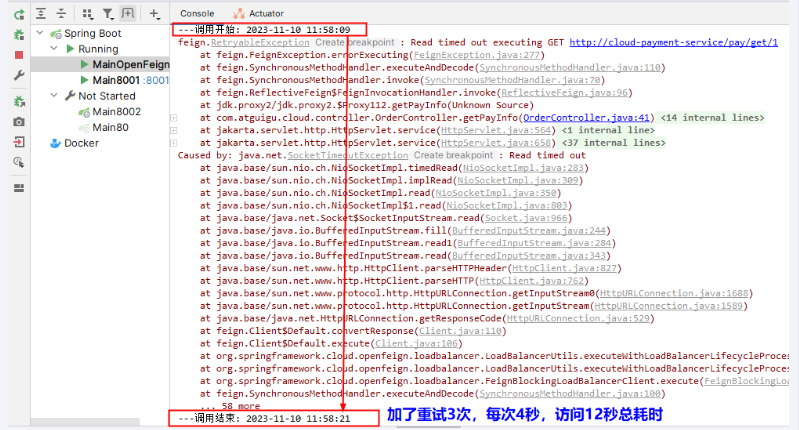
OpenFeign默认HttpClient修改
OpenFeign中http client如果不做特殊配置,OpenFeign默认使用JDK自带的HttpURLConnection发送HTTP请求,由于默认HttpURLConnection没有连接池、性能和效率比较低,如果采用默认,性能上不是最牛B的,所以我们要用Apache HttpClient 5替换OpenFeign默认的HttpURLConnection。
Apache HttpClient 5修改教程
导入HttpClient5依赖
<!-- httpclient5-->
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
<version>5.3</version>
</dependency>
<!-- feign-hc5-->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-hc5</artifactId>
<version>13.1</version>
</dependency>配置文件开启HttpClient5
# Apache HttpClient5 配置开启
spring:
cloud:
openfeign:
httpclient:
hc5:
enabled: true
OpenFeign请求/响应压缩
对请求和响应进行GZIP压缩
Spring Cloud OpenFeign支持对请求和响应进行GZIP压缩,以减少通信过程中的性能损耗。
通过下面的两个参数设置,就能开启请求与相应的压缩功能:
spring.cloud.openfeign.compression.request.enabled=true
spring.cloud.openfeign.compression.response.enabled=true细粒度化设置
对请求压缩做一些更细致的设置,比如下面的配置内容指定压缩的请求数据类型并设置了请求压缩的大小下限,
只有超过这个大小的请求才会进行压缩:
spring.cloud.openfeign.compression.request.enabled=true
spring.cloud.openfeign.compression.request.mime-types=text/xml,application/xml,application/json #触发压缩数据类型
spring.cloud.openfeign.compression.request.min-request-size=2048 #最小触发压缩的大小骚戴理解:最小触发压缩的大小是指的只有当请求体大小超过这个限制时,才会触发请求压缩
配置案例
server:
port: 80
spring:
application:
name: cloud-consumer-openfeign-order
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}
openfeign:
client:
config:
default:
#cloud-payment-service:
#连接超时时间
connectTimeout: 4000
#读取超时时间
readTimeout: 4000
httpclient:
hc5:
enabled: true
compression:
request:
enabled: true
min-request-size: 2048 #最小触发压缩的大小
mime-types: text/xml,application/xml,application/json #触发压缩数据类型
response:
enabled: trueOpenFeign日志打印功能
Feign 提供了日志打印功能,我们可以通过配置来调整日志级别,从而了解 Feign 中 Http 请求的细节,说白了就是对Feign接口的调用情况进行监控和输出
日志级别
NONE:默认的,不显示任何日志;
BASIC:仅记录请求方法、URL、响应状态码及执行时间;
HEADERS:除了 BASIC 中定义的信息之外,还有请求和响应的头信息;
FULL:除了 HEADERS 中定义的信息之外,还有请求和响应的正文及元数据。
配置日志级别
package com.atguigu.cloud.config;
import feign.Logger;
import feign.Retryer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/
* @auther zzyy
* @create 2023-04-12 17:24
*/
@Configuration
public class FeignConfig
{
@Bean
public Retryer myRetryer()
{
return Retryer.NEVER_RETRY; //默认
}
@Bean
Logger.Level feignLoggerLevel() {
return Logger.Level.FULL;
}
}骚戴理解:先在Feign的接口里面配置日志的级别,也就是上面的feignLoggerLevel,然后在配置文件指定feign日志以什么级别监控哪个接口
在配置文件指定feign日志以什么级别监控哪个接口
# feign日志以什么级别监控哪个接口
logging:
level:
com:
atguigu:
cloud:
apis:
PayFeignApi: debug 公式(三段):logging.level + 含有@FeignClient注解的完整带包名的接口名+debug
断路器-CircuitBreaker
Hystrix
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。了解一下即可,2024年了不再使用Hystrix,用Resilience4j替代
分布式系统面临的问题
复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。

服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
所以,通常当你发现一个模块下的某个实例失败后,这时候这个模块依然还会接收流量,然后这个有问题的模块还调用了其他的模块,这样就会发生级联故障,或者叫雪崩。
问题:禁止服务雪崩故障
解决: 有问题的节点,快速熔断(快速返回失败处理或者返回默认兜底数据【服务降级】)
“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。一句话,出故障了“保险丝”跳闸,别把整个家给烧了
断路器的作用
服务熔断(Circuit Breaker)是一种用于微服务架构中的重要模式,用于预防分布式系统中的故障蔓延和雪崩效应。除了服务熔断。
1. 服务熔断(Circuit Breaker)
- 服务熔断是通过引入一个临时的中间件组件,在请求发生异常的情况下,阻止请求继续发起,从而保护系统。典型的服务熔断框架包括Hystrix、Resilience4j等。
- 举例:当某个微服务不可用或者响应时间过长时,服务熔断可以使得失败的请求快速失败,不至于影响整个系统。例如,当一个服务的故障率超过某个阈值时,服务熔断器将拒绝为一段时间内的请求,避免故障在整个系统中传播。
2. 服务降级(Service Degradation)
- 服务降级是指在系统遇到大量请求时,对某些服务的处理进行降级,以保证核心功能的正常运行。
- 举例:当一个电商网站的用户评论服务(非核心功能)不可用时,可以采用静态缓存显示评论,而不是抛出错误。这样核心的下单、支付等功能仍能正常使用。
3. 服务限流(Rate Limiting)
- 服务限流是控制每个服务的访问量,以保护系统免受过载的一种技术手段。
- 举例:在API网关中,可以设置每个微服务的QPS(每秒请求量),当接口的请求量超过设定值时,就会进行限流,拒绝多余的请求。
4. 服务限时(Timeout Handling)
- 服务限时是为了控制服务请求的响应时间,避免请求因为等待超时而阻塞影响整个系统的服务。
- 举例:在调用外部依赖的服务时,设置每个操作的超时时间,当服务响应的时间过长时,系统不会无限等待,而是及时放弃该请求。
5. 服务预热(Warm-up)
- 服务预热是在请求到来之前,提前初始化和准备资源以加速服务的响应。
- 举例:某个机房突然发生故障,系统会自动将请求转发到其他机房,而在这之前,系统并不会直接将请求转发到这个机房,而是先预热。
6. 接近实时的监控兜底的处理动作
- 在服务发现到系统中有很多个服务调用链路时,监控这些链路状态对于保证系统稳定性非常重要。一旦发现某个服务调用异常,系统需要自动快速处理。
- 举例:在微服务架构中,通过实时监控系统中服务的健康度,可以快速地对出现问题的服务进行下线,从而保证整个系统能够正常运行。
CircuitBreaker
circuit Breaker只是一套规范和接口,落地实现者是Resilience4J
CircuitBreaker的目的是保护分布式系统免受故障和异常,提高系统的可用性和健壮性。
当一个组件或服务出现故障时,CircuitBreaker会迅速切换到开放OPEN状态(保险丝跳闸断电),阻止请求发送到该组件或服务从而避免更多的请求发送到该组件或服务。这可以减少对该组件或服务的负载,防止该组件或服务进一步崩溃,并使整个系统能够继续正常运行。同时,CircuitBreaker还可以提高系统的可用性和健壮性,因为它可以在分布式系统的各个组件之间自动切换,从而避免单点故障的问题。
Resilience4j
Resilience4j是一个专为函数式编程设计的轻量级容错库。Resilience4j提供高阶函数(装饰器),以通过断路器、速率限制器、重试或隔板增强任何功能接口、lambda 表达式或方法引用。您可以在任何函数式接口、lambda 表达式或方法引用上堆叠多个装饰器。优点是您可以选择您需要的装饰器,而没有其他选择。

熔断(CircuitBreaker)(服务熔断+服务降级)

举个例子:6次访问中当执行方法的失败率达到50%时CircuitBreaker将进入开启OPEN状态(保险丝跳闸断电)拒绝所有请求。等待5秒后,CircuitBreaker 将自动从开启OPEN状态过渡到半开HALF_OPEN状态,允许一些请求通过以测试服务是否恢复正常。如还是异常CircuitBreaker 将重新进入开启OPEN状态;如正常将进入关闭CLOSE闭合状态恢复正常处理请求。
断路器所有配置参数参考
failure-rate-threshold |
以百分比配置失败率峰值 |
sliding-window-type |
断路器的滑动窗口期类型 |
sliding-window-size |
若COUNT_BASED,则10次调用中有50%失败(即5次)打开熔断断路器; 若为TIME_BASED则,此时还有额外的两个设置属性,含义为:在N秒内(sliding-window-size)100%(slow-call-rate-threshold)的请求超过N秒(slow-call-duration-threshold)打开断路器。 |
slowCallRateThreshold |
以百分比的方式配置,断路器把调用时间大于slowCallDurationThreshold的调用视为慢调用,当慢调用比例大于等于峰值时,断路器开启,并进入服务降级。 |
slowCallDurationThreshold |
配置调用时间的峰值,高于该峰值的视为慢调用。 |
permitted-number-of-calls-in-half-open-state |
运行断路器在HALF_OPEN状态下时进行N次调用,如果故障或慢速调用仍然高于阈值,断路器再次进入打开状态。 |
minimum-number-of-calls |
在每个滑动窗口期样本数,配置断路器计算错误率或者慢调用率的最小调用数。比如设置为5意味着,在计算故障率之前,必须至少调用5次。如果只记录了4次,即使4次都失败了,断路器也不会进入到打开状态。 |
wait-duration-in-open-state |
从OPEN到HALF_OPEN状态需要等待的时间 |
按照COUNT_BASED(计数的滑动窗口)
导入依赖
<!--resilience4j-circuitbreaker-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId>
</dependency>
<!-- 由于断路保护等需要AOP实现,所以必须导入AOP包 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>配置resilience4j
server:
port: 80
spring:
application:
name: cloud-consumer-openfeign-order
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}
openfeign:
client:
config:
default:
#cloud-payment-service:
#连接超时时间,为避免演示出错,讲解完本次内容后设置为20秒
connectTimeout: 20000
#读取超时时间,为避免演示出错,讲解完本次内容后设置为20秒
readTimeout: 20000
#开启httpclient5
httpclient:
hc5:
enabled: true
#开启压缩特性
compression:
request:
enabled: true
min-request-size: 2048
mime-types: text/xml,application/xml,application/json
response:
enabled: true
# 开启circuitbreaker和分组激活 spring.cloud.openfeign.circuitbreaker.enabled
circuitbreaker:
enabled: true
group:
enabled: true #没开分组永远不用分组的配置。精确优先、分组次之(开了分组)、默认最后
# feign日志以什么级别监控哪个接口
logging:
level:
com:
atguigu:
cloud:
apis:
PayFeignApi: debug
# Resilience4j CircuitBreaker 按照次数:COUNT_BASED 的例子
# 6次访问中当执行方法的失败率达到50%时CircuitBreaker将进入开启OPEN状态(保险丝跳闸断电)拒绝所有请求。
# 等待5秒后,CircuitBreaker 将自动从开启OPEN状态过渡到半开HALF_OPEN状态,允许一些请求通过以测试服务是否恢复正常。
# 如还是异常CircuitBreaker 将重新进入开启OPEN状态;如正常将进入关闭CLOSE闭合状态恢复正常处理请求。
resilience4j:
circuitbreaker:
configs:
default:
failureRateThreshold: 50 #设置50%的调用失败时打开断路器,超过失败请求百分⽐CircuitBreaker变为OPEN状态。
slidingWindowType: COUNT_BASED # 滑动窗口的类型
slidingWindowSize: 6 #滑动窗⼝的⼤⼩配置COUNT_BASED表示6个请求,配置TIME_BASED表示6秒
minimumNumberOfCalls: 6 #断路器计算失败率或慢调用率之前所需的最小样本(每个滑动窗口周期)。如果minimumNumberOfCalls为10,则必须最少记录10个样本,然后才能计算失败率。如果只记录了9次调用,即使所有9次调用都失败,断路器也不会开启。
automaticTransitionFromOpenToHalfOpenEnabled: true # 是否启用自动从开启状态过渡到半开状态,默认值为true。如果启用,CircuitBreaker将自动从开启状态过渡到半开状态,并允许一些请求通过以测试服务是否恢复正常
waitDurationInOpenState: 5s #从OPEN到HALF_OPEN状态需要等待的时间
permittedNumberOfCallsInHalfOpenState: 2 #半开状态允许的最大请求数,默认值为10。在半开状态下,CircuitBreaker将允许最多permittedNumberOfCallsInHalfOpenState个请求通过,如果其中有任何一个请求失败,CircuitBreaker将重新进入开启状态。
recordExceptions:
- java.lang.Exception
instances:
cloud-payment-service:
baseConfig: default骚戴理解:这里的几个参数要配合在一起去理解,以下的n表示的是对应参数的配置
- slidingWindowSize表示统计最近的n个请求的失败情况(如上slidingWindowSize的配置,那这里的n就是6),如果失败率大于failureRateThreshold配置的百分比就会开启断路器,需要注意这个统计的最小样本数是minimumNumberOfCalls的配置,如果没达到这个数量断路器是不会起作用的
- 还要注意permittedNumberOfCallsInHalfOpenState配置的参数,如果在这个范围内有任何一个请求失败了又会重新打开断路器,我一开始以为是计算他的失败率!这里特别注意!
- recordExceptions配置的参数表示CircuitBreaker 会记录 java.lang.Exception这种异常类型的发生情况(可以配置多个)。当被调用的方法抛出这些异常时,CircuitBreaker 会将异常视为失败的调用,从而影响断路器的状态
- 我感觉就是slidingWindowSize不太好理解,看到下面的两个图片就很好理解了


使用@CircuitBreaker实现熔断
package com.atguigu.cloud.controller;
import com.atguigu.cloud.apis.PayFeignApi;
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
/
* @auther zzyy
* @create 2023-11-13 14:54
* Resilience4j CircuitBreaker 的例子
*/
@RestController
public class OrderCircuitController
{
@Resource
private PayFeignApi payFeignApi;
@GetMapping(value = "/feign/pay/circuit/{id}")
@CircuitBreaker(name = "cloud-payment-service", fallbackMethod = "myCircuitFallback")
public String myCircuitBreaker(@PathVariable("id") Integer id)
{
return payFeignApi.myCircuit(id);
}
//myCircuitFallback就是服务降级后的兜底处理方法
public String myCircuitFallback(Integer id,Throwable t) {
// 这里是容错处理逻辑,返回备用结果
return "myCircuitFallback,系统繁忙,请稍后再试-----/(ㄒoㄒ)/~~";
}
}骚戴理解:这里是订单服务通过Feign去调用支付服务,在订单服务的接口里面使用这个 @CircuitBreaker(name = "cloud-payment-service"来在指定调用支付服务的服务名称cloud-payment-service,这个要和consul配置的服务名称一致,注意不是在支付服务的接口上面加@CircuitBreaker!
按照TIME_BASED(时间的滑动窗口)
实现原理

导入依赖
<!--resilience4j-circuitbreaker-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId>
</dependency>
<!-- 由于断路保护等需要AOP实现,所以必须导入AOP包 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>配置resilience4j
server:
port: 80
spring:
application:
name: cloud-consumer-openfeign-order
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}
openfeign:
client:
config:
default:
#cloud-payment-service:
#连接超时时间,为避免演示出错,讲解完本次内容后设置为20秒
connectTimeout: 20000
#读取超时时间,为避免演示出错,讲解完本次内容后设置为20秒
readTimeout: 20000
#开启httpclient5
httpclient:
hc5:
enabled: true
#开启压缩特性
compression:
request:
enabled: true
min-request-size: 2048
mime-types: text/xml,application/xml,application/json
response:
enabled: true
#开启circuitbreaker和分组激活
circuitbreaker:
enabled: true
group:
enabled: true #没开分组永远不用分组的配置。精确优先、分组次之(开了分组)、默认最后
# feign日志以什么级别监控哪个接口
logging:
level:
com:
atguigu:
cloud:
apis:
PayFeignApi: debug
# Resilience4j CircuitBreaker 按照时间:TIME_BASED 的例子
resilience4j:
timelimiter:
configs:
default:
timeout-duration: 10s #神坑的位置,timelimiter 默认限制远程1s,超于1s就超时异常,配置了降级,就走降级逻辑
circuitbreaker:
configs:
default:
failureRateThreshold: 50 #设置50%的调用失败时打开断路器,超过失败请求百分⽐CircuitBreaker变为OPEN状态。
slowCallDurationThreshold: 2s #慢调用时间阈值,高于这个阈值的视为慢调用并增加慢调用比例。
slowCallRateThreshold: 30 #慢调用百分比峰值,断路器把调用时间⼤于slowCallDurationThreshold,视为慢调用,当慢调用比例高于阈值,断路器打开,并开启服务降级
slidingWindowType: TIME_BASED # 滑动窗口的类型
slidingWindowSize: 2 #滑动窗口的大小配置,配置TIME_BASED表示2秒
minimumNumberOfCalls: 2 #断路器计算失败率或慢调用率之前所需的最小样本(每个滑动窗口周期)。
permittedNumberOfCallsInHalfOpenState: 2 #半开状态允许的最大请求数,默认值为10。
waitDurationInOpenState: 5s #从OPEN到HALF_OPEN状态需要等待的时间
recordExceptions:
- java.lang.Exception
instances:
cloud-payment-service:
baseConfig: default 骚戴理解: timeout-duration注意这个坑!根据时间的滑动窗口实现的熔断器是有三个捆绑参数的,在slidingWindowSize配置的n秒内,slowCallDurationThreshold定义慢调用的时间,超过这个时间的就会被认为是慢调用,然后就被增加慢调用的比例,如果比例大于slowCallRateThreshold配置的参数,那就会开启断路器。这里我一开始觉得如果按这个逻辑,那failureRateThreshold不就是多余没用的吗?这个是错误的!
因为两者的作用是不同的。slowCallRateThreshold 是用于度量调用中慢速的响应时间,而 failureRateThreshold 则是度量整体调用中的失败率。它们可以同时存在,用于断路器的不同类型的保护。因此,两个参数都是有用的,并且在不同情况下都可以触发断路器的打开

总结
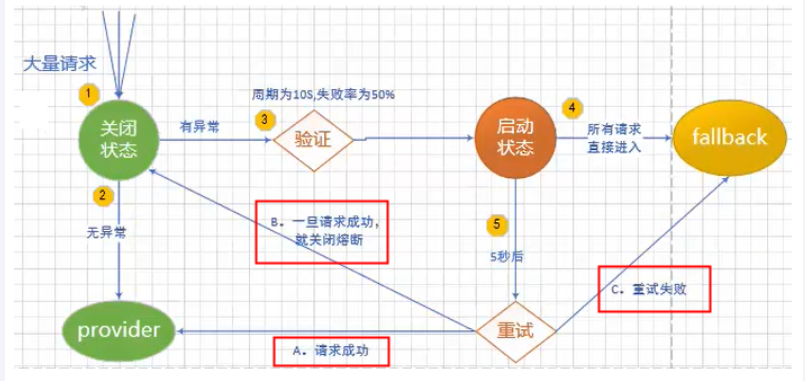
- 当满足一定的峰值和失败率达到一定条件后,断路器将会进入OPEN状态(保险丝跳闸),服务熔断
- 当OPEN的时候,所有请求都不会调用主业务逻辑方法,而是直接走fallbackmetnod兜底背锅方法,服务降级
- 断路器开启或者关闭的条件B一段时间之后,这个时候断路器会从OPEN进入到HALF_OPEN半开状态,会放几个请求过去探探链路是否通?如成功,断路器会关闭CLOSE(类似保险丝闭合,恢复可用);
- 如失败,继续开启。
- 重复上述。
个人建议不要混合用,推荐按照调用次数count_based
隔离(BulkHead)
作用
简单说就是限并发、依赖隔离、负载保护:用来限制对于下游服务的最大并发数量的限制
- 避免故障扩散:当一个服务失败或变慢时,隔离可防止该服务的问题通过整个系统传播,从而提高系统的稳定性和可用性。
- 资源限制:通过对并发请求的限制,隔离可以确保每个服务或功能所需的资源不会被其他服务的问题所耗尽。
- 提高系统容错性:通过实现隔离,可以避免在高负载或故障情况下影响整个系统的稳定性,从而提高系统的容错能力。
- 性能管理:通过隔离不同资源的使用,可以更好地管理系统的性能和资源分配,确保重要功能和关键服务的优先级得到保障。
实现
Resilience4j提供了如下两种隔离的实现方式,可以限制并发执行的数量
- 实现SemaphoreBulkhead(信号量舱壁)
- 实现FixedThreadPoolBulkhead(固定线程池舱壁)
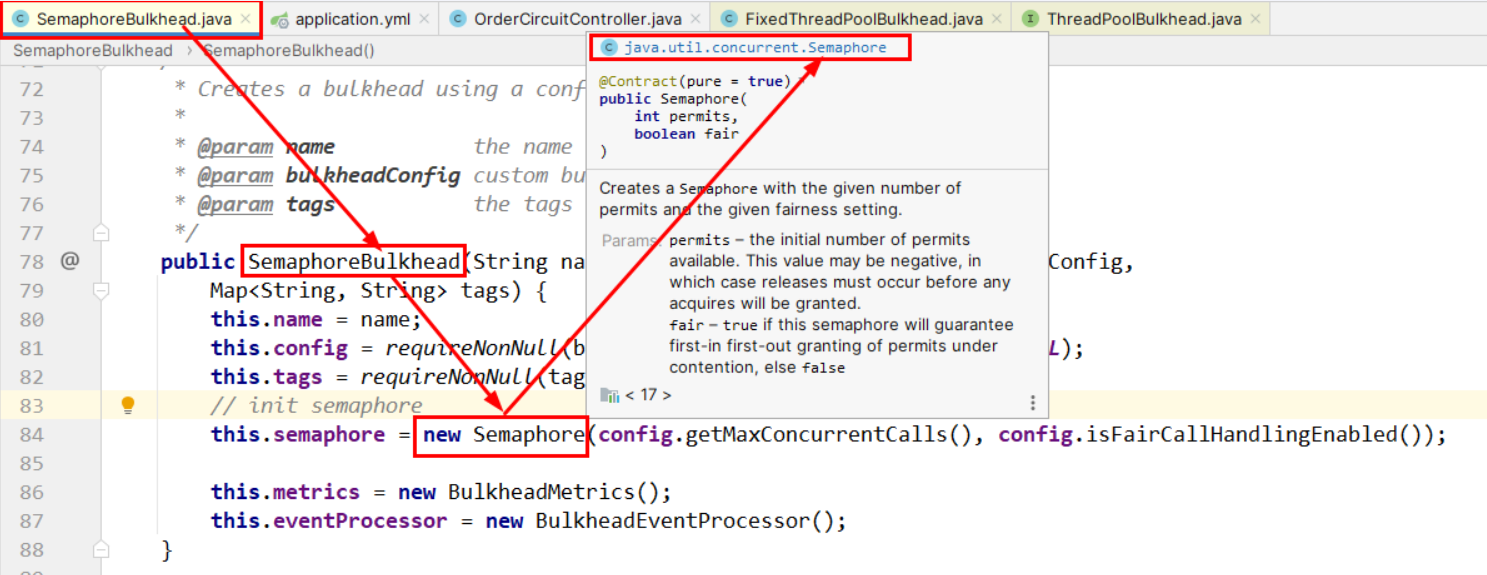
实现SemaphoreBulkhead(信号量舱壁)
信号量舱壁(SemaphoreBulkhead)原理
当信号量有空闲时,进入系统的请求会直接获取信号量并开始业务处理。
当信号量全被占用时,接下来的请求将会进入阻塞状态,SemaphoreBulkhead提供了一个阻塞计时器,
如果阻塞状态的请求在阻塞计时内无法获取到信号量则系统会拒绝这些请求。
若请求在阻塞计时内获取到了信号量,那将直接获取信号量并执行相应的业务处理。
导入依赖
<!--resilience4j-bulkhead-->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-bulkhead</artifactId>
</dependency>配置Yml
server:
port: 80
spring:
application:
name: cloud-consumer-openfeign-order
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}
openfeign:
client:
config:
default:
#cloud-payment-service:
#连接超时时间,为避免演示出错,讲解完本次内容后设置为20秒
connectTimeout: 20000
#读取超时时间,为避免演示出错,讲解完本次内容后设置为20秒
readTimeout: 20000
#开启httpclient5
httpclient:
hc5:
enabled: true
#开启压缩特性
compression:
request:
enabled: true
min-request-size: 2048
mime-types: text/xml,application/xml,application/json
response:
enabled: true
#开启circuitbreaker和分组激活
circuitbreaker:
enabled: true
group:
enabled: true #没开分组永远不用分组的配置。精确优先、分组次之(开了分组)、默认最后
# feign日志以什么级别监控哪个接口
logging:
level:
com:
atguigu:
cloud:
apis:
PayFeignApi: debug
####resilience4j bulkhead 的例子
resilience4j:
bulkhead:
configs:
default:
maxConcurrentCalls: 2 # 隔离允许并发线程执行的最大数量
maxWaitDuration: 1s # 当达到并发调用数量时,新的线程的阻塞时间,我只愿意等待1秒,过时不候进舱壁兜底fallback
instances:
cloud-payment-service:
baseConfig: default
timelimiter:
configs:
default:
timeout-duration: 20s使用@Bulkhead隔离
/
*(船的)舱壁,隔离
* @param id
* @return
*/
@GetMapping(value = "/feign/pay/bulkhead/{id}")
@Bulkhead(name = "cloud-payment-service",fallbackMethod = "myBulkheadFallback",type = Bulkhead.Type.SEMAPHORE)
public String myBulkhead(@PathVariable("id") Integer id)
{
return payFeignApi.myBulkhead(id);
}
public String myBulkheadFallback(Throwable t)
{
return "myBulkheadFallback,隔板超出最大数量限制,系统繁忙,请稍后再试-----/(ㄒoㄒ)/~~";
}
骚戴理解:type = Bulkhead.Type.SEMAPHORE表示使用信号量实现隔离,上面配置文件的两个核心配置参数maxConcurrentCalls和maxWaitDuration,maxConcurrentCalls限制最大的并发请求数量,如果超过这个数量就阻塞等待,maxWaitDuration就是设置等待时间,如果超过的并发请求数量愿意等待maxWaitDuration设置的等待时间那就等着,不愿意的话就直接降级,跳到fallbackMethod指定的降级方法去
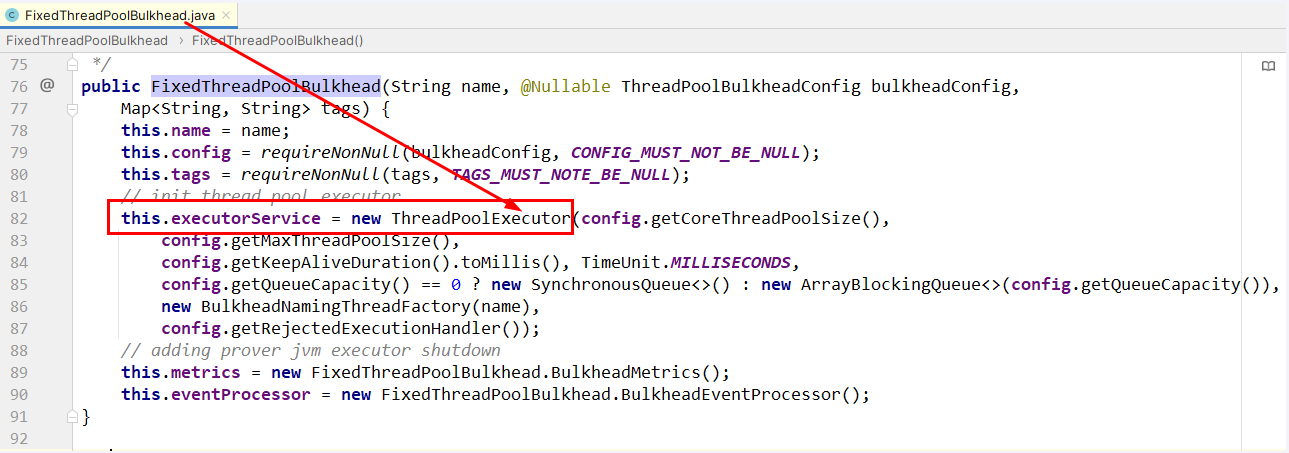
实现FixedThreadPoolBulkhead(固定线程池舱壁)
固定线程池舱壁(FixedThreadPoolBulkhead)原理
FixedThreadPoolBulkhead的功能与SemaphoreBulkhead一样也是用于限制并发执行的次数的,但是二者的实现原理存在差别而且表现效果也存在细微的差别。FixedThreadPoolBulkhead使用一个固定线程池和一个等待队列来实现舱壁。
当线程池中存在空闲时,则此时进入系统的请求将直接进入线程池开启新线程或使用空闲线程来处理请求。
当线程池中无空闲时时,接下来的请求将进入等待队列,
- 若等待队列仍然无剩余空间时接下来的请求将直接被拒绝,
- 在队列中的请求等待线程池出现空闲时,将进入线程池进行业务处理。
另外:ThreadPoolBulkhead只对CompletableFuture方法有效,所以我们必创建返回CompletableFuture类型的方法
导入依赖
<!--resilience4j-bulkhead-->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-bulkhead</artifactId>
</dependency>配置Yml
server:
port: 80
spring:
application:
name: cloud-consumer-openfeign-order
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}
openfeign:
client:
config:
default:
#cloud-payment-service:
#连接超时时间,为避免演示出错,讲解完本次内容后设置为20秒
connectTimeout: 20000
#读取超时时间,为避免演示出错,讲解完本次内容后设置为20秒
readTimeout: 20000
#开启httpclient5
httpclient:
hc5:
enabled: true
#开启压缩特性
compression:
request:
enabled: true
min-request-size: 2048
mime-types: text/xml,application/xml,application/json
response:
enabled: true
#开启circuitbreaker和分组激活
circuitbreaker:
enabled: true
# group:
# enabled: true # 演示Bulkhead.Type.THREADPOOL时spring.cloud.openfeign.circuitbreaker.group.enabled
设为false新启线程和原来主线程脱离了。
# feign日志以什么级别监控哪个接口
logging:
level:
com:
atguigu:
cloud:
apis:
PayFeignApi: debug
####resilience4j bulkhead -THREADPOOL的例子
resilience4j:
timelimiter:
configs:
default:
timeout-duration: 10s #timelimiter默认限制远程1s,超过报错不好演示效果所以加上10秒
thread-pool-bulkhead:
configs:
default:
core-thread-pool-size: 1 #配置核心线程池大小
max-thread-pool-size: 1 #配置最大线程池大小
queue-capacity: 1 #配置队列的容量
instances:
cloud-payment-service:
baseConfig: default
# spring.cloud.openfeign.circuitbreaker.group.enabled 请设置为false 新启线程和原来主线程脱离骚戴理解:特别注意spring.cloud.openfeign.circuitbreaker.group.enabled 请设置为false 新启线程和原来主线程脱离,spring.cloud.openfeign.circuitbreaker.group.enabled的意思如下所示:
在Spring Cloud OpenFeign中,spring.cloud.openfeign.circuitbreaker.group.enabled是一个配置属性,用于启用或禁用Feign客户端中的断路器分组功能。
断路器分组是一种将特定服务的断路器进行分组管理的功能。当启用了断路器分组后,可以为不同的服务配置不同的断路器属性,比如失败率阈值、慢调用阈值等,从而更精细地控制各个服务的熔断行为。
默认情况下,Feign客户端的断路器是针对每个服务的。但通过将spring.cloud.openfeign.circuitbreaker.group.enabled设置为true,可以启用断路器分组功能,从而实现对不同服务的断路器进行分组管理。
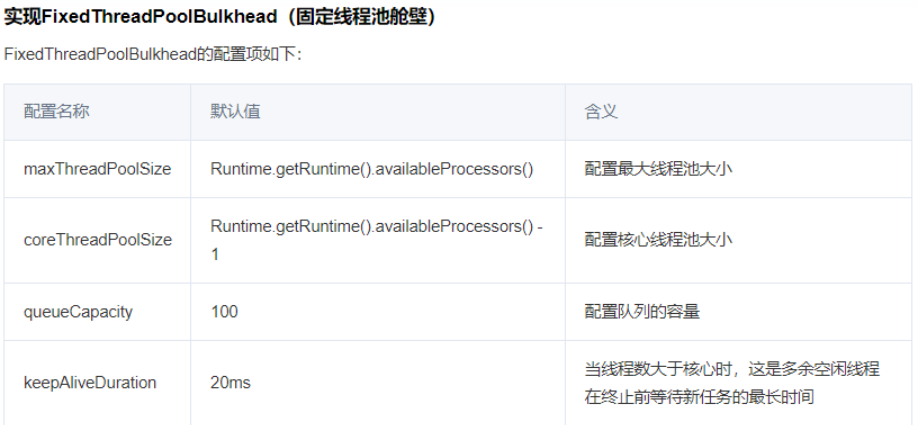

骚戴理解:可以看到和核心线程没啥关系,最大线程+等待队列的线程容纳数就是最大的请求并发数,超过了就直接隔离了
使用@Bulkhead隔离
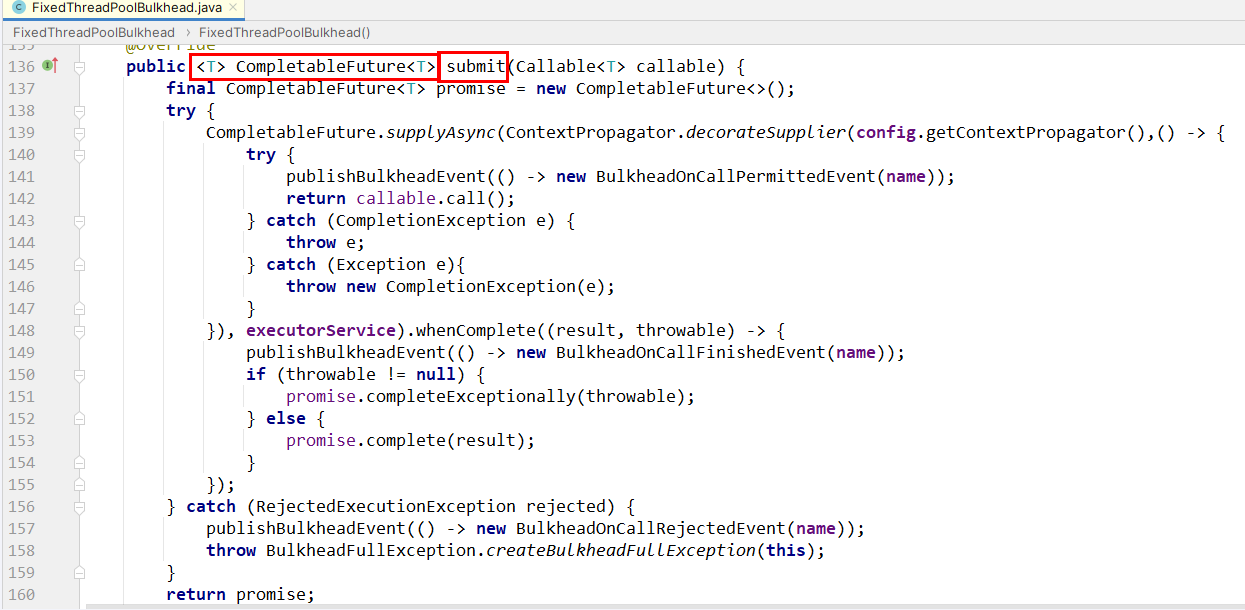
/
* (船的)舱壁,隔离,THREADPOOL
* @param id
* @return
*/
@GetMapping(value = "/feign/pay/bulkhead/{id}")
@Bulkhead(name = "cloud-payment-service",fallbackMethod = "myBulkheadPoolFallback",type = Bulkhead.Type.THREADPOOL)
public CompletableFuture<String> myBulkheadTHREADPOOL(@PathVariable("id") Integer id)
{
System.out.println(Thread.currentThread().getName()+"\t"+"enter the method!!!");
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
System.out.println(Thread.currentThread().getName()+"\t"+"exist the method!!!");
return CompletableFuture.supplyAsync(() -> payFeignApi.myBulkhead(id) + "\t" + " Bulkhead.Type.THREADPOOL");
}
public CompletableFuture<String> myBulkheadPoolFallback(Integer id,Throwable t)
{
return CompletableFuture.supplyAsync(() -> "Bulkhead.Type.THREADPOOL,系统繁忙,请稍后再试-----/(ㄒoㄒ)/~~");
}骚戴理解:ThreadPoolBulkhead只对CompletableFuture方法有效,所以我们必创建返回CompletableFuture类型的方法,可以看到上面的写法是return CompletableFuture.supplyAsync(() ->xxx),type = Bulkhead.Type.THREADPOOL意味着使用线程池实现隔离

限流(RateLimiter)
限流 就是限制最大访问流量。系统能提供的最大并发是有限的,同时来的请求又太多,就需要限流。 比如商城秒杀业务,瞬时大量请求涌入,服务器忙不过就只好排队限流了,和去景点排队买票和去医院办理业务排队等号道理相同。
所谓限流,就是通过对并发访问/请求进行限速,或者对一个时间窗口内的请求进行限速,以保护应用系统,一旦达到限制速率则可以拒绝服务、排队或等待、降级等处理。
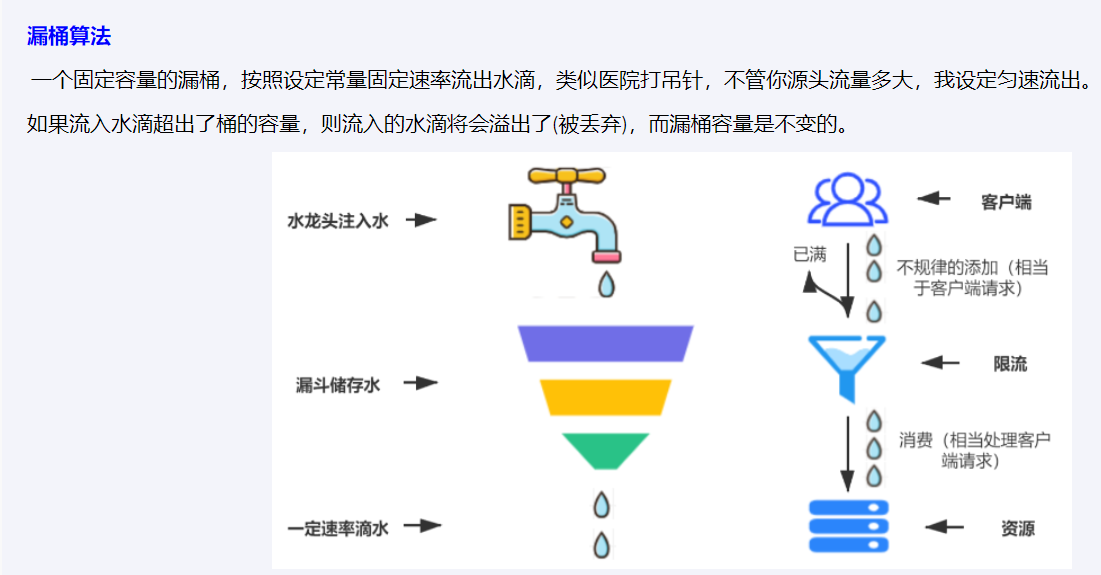
常见限流算法
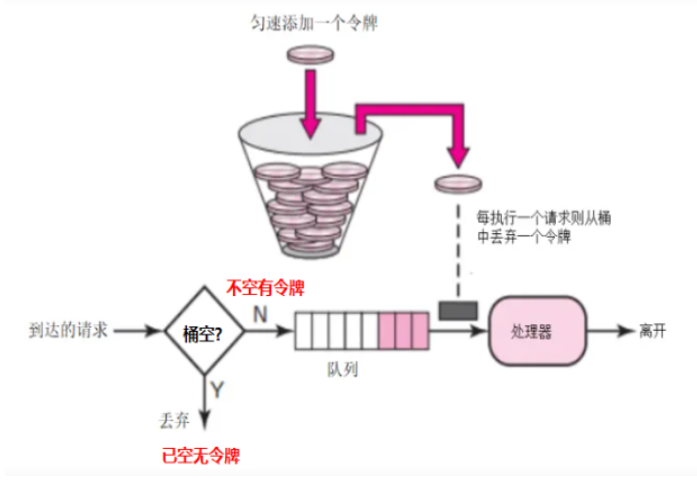
1.漏斗算法(Leaky Bucket)

2.令牌桶算法(Token Bucket)
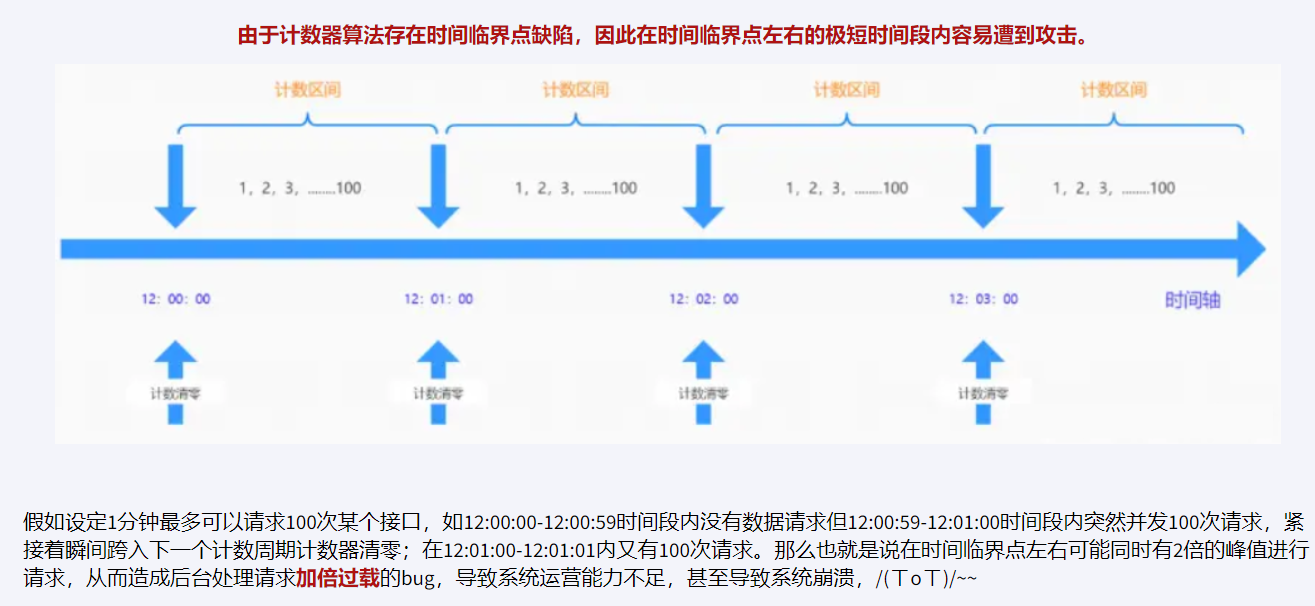
3.滚动时间窗(tumbling time window)

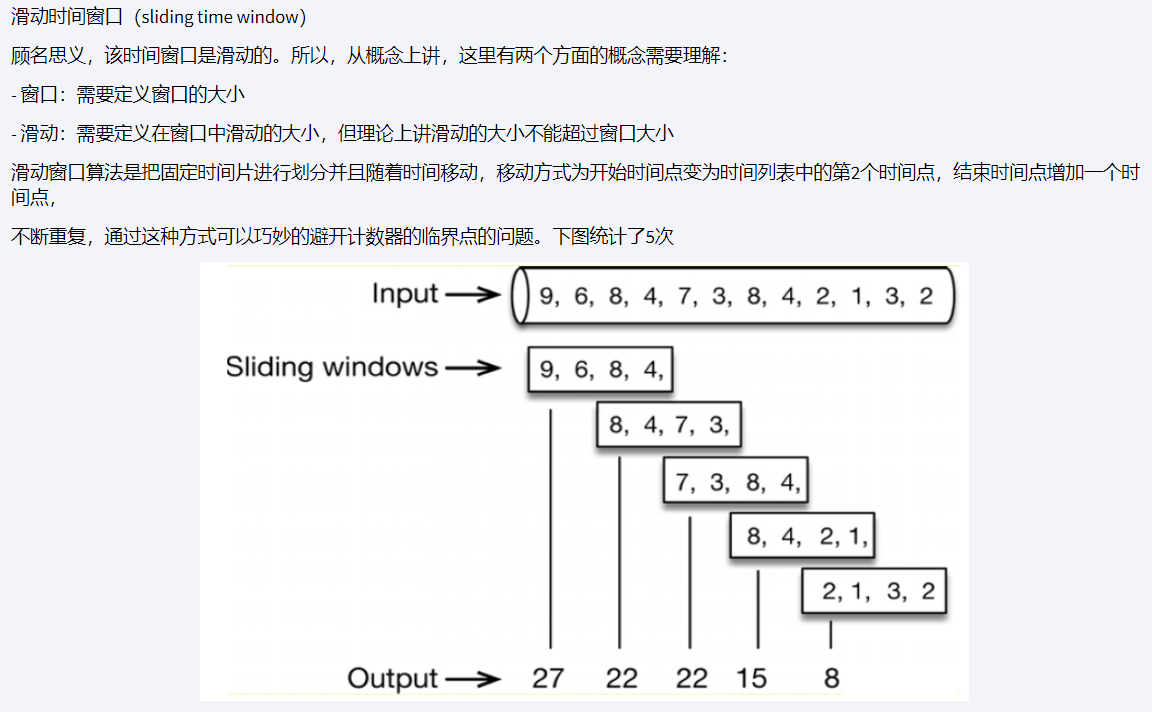
4.滑动时间窗口(sliding time window)
导入依赖
<!--resilience4j-ratelimiter-->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-ratelimiter</artifactId>
</dependency>配置ratelimiter
####resilience4j ratelimiter 限流的例子
resilience4j:
ratelimiter:
configs:
default:
limitForPeriod: 2 #在一次刷新周期内,允许执行的最大请求数
limitRefreshPeriod: 1s # 限流器每隔limitRefreshPeriod刷新一次,将允许处理的最大请求数量重置为limitForPeriod
timeout-duration: 1 # 线程等待权限的默认等待时间
instances:
cloud-payment-service:
baseConfig: default骚戴理解:limitRefreshPeriod就是定义刷新周期(这个刷新周期一到就会将允许处理的最大请求数量重置为limitForPeriod),在这个周期内最大请求数为limitForPeriod,如果超过了就等,等多久由 timeout-duration说了算,如果等了这timeout-duration这么久还是没轮到他就会被拒绝
- limitForPeriod:在一次刷新周期内,允许执行的最大请求数。换句话说,这是在 limitRefreshPeriod 时间内允许通过的最大请求数。
- limitRefreshPeriod:限流器每隔 limitRefreshPeriod 时间刷新一次,在刷新时将允许处理的最大请求数重置为 limitForPeriod。这个参数指定了限流器的刷新周期,即在多长时间后,限流器将重置已经处理的请求数。
- timeout-duration: 线程等待权限的默认等待时间。如果一个请求被限流器拒绝了,该请求将会被放入等待队列中。这个参数确定了线程在等待权限时的默认超时时间。如果在这个时间内未能获取到执行权限,请求将会被拒绝执行。
使用@RateLimiter限流
@GetMapping(value = "/feign/pay/ratelimit/{id}")
@RateLimiter(name = "cloud-payment-service",fallbackMethod = "myRatelimitFallback")
public String myBulkhead(@PathVariable("id") Integer id)
{
return payFeignApi.myRatelimit(id);
}
public String myRatelimitFallback(Integer id,Throwable t)
{
return "你被限流了,禁止访问/(ㄒoㄒ)/~~";
}
分布式链路追踪-Sleuth(Micrometer)+ZipKin
分布式链路跟踪产生的由来
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。
在分布式与微服务场景下,我们需要解决如下问题:
- 在大规模分布式与微服务集群下,如何实时观测系统的整体调用链路情况。
- 在大规模分布式与微服务集群下,如何快速发现并定位到问题。
- 在大规模分布式与微服务集群下,如何尽可能精确的判断故障对系统的影响范围与影响程度。
- 在大规模分布式与微服务集群下,如何尽可能精确的梳理出服务之间的依赖关系,并判断出服务之间的依赖关系是否合理。
- 在大规模分布式与微服务集群下,如何尽可能精确的分析整个系统调用链路的性能与瓶颈点。
- 在大规模分布式与微服务集群下,如何尽可能精确的分析系统的存储瓶颈与容量规划。
上述问题就是我们的落地议题答案:
分布式链路追踪技术要解决的问题,分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
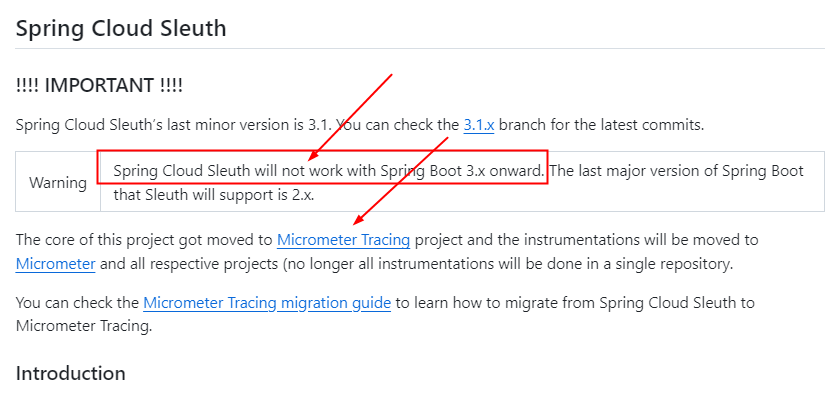
新一代Spring Cloud Sleuth: Micrometer
Sleuth官宣改头换面,Sleuth未来替换方案Micrometer Tracing,Sleuth能用,但是要注意不能支持springboot3.0+以上的版本了,Spring Cloud Sleuth(micrometer)提供了一套完整的分布式链路追踪(Distributed Tracing)解决方案且兼容支持了zipkin展现
将一次分布式请求还原成调用链路,进行日志记录和性能监控,并将一次分布式请求的调用情况集中web展示

分布式链路追踪原理
那么一条链路追踪会在每个服务调用的时候加上Trace ID 和 Span ID,链路通过TraceId唯一标识,Span标识发起的请求信息,各span通过parent id 关联起来 (Span:表示调用链路来源,通俗的理解span就是一次请求信息)

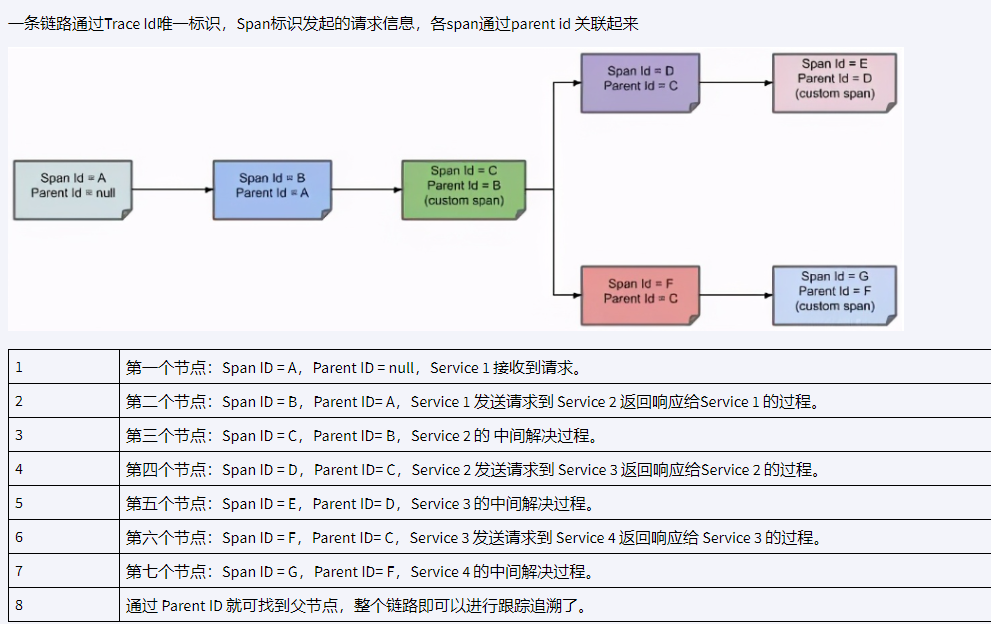
骚戴理解:简单来说就是一条链路追踪会在每个服务调用的时候加上Trace ID 和 Span ID,Trace ID就是用来表示这些是一条链路的,是一组的标记,而 Span ID是每个请求过程中每个服务的id,通过Span里的parent id 可以标记这个请求的上一级是什么,这样就可以知道完整的依赖关系和链路关系
Zipkin
Zipkin是一种分布式链路跟踪系统图形化的工具,Zipkin 是 Twitter 开源的分布式跟踪系统,能够收集微服务运行过程中的实时调用链路信息,并能够将这些调用链路信息展示到Web图形化界面上供开发人员分析,开发人员能够从ZipKin中分析出调用链路中的性能瓶颈,识别出存在问题的应用程序,进而定位问题和解决问题。
骚戴理解:Zipkin需要去下载一个jar包并运行它才行
java -jar zipkin-server-3.0.0-rc0-exec.jar
Micrometer+ZipKin搭建链路监控案例步骤
总体父工程pom导入依赖
<!--micrometer-tracing-bom导入链路追踪版本中心 1-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bom</artifactId>
<version>${micrometer-tracing.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--micrometer-tracing指标追踪 2-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing</artifactId>
<version>${micrometer-tracing.version}</version>
</dependency>
<!--micrometer-tracing-bridge-brave适配zipkin的桥接包 3-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-brave</artifactId>
<version>${micrometer-tracing.version}</version>
</dependency>
<!--micrometer-observation 4-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-observation</artifactId>
<version>${micrometer-observation.version}</version>
</dependency>
<!--feign-micrometer 5-->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-micrometer</artifactId>
<version>${feign-micrometer.version}</version>
</dependency>
<!--zipkin-reporter-brave 6-->
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter-brave</artifactId>
<version>${zipkin-reporter-brave.version}</version>
</dependency>由于Micrometer Tracing是一个门面工具自身并没有实现完整的链路追踪系统,具体的链路追踪另外需要引入的是第三方链路追踪系统的依赖:
1 |
micrometer-tracing-bom |
导入链路追踪版本中心,体系化说明 |
2 |
micrometer-tracing |
指标追踪 |
3 |
micrometer-tracing-bridge-brave |
一个Micrometer模块,用于与分布式跟踪工具 Brave 集成,以收集应用程序的分布式跟踪数据。Brave是一个开源的分布式跟踪工具,它可以帮助用户在分布式系统中跟踪请求的流转,它使用一种称为"跟踪上下文"的机制,将请求的跟踪信息存储在请求的头部,然后将请求传递给下一个服务。在整个请求链中,Brave会将每个服务处理请求的时间和其他信息存储到跟踪数据中,以便用户可以了解整个请求的路径和性能。 |
4 |
micrometer-observation |
一个基于度量库 Micrometer的观测模块,用于收集应用程序的度量数据。 |
5 |
feign-micrometer |
一个Feign HTTP客户端的Micrometer模块,用于收集客户端请求的度量数据。 |
6 |
zipkin-reporter-brave |
一个用于将 Brave 跟踪数据报告到Zipkin 跟踪系统的库。 |
补充包:spring-boot-starter-actuator SpringBoot框架的一个模块用于监视和管理应用程序
调用者和提供者导入依赖
<!--micrometer-tracing指标追踪 1-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing</artifactId>
</dependency>
<!--micrometer-tracing-bridge-brave适配zipkin的桥接包 2-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-brave</artifactId>
</dependency>
<!--micrometer-observation 3-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-observation</artifactId>
</dependency>
<!--feign-micrometer 4-->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-micrometer</artifactId>
</dependency>
<!--zipkin-reporter-brave 5-->
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter-brave</artifactId>
</dependency>骚戴理解:可以注意到没有引用micrometer-tracing-bom依赖,因为这个是放在父工程的,类似于大脑中心
修改yml配置文件
server:
port: 8001
# ==========applicationName + druid-mysql8 driver===================
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db2024?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&rewriteBatchedStatements=true&allowPublicKeyRetrieval=true
username: root
password: 123456
profiles:
active: dev # 多环境配置加载内容dev/prod,不写就是默认default配置
# ========================mybatis===================
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.atguigu.cloud.entities
configuration:
map-underscore-to-camel-case: true
# ========================zipkin===================
management:
zipkin:
tracing:
endpoint: http://localhost:9411/api/v2/spans
tracing:
sampling:
probability: 1.0 #采样率默认为0.1(0.1就是10次只能有一次被记录下来),值越大收集越及时。骚戴理解:tracing.sampling.probability指定了采样的概率。在分布式跟踪系统中,为了减少对性能的影响,不会对所有的请求进行跟踪。相反,只会选择一个子集进行跟踪。probability参数是一个介于0到1之间的值,表示采样的概率。例如,如果设置为1.0表示对100%的请求进行采样,而0.1表示对10%的请求进行采样。因此,设置为1.0表示在跟踪系统中开启了对所有请求的跟踪,这意味着每个请求都将生成跟踪数据。
tracing.endpoint 指定了 Zipkin 服务器的地址,用于接收跟踪数据。在这个例子中,设置为http://localhost:9411/api/v2/spans,表示跟踪数据将会发送至本地的 Zipkin 服务的 /api/v2/spans 接口
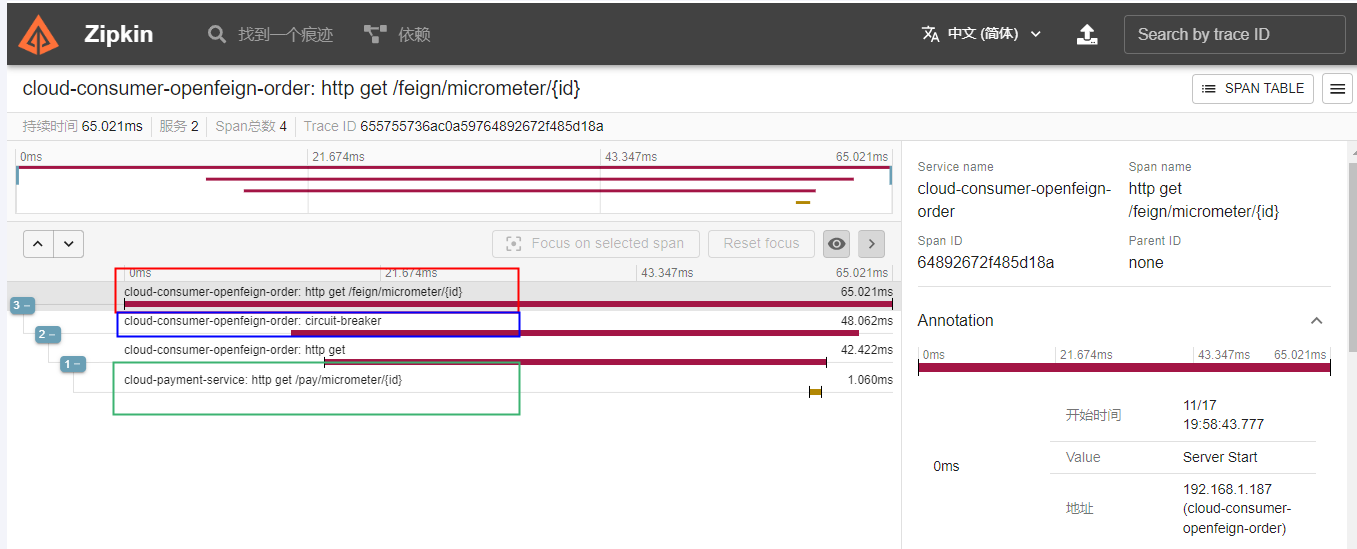
测试结果
首先要把ZipKin的jar包跑起来,然后启动服务把服务注册到Consul,当访问了某个接口后,可以访问 http://localhost:9411这个地址去zipkin看看链路过程
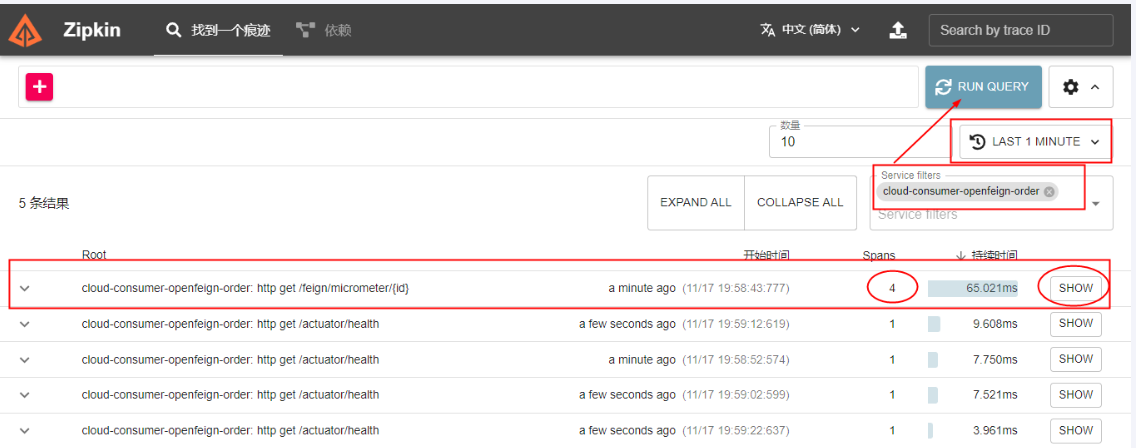
点击【SHOW】按钮查看

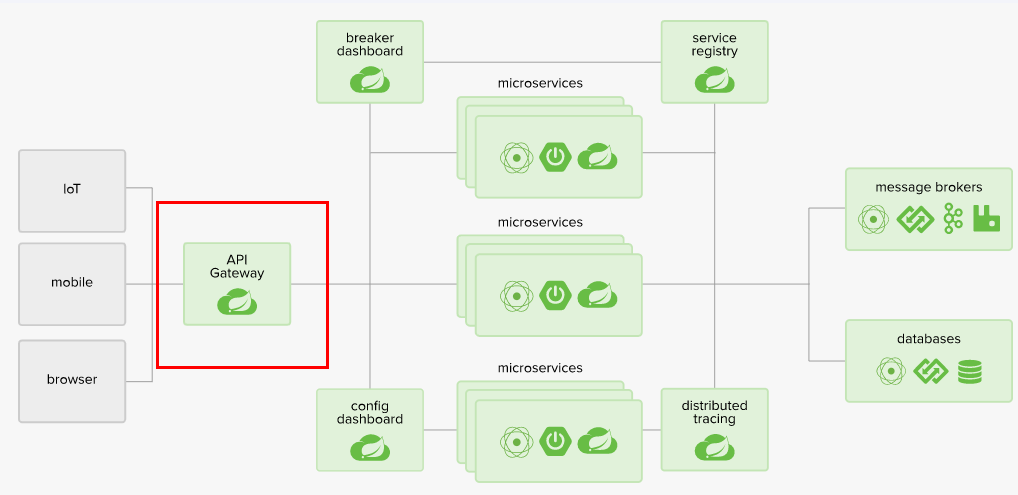
新一代网关-Gateway
Gateway概述
Gateway是在Spring生态系统之上构建的API网关服务,基于Spring6,Spring Boot 3和Project Reactor等技术。它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式,并为它们提供跨领域的关注点,例如:安全性、监控/度量和恢复能力。
Cloud全家桶中有个很重要的组件就是网关,在1.x版本中都是采用的Zuul网关;但在2.x版本中,zuul的升级一直跳票,SpringCloud最后自己研发了一个网关SpringCloud Gateway替代Zuul,那就是SpringCloud Gateway一句话:gateway是原zuul1.x版的替代
Gateway(网关)通常也被用作负载均衡器。在微服务架构中,Gateway的一个主要作用就是作为入口,为客户端程序提供服务路由和负载均衡的功能。
具体而言,Gateway可以根据路由配置,将收到的请求动态地路由到后端的多个实例上,从而分摊服务压力,提高整体系统的性能和稳定性。它可以进行基于负载情况的动态路由,将请求分发到不同的服务实例上,以实现负载均衡。
在网关中,通常会配置负载均衡算法,比如轮询、权重轮询、随机、最小连接数等,以使得请求在后端服务实例之间得到均衡分发。另外,Gateway本身会进行状态监控,及时剔除出现故障或不可用的实例,从而保证请求都能被分发到正常运行的服务实例上。

总结:Spring Cloud Gateway组件的核心是一系列的过滤器,通过这些过滤器可以将客户端发送的请求转发(路由)到对应的微服务。 Spring Cloud Gateway是加在整个微服务最前沿的防火墙和代理器,隐藏微服务结点IP端口信息,从而加强安全保护。Spring Cloud Gateway本身也是一个微服务,需要注册进服务注册中心。
作用
- 反向代理
- 鉴权
- 流量控制
- 熔断
- 日志监控
Gateway三大核心
在Spring Cloud Gateway中,有三个核心概念:Route(路由)、Predicate(断言)、Filter(过滤):
1. Route(路由):Route定义了请求应该被如何转发,可以理解为一条路线的定义。它定义了请求的转发规则,包括目标服务的地址、负载均衡规则、路径匹配规则等。通过定义Route,可以将请求映射到后端的一个或多个服务上。
2. Predicate(断言):Predicate用于匹配请求,当请求到达Gateway时,Predicate会判断这个请求是否满足某些条件,比如请求的路径、请求的头部信息、请求的参数等。如果请求满足Predicate的条件,才会进一步按照对应的Route进行转发。
3. Filter(过滤):Filter用于在请求被转发到目标服务之前或之后执行一些过滤操作。它可以用于修改请求和响应,实现请求过程中的日志记录、安全认证、流量控制、请求转发等功能。Gateway内置了多种不同用途的Filter,同时也支持自定义Filter。

web前端请求,通过一些匹配条件,定位到真正的服务节点。并在这个转发过程的前后,进行一些精细化控制。
predicate就是我们的匹配条件;filter就可以理解为一个无所不能的拦截器。有了这两个元素,再加上目标uri,就可以实现一个具体的路由了
Gateway工作流程
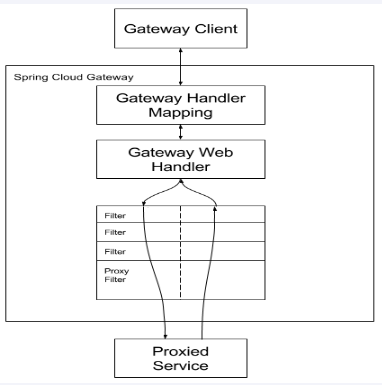
客户端向 Spring Cloud Gateway 发出请求。然后在 Gateway Handler Mapping 中找到与请求相匹配的路由,将其发送到 Gateway Web Handler。Handler 再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回。
过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(Pre)或之后(Post)执行业务逻辑。
在“pre”类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等;
在“post”类型的过滤器中可以做响应内容、响应头的修改,日志的输出,流量监控等有着非常重要的作用。
核心逻辑:路由转发+断言判断+执行过滤器链
入门配置
导入依赖
<!--gateway-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>修改Yml文件
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
// uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
// uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由骚戴理解:GateWay注册到Consul后就会根据配置文件里面配置的路由进行请求筛选了,这里需要注意的是要用uri: lb://cloud-payment-service 这种写法去指定路由地址的服务,不要像uri: http://localhost:8001这样直接写死了
注册到Consul
package com.atguigu.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
/
* @auther zzyy
* @create 2023-11-20 12:38
*/
@SpringBootApplication
@EnableDiscoveryClient //服务注册和发现
public class Main9527
{
public static void main(String[] args)
{
SpringApplication.run(Main9527.class,args);
}
}测试

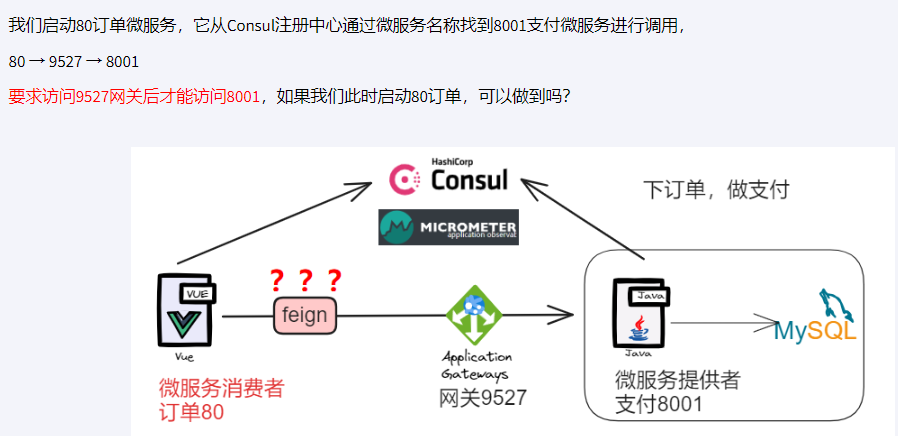
骚戴理解:如果是直接访问网关去调用微服务提供者的话就不需要配置啥,但是如果是通过消费者去调用网关,网关调用微服务提供者的话就需要根据情况来配,如果是不同家公司有外人,系统外访问,先找网关再服务,那就需要改一下OpenFeign的@FeignClient的value值为网关服务的名称,如果openFeign没有指定网关的话,那就会绕开网关的拦截,那网关的那些逻辑就不起作用了。但是如果是同一家公司自己人,系统内环境,直接找微服务就行了
Predicate断言(谓词)
Predicate用于匹配请求,Predicate接受一个输入参数返回一个布尔值。当请求到达Gateway时,Predicate会判断这个请求是否满足某些条件,比如请求的路径、请求的头部信息、请求的参数等。如果请求满足Predicate的条件,才会进一步按照对应的Route进行转发
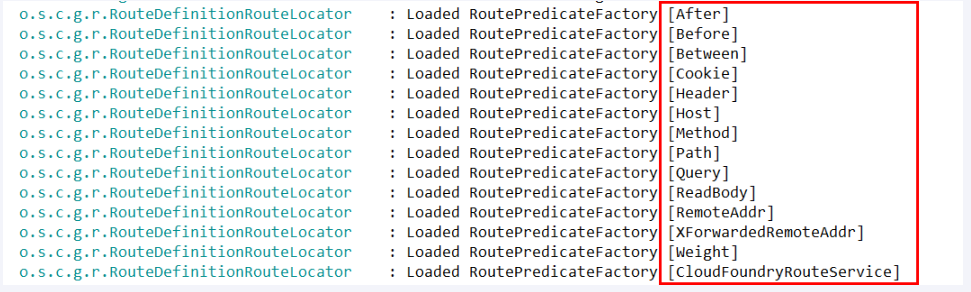
常用断言api
After Route Predicate
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由骚戴理解:- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]就是配置一个时间,然后Path定义的这些路径下的所有请求必须要在这个时间以后才能访问,这个时间的格式是根据下面的代码来获取的,然后根据需求去修改这个时间
package com.atguigu.test;
import java.time.ZoneId;
import java.time.ZonedDateTime;
/
* @auther zzyy
* @create 2019-12-02 17:37
*/
public class ZonedDateTimeDemo
{
public static void main(String[] args)
{
ZonedDateTime zbj = ZonedDateTime.now(); // 默认时区
System.out.println(zbj);
}
}Before Route Predicate
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-11-27T15:25:06.424566300+08:00[Asia/Shanghai] #超过规定时间不可访问骚戴理解:- Before=2023-11-27T15:25:06.424566300+08:00[Asia/Shanghai]表示在这个时间以前才能访问Path定义的这些路径
Between Route Predicate
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
#- Before=2023-11-20T17:58:13.586918800+08:00[Asia/Shanghai]
- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]Cookie Route Predicate
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-12-29T17:58:13.586918800+08:00[Asia/Shanghai]
#- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]
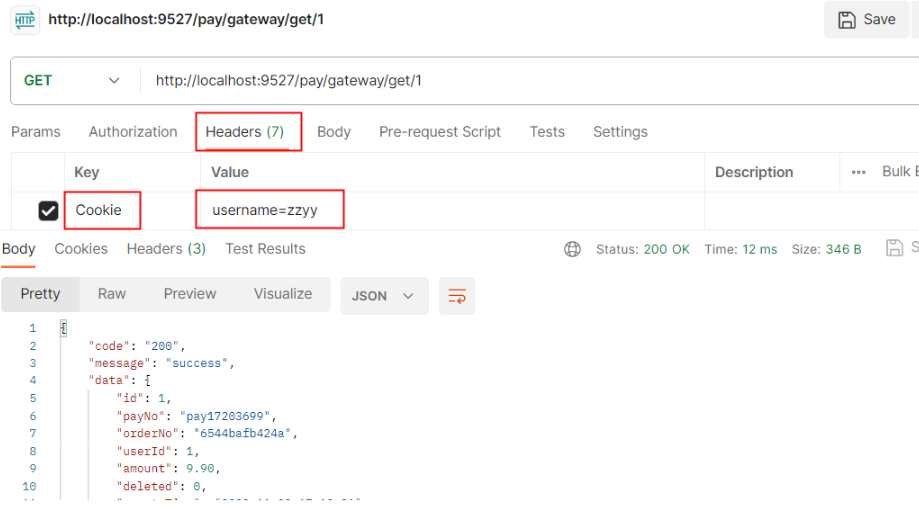
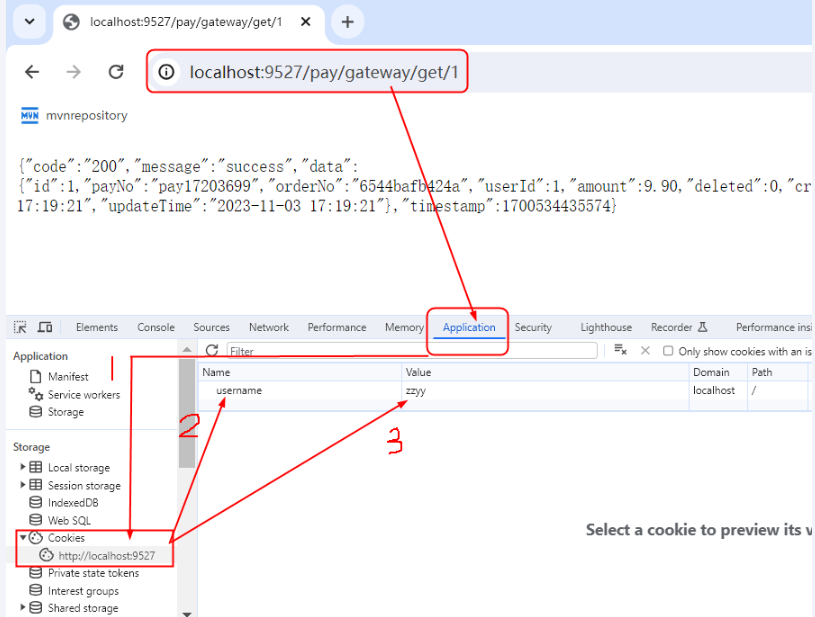
- Cookie=username,zzyy骚戴理解: - Cookie=username,zzyy表示Path定义的这些路径下的所有请求的Cookie里面必须有username这个key,并且这个key的值为zzyy,不然的话请求会被拦截掉
测试

Header Route Predicate
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-12-29T17:58:13.586918800+08:00[Asia/Shanghai]
#- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
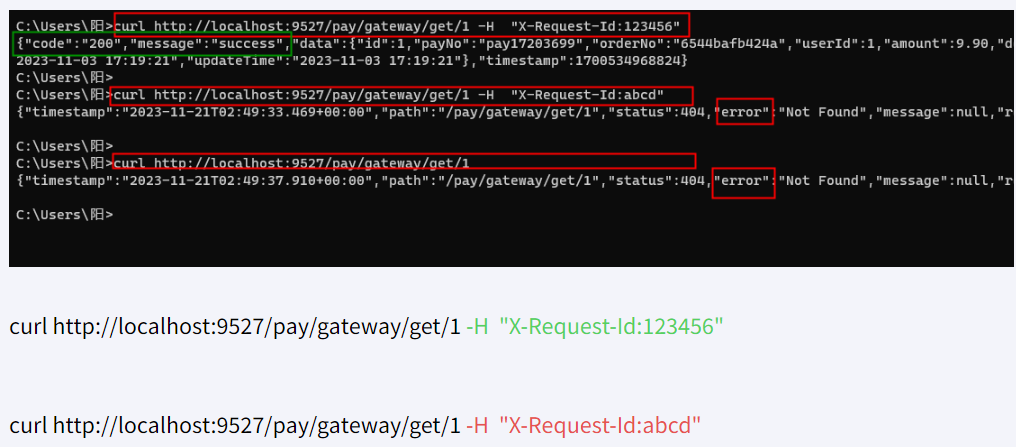
- Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式骚戴理解:- Header=X-Request-Id, \d+表示Path定义的这些路径下的所有请求的Header请求头里面必须有X-Request-Id这个key,并且这个key的值必须为整数,不然的话请求会被拦截掉
测试

Host Route Predicate
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-12-29T17:58:13.586918800+08:00[Asia/Shanghai]
#- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
#- Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
- Host=.atguigu.com,.saodai.com
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
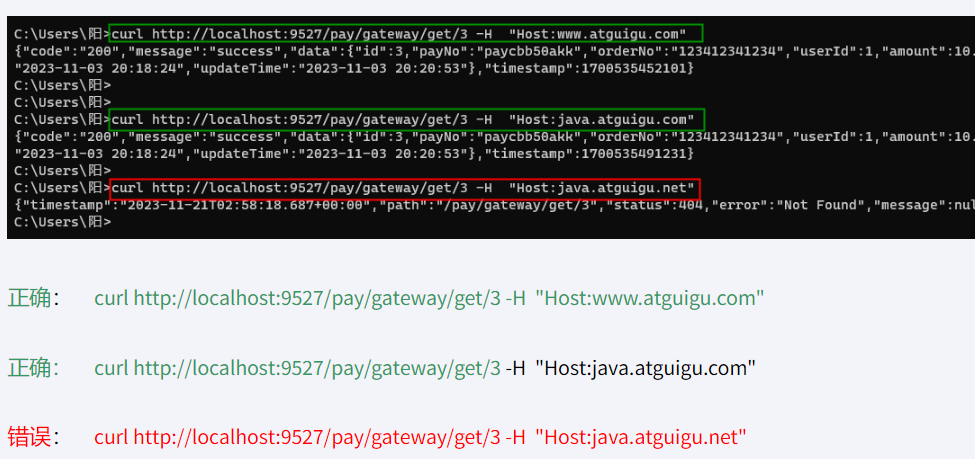
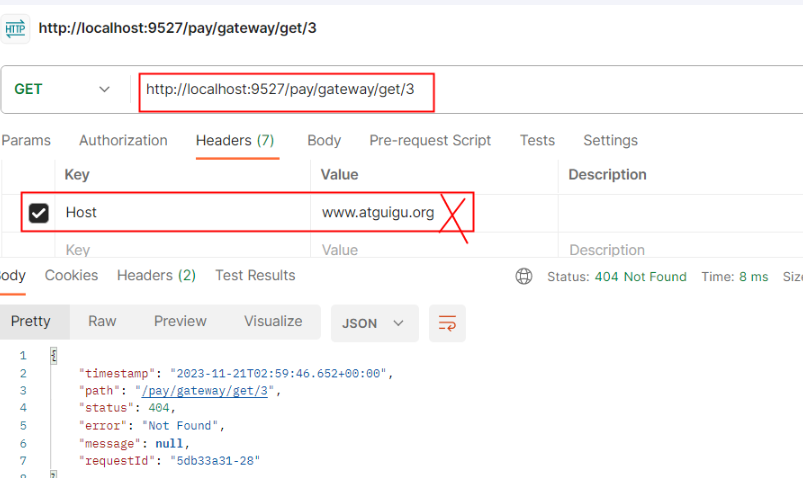
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由Host Route Predicate 接收一组参数,一组匹配的域名列表,如果有用逗号作为分隔符。它通过参数中的主机地址作为匹配规则。
骚戴理解: - Host=.atguigu.com,.saodai.com表示Path定义的这些路径下的所有请求的Host域名里面必须有包含atguigu或者saodai,不然的话请求会被拦截掉
测试
Path Route Predicate
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-12-29T17:58:13.586918800+08:00[Asia/Shanghai]
#- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
#- Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由Query Route Predicate
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-12-29T17:58:13.586918800+08:00[Asia/Shanghai]
#- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
#- Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
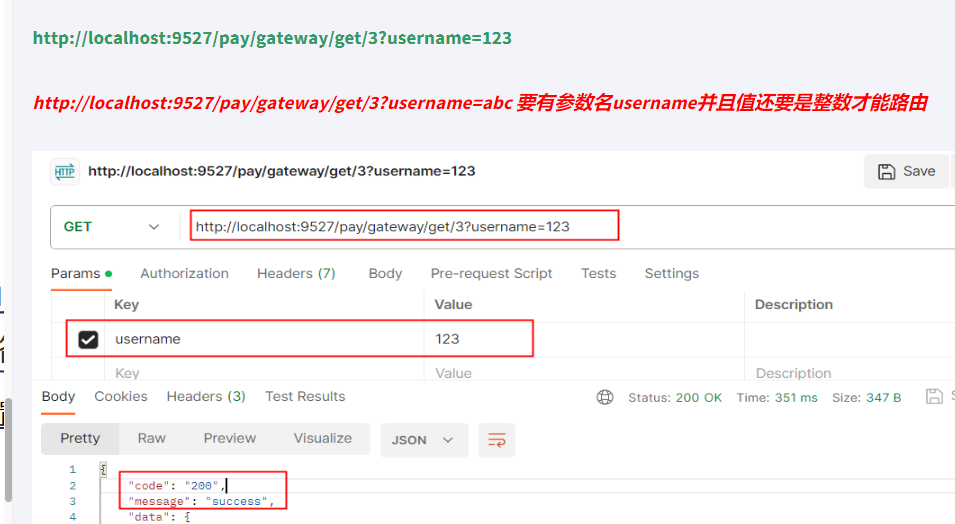
- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
骚戴理解: - Query=username, \d+表示Path定义的这些路径下的所有请求的查询参数里面必须有包含username,并且参数值必须为整数,不然的话请求会被拦截掉。支持传入两个参数,一个是属性名,一个为属性值,属性值可以是正则表达式。
RemoteAddr route predicate
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-12-29T17:58:13.586918800+08:00[Asia/Shanghai]
#- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
#- Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
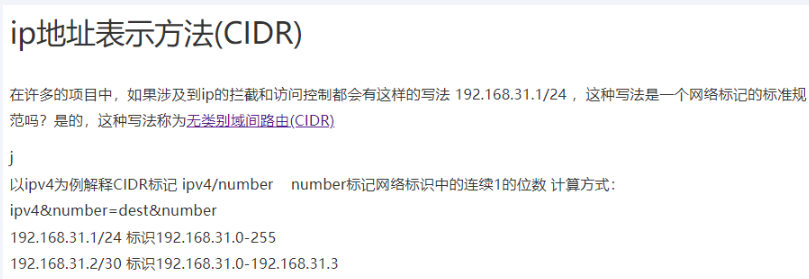
- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24它们是 CIDR 表示法。
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由骚戴理解: - RemoteAddr=192.168.124.1/24表示Path定义的这些路径下的所有请求的IP地址必须是来自 192.168.124.0 到 192.168.124.255 的客户端 IP 地址,不然的话请求会被拦截掉。要和Host Route Predicate 区分开来,Host Route Predicate 是限制域名,RemoteAddr route predicate是限制ip地址
Method Route Predicate
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-12-29T17:58:13.586918800+08:00[Asia/Shanghai]
#- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
#- Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24它们是 CIDR 表示法。
- Method=GET,POST
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由骚戴理解: - RemoteAddr=192.168.124.1/24表示Path定义的这些路径下的所有请求的只能用Get/Post方法访问,不然的话请求会被拦截掉。
自定义断言XXXRoutePredicateFactory规则
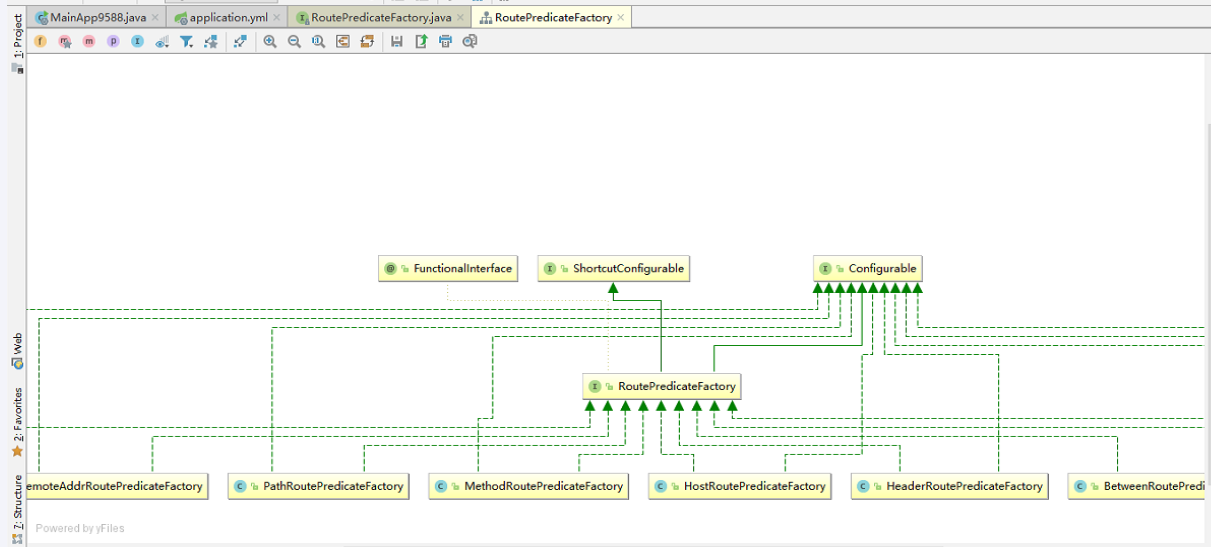
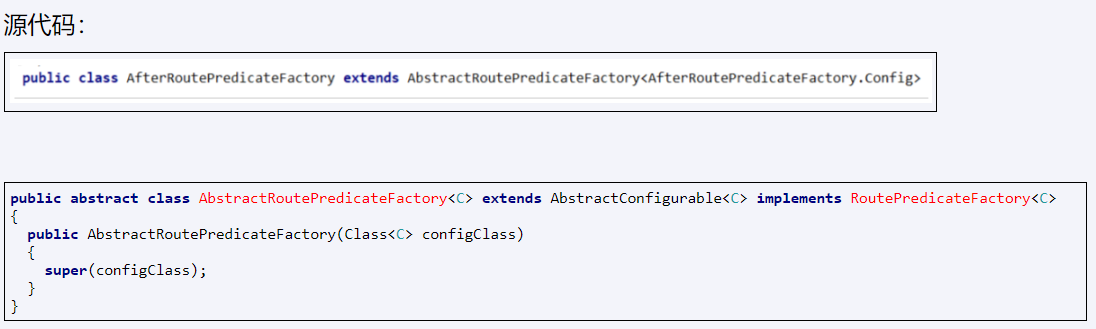
要么继承AbstractRoutePredicateFactory抽象类
要么实现RoutePredicateFactory接口
开头任意取名,但是必须以RoutePredicateFactory后缀结尾
自定义断言MyRoutePredicateFactory
package com.atguigu.cloud.mygateway;
import jakarta.validation.constraints.NotEmpty;
import lombok.Getter;
import lombok.Setter;
import org.springframework.cloud.gateway.handler.predicate.AbstractRoutePredicateFactory;
import org.springframework.stereotype.Component;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.server.ServerWebExchange;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Predicate;
/
* @auther zzyy
* @create 2023-04-23 18:30
*/
@Component
public class MyRoutePredicateFactory extends AbstractRoutePredicateFactory<MyRoutePredicateFactory.Config>
{
public MyRoutePredicateFactory()
{
super(MyRoutePredicateFactory.Config.class);
}
@Validated
public static class Config{
@Setter
@Getter
@NotEmpty
private String userType; //钻、金、银等用户等级
}
@Override
public Predicate<ServerWebExchange> apply(MyRoutePredicateFactory.Config config)
{
return new Predicate<ServerWebExchange>()
{
@Override
public boolean test(ServerWebExchange serverWebExchange)
{
//检查request的参数里面,userType是否为指定的值,符合配置就通过
String userType = serverWebExchange.getRequest().getQueryParams().getFirst("userType");
if (userType == null) return false;
//如果说参数存在,就和config的数据进行比较
if(userType.equals(config.getUserType())) {
return true;
}
return false;
}
};
}
@Override
public List<String> shortcutFieldOrder() {
return Collections.singletonList("userType");
}
}骚戴理解:如果没有重写shortcutFieldOrder方法就不能在配置文件里面使用- My=diamond这种短格式写法
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- After=2023-12-30T23:02:39.079979400+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
# - Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24它们是 CIDR 表示法。
// 自定义断言完整的格式写法
- name: My
args:
userType: diamond
#- My=diamond // 自定义断言短格式写法
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由Filter过滤
Filter过滤分为全局默认过滤器、单一内置过滤器、自定义过滤器
- 全局默认过滤器:是gateway出厂默认已有的,直接用即可,主要作用于所有的路由不需要在配置文件中配置,作用在所有的路由.上,实现GlobalFilter接口即可
- 单一内置过滤器:也可以称为网关过滤器,这种过滤器主要是作用于单一路由或者某个路由分组
作用:请求鉴权、异常处理、记录接口调用时长统计
常用的内置过滤器
请求头(RequestHeader )相关组
The AddRequestHeader GatewayFilter Factory
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- After=2023-12-30T23:02:39.079979400+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
# - Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24它们是 CIDR 表示法。
- My=gold
# - name: My
# args:
# userType: diamond
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/filter/ # 断言,路径相匹配的进行路由
filters:
- AddRequestHeader=X-Request-atguigu1,atguiguValue1 # 请求头kv,若一头含有多参则重写一行设置
- AddRequestHeader=X-Request-atguigu2,atguiguValue2
骚戴理解: - AddRequestHeader=X-Request-atguigu1,atguiguValue1表示Path定义的这些路径下的所有请求都会给他们加一个请求头Key为X-Request-atguigu1,值为atguiguValue1的请求头,如果存在多个就需要一行行写
The RemoveRequestHeader GatewayFilter Factory
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- After=2023-12-30T23:02:39.079979400+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
# - Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24它们是 CIDR 表示法。
- My=gold
# - name: My
# args:
# userType: diamond
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/filter/ # 断言,路径相匹配的进行路由
filters:
// - AddRequestHeader=X-Request-atguigu1,atguiguValue1 # 请求头kv,若一头含有多参则重写一行设置
// - AddRequestHeader=X-Request-atguigu2,atguiguValue2
- RemoveRequestHeader=sec-fetch-site # 删除请求头sec-fetch-site骚戴理解:- RemoveRequestHeader=sec-fetch-site 表示Path定义的这些路径下的所有请求都会删除其中的sec-fetch-site请求头
The SetRequestHeader GatewayFilter Factory
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- After=2023-12-30T23:02:39.079979400+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
# - Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24它们是 CIDR 表示法。
- My=gold
# - name: My
# args:
# userType: diamond
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/filter/ # 断言,路径相匹配的进行路由
filters:
// - AddRequestHeader=X-Request-atguigu1,atguiguValue1 # 请求头kv,若一头含有多参则重写一行设置
// - AddRequestHeader=X-Request-atguigu2,atguiguValue2
// - RemoveRequestHeader=sec-fetch-site # 删除请求头sec-fetch-site
- SetRequestHeader=sec-fetch-mode, Blue-updatebyzzyy # 将请求头sec-fetch-mode对应的值修改为Blue-updatebyzzyy骚戴理解: - SetRequestHeader=sec-fetch-mode, Blue-updatebyzzyy 表示Path定义的这些路径下的所有请求都会新增sec-fetch-mode请求头,请求头的值为Blue-updatebyzzyy
请求参数(RequestParameter)相关组
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- After=2023-12-30T23:02:39.079979400+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
# - Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24它们是 CIDR 表示法。
- My=gold
# - name: My
# args:
# userType: diamond
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/filter/ # 断言,路径相匹配的进行路由
filters:
// - AddRequestHeader=X-Request-atguigu1,atguiguValue1 # 请求头kv,若一头含有多参则重写一行设置
// - AddRequestHeader=X-Request-atguigu2,atguiguValue2
// - RemoveRequestHeader=sec-fetch-site # 删除请求头sec-fetch-site
// - SetRequestHeader=sec-fetch-mode, Blue-updatebyzzyy # 将请求头sec-fetch-mode对应的值修改为Blue-updatebyzzyy
- AddRequestParameter=customerId,9527001 # 新增请求参数Parameter:k ,v
- RemoveRequestParameter=customerName # 删除url请求参数customerName,你传递过来也是null骚戴理解: - AddRequestParameter=customerId,9527001表示Path定义的这些路径下的所有请求都添加请求参数customerId,参数值为9527001,- RemoveRequestParameter=customerName表示移除请求参数customerName
响应头(ResponseHeader)相关组
The AddResponseHeader GatewayFilter Factory
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- After=2023-12-30T23:02:39.079979400+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
# - Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24它们是 CIDR 表示法。
- My=gold
# - name: My
# args:
# userType: diamond
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/filter/ # 断言,路径相匹配的进行路由
filters:
// - AddRequestHeader=X-Request-atguigu1,atguiguValue1 # 请求头kv,若一头含有多参则重写一行设置
// - AddRequestHeader=X-Request-atguigu2,atguiguValue2
// - RemoveRequestHeader=sec-fetch-site # 删除请求头sec-fetch-site
// - SetRequestHeader=sec-fetch-mode, Blue-updatebyzzyy # 将请求头sec-fetch-mode对应的值修改为Blue-updatebyzzyy
// - AddRequestParameter=customerId,9527001 # 新增请求参数Parameter:k ,v
// - RemoveRequestParameter=customerName # 删除url请求参数customerName,你传递过来也是null
- AddResponseHeader=X-Response-atguigu, BlueResponse # 新增响应头X-Response-atguigu并设值为BlueResponseThe SetResponseHeader GatewayFilter Factory
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- After=2023-12-30T23:02:39.079979400+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
# - Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24它们是 CIDR 表示法。
- My=gold
# - name: My
# args:
# userType: diamond
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/filter/ # 断言,路径相匹配的进行路由
filters:
// - AddRequestHeader=X-Request-atguigu1,atguiguValue1 # 请求头kv,若一头含有多参则重写一行设置
// - AddRequestHeader=X-Request-atguigu2,atguiguValue2
// - RemoveRequestHeader=sec-fetch-site # 删除请求头sec-fetch-site
// - SetRequestHeader=sec-fetch-mode, Blue-updatebyzzyy # 将请求头sec-fetch-mode对应的值修改为Blue-updatebyzzyy
// - AddRequestParameter=customerId,9527001 # 新增请求参数Parameter:k ,v
// - RemoveRequestParameter=customerName # 删除url请求参数customerName,你传递过来也是null
// - AddResponseHeader=X-Response-atguigu, BlueResponse # 新增请求参数X-Response-atguigu并设值为BlueResponse
- SetResponseHeader=Date,2099-11-11 # 设置响应头Date值为2099-11-11The RemoveResponseHeader GatewayFilter Factory
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- After=2023-12-30T23:02:39.079979400+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
# - Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24它们是 CIDR 表示法。
- My=gold
# - name: My
# args:
# userType: diamond
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/filter/ # 断言,路径相匹配的进行路由
filters:
// - AddRequestHeader=X-Request-atguigu1,atguiguValue1 # 请求头kv,若一头含有多参则重写一行设置
// - AddRequestHeader=X-Request-atguigu2,atguiguValue2
// - RemoveRequestHeader=sec-fetch-site # 删除请求头sec-fetch-site
// - SetRequestHeader=sec-fetch-mode, Blue-updatebyzzyy # 将请求头sec-fetch-mode对应的值修改为Blue-updatebyzzyy
// - AddRequestParameter=customerId,9527001 # 新增请求参数Parameter:k ,v
// - RemoveRequestParameter=customerName # 删除url请求参数customerName,你传递过来也是null
// - AddResponseHeader=X-Response-atguigu, BlueResponse # 新增请求参数X-Response-atguigu并设值为BlueResponse
// - SetResponseHeader=Date,2099-11-11 # 设置回应头Date值为2099-11-11
- RemoveResponseHeader=Content-Type # 将默认自带Content-Type响应头删除前缀和路径相关组
The PrefixPath GatewayFilter Factory
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-12-29T17:58:13.586918800+08:00[Asia/Shanghai]
#- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
#- Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.124.1/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24。
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
// #- Path=/pay/gateway/filter/ # 被分拆为: PrefixPath + Path
- Path=/gateway/filter/ # 断言,为配合PrefixPath测试过滤,暂时注释掉/pay
filters:
// - AddRequestHeader=X-Request-atguigu1,atguiguValue1 #请求头kv,若一头含有多参则重写一行设置
// #- AddRequestHeader=X-Request-atguigu2,atguiguValue2
// #- RemoveRequestHeader=sec-fetch-site # 删除请求头sec-fetch-site
// #- SetRequestHeader=sec-fetch-mode, Blue-updatebyzzyy # 将请求头sec-fetch-mode对应的值修改为Blue-updatebyzzyy
// #- AddRequestParameter=customerId,9527001 # 新增请求参数Parameter:k ,v
// #- RemoveRequestParameter=customerName # 删除url请求参数customerName,你传递过来也是null
// #- AddResponseHeader=X-Response-atguigu, BlueResponse # 新增请求参数X-Response-atguigu并设值为BlueResponse
// #- SetResponseHeader=Date,2099-11-11 # 设置回应头Date值为2099-11-11
// #- RemoveResponseHeader=Content-Type # 将默认自带Content-Type回应属性删除
- PrefixPath=/pay # http://localhost:9527/pay/gateway/filter骚戴理解: - Path=/gateway/filter/和- PrefixPath=/pay一起配合,实现所有包含gateway/filter/的请求都会在这个路径前面加一个前缀/pay,最后完整的路径为/pay/gateway/filter,这可以实现隐藏后端真实的路径,例如原来的路径是http://localhost:9527/pay/gateway/filter,现在访问http://localhost:9527/gateway/filter也一样可以访问到后端接口,但是后端接口的真实路径却是/pay/gateway/filter,而不是/gateway/filter
The SetPath GatewayFilter Factory
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-12-29T17:58:13.586918800+08:00[Asia/Shanghai]
#- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
#- Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.1.196/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24。
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
#- Path=/pay/gateway/filter/ # 真实地址
#- Path=/gateway/filter/ # 断言,为配合PrefixPath测试过滤,暂时注释掉/pay
- Path=/XYZ/abc/{segment} # 断言,为配合SetPath测试,{segment}的内容最后被SetPath取代
filters:
- SetPath=/pay/gateway/{segment} # {segment}表示占位符,你写abc也行但要上下一致
骚戴理解:- Path=/XYZ/abc/{segment} 和- SetPath=/pay/gateway/{segment}一起配合,实现只要访问路径是是http://localhost:9527/XYZ/abc/{占位符}这样前缀开头的,那就会被替换成http://localhost:9527/pay/gateway/占位符,这个占位符随便输入什么都行,这样写就可以完全隐藏真实路径,
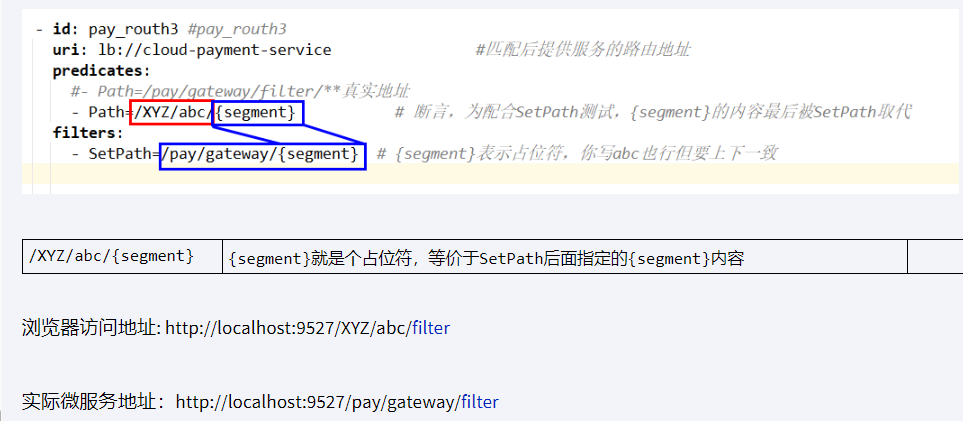
The RedirectTo GatewayFilter Factory
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
#- After=2023-11-20T17:38:13.586918800+08:00[Asia/Shanghai]
- Before=2023-12-29T17:58:13.586918800+08:00[Asia/Shanghai]
#- Between=2023-11-21T17:38:13.586918800+08:00[Asia/Shanghai],2023-11-22T17:38:13.586918800+08:00[Asia/Shanghai]
#- Cookie=username,zzyy
#- Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
#- Host=.atguigu.com
#- Query=username, \d+ # 要有参数名username并且值还要是整数才能路由
#- RemoteAddr=192.168.1.196/24 # 外部访问我的IP限制,最大跨度不超过32,目前是1~24。
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
#uri: http://localhost:8001 #匹配后提供服务的路由地址
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/filter/ # 真实地址
filters:
- RedirectTo=302, http://www.atguigu.com/ # 访问http://localhost:9527/pay/gateway/filter跳转到http://www.atguigu.com/骚戴理解:将匹配所有请求,并将它们重定向到 http://www.atguigu.com/ URL
- RedirectTo=302:指定将使用 HTTP 302 重定向状态代码执行重定向。这表示临时重定向,客户端应在后续请求中使用新的 URL。
- http://www.atguigu.com/:指定重定向目标 URL。
全局配置
自定义过滤器
自定义全局Filter
统计接口调用耗时情况,如何落地,谈谈设计思路
package com.atguigu.cloud.mygateway;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
/
* @auther zzyy
* @create 2023-11-22 17:27
*/
@Component
@Slf4j
public class MyGlobalFilter implements GlobalFilter, Ordered
{
/
* 数字越小优先级越高
* @return
*/
@Override
public int getOrder()
{
return 0;
}
private static final String BEGIN_VISIT_TIME = "begin_visit_time";//开始访问时间
/
*第2版,各种统计
* @param exchange
* @param chain
* @return
*/
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//先记录下访问接口的开始时间
exchange.getAttributes().put(BEGIN_VISIT_TIME, System.currentTimeMillis());
return chain.filter(exchange).then(Mono.fromRunnable(()->{
Long beginVisitTime = exchange.getAttribute(BEGIN_VISIT_TIME);
if (beginVisitTime != null){
log.info("访问接口主机: " + exchange.getRequest().getURI().getHost());
log.info("访问接口端口: " + exchange.getRequest().getURI().getPort());
log.info("访问接口URL: " + exchange.getRequest().getURI().getPath());
log.info("访问接口URL参数: " + exchange.getRequest().getURI().getRawQuery());
log.info("访问接口时长: " + (System.currentTimeMillis() - beginVisitTime) + "ms");
log.info("我是美丽分割线: ###################################################");
System.out.println();
}
}));
}
}
server:
port: 9527
spring:
application:
name: cloud-gateway #以微服务注册进consul或nacos服务列表内
cloud:
consul: #配置consul地址
host: localhost
port: 8500
discovery:
prefer-ip-address: true
service-name: ${spring.application.name}
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/get/ # 断言,路径相匹配的进行路由
- After=2023-12-30T23:02:39.079979400+08:00[Asia/Shanghai]
- id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
uri: lb://cloud-payment-service
predicates:
- Path=/pay/gateway/info/ # 断言,路径相匹配的进行路由
- id: pay_routh3 #pay_routh3
uri: lb://cloud-payment-service #匹配后提供服务的路由地址
predicates:
- Path=/pay/gateway/filter/ # 断言,路径相匹配的进行路由,默认正确地址
filters:
- AddRequestHeader=X-Request-atguigu1,atguiguValue1 # 请求头kv,若一头含有多参则重写一行设置自定义条件Filter
package com.atguigu.cloud.mygateway;
import lombok.Getter;
import lombok.Setter;
import org.springframework.cloud.gateway.filter.GatewayFilter;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.factory.AbstractGatewayFilterFactory;
import org.springframework.cloud.gateway.filter.factory.SetPathGatewayFilterFactory;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import java.util.Arrays;
import java.util.List;
/
* @auther zzyy
* @create 2023-12-31 21:41
*/
@Component
public class MyGatewayFilterFactory extends AbstractGatewayFilterFactory<MyGatewayFilterFactory.Config>
{
public MyGatewayFilterFactory()
{
super(MyGatewayFilterFactory.Config.class);
}
@Override
public GatewayFilter apply(MyGatewayFilterFactory.Config config)
{
return new GatewayFilter()
{
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain)
{
ServerHttpRequest request = exchange.getRequest();
System.out.println("进入了自定义网关过滤器MyGatewayFilterFactory,status:"+config.getStatus());
if(request.getQueryParams().containsKey("atguigu")){
return chain.filter(exchange);
}else{
exchange.getResponse().setStatusCode(HttpStatus.BAD_REQUEST);
return exchange.getResponse().setComplete();
}
}
};
}
@Override
public List<String> shortcutFieldOrder() {
return Arrays.asList("status");
}
public static class Config
{
@Getter@Setter
private String status;//设定一个状态值/标志位,它等于多少,匹配和才可以访问
}
}
//单一内置过滤器GatewayFilter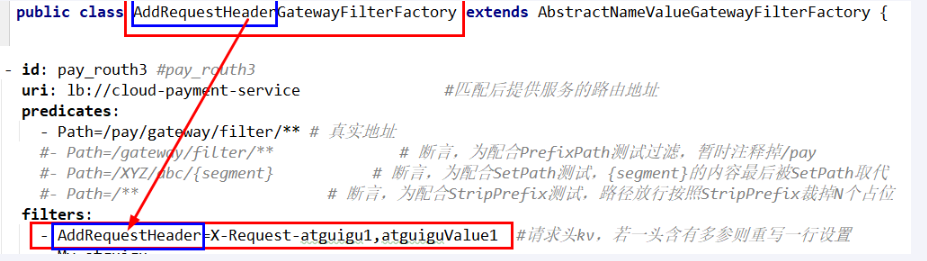
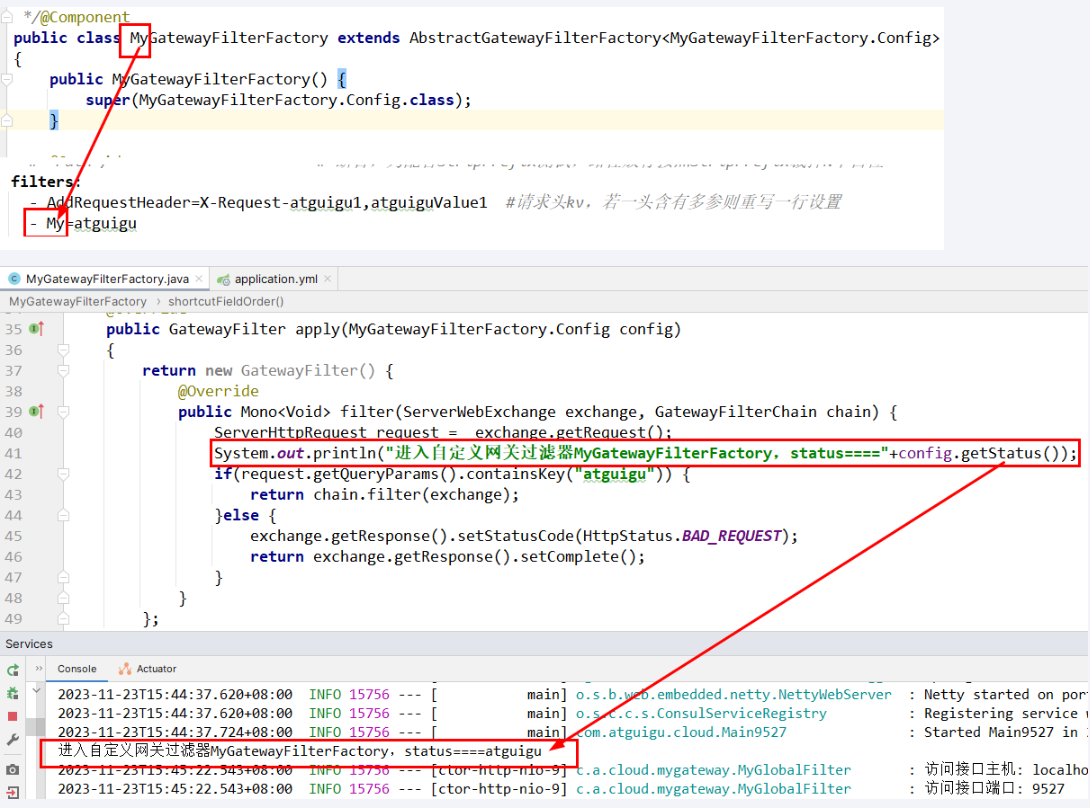
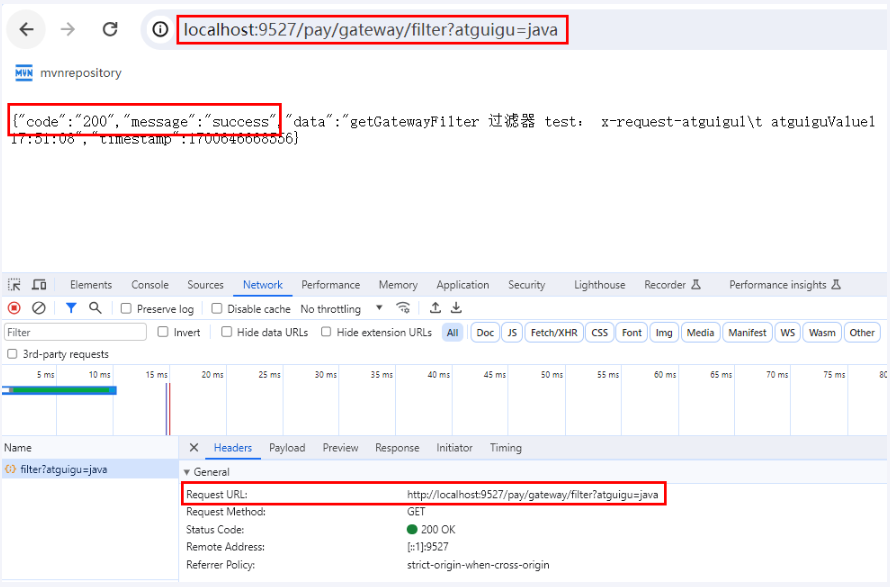
SpringCloud Alibaba入门简介
介绍
Spring Cloud Alibaba 是一个由阿里巴巴开源的 Spring Cloud 扩展,用于提供一整套微服务开发工具和组件。它提供了与阿里云服务(如阿里云 OSS、阿里云消息队列等)的无缝集成,以及分布式系统开发中常用的组件,如服务发现、配置管理、消息总线、熔断器和限流等。
组件
Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Nacos: 十个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
RocketMQ:-款开源的分布式消息系统, 基于高可用分布式集群技术,提供低延时的、可靠的消息发布与订阅服务。
Seata: 阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
Alibaba Cloud OSS:阿里云对象存储服务(Object Storage Service,简称OSS) ,是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
Alibaba Cloud SchedulerX:阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于Cron表达式)任务调度服务。
Alibaba Cloud SMS:覆盖全球的短信服务,友好高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
主要功能
服务限流降级:默认支持WebServlet、 WebFlux、 OpenFeign、 RestTemplate、 Spring Cloud Gateway. Dubbo和RocketMQ限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级Metrics监控。
服务注册与发现:适配Spring Cloud服务注册与发现标准,默认集成对应Spring Cloud版本所支持的负载均衡组件的适配。
分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新。
消息驱动能力:基于Spring Cloud Stream为微服务应用构建消息驱动能力。
分布式事务:使用@GlobalTransactional注解,高效并 且对业务零侵入地解决分布式事务问题。
阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
分布式任务调度:提供秒级、精准、高可靠、高可用的定时(基于Cron表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有Worker (schedulerx-client). 上执行。
阿里云短信服务:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
服务注册和配置中心-SpringCloud Alibaba Nacos
介绍
一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。Nacos就是注册中心+配置中心的组合。Nacos作为注册中心自带负载均衡的效果,Nacos = Eureka+ Config + Bus,Nacos = Spring Cloud Consul
作用
- 替代Eureka/Consul做服务注册中心
- 替代(Config+ Bus)/Consul做服务配置中心和满足动态刷新广播通知

各种注册中心比较

据说 Nacos 在阿里巴巴内部有超过 10 万的实例运行,已经过了类似双十一等各种大型流量的考验,Nacos默认是AP模式,但也可以调整切换为CP,我们一般用默认AP即可。
Nacos Discovery服务注册中心
基于Nacos的服务提供者
导入依赖
<!--nacos-discovery-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>Yaml文件
server:
port: 9001
spring:
application:
name: nacos-payment-provider
cloud:
nacos:
discovery:
server-addr: localhost:8848 #配置Nacos地址如果不想使用Nacos作为您的服务注册与发现,可以将spring.cloud.nacos .discovery. enabled设置为false
使用@EnableDiscoveryClient
@SpringBootApplication
@EnableDiscoveryClient
public class Main9001
{
public static void main(String[] args)
{
SpringApplication.run(Main9001.class,args);
}
}基于Nacos的服务消费者
导入依赖

<!--nacos-discovery-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--loadbalancer-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>Yaml文件
server:
port: 83
spring:
application:
name: nacos-order-consumer
cloud:
nacos:
discovery:
server-addr: localhost:8848
#消费者将要去访问的微服务名称(nacos微服务提供者叫什么你写什么)
service-url:
nacos-user-service: http://nacos-payment-provider使用@EnableDiscoveryClient
@EnableDiscoveryClient
@SpringBootApplication
public class Main83
{
public static void main(String[] args)
{
SpringApplication.run(Main83.class,args);
}
}使用restTemplate调用其他微服务
package com.atguigu.cloud.config;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
/
* @auther zzyy
* @create 2023-11-23 17:20
*/
@Configuration
public class RestTemplateConfig
{
@Bean
@LoadBalanced //赋予RestTemplate负载均衡的能力
public RestTemplate restTemplate()
{
return new RestTemplate();
}
}package com.atguigu.cloud.controller;
import jakarta.annotation.Resource;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
/
* @auther zzyy
* @create 2023-11-23 17:21
*/
@RestController
public class OrderNacosController
{
@Resource
private RestTemplate restTemplate;
@Value("${service-url.nacos-user-service}")
private String serverURL;
@GetMapping("/consumer/pay/nacos/{id}")
public String paymentInfo(@PathVariable("id") Integer id)
{
String result = restTemplate.getForObject(serverURL + "/pay/nacos/" + id, String.class);
return result+"\t"+" 我是OrderNacosController83调用者。。。。。。";
}
}Nacos Config服务配置中心
通过Nacos和spring-cloud-starter-alibaba-nacos-config实现中心化全局配置的动态变更
导入依赖
<!--bootstrap-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
<!--nacos-config-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>Yml配置
Nacos同Consul一样,在项目初始化时,要保证先从配置中心进行配置拉取,拉取配置之后,才能保证项目的正常启动,为了满足动态刷新和全局广播通知,springboot中配置文件的加载是存在优先级顺序的,bootstrap优先级高于application
# nacos配置
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
config:
server-addr: localhost:8848 #Nacos作为配置中心地址
file-extension: yaml #指定yaml格式的配置
# nacos端配置文件DataId的命名规则是:
# ${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension}
# 本案例的DataID是:nacos-config-client-dev.yamlserver:
port: 3377
spring:
profiles:
active: dev # 表示开发环境
#active: prod # 表示生产环境
#active: test # 表示测试环境使用@EnableDiscoveryClient
@EnableDiscoveryClient
@SpringBootApplication
public class NacosConfigClient3377
{
public static void main(String[] args)
{
SpringApplication.run(NacosConfigClient3377.class,args);
}
}业务类
package com.atguigu.cloud.controller;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/
* @auther zzyy
* @create 2023-11-27 15:51
*/
@RestController
@RefreshScope //在控制器类加入@RefreshScope注解使当前类下的配置支持Nacos的动态刷新功能。
public class NacosConfigClientController
{
@Value("${config.info}")
private String configInfo;
@GetMapping("/config/info")
public String getConfigInfo() {
return configInfo;
}
}
@RefreshScope //在控制器类加入@RefreshScope注解使当前类下的配置支持Nacos的动态刷新功能。
在Nacos中添加配置信息
nacos端配置文件DataId的命名规则是:
${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension}
本案例的DataID是:nacos-config-client-dev.yaml
骚戴理解:其实就是DataID有自己命名规则,由三部分组成,应用名称+profile指定的环境+文件后缀,配置好后nacos就可以根据命名规则找到这个配置,然后就可以在代码里面通过@Value("${config.info}")这样读取到nacos里面配置的内容,也可以在配置文件里面通过${config.info}去拿对应的值



Nacos会记录配置文件的历史版本默认保留30天,此外还有一键回滚功能, 回滚操作将会触发配置更新
Nacos数据模型之Namespace-Group-Datald
问题1:
实际开发中,通常一个系统会准备dev开发环境、test测试环境、prod生产环境,如何保证指定环境启动时服务能正确读取到Nacos上相应环境的配置文件呢?
问题2:
一个大型分布式微服务系统会有很多微服务子项目,每个微服务项目又都会有相应的开发环境、测试环境、预发环境、正式环境......那怎么对这些微服务配置进行分组和命名空间管理呢?
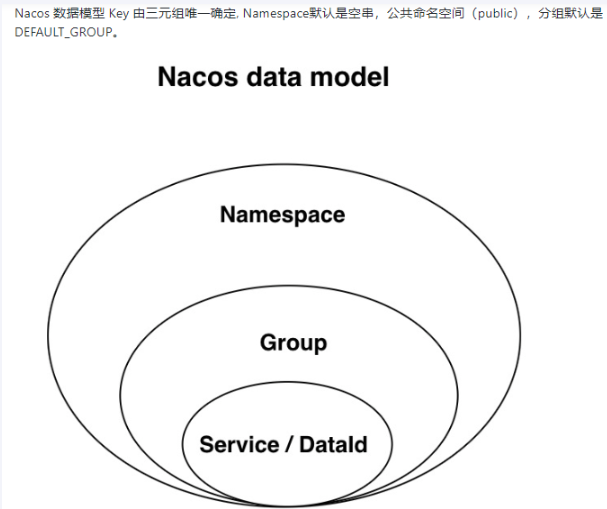
默认情况:Namespace=public,Group=DEFAULT_GROUP
Nacos默认的命名空间是public,Namespace主要用来实现隔离。比方说我们现在有三个环境:开发、测试、生产环境,我们就可以创建三个Namespace,不同的Namespace之间是隔离的。Group默认是DEFAULT_GROUP,Group可以把不同的微服务划分到同一个分组里面去
三种方案加载配置
DatalD方案
指定spring.profile active和配置文件的DatalD来使不同环境下读取不同的配置,默认空间public+默认分组DEFAULT GROUP+新建DatalD

# nacos配置 第一种:默认空间+默认分组+新建DataID
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
config:
server-addr: localhost:8848 #Nacos作为配置中心地址
file-extension: yaml #指定yaml格式的配置server:
port: 3377
spring:
profiles:
#active: dev # 表示开发环境
active: test # 表示测试环境
#active: prod # 表示生产环境骚戴理解:其实很好理解,核心在于“指定spring.profile.active和配置文件的DatalD来使不同环境下读取不同的配置”这句话,就是根据application.yml里spring.profile.active指定的这个去nacos上面找到对应的配置,也就是上面nacos配置中心的nacos-config-client-test-yaml配置
Group方案
通过Group实现环境区分,默认空间public+新建PROD_ GROUP+新建DatalD
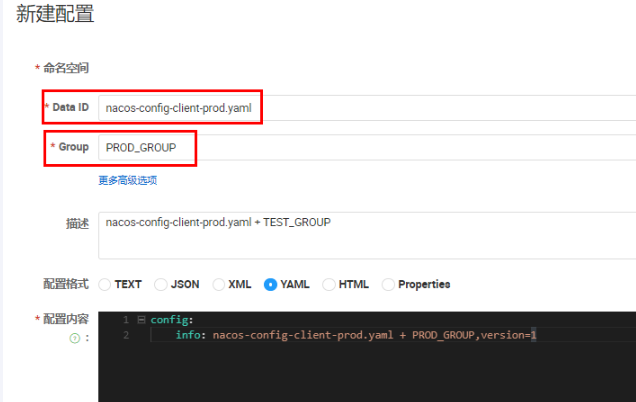

# nacos配置 第2种:默认空间+新建分组+新建DataID
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
config:
server-addr: localhost:8848 #Nacos作为配置中心地址
file-extension: yaml #指定yaml格式的配置
group: PROD_GROUP在config下增加一条group的配置,配置为PROD GROUP
server:
port: 3377
spring:
profiles:
#active: dev # 表示开发环境
#active: test # 表示测试环境
active: prod # 表示生产环境Namespace方案
通过Namespace实现命名空间环境区分,Prod_ Namespace命名空间+PROD_ GROUP分组+DatalD(nacos-config-client-prod.yaml)
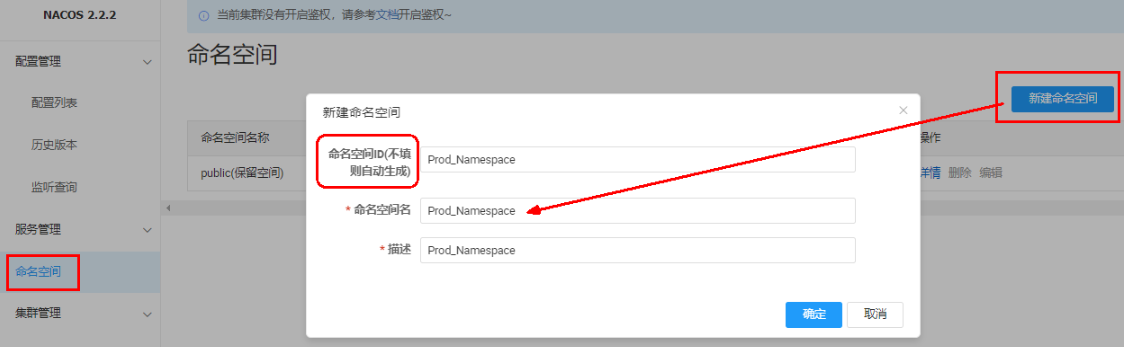
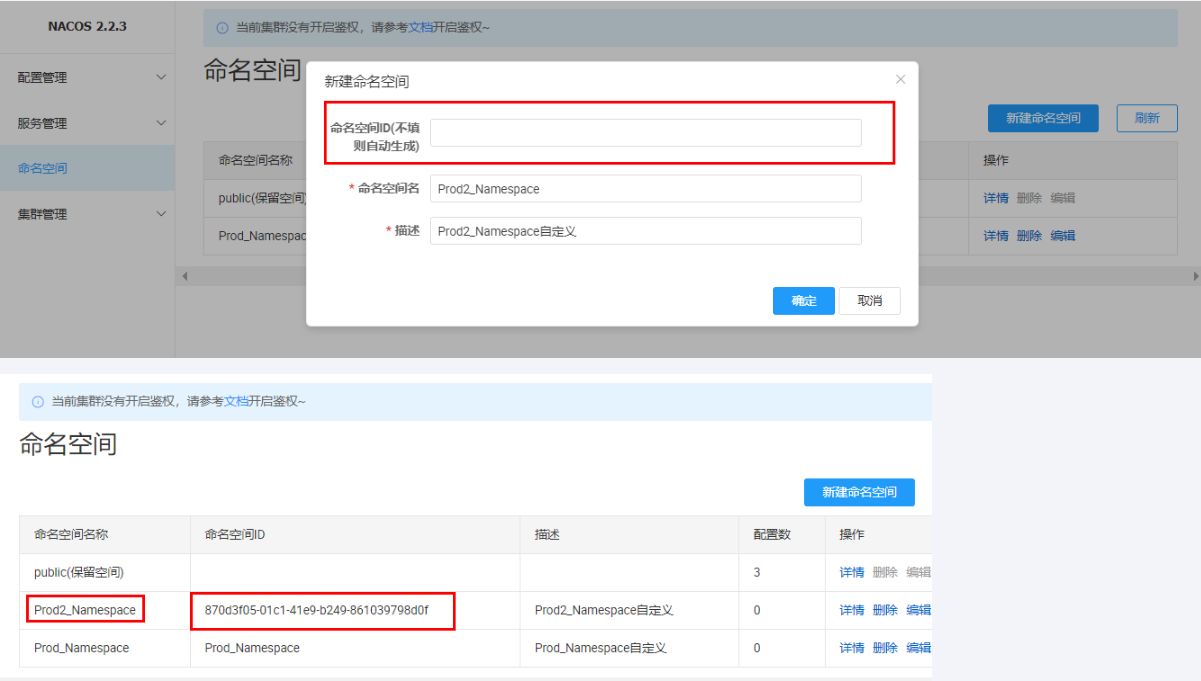


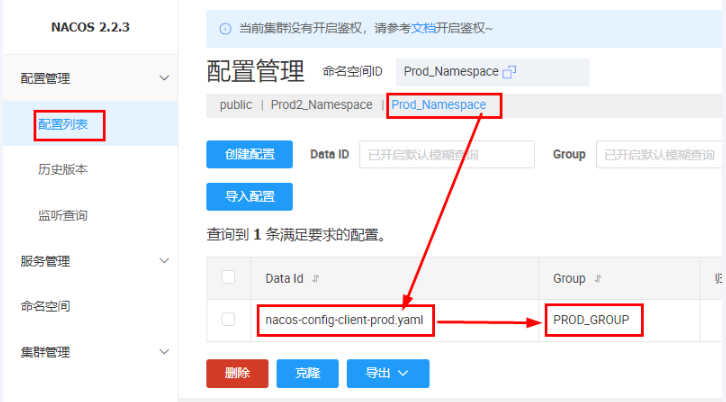
# nacos配置 第3种:新建空间+新建分组+新建DataID
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
config:
server-addr: localhost:8848 #Nacos作为配置中心地址
file-extension: yaml #指定yaml格式的配置
group: PROD_GROUP
namespace: Prod_Namespaceserver:
port: 3377
spring:
profiles:
#active: dev # 表示开发环境
#active: test # 表示测试环境
active: prod # 表示生产环境实现熔断与限流-SpringCloud Alibaba Sentinel
面向分布式、多语言异构化服务架构的流量治理组件,等价对标Spring Cloud Circuit Breaker
Sentinel的特征
丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Apache Dubbo、gRPC、Quarkus 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。同时 Sentinel 提供 Java/Go/C++ 等多语言的原生实现。
完善的 SPI 扩展机制:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。

面试题
服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
所以,通常当你发现一个模块下的某个实例失败后,这时候这个模块依然还会接收流量,然后这个有问题的模块还调用了其他的模块,这样就会发生级联故障,或者叫雪崩。复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。
服务降级
服务降级,说白了就是一种服务托底方案,如果服务无法完成正常的调用流程,就使用默认的托底方案来返回数据。
例如,在商品详情页一般都会展示商品的介绍信息,一旦商品详情页系统出现故障无法调用时,会直接获取缓存中的商品介绍信息返回给前端页面。
服务熔断
在分布式与微服务系统中,如果下游服务因为访问压力过大导致响应很慢或者一直调用失败时,上游服务为了保证系统的整体可用性,会暂时断开与下游服务的调用连接。这种方式就是熔断。类比保险丝达到最大服务访问后,直接拒绝访问,拉闸限电,然后调用服务降级的方法并返回友好提示。
服务熔断一般情况下会有三种状态:闭合、开启和半熔断;
闭合状态(保险丝闭合通电OK):服务一切正常,没有故障时,上游服务调用下游服务时,不会有任何限制。
开启状态(保险丝断开通电Error):上游服务不再调用下游服务的接口,会直接返回上游服务中预定的方法。
半熔断状态:处于开启状态时,上游服务会根据一定的规则,尝试恢复对下游服务的调用。此时,上游服务会以有限的流量来调用下游服务,同时,会监控调用的成功率。如果成功率达到预期,则进入关闭状态。如果未达到预期,会重新进入开启状态。
服务限流
服务限流就是限制进入系统的流量,以防止进入系统的流量过大而压垮系统。其主要的作用就是保护服务节点或者集群后面的数据节点,防止瞬时流量过大使服务和数据崩溃(如前端缓存大量实效),造成不可用;还可用于平滑请求,类似秒杀高并发等操作,严禁一窝蜂的过来拥挤,大家排队,一秒钟N个,有序进行。
限流算法有两种,一种就是简单的请求总量计数,一种就是时间窗口限流(一般为1s),如令牌桶算法和漏牌桶算法就是时间窗口的限流算法。
服务隔离
有点类似于系统的垂直拆分,就按照一定的规则将系统划分成多个服务模块,并且每个服务模块之间是互相独立的,不会存在强依赖的关系。如果某个拆分后的服务发生故障后,能够将故障产生的影响限制在某个具体的服务内,不会向其他服务扩散,自然也就不会对整体服务产生致命的影响。
互联网行业常用的服务隔离方式有:线程池隔离和信号量隔离。
服务超时
整个系统采用分布式和微服务架构后,系统被拆分成一个个小服务,就会存在服务与服务之间互相调用的现象,从而形成一个个调用链。
形成调用链关系的两个服务中,主动调用其他服务接口的服务处于调用链的上游,提供接口供其他服务调用的服务处于调用链的下游。服务超时就是在上游服务调用下游服务时,设置一个最大响应时间,如果超过这个最大响应时间下游服务还未返回结果,则断开上游服务与下游服务之间的请求连接,释放资源。
下载Sentinel
Sentinel分为两个部分
- 核心库(Java客户端)不依赖任何框架/库,能够运行于所有Java运行时环境,同时对Dubbo / Spring Cloud等框架也有较好的支持。
- 控制台(Dashboard) 基于Spring Boot开发,打包后可以直接运行,不需要额外的Tomcat等应用容器。
骚戴理解:后台8719默认,前台8080开启,需要确保Java环境没问题,8080端口不能被占用【Tomcat也是这个端口】,然后运行下载的jar包,命令为java -jar sentinel-dashboard-1.8.6.jar,最后访问http://localhost:8080,登录账号密码均为sentinel
整合Sentinel
需要先启动Nacos和Sentinel
导入依赖
<!--SpringCloud alibaba sentinel -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>配置yml
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
sentinel:
transport:
dashboard: localhost:8080 #配置Sentinel dashboard控制台服务地址
port: 8719 #默认8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口@EnableDiscoveryClient注册到nacos
@EnableDiscoveryClient
@SpringBootApplication
public class Main8401
{
public static void main(String[] args)
{
SpringApplication.run(Main8401.class,args);
}
}配置Controller
@RestController
public class FlowLimitController
{
@GetMapping("/testA")
public String testA()
{
return "------testA";
}
@GetMapping("/testB")
public String testB()
{
return "------testB";
}
}骚戴理解:想使用Sentine是对某个接口进行限流和降级等操作,一定要先访问下接口,使Sentinel检测出相应的接口,因为Sentine懒加载

流控规则
Sentinel能够对流量进行控制,主要是监控应用的QPS流量或者并发线程数等指标,如果达到指定的阈值时,就会被流量进行控制,以避免服务被瞬时的高并发流量击垮,保证服务的高可靠性。参数见最下方:

资源名 |
资源的唯一名称,默认就是请求的接口路径,可以自行修改,但是要保证唯一。 |
针对来源 |
具体针对某个微服务进行限流,默认值为default,表示不区分来源,全部限流。 |
阈值类型 |
QPS表示通过QPS进行限流,并发线程数表示通过并发线程数限流。 |
单机阈值 |
与阈值类型组合使用。如果阈值类型选择的是QPS,表示当调用接口的QPS达到阈值时,进行限流操作。如果阈值类型选择的是并发线程数,则表示当调用接口的并发线程数达到阈值时,进行限流操作。 |
是否集群 |
选中则表示集群环境,不选中则表示非集群环境。 |
骚戴扩展:QPS(Queries Per Second)表示每秒查询数,它衡量每秒处理的请求数。并发线程数阈值不推荐使用!在限流场景中,QPS 阈值类型表示通过限制每秒处理的请求数来进行限流。当请求速率超过 QPS 阈值时,限流器将触发,阻止额外的请求进入系统。
例如,如果您设置了一个 QPS 阈值为 100 的限流器,则该限流器将允许每秒处理最多 100 个请求。如果请求速率超过 100 QPS,则限流器将阻止额外的请求进入系统。
并发线程数阈值类型表示通过限制同时处理的请求数来进行限流。当同时处理的请求数超过并发线程数阈值时,限流器将触发,阻止额外的请求进入系统。
例如,如果您设置了一个并发线程数阈值为 10 的限流器,则该限流器将允许同时处理最多 10 个请求。如果同时处理的请求数超过 10,则限流器将阻止额外的请求进入系统。
QPS 与并发线程数的区别:
- QPS 衡量每秒处理的请求数,而 并发线程数 衡量同时处理的请求数。
- QPS 限制的是请求速率,而 并发线程数 限制的是同时处理的请求数。
- QPS 更适合于限制对服务器资源有较高要求的请求,例如数据库查询和 API 调用。并发线程数 更适合于限制对服务器资源要求较低的请求,例如静态文件服务和缓存读取。
流控模式
![]()
直接
默认的流控模式,当接口达到限流条件时,直接开启限流功能。
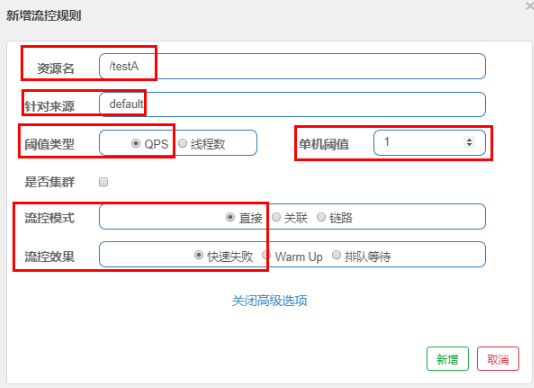
设置效果:表示1秒钟内查询1次就是OK,若超过次数1,就直接-快速失败,报默认错误
关联
当关联的资源达到阈值时,就限流自己,当与A关联的资源B达到阀值后,就限流A自己
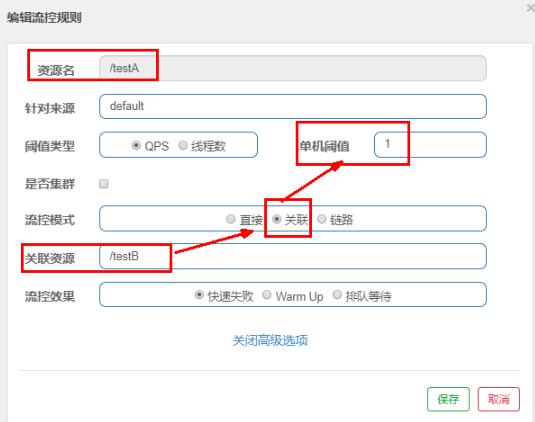
设置效果:当关联资源/testB的qps阀值超过1时,就限流/testA的Rest访问地址,当关联资源到阈值后限制配置好的资源名,B惹事,A挂了,访问A显示Blocked by Sentinel (flow limiting)
骚戴理解:这个需要借助Jmeter模拟并发密集访问testB
链路
来自不同链路的请求对同一个目标访问时,实施针对性的不同限流措施,比如C请求来访问就限流,D请求来访问就是0K,看人下菜!
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service #8401微服务提供者后续将会被纳入阿里巴巴sentinel监管
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
sentinel:
transport:
dashboard: localhost:8080 #配置Sentinel dashboard控制台服务地址
port: 8719 #默认8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口
web-context-unify: false # controller层的方法对service层调用不认为是同一个根链路骚戴理解:web-context-unify: false表示controller层的方法对service层调用不认为是同一个根链路,从而模拟出链路的效果
package com.atguigu.cloudalibaba.service;
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import org.springframework.stereotype.Service;
/
* @auther zzyy
* @create 2023-05-26 18:40
*/
@Service
public class FlowLimitService
{
@SentinelResource(value = "common")
public void common()
{
System.out.println("------FlowLimitService come in");
}
}/
* @auther zzyy
* @create 2023-05-24 15:35
*/
@RestController
public class FlowLimitController
{
/流控-链路演示demo
* C和D两个请求都访问flowLimitService.common()方法,阈值到达后对C限流,对D不管
*/
@Resource private FlowLimitService flowLimitService;
@GetMapping("/testC")
public String testC()
{
flowLimitService.common();
return "------testC";
}
@GetMapping("/testD")
public String testD()
{
flowLimitService.common();
return "------testD";
}
}骚戴扩展:@SentinelResource(value = "common") 是 Sentinel 注解,用于标记需要限流保护的方法。
- value:指定资源名称,用于标识受保护的方法。
用法:
在需要限流保护的方法上添加 @SentinelResource 注解,例如:
@SentinelResource(value = "common")
public String common() {
// ...
}作用:
- 对标注的方法进行限流保护,防止方法被过量调用。
- 当方法被调用次数超过限流阈值时,Sentinel 将会抛出异常或执行降级逻辑。
其他属性:
除了 value 属性之外,@SentinelResource 注解还支持其他属性,用于自定义限流规则,例如:
- blockHandler:指定当限流发生时执行的降级处理方法。
- fallback:指定当限流发生时执行的兜底处理方法。
- entryType:指定限流的类型,可以是 QPS 限流或并发线程数限流。
- count:指定限流阈值,例如 QPS 限流的阈值为每秒处理的请求数,并发线程数限流的阈值为同时处理的请求数。
示例:
@SentinelResource(value = "common", blockHandler = "commonBlockHandler")
public String common() {
// ...
}
public String commonBlockHandler(BlockException ex) {
// 降级处理逻辑
}在上面的示例中,当 common() 方法被调用次数超过限流阈值时,Sentinel 将会调用 commonBlockHandler() 方法执行降级处理逻辑。
sentinel配置

说明:C和D两个请求都访问flowLimitService.common()方法,对C限流,对D不管
流控效果
快速失败
快速失败(默认的流控处理)直接失败, 抛出异常Blocked by Sentinel (flow limiting)
预热WarmUp
当流量突然增大的时候,我们常常会希望系统从空闲状态到繁忙状态的切换的时间长一些。 即如果系统在此之前长期处于空闲的状态,我们希望处理请求的数量是缓步的增多,经过预期的时间以后,到达系统处理请求个数的最大值。Warm Up (冷启动,预热)模式就是为了实现这个目的。
这个场景主要用于启动需要额外开销的场景,例如建立数据库连接等。
公式:阈值除以冷却因子coldFactor(默认值为3),经过预热时长后才会达到阈值
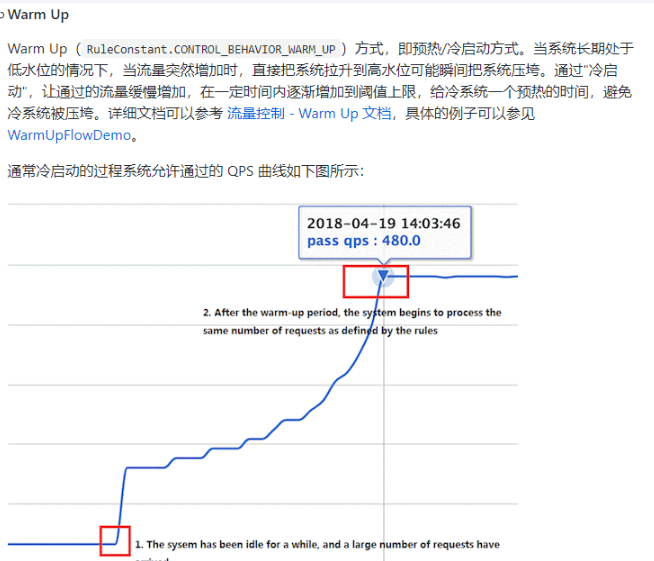
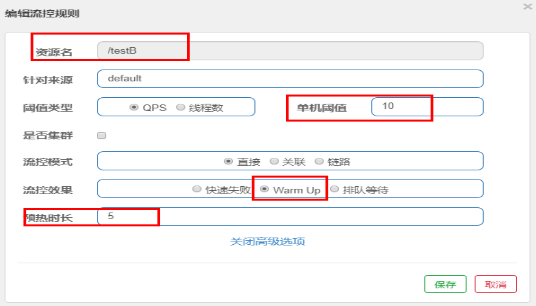
默认 coldFactor 为 3,即请求QPS从(threshold / 3) 开始,经多少预热时长才逐渐升至设定的 QPS 阈值。
案例:单机阈值为10,预热时长设置5秒。
系统初始化的阈值为10 / 3 约等于3,即单机阈值刚开始为3(我们人工设定单机阈值是10,sentinel计算后QPS判定为3开始);然后过了5秒后阀值才慢慢升高恢复到设置的单机阈值10,也就是说5秒钟内QPS为3,过了保护期5秒后QPS为10
应用场景:秒杀系统在开启的瞬间,会有很多流量上来,很有可能把系统打死,预热方式就是把为了保护系统,可慢慢的把流量放进来,慢慢的把阈值增长到设置的阈值。
骚戴理解:拿上面的案例来说,假如突然有1s来了10个请求,预热时长为5s,所以就是在5s内只处理3个请求,剩下的7个请求5s后再处理
排队等待

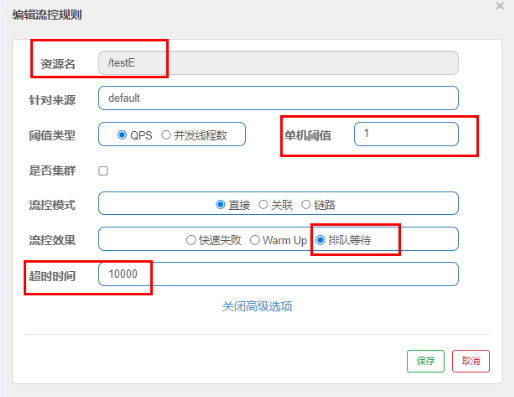
骚戴理解:上面得到这个配置表示1秒一个请求,如果请求大于1s就放到队列里面去等待,等待时间就是上面的超时时间,这里设置为10s,如果超过了10s,队列里面的请求还是没有被处理就会被放弃掉
骚戴扩展:Sentinel 的排队等待是一种流量控制机制,当系统资源不足时,将请求放入队列中等待处理。它通常用于防止系统过载和确保服务的稳定性。
排队的原理
当请求到达系统时,Sentinel 将检查系统的当前负载。如果系统当前的负载超过了预设的阈值,则请求将被放入队列中进行等待。Sentinel 将根据队列中的请求数量和系统的容量,控制进入系统的请求速率。
排队的示例
假设有一个电商网站,处理大量的订单请求。Sentinel 被配置为监控系统的 CPU 利用率,并将阈值设置为 90%。
- 高峰流量期间:当网站流量激增时,系统 CPU 利用率可能会超过 90%。Sentinel 将启动排队机制,将多余的订单请求放入队列中等待处理。
- 队列中的请求:等待队列中的请求将被临时存储,直到系统的 CPU 利用率下降到阈值以下。
- 释放请求:当系统的 CPU 利用率下降时,Sentinel 将从队列中释放请求进行处理。
熔断规则
Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。
熔断策略
慢调用比例( SLOW REQUEST RATIO ):选择以慢调用比例作为阈值,需要设置允许的慢调用RT (即最大的响应时间),请求的啊应时间大于该值则统许为慢调用。当单位统计时长( statIntervalMs )内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN状态),若接下来的一个请求响应时间小于设置的慢调用RT则结束熔断,若大于设置的慢调用RT则会再次被熔断
异常比例( ERROR RATIO ):为单位统计时长( statIntervalMs )内请求数目大于设置的最小请求数目,并且异常的比例大于尚值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态) , 若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是[0.0, 1.0]. 代表0%-100%。
异常数(ERROR COUNT ):当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN状态)。若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
注意异常降级仅针对业务异常,对Sentinel限流降级本身的异常( BlockException) 不生效。为了统计异常比例或异常数,需要通过Tracer.trace(ex) 记录业务异常。

慢调用比例
进入熔断状态判断依据:在统计时长内,实际请求数目>设定的最小请求数且实际慢调用比例>比例阈值 ,进入熔断状态。
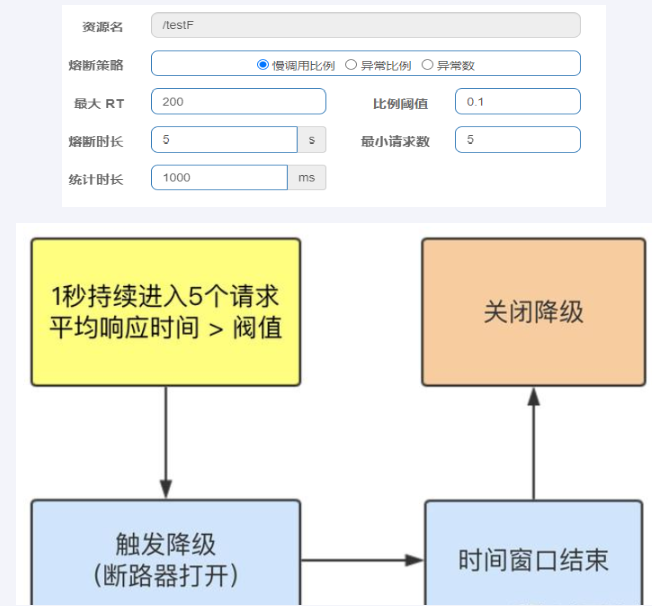
1.调用:一个请求发送到服务器,服务器给与响应,一个响应就是一个调用。
2.最大RT:即最大的响应时间,指系统对请求作出响应的业务处理时间。
3.慢调用:处理业务逻辑的实际时间>设置的最大RT时间,这个调用叫做慢调用。
4.慢调用比例:在所以调用中,慢调用占有实际的比例=慢调用次数➗总调用次数
5.比例阈值:自己设定的 , 比例阈值=慢调用次数➗调用次数
6.统计时长:时间的判断依据
7.最小请求数:设置的调用最小请求数,上图比如1秒钟打进来10个线程(大于我们配置的5个了)调用被触发
熔断过程
熔断状态(保险丝跳闸断电,不可访问):在接下来的熔断时长内请求会自动被熔断
探测恢复状态(探路先锋):熔断时长结束后进入探测恢复状态
结束熔断(保险丝闭合恢复,可以访问):在探测恢复状态,如果接下来的一个请求响应时间小于设置的慢调用 RT,则结束熔断,否则继续熔断。
/
* 新增熔断规则-慢调用比例
* @return
*/
@GetMapping("/testF")
public String testF()
{
//暂停几秒钟线程
try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
System.out.println("----测试:新增熔断规则-慢调用比例 ");
return "------testF 新增熔断规则-慢调用比例";
}
10个线程,在一秒的时间内发送完。又因为服务器响应时长设置:暂停1秒,所以响应一个请求的时长都大于1秒综上符合熔断条件,所以当线程开启1秒后,进入熔断状态
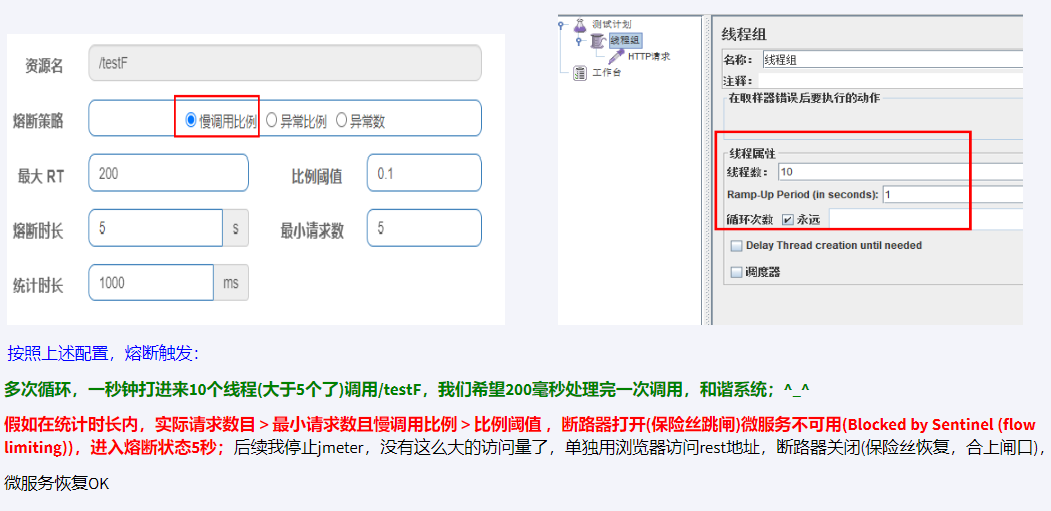
异常比例
为单位统计时长( statIntervalMs )内请求数目大于设置的最小请求数目,并且异常的比例大于尚值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态) , 若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是[0.0, 1.0]. 代表0%-100%。
/
* 新增熔断规则-异常比例
* @return
*/
@GetMapping("/testG")
public String testG()
{
System.out.println("----测试:新增熔断规则-异常比例 ");
int age = 10/0;
return "------testG,新增熔断规则-异常比例 ";
}不配置Sentinel,对于int age=10/0,调一次错一次报错error,页面报【Whitelabel Error Page】或全局异常
配置Sentinel,对于int age=10/0,如符合如下异常比例启动熔断,页面报【Blocked by Sentinel (flow limiting)】
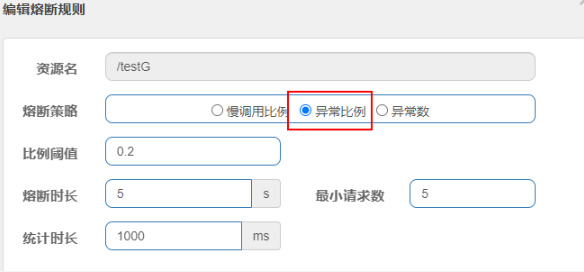
骚戴理解:需要注意的是不是一次异常就会熔断,因为配置了熔断的比例,如果达到了那个比例才会有熔断效果
异常数
当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN状态)。若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
/
* 新增熔断规则-异常数
* @return
*/
@GetMapping("/testH")
public String testH()
{
System.out.println("----测试:新增熔断规则-异常数 ");
int age = 10/0;
return "------testH,新增熔断规则-异常数 ";
}
骚戴理解:需要注意的是不是一次异常就会熔断,因为配置了熔断数,如果达到了那个数量才会有熔断效果
@SentinelResource注解
SentinelResource是一个流量防卫防护组件注解,用于指定防护资源,对配置的资源进行流量控制、熔断降级等功能。
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface SentinelResource {
//资源名称
String value() default "";
//entry类型,标记流量的方向,取值IN/OUT,默认是OUT
EntryType entryType() default EntryType.OUT;
//资源分类
int resourceType() default 0;
//处理BlockException的函数名称,函数要求:
//1. 必须是 public
//2.返回类型 参数与原方法一致
//3. 默认需和原方法在同一个类中。若希望使用其他类的函数,可配置blockHandlerClass ,并指定blockHandlerClass里面的方法。
String blockHandler() default "";
//存放blockHandler的类,对应的处理函数必须static修饰。
Class<?>[] blockHandlerClass() default {};
//用于在抛出异常的时候提供fallback处理逻辑。 fallback函数可以针对所
//有类型的异常(除了 exceptionsToIgnore 里面排除掉的异常类型)进行处理。函数要求:
//1. 返回类型与原方法一致
//2. 参数类型需要和原方法相匹配
//3. 默认需和原方法在同一个类中。若希望使用其他类的函数,可配置fallbackClass ,并指定fallbackClass里面的方法。
String fallback() default "";
//存放fallback的类。对应的处理函数必须static修饰。
String defaultFallback() default "";
//用于通用的 fallback 逻辑。默认fallback函数可以针对所有类型的异常进
//行处理。若同时配置了 fallback 和 defaultFallback,以fallback为准。函数要求:
//1. 返回类型与原方法一致
//2. 方法参数列表为空,或者有一个 Throwable 类型的参数。
//3. 默认需要和原方法在同一个类中。若希望使用其他类的函数,可配置fallbackClass ,并指定 fallbackClass 里面的方法。
Class<?>[] fallbackClass() default {};
//需要trace的异常
Class<? extends Throwable>[] exceptionsToTrace() default {Throwable.class};
//指定排除忽略掉哪些异常。排除的异常不会计入异常统计,也不会进入fallback逻辑,而是原样抛出。
Class<? extends Throwable>[] exceptionsToIgnore() default {};
}按SentinelResource资源名称限流+自定义限流返回
不想用默认的限流提示(Blocked by Sentinel (flow limiting)), 想返回自定义限流的提示
@RestController
@Slf4j
public class RateLimitController
{
@GetMapping("/rateLimit/byUrl")
public String byUrl()
{
return "按rest地址限流测试OK";
}
@GetMapping("/rateLimit/byResource")
@SentinelResource(value = "byResourceSentinelResource",blockHandler = "handleException")
public String byResource()
{
return "按资源名称SentinelResource限流测试OK";
}
public String handleException(BlockException exception)
{
return "服务不可用@SentinelResource启动"+"\t"+"o(╥﹏╥)o";
}
}骚戴理解:blockHandler就是根据限流规则去匹配,如果不满足就跳到blockHandler指定的方法去,可以在方法里面跳转到自定义的限流页面去

默认的限流提示
自定义的限流提示

按SentinelResource资源名称限流+自定义限流返回+服务降级处理
按SentinelResource配置,点击超过限流配置返回自定义限流提示+程序异常返回fallback服务降级
@RestController
@Slf4j
public class RateLimitController
{
@GetMapping("/rateLimit/doAction/{p1}")
@SentinelResource(value = "doActionSentinelResource",
blockHandler = "doActionBlockHandler", fallback = "doActionFallback")
public String doAction(@PathVariable("p1") Integer p1) {
if (p1 == 0){
throw new RuntimeException("p1等于零直接异常");
}
return "doAction";
}
public String doActionBlockHandler(@PathVariable("p1") Integer p1,BlockException e){
log.error("sentinel配置自定义限流了:{}", e);
return "sentinel配置自定义限流了";
}
public String doActionFallback(@PathVariable("p1") Integer p1,Throwable e){
log.error("程序逻辑异常了:{}", e);
return "程序逻辑异常了"+"\t"+e.getMessage();
}
}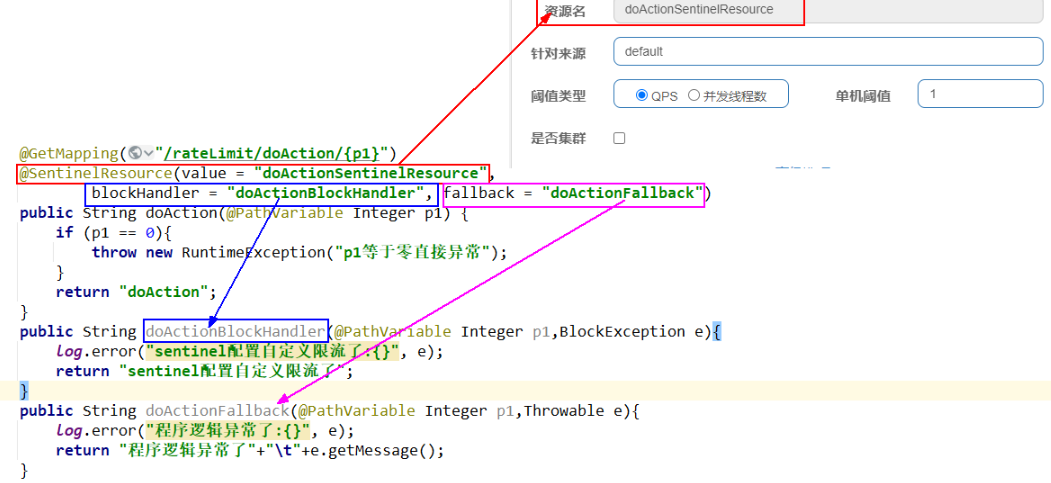
骚戴理解:blockHandler主要针对sentinel配置后出现的违规情况处理(当 Sentinel 规则被触发时(例如流量或资源限制超出),Sentinel 会调用 blockHandler 来处理违规请求),fallback主要针对程序异常了JVM抛出的异常服务降级,两者可以同时共存
热点规则
热点即经常访问的数据,很多时候我们希望统计或者限制某个热点数据中访问频次最高的TopN数据,并对其访问进行限流或者其它操作
对参数进行限流
@GetMapping("/testHotKey")
@SentinelResource(value = "testHotKey",blockHandler = "dealHandler_testHotKey")
public String testHotKey(@RequestParam(value = "p1",required = false) String p1,
@RequestParam(value = "p2",required = false) String p2){
return "------testHotKey";
}
public String dealHandler_testHotKey(String p1,String p2,BlockException exception)
{
return "-----dealHandler_testHotKey";
}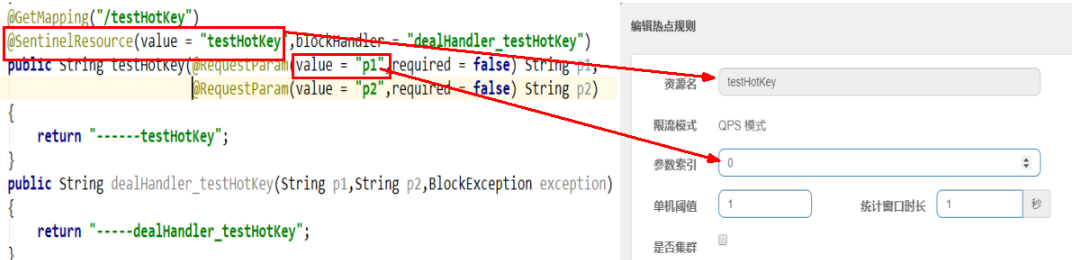
限流模式只支持QPS模式,固定写死了。(这才叫热点)
@SentinelResource注解的方法参数索引,0代表第一个参数,1代表第二个参数,以此类推
单机阀值以及统计窗口时长表示在此窗口时间超过阀值就限流。
上面的抓图就是第一个参数有值的话,1秒的QPS为1,超过就限流,限流后调用dealHandler_testHotKey支持方法。
骚戴理解:方法testHotKey里面第一个参数P 1只要QPS超过每秒1次,马上降级处理,意思是参数P1是一个热点参数,比如秒杀某个商品,那么商品id就是那个热点参数,然后我们要对这个参数进行限流,如果不带这个参数就不限流

对参数值进行限流
我们期望p1参数当它是某个特殊值时,到达某个约定值后[ 普通正常限流]规则突然例外、失效了,它的限流值和平时不一样,假如当p1的值等于5时,它的阈值可以达到200或其它值
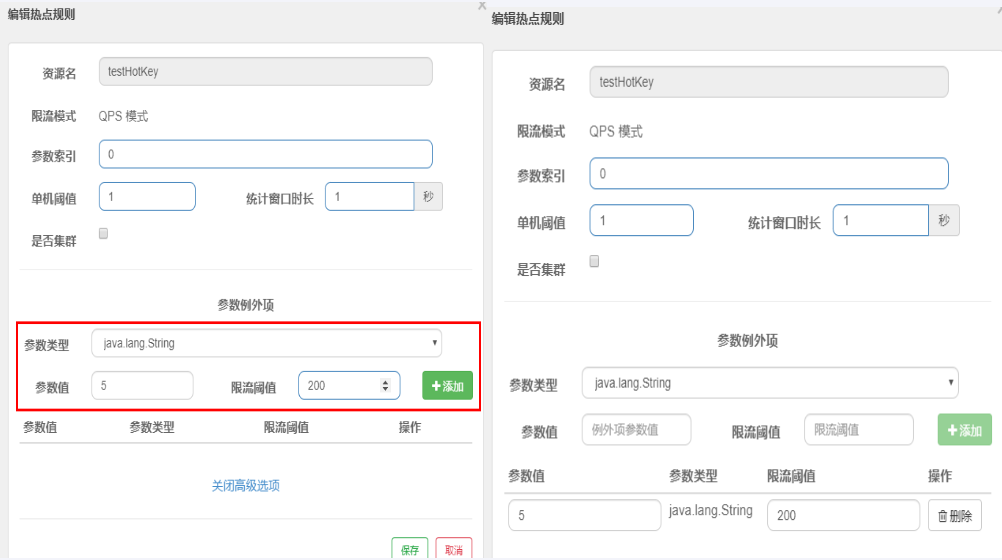
骚戴理解:上面是对参数值进行限流,这是一个更精细的配置,例如商品id是这个参数,那不可能对所有商品进行限流,当然是对秒杀商品进行限流,所以就可以这样配置,配置完后一定要点击添加按钮才能把这个配置添加到配置列表里面去,最后保存!热点参数的注意点,参数必须是基本类型或者String!
授权规则
在某些场景下,需要根据调用接口的来源判断是否允许执行本次请求。此时就可以使用Sentinel提供的授权规则来实现,Sentinel的授权规则能够根据请求的来源判断是否允许本次请求通过。
在Sentinel的授权规则中,提供了 白名单与黑名单 两种授权类型。白放行、黑禁止
@RestController
@Slf4j
public class EmpowerController //Empower授权规则,用来处理请求的来源
{
@GetMapping(value = "/empower")
public String requestSentinel4(){
log.info("测试Sentinel授权规则empower");
return "Sentinel授权规则";
}
}package com.atguigu.cloud.handler;
import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.RequestOriginParser;
import jakarta.servlet.http.HttpServletRequest;
import org.springframework.stereotype.Component;
/
* @auther zzyy
* @create 2023-11-30 19:33
*/
@Component
public class MyRequestOriginParser implements RequestOriginParser
{
@Override
public String parseOrigin(HttpServletRequest httpServletRequest) {
return httpServletRequest.getParameter("serverName");
}
}骚戴理解:这里要实现RequestOriginParser接口并重写parseOrigin方法
MyRequestOriginParser 是一个 Java 类,它实现了 RequestOriginParser 接口。RequestOriginParser 接口用于从 HTTP 请求中解析请求的来源,或称为来源服务器。
parseOrigin 方法:parseOrigin 方法负责从给定的 HTTP 请求中解析请求的来源。
在 MyRequestOriginParser 类中,parseOrigin 方法从 HTTP 请求中提取 serverName 参数,并将其返回作为请求的来源。serverName 参数通常包含发起请求的服务器的名称或主机名。
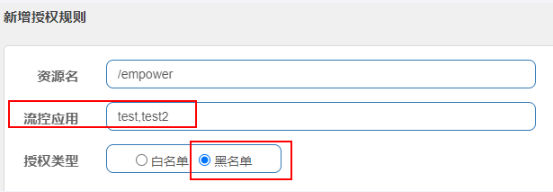

规则持久化
一旦我们重启微服务应用,sentinel规则将消失, 生产环境需要将配置规则进行持久化将限流配置规则持久化进Nacos保存,只要刷新8401某个rest地址,sentinel控制台的流控规则就能看到,只要Nacos里面的配置不删除,针对8401上sentinel上的流控规则持续有效
在原来的依赖基础上加上新依赖
<!--SpringCloud ailibaba sentinel-datasource-nacos -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>配置yml
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service #8401微服务提供者后续将会被纳入阿里巴巴sentinel监管
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
sentinel:
transport:
dashboard: localhost:8080 #配置Sentinel dashboard控制台服务地址
port: 8719 #默认8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口
web-context-unify: false # controller层的方法对service层调用不认为是同一个根链路
datasource:
ds1:
nacos:
server-addr: localhost:8848
dataId: ${spring.application.name}
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow # com.alibaba.cloud.sentinel.datasource.RuleType骚戴理解:
- ds1:数据源的名称,可以任意定义。
- nacos:指定数据源类型为 Nacos。
- server-addr:Nacos 服务器地址。
- dataId:Nacos 中的 dataId,通常设置为 Spring Boot 应用的名称。
- groupId:Nacos 中的 groupId,通常设置为 DEFAULT_GROUP。
- data-type:Nacos 中数据的类型,这里设置为 json。
- rule-type:Sentinel 规则类型,这里设置为 flow,表示该数据源包含流控规则。
rule-type:
com.alibaba.cloud.sentinel.datasource.RuleType 是一个枚举类,定义了 Sentinel 支持的规则类型。在您的配置中,rule-type 被设置为 flow,表示该数据源包含流控规则。
其他支持的规则类型:
- flow:流控规则
- degrade:降级规则
- system:系统规则
- authority:授权规则
- param-flow:参数流控规则
通过指定 rule-type,可以告诉 Sentinel 从 Nacos 中加载哪种类型的规则。
[
{
"resource": "/rateLimit/byUrl", //资源名称
"limitApp": "default", //来源应用
"grade": 1, //阈值类型,0表示线程数,1表示QPS;
"count": 1, //单机阈值
"strategy": 0, //流控模式,0表示直接,1表示关联,2表示链路;
"controlBehavior": 0,//流控效果
"clusterMode": false
}
]
骚戴理解:简单来说就是之前我们都是在Sentinel的控制台界面去配置的这些参数,但是那样配置无法持久化,所以需要放到nacos里面去配置,如上所示那一个json其实就是控制台配置的那些参数的json格式值,这样Sentinel就可以从nacos里面去拿这个规则了,不会丢失
- resource:要保护的资源名称,在本例中是 "/rateLimit/byUrl"。
- limitApp:要应用此规则的来源应用,在本例中是 "default"。
- grade:阈值类型,0 表示线程数,1 表示 QPS(每秒查询数)。在本例中,设置为 1,表示 QPS。
- count:单机阈值,表示允许通过的 QPS 数量。在本例中,设置为 1,表示每秒只允许通过 1 个请求。
- strategy:流控模式,0 表示直接模式,1 表示关联模式,2 表示链路模式。在本例中,设置为 0,表示直接模式,即直接对资源进行流控。
- controlBehavior:流控效果,0 表示快速失败,1 表示匀速排队,2 表示 Warm Up。在本例中,设置为 0,表示快速失败,即当达到阈值时,超出阈值的请求将立即被拒绝。
- clusterMode:是否启用集群模式。在本例中,设置为 false,表示不启用集群模式。
此流控规则表示,对于来自 "default" 应用的请求,针对 "/rateLimit/byUrl" 资源的 QPS 阈值为 1。当 QPS 达到或超过 1 时,超出阈值的请求将被快速失败,即立即拒绝。
OpenFeign和Sentinel集成实现fallback服务降级
cloudalibaba-consumer-nacos-order83 通过OpenFeign调用 cloudalibaba-provider-payment9001会有以下几种情况:
- 通过OpenFeign调用 9001微服务,正常访问OK
- 通过OpenFeign调用 9001微服务,异常访问error
-
- 访问者要有fallback服务降级的情况,不要持续访问9001加大微服务负担,但是通过feign接口调用的又方法各自不同,如果每个不同方法都加一个fallback配对方法,会导致代码膨胀不好管理,工程埋雷
解决思路
- public @interface FeignClient通过fallback属性进行统一配置,feign接口里面定义的全部方法都走统一的服务降级,一个搞定即可。
- 9001微服务自身还带着sentinel内部配置的流控规则,如果满足也会被触发,也即本例有2个Case
-
- OpenFeign接口的统一fallback服务降级处理
- Sentinel访问触发了自定义的限流配置,在注解@SentinelResource里面配置的blockHandler方法。

服务提供者
导入依赖
<!--openfeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!--alibaba-sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<!-- 引入自己定义的api通用包 -->
<dependency>
<groupId>com.atguigu.cloud</groupId>
<artifactId>cloud-api-commons</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>配置yml
server:
port: 9001
spring:
application:
name: nacos-payment-provider
cloud:
nacos:
discovery:
server-addr: localhost:8848 #配置Nacos地址
sentinel:
transport:
dashboard: localhost:8080 #配置Sentinel dashboard控制台服务地址
port: 8719 #默认8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口启动类
@SpringBootApplication
@EnableDiscoveryClient
public class Main9001
{
public static void main(String[] args)
{
SpringApplication.run(Main9001.class,args);
}
}controller
package com.atguigu.cloud.controller;
import cn.hutool.core.util.IdUtil;
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.atguigu.cloud.entities.PayDTO;
import com.atguigu.cloud.resp.ResultData;
import com.atguigu.cloud.resp.ReturnCodeEnum;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.math.BigDecimal;
/
* @auther zzyy
* @create 2023-11-23 17:09
*/
@RestController
public class PayAlibabaController
{
@Value("${server.port}")
private String serverPort;
@GetMapping(value = "/pay/nacos/{id}")
public String getPayInfo(@PathVariable("id") Integer id)
{
return "nacos registry, serverPort: "+ serverPort+"\t id"+id;
}
@GetMapping("/pay/nacos/get/{orderNo}")
@SentinelResource(value = "getPayByOrderNo",blockHandler = "handlerBlockHandler")
public ResultData getPayByOrderNo(@PathVariable("orderNo") String orderNo)
{
//模拟从数据库查询出数据并赋值给DTO
PayDTO payDTO = new PayDTO();
payDTO.setId(1024);
payDTO.setOrderNo(orderNo);
payDTO.setAmount(BigDecimal.valueOf(9.9));
payDTO.setPayNo("pay:"+IdUtil.fastUUID());
payDTO.setUserId(1);
return ResultData.success("查询返回值:"+payDTO);
}
public ResultData handlerBlockHandler(@PathVariable("orderNo") String orderNo,BlockException exception)
{
return ResultData.fail(ReturnCodeEnum.RC500.getCode(),"getPayByOrderNo服务不可用," +
"触发sentinel流控配置规则"+"\t"+"o(╥﹏╥)o");
}
/*
fallback服务降级方法纳入到Feign接口统一处理,全局一个
public ResultData myFallBack(@PathVariable("orderNo") String orderNo,Throwable throwable)
{
return ResultData.fail(ReturnCodeEnum.RC500.getCode(),"异常情况:"+throwable.getMessage());
}
*/
}
公共模块
导入依赖
<!--openfeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!--alibaba-sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>定义openFeign
@FeignClient(value = "nacos-payment-provider",fallback = PayFeignSentinelApiFallBack.class)
public interface PayFeignSentinelApi
{
@GetMapping("/pay/nacos/get/{orderNo}")
public ResultData getPayByOrderNo(@PathVariable("orderNo") String orderNo);
}package com.atguigu.cloud.apis;
import com.atguigu.cloud.resp.ResultData;
import com.atguigu.cloud.resp.ReturnCodeEnum;
import org.springframework.stereotype.Component;
/
* @auther zzyy
* @create 2023-11-30 20:22
*/
@Component
public class PayFeignSentinelApiFallBack implements PayFeignSentinelApi
{
@Override
public ResultData getPayByOrderNo(String orderNo)
{
return ResultData.fail(ReturnCodeEnum.RC500.getCode(),"对方服务宕机或不可用,FallBack服务降级o(╥﹏╥)o");
}
}骚戴理解:这一小节的核心内容就在这个feign接口这里了,其实也很简单,就是在feign接口定义了fallback,这样就不用每一个业务接口都需要定义一个降级方法了,统一在openfeign这里处理掉,解耦合.
骚戴扩展:PayFeignSentinelApi 接口用于在服务降级时提供备用逻辑。覆盖了 PayFeignSentinelApi 接口中的 getPayByOrderNo() 方法,在服务降级时返回一个固定的失败响应。
消费者
导入依赖
<!-- 引入自己定义的api通用包 -->
<dependency>
<groupId>com.atguigu.cloud</groupId>
<artifactId>cloud-api-commons</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<!--openfeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!--alibaba-sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>配置yml
server:
port: 83
spring:
application:
name: nacos-order-consumer
cloud:
nacos:
discovery:
server-addr: localhost:8848
#消费者将要去访问的微服务名称(nacos微服务提供者叫什么你写什么)
service-url:
nacos-user-service: http://nacos-payment-provider
# 激活Sentinel对Feign的支持
feign:
sentinel:
enabled: true骚戴理解:这里的消费者配置文件里面需要激活Sentinel对Feign的支持
使用@EnableFeignClients
@EnableDiscoveryClient
@SpringBootApplication
@EnableFeignClients
public class Main83
{
public static void main(String[] args)
{
SpringApplication.run(Main83.class,args);
}
}Controller
@RestController
public class OrderNacosController
{
@Resource
private RestTemplate restTemplate;
@Resource
private PayFeignSentinelApi payFeignSentinelApi;
@Value("${service-url.nacos-user-service}")
private String serverURL;
@GetMapping(value = "/consumer/pay/nacos/get/{orderNo}")
public ResultData getPayByOrderNo(@PathVariable("orderNo") String orderNo)
{
return payFeignSentinelApi.getPayByOrderNo(orderNo);
}
}可能存在的bug
报错原因:springboot+springcloud版本太高导致和阿里巴巴Sentinel不兼容
GateWay和Sentinel集成实现服务限流
导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-transport-simple-http</artifactId>
<version>1.8.6</version>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-spring-cloud-gateway-adapter</artifactId>
<version>1.8.6</version>
</dependency>
<dependency>
<groupId>javax.annotation</groupId>
<artifactId>javax.annotation-api</artifactId>
<version>1.3.2</version>
<scope>compile</scope>
</dependency>配置yml
server:
port: 9528
spring:
application:
name: cloudalibaba-sentinel-gateway # sentinel+gataway整合Case
cloud:
nacos:
discovery:
server-addr: localhost:8848
gateway:
routes:
- id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名
uri: http://localhost:9001 #匹配后提供服务的路由地址
predicates:
- Path=/pay/ # 断言,路径相匹配的进行路由配置类
package com.atguigu.cloud.config;
import com.alibaba.csp.sentinel.adapter.gateway.common.rule.GatewayFlowRule;
import com.alibaba.csp.sentinel.adapter.gateway.common.rule.GatewayRuleManager;
import com.alibaba.csp.sentinel.adapter.gateway.sc.SentinelGatewayFilter;
import com.alibaba.csp.sentinel.adapter.gateway.sc.callback.BlockRequestHandler;
import com.alibaba.csp.sentinel.adapter.gateway.sc.callback.GatewayCallbackManager;
import com.alibaba.csp.sentinel.adapter.gateway.sc.exception.SentinelGatewayBlockExceptionHandler;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.Ordered;
import org.springframework.core.annotation.Order;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.codec.ServerCodecConfigurer;
import org.springframework.web.reactive.function.BodyInserters;
import org.springframework.web.reactive.function.server.ServerResponse;
import org.springframework.web.reactive.result.view.ViewResolver;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import javax.annotation.PostConstruct;
import java.util.*;
/
* @auther zzyy
* @create 2023-12-01 15:38
* 使用时只需注入对应的 SentinelGatewayFilter 实例以及 SentinelGatewayBlockExceptionHandler 实例即可
*/
@Configuration
public class GatewayConfiguration {
private final List<ViewResolver> viewResolvers;
private final ServerCodecConfigurer serverCodecConfigurer;
public GatewayConfiguration(ObjectProvider<List<ViewResolver>> viewResolversProvider, ServerCodecConfigurer serverCodecConfigurer)
{
this.viewResolvers = viewResolversProvider.getIfAvailable(Collections::emptyList);
this.serverCodecConfigurer = serverCodecConfigurer;
}
@Bean
@Order(Ordered.HIGHEST_PRECEDENCE)
public SentinelGatewayBlockExceptionHandler sentinelGatewayBlockExceptionHandler() {
// Register the block exception handler for Spring Cloud Gateway.
return new SentinelGatewayBlockExceptionHandler(viewResolvers, serverCodecConfigurer);
}
@Bean
@Order(-1)
public GlobalFilter sentinelGatewayFilter() {
return new SentinelGatewayFilter();
}
@PostConstruct //javax.annotation.PostConstruct
public void doInit() {
initBlockHandler();
}
//处理/自定义返回的例外信息
private void initBlockHandler() {
Set<GatewayFlowRule> rules = new HashSet<>();
rules.add(new GatewayFlowRule("pay_routh1").setCount(2).setIntervalSec(1));
GatewayRuleManager.loadRules(rules);
BlockRequestHandler handler = new BlockRequestHandler() {
@Override
public Mono<ServerResponse> handleRequest(ServerWebExchange exchange, Throwable t) {
Map<String,String> map = new HashMap<>();
map.put("errorCode", HttpStatus.TOO_MANY_REQUESTS.getReasonPhrase());
map.put("errorMessage", "请求太过频繁,系统忙不过来,触发限流(sentinel+gataway整合Case)");
return ServerResponse.status(HttpStatus.TOO_MANY_REQUESTS)
.contentType(MediaType.APPLICATION_JSON)
.body(BodyInserters.fromValue(map));
}
};
GatewayCallbackManager.setBlockHandler(handler);
}
}骚戴理解:GateWay和Sentinel集成实现服务限流的核心内容就在于上面这个配置类,其他东西可以照抄,只有initBlockHandler方法需要根据自己的需求进行重写,下面分开解释代码
Set<GatewayFlowRule> rules = new HashSet<>();
rules.add(new GatewayFlowRule("pay_routh1").setCount(2).setIntervalSec(1));
GatewayRuleManager.loadRules(rules);代码解释:创建一组网关流规则,并将它们加载到规则管理器中。这些规则将限制名为 "pay_routh1" 的网关的请求速率,使其每秒最多处理 2 个请求,setCount(2)是设置请求数量为2,setIntervalSec(1)是设置请求时间为1s,两个配合使用,表示每秒最多处理 2 个请求
BlockRequestHandler handler = new BlockRequestHandler() {
@Override
public Mono<ServerResponse> handleRequest(ServerWebExchange exchange, Throwable t) {
Map<String,String> map = new HashMap<>();
map.put("errorCode", HttpStatus.TOO_MANY_REQUESTS.getReasonPhrase());
map.put("errorMessage", "请求太过频繁,系统忙不过来,触发限流(sentinel+gataway整合Case)");
return ServerResponse.status(HttpStatus.TOO_MANY_REQUESTS)
.contentType(MediaType.APPLICATION_JSON)
.body(BodyInserters.fromValue(map));
}
};代码解释:创建一个块请求处理程序,该处理程序在网关限制请求时被调用。它返回一个 HTTP 响应,其中包含自定义的错误代码和消息。简单来说就是自定义限流后的处理方式
分布式事务处理-SpringCloud Alibaba Seata
分布式事务问题如何产生?
一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务问题。关系型数据库提供的能力是基于单机事务的,一旦遇到分布式事务场景,就需要通过更多其他技术手段来解决问题。
单体应用被拆分成微服务应用,原来的三个模块被拆分成三个独立的应用,分别使用三个独立的数据源,业务操作需要调用三个服务来完成。此时每个服务自己内部的数据一致性由本地事务来保证,但是全局的数据一致性问题没法保证。
Seata简介
Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
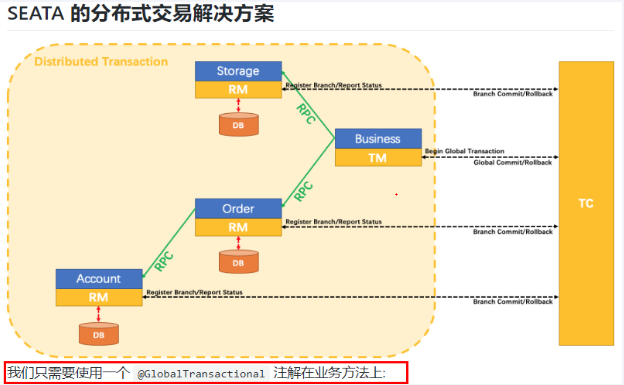
骚戴理解:Seata的使用很简单,在业务方法上面加个注解@GlobalTransactional就行
Seata工作流程简介
Seata对分布式事务的协调和控制就是1+3,其中1是指的XID【全局事务的唯一标识, 它可以在服务的调用链路中传递,绑定到服务的事务上下文中】,3指的是事务协调器、事务管理器、资源管理器这三个
- TC (Transaction Coordinator)-事务协调器:就是Seata,负责维护全局事务和分支事务的状态,驱动全局事务提交或回滚。
- TM (Transaction Manager)-事务管理器:标注全局@GlobalITransactional启动入口动作的微服务模块(比如订单模块),它是事务的发起者,负责定义全局事务的范围,并根据TC维护的全局事务和分支事务状态,做出开始事务、提交事务、回滚事务的决议
- RM (Resource Manager)-资源管理器:就是mysq|数据库本身,可以是多个RM,负责管理分支事务上的资源,向TC注册分支事务,汇报分支事务状态,驱动分支事务的提交或回滚
三个组件相互协作,TC以Seata 服务器(Server)形式独立部署,TM和RM则是以Seata Client的形式集成在微服务中运行,流程如下
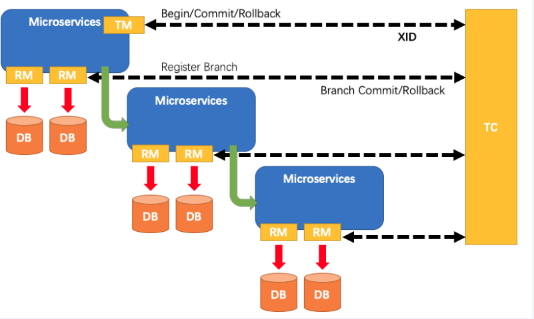
- TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID;
- XID 在微服务调用链路的上下文中传播;
- RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖;
- TM 向 TC 发起针对 XID 的全局提交或回滚决议;
- TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求。
骚戴理解:XID就是用来标识有哪些微服务参与了 这个事务,这样回归的时候就可以根据XID把所有的微服务涉及到的数据库操作都回滚了,TM就是分布式事务的开始,也是@GlobalTransactional注解使用的地方,例如A服务里面调用了B服务和C服务进行数据库操作,那么A服务就是TM,在A服务的业务方法上面使用@GlobalTransactional即可,而ABC三个服务都充当着RM的角色,简单理解就是RM是分事务,TC是管理分事务的,TM是分布式事务的发起者,TM说回滚,那所有的RM作为分事务就回滚各自的操作,它们都有自己的日志操作表,里面记录的操作前的数据,用于回滚
Seata的使用
导入seata脚本
下载seata后,在数据库中创建seata库,执行下面的脚本导入几个系统表到seata库里面
-- -------------------------------- The script used when storeMode is 'db' --------------------------------
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`status` TINYINT NOT NULL,
`application_id` VARCHAR(32),
`transaction_service_group` VARCHAR(32),
`transaction_name` VARCHAR(128),
`timeout` INT,
`begin_time` BIGINT,
`application_data` VARCHAR(2000),
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`xid`),
KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(
`branch_id` BIGINT NOT NULL,
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`resource_group_id` VARCHAR(32),
`resource_id` VARCHAR(256),
`branch_type` VARCHAR(8),
`status` TINYINT,
`client_id` VARCHAR(64),
`application_data` VARCHAR(2000),
`gmt_create` DATETIME(6),
`gmt_modified` DATETIME(6),
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(
`row_key` VARCHAR(128) NOT NULL,
`xid` VARCHAR(128),
`transaction_id` BIGINT,
`branch_id` BIGINT NOT NULL,
`resource_id` VARCHAR(256),
`table_name` VARCHAR(32),
`pk` VARCHAR(36),
`status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`row_key`),
KEY `idx_status` (`status`),
KEY `idx_branch_id` (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE IF NOT EXISTS `distributed_lock`
(
`lock_key` CHAR(20) NOT NULL,
`lock_value` VARCHAR(20) NOT NULL,
`expire` BIGINT,
primary key (`lock_key`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('AsyncCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryRollbacking', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('TxTimeoutCheck', ' ', 0);
修改配置文件
修改seata-server-2.0.0\conflapplication.yml配置文件,记得先备份
# Copyright 1999-2019 Seata.io Group.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
server:
port: 7091
spring:
application:
name: seata-server
logging:
config: classpath:logback-spring.xml
file:
path: ${log.home:${user.home}/logs/seata}
extend:
logstash-appender:
destination: 127.0.0.1:4560
kafka-appender:
bootstrap-servers: 127.0.0.1:9092
topic: logback_to_logstash
console:
user:
username: seata
password: seata
seata:
config:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
namespace:
group: SEATA_GROUP #后续自己在nacos里面新建,不想新建SEATA_GROUP,就写DEFAULT_GROUP
username: nacos
password: nacos
registry:
type: nacos
nacos:
application: seata-server
server-addr: 127.0.0.1:8848
group: SEATA_GROUP #后续自己在nacos里面新建,不想新建SEATA_GROUP,就写DEFAULT_GROUP
namespace:
cluster: default
username: nacos
password: nacos
store:
mode: db
db:
datasource: druid
db-type: mysql
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/seata?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&rewriteBatchedStatements=true&allowPublicKeyRetrieval=true
user: root
password: 123456
min-conn: 10
max-conn: 100
global-table: global_table
branch-table: branch_table
lock-table: lock_table
distributed-lock-table: distributed_lock
query-limit: 1000
max-wait: 5000
# server:
# service-port: 8091 #If not configured, the default is '${server.port} + 1000'
security:
secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017
tokenValidityInMilliseconds: 1800000
ignore:
urls: /,//*.css,//*.js,//*.html,//*.map,//*.svg,//*.png,//*.jpeg,//*.ico,/api/v1/auth/login,/metadata/v1/骚戴理解:这里主要是配置服务的注册发现地址和seata的系统库的地址,也就是前面创建的那个seata库,同时要记得启动Nacos,因为seata是注册到Nacos里面的,所以要先启动Nacos,然后启动Seata
模拟实践
模拟场景:这里我们创建三个服务,一个订单服务,一个库存服务,一个账户服务。当用户下单时,会在订单服务中创建一个订单,然后通过远程调用库存服务来扣减下单商品的库存,再通过远程调用账户服务来扣减用户账户里面的余额,
最后在订单服务中修改订单状态为已完成。该操作跨越三个数据库,有两次远程调用,很明显会有分布式事务问题。
导入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.atguigu.cloud</groupId>
<artifactId>mscloudV5</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>seata-order-service2001</artifactId>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- nacos -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--alibaba-seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
<!--openfeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!--loadbalancer-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<!--cloud-api-commons-->
<dependency>
<groupId>com.atguigu.cloud</groupId>
<artifactId>cloud-api-commons</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<!--web + actuator-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--SpringBoot集成druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
</dependency>
<!-- Swagger3 调用方式 http://你的主机IP地址:5555/swagger-ui/index.html -->
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
</dependency>
<!--mybatis和springboot整合-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
<!--Mysql数据库驱动8 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--persistence-->
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>persistence-api</artifactId>
</dependency>
<!--通用Mapper4-->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper</artifactId>
</dependency>
<!--hutool-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
</dependency>
<!-- fastjson2 -->
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.28</version>
<scope>provided</scope>
</dependency>
<!--test-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>每个业务库里面的日志表undo log(AT模式专用,其它模式不需要)
-- for AT mode you must to init this sql for you business database. the seata server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';
ALTER TABLE `undo_log` ADD INDEX `ix_log_created` (`log_created`);修改yml
server:
port: 2001
spring:
application:
name: seata-order-service
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
# ==========applicationName + druid-mysql8 driver===================
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/seata_order?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&rewriteBatchedStatements=true&allowPublicKeyRetrieval=true
username: root
password: 123456
# ========================mybatis===================
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.atguigu.cloud.entities
configuration:
map-underscore-to-camel-case: true
# ========================seata===================
seata:
registry: # seata注册配置
type: nacos # seata注册类型
nacos:
server-addr: 127.0.0.1:8848
namespace: ""
group: SEATA_GROUP
application: seata-server
tx-service-group: default_tx_group # 事务组,由它获得TC服务的集群名称
service:
vgroup-mapping: # 点击源码分析
default_tx_group: default # 事务组与TC服务集群的映射关系
data-source-proxy-mode: AT
logging:
level:
io:
seata: infoService中使用 @GlobalTransactional
package com.atguigu.cloud.service.impl;
import com.atguigu.cloud.apis.AccountFeignApi;
import com.atguigu.cloud.apis.StorageFeignApi;
import com.atguigu.cloud.entities.Order;
import com.atguigu.cloud.mapper.OrderMapper;
import com.atguigu.cloud.service.OrderService;
import io.seata.core.context.RootContext;
import io.seata.rm.tcc.api.LocalTCC;
import io.seata.spring.annotation.GlobalTransactional;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import tk.mybatis.mapper.entity.Example;
import java.util.concurrent.atomic.AtomicInteger;
/
* @auther zzyy
* @create 2023-12-01 17:53
* 下订单->减库存->扣余额->改(订单)状态
*/
@Slf4j
@Service
public class OrderServiceImpl implements OrderService
{
@Resource
private OrderMapper orderMapper;
@Resource//订单微服务通过OpenFeign去调用库存微服务
private StorageFeignApi storageFeignApi;
@Resource//订单微服务通过OpenFeign去调用账户微服务
private AccountFeignApi accountFeignApi;
@Override
@GlobalTransactional(name = "zzyy-create-order",rollbackFor = Exception.class) //AT
//@GlobalTransactional @Transactional(rollbackFor = Exception.class) //XA
public void create(Order order) {
//xid检查
String xid = RootContext.getXID();
//1. 新建订单
log.info("==================>开始新建订单"+"\t"+"xid_order:" +xid);
//订单状态status:0:创建中;1:已完结
order.setStatus(0);
int result = orderMapper.insertSelective(order);
//插入订单成功后获得插入mysql的实体对象
Order orderFromDB = null;
if(result > 0)
{
orderFromDB = orderMapper.selectOne(order);
//orderFromDB = orderMapper.selectByPrimaryKey(order.getId());
log.info("-------> 新建订单成功,orderFromDB info: "+orderFromDB);
System.out.println();
//2. 扣减库存
log.info("-------> 订单微服务开始调用Storage库存,做扣减count");
storageFeignApi.decrease(orderFromDB.getProductId(), orderFromDB.getCount());
log.info("-------> 订单微服务结束调用Storage库存,做扣减完成");
System.out.println();
//3. 扣减账号余额
log.info("-------> 订单微服务开始调用Account账号,做扣减money");
accountFeignApi.decrease(orderFromDB.getUserId(), orderFromDB.getMoney());
log.info("-------> 订单微服务结束调用Account账号,做扣减完成");
System.out.println();
//4. 修改订单状态
//订单状态status:0:创建中;1:已完结
log.info("-------> 修改订单状态");
orderFromDB.setStatus(1);
Example whereCondition=new Example(Order.class);
Example.Criteria criteria=whereCondition.createCriteria();
criteria.andEqualTo("userId",orderFromDB.getUserId());
criteria.andEqualTo("status",0);
int updateResult = orderMapper.updateByExampleSelective(orderFromDB, whereCondition);
log.info("-------> 修改订单状态完成"+"\t"+updateResult);
log.info("-------> orderFromDB info: "+orderFromDB);
}
System.out.println();
log.info("==================>结束新建订单"+"\t"+"xid_order:" +xid);
}
}骚戴理解:用起来很简单,只需要在事务发起的业务方法上面使用@GlobalTransactional即可,剩下的都是简单的业务没必要做笔记,这里只要知道怎么用就行
@GlobalTransactional(name = "zzyy-create-order",rollbackFor = Exception.class)
- name="zzyy-create-order":指定事务的名称。这对于跟踪和管理分布式事务非常有用。
- rollbackFor = Exception.class:指定引发哪些类型的异常会导致事务回滚。在本例中,如果方法抛出任何类型的异常(包括检查异常和非检查异常),事务都将回滚。
可能会出现的bug
springboot+springcloud版本太高导致和阿里巴巴Seata不兼容
解决办法:降低版本处理下
<spring.boot.version>3.1.7</spring.boot.version>
<spring.cloud.version>2022.0.4</spring.cloud.version>AT模式如何做到对业务的无侵入
在一阶段,Seata 会拦截“业务 SQL”,
1 解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”
2 执行“业务 SQL”更新业务数据,在业务数据更新之后,其保存成“after image”,最后生成行锁。
以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
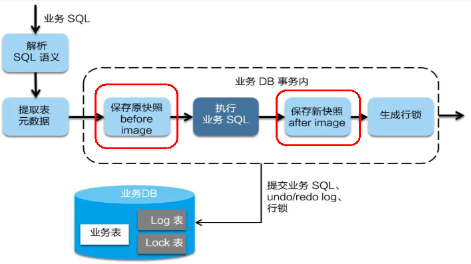
二阶段顺利提交:
二阶段如是顺利提交的话,因为“业务 SQL”在一阶段已经提交至数据库,所以Seata框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
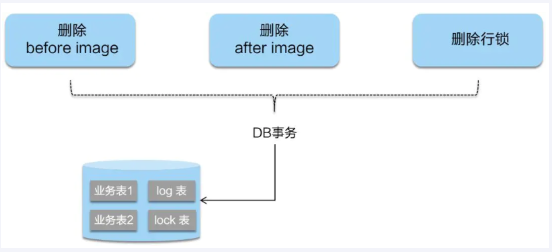
二阶段回滚:
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。
回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
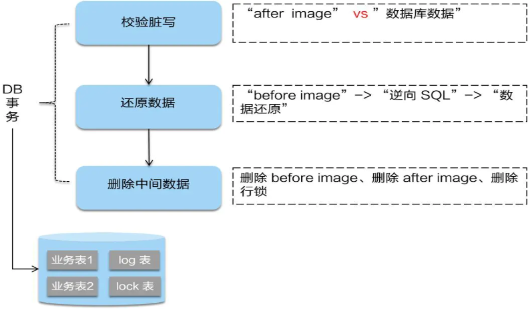


























![[StartingPoint][Tier1]Crocodile](https://img-blog.csdnimg.cn/img_convert/9d0a20a13252870e2d96b07d88b06171.jpeg)