troop主页
今日鸡汤:Never bend your head.Always hold it high.Look the world straight in the face.
加油!成为最好的编程大师
前言
我们前几篇文章讲了搜索二叉树,我们提到了搜索二叉树的应用就是K结构和KV结构,今天我们要提到的这两个关联式容器就是这两个结构的实现,废话少说直接今日我们的内容。
一,set
- set是按照一定次序存储元素的容器
- 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。
set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。 - 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行
排序。 - set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对
子集进行直接迭代。 - set在底层是用二叉搜索树(红黑树)实现的。
最后一点也是我们后面学习的重点。
1.1set的使用

这里的Compare就是比较大小,默认是按照小于的比较。
set的使用上没有太多可以讲的,他的绝大多数容器我们都是可以类比之前学习过的。
我们直接写一些代码来熟悉它。
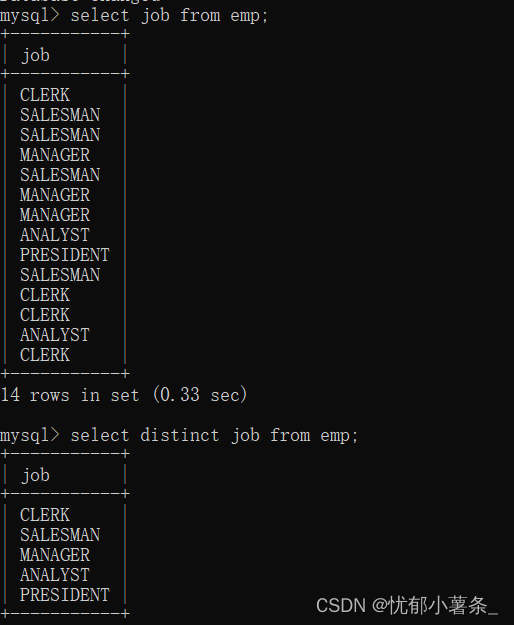
//去重+排序
set<int> s;
s.insert(2);
s.insert(7);
s.insert(7);
s.insert(1);
s.insert(10);
s.insert(9);
s.insert(14);
s.insert(17);
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
it++;
}
cout << endl;
set就是二叉搜索树的K结构,她最基本就是排序+去重操作。

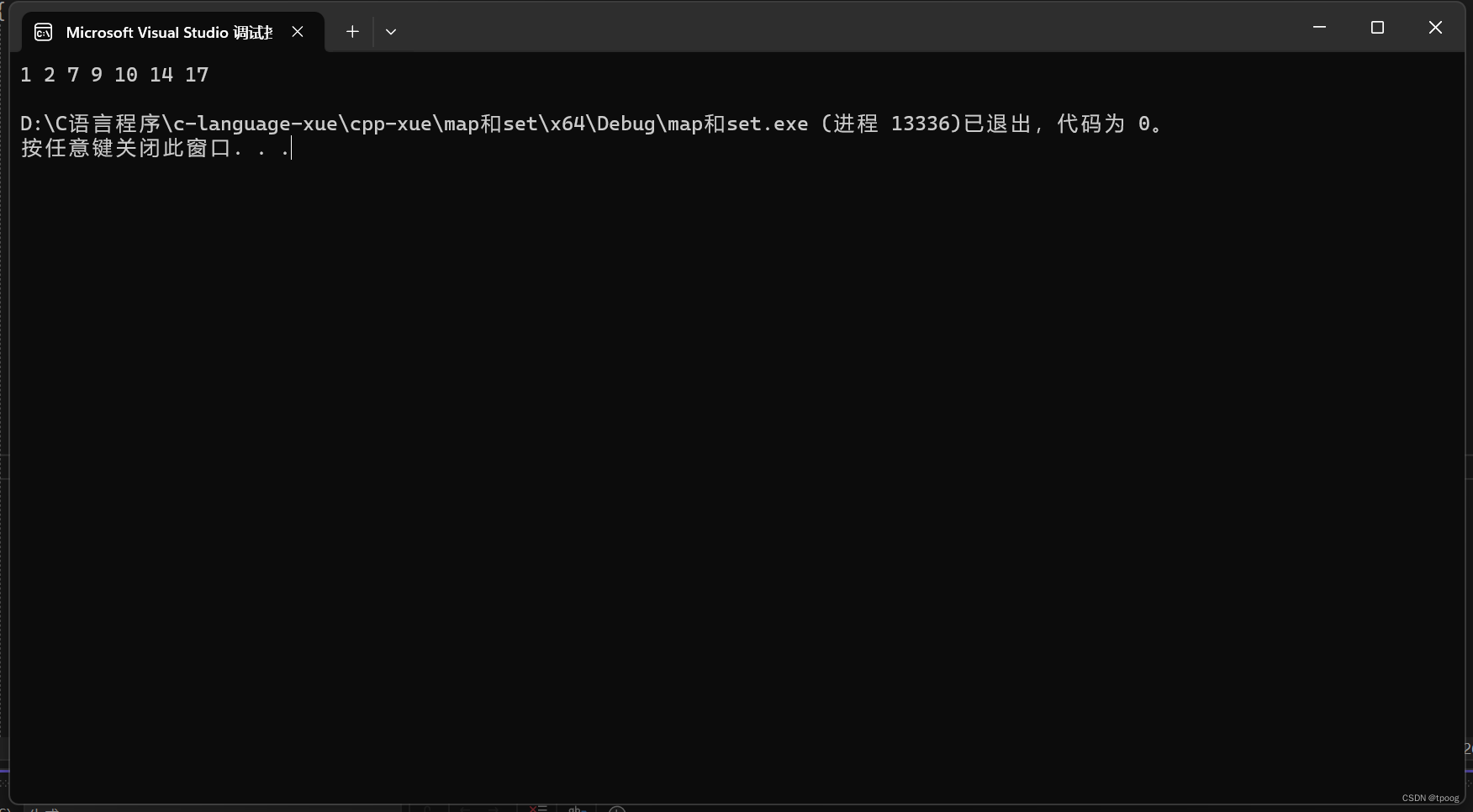
值得注意的是set的find,它的返回值是一个迭代器,并且当找不到这个数的时候返回的是set的最后一个位置,那么我们的代码就可以这样写。
set<int>::iterator pos1 = s.find(7);
if (pos1 != s.end())
{
cout << "找到了" << endl;
}
else
{
cout << "没有" << endl;
}
cout << endl;
set<int>::iterator pos2 = s.find(100);
if (pos2 != s.end())
{
cout << "找到了" << endl;
}
else
{
cout << "没有" << endl;
}
cout << endl;
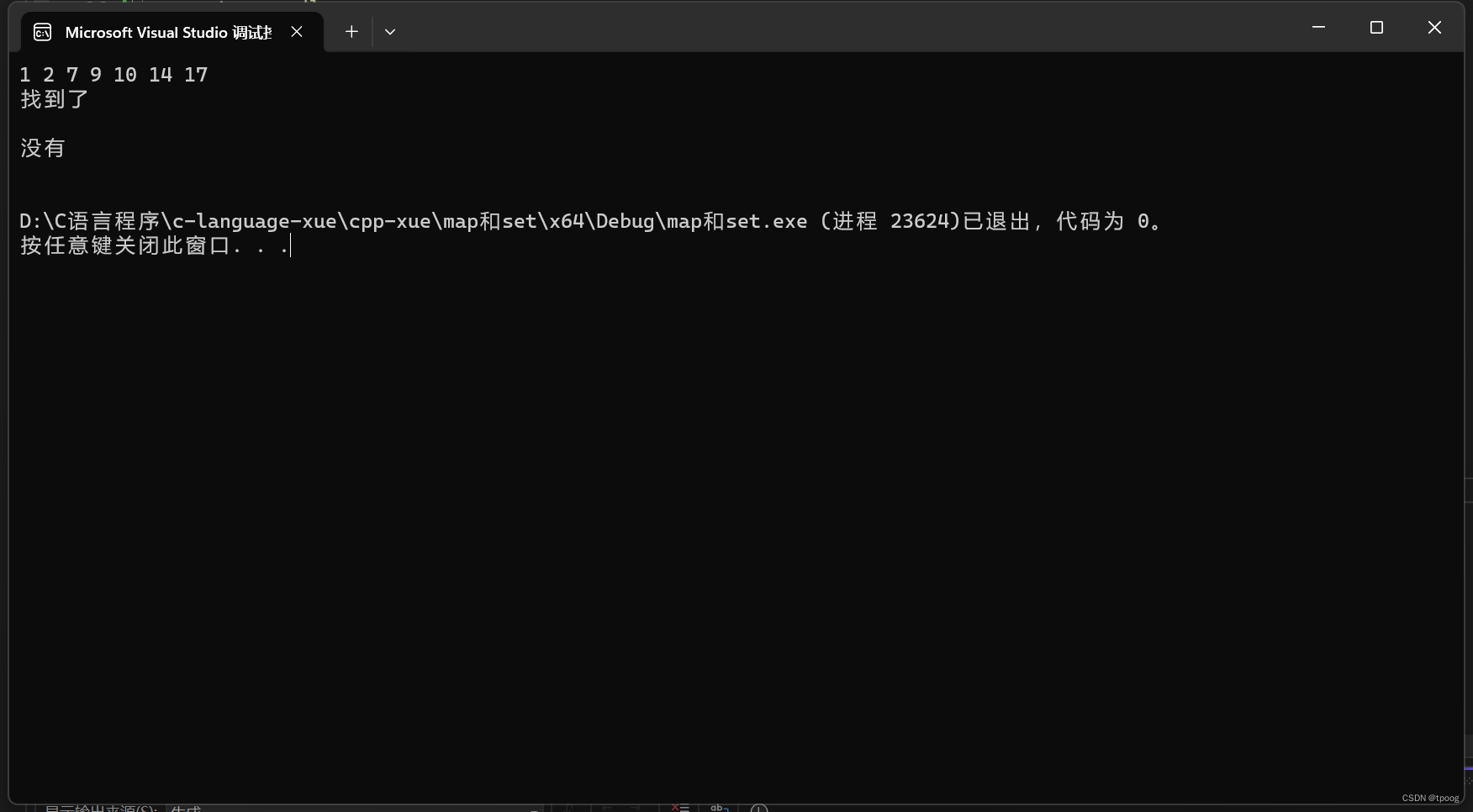
同时set还有一个新的函数count

与find类似它也是查找,但他会返回这个数出现的次数,但是我们知道set是去重操作的,这个数最多一个。
这个函数是给multiset使用的。
特殊的set(multiset)
这个multiset就可以称得上真正的排序了,因为它只排序不去重
multiset<int> s;
s.insert(2);
s.insert(7);
s.insert(7);
s.insert(7);
s.insert(7);
s.insert(7);
s.insert(1);
s.insert(10);
s.insert(9);
s.insert(14);
s.insert(17);
for (auto& e : s)
{
cout << e << " ";
}
cout << endl;
cout << s.count(7) << endl;
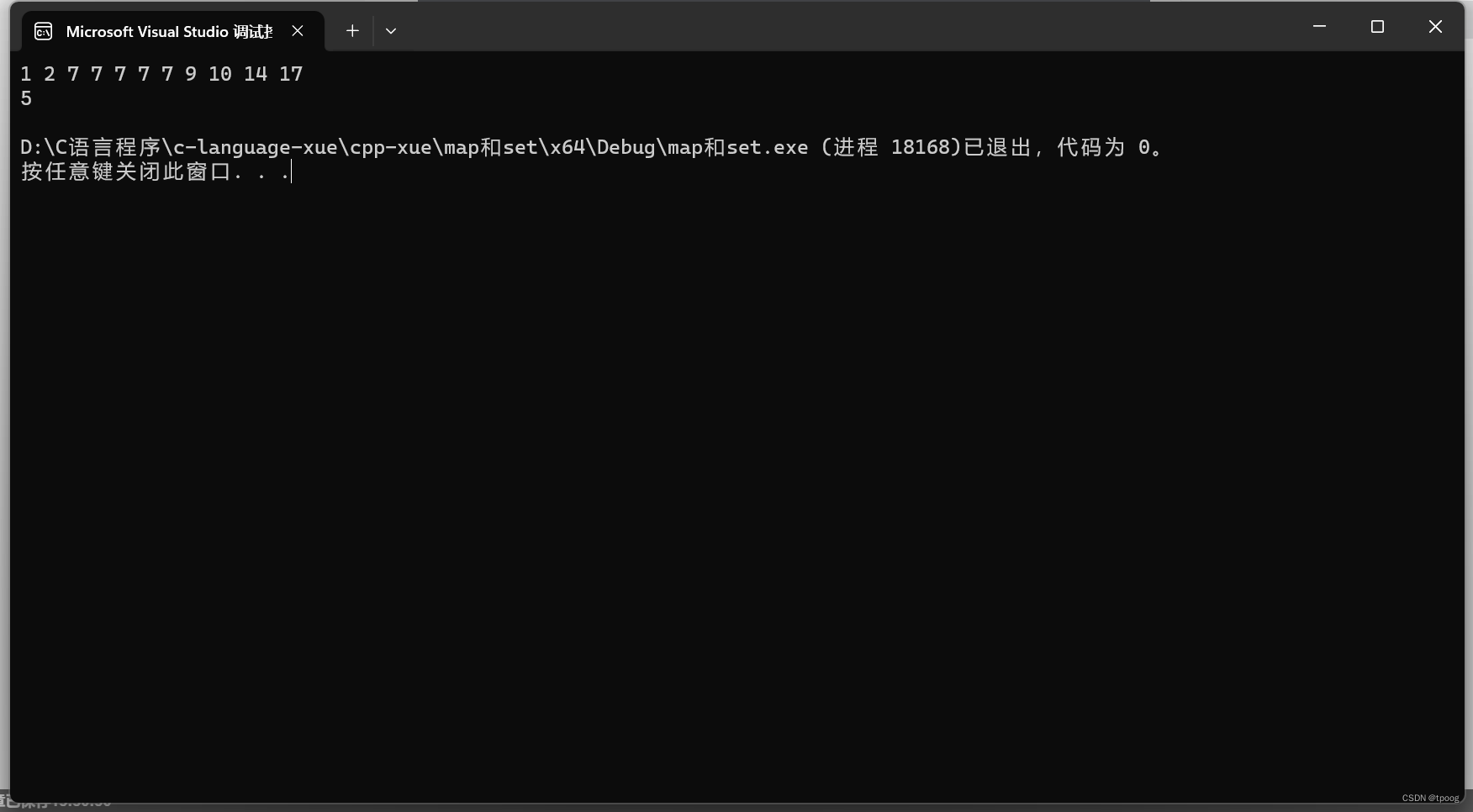
这里的count就发挥了他的作用了。
二,map
- map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元
素。 - 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的
内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型
value_type绑定在一起,为其取别名称为pair:
typedef pair<const key, T> value_type; - 在内部,map中的元素总是按照键值key进行比较排序的。
- map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序
对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。 - map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
- map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
2.2map的使用


map就是KV结构,C++这里的设计就是把KV一起放在一个结构体中去使用。
我们来看看map的插入。

注意看,insert的pair和上面的pair是两个不一样的pair,等会到[]我们会重点提到这个。
insert的插入方式有很多。
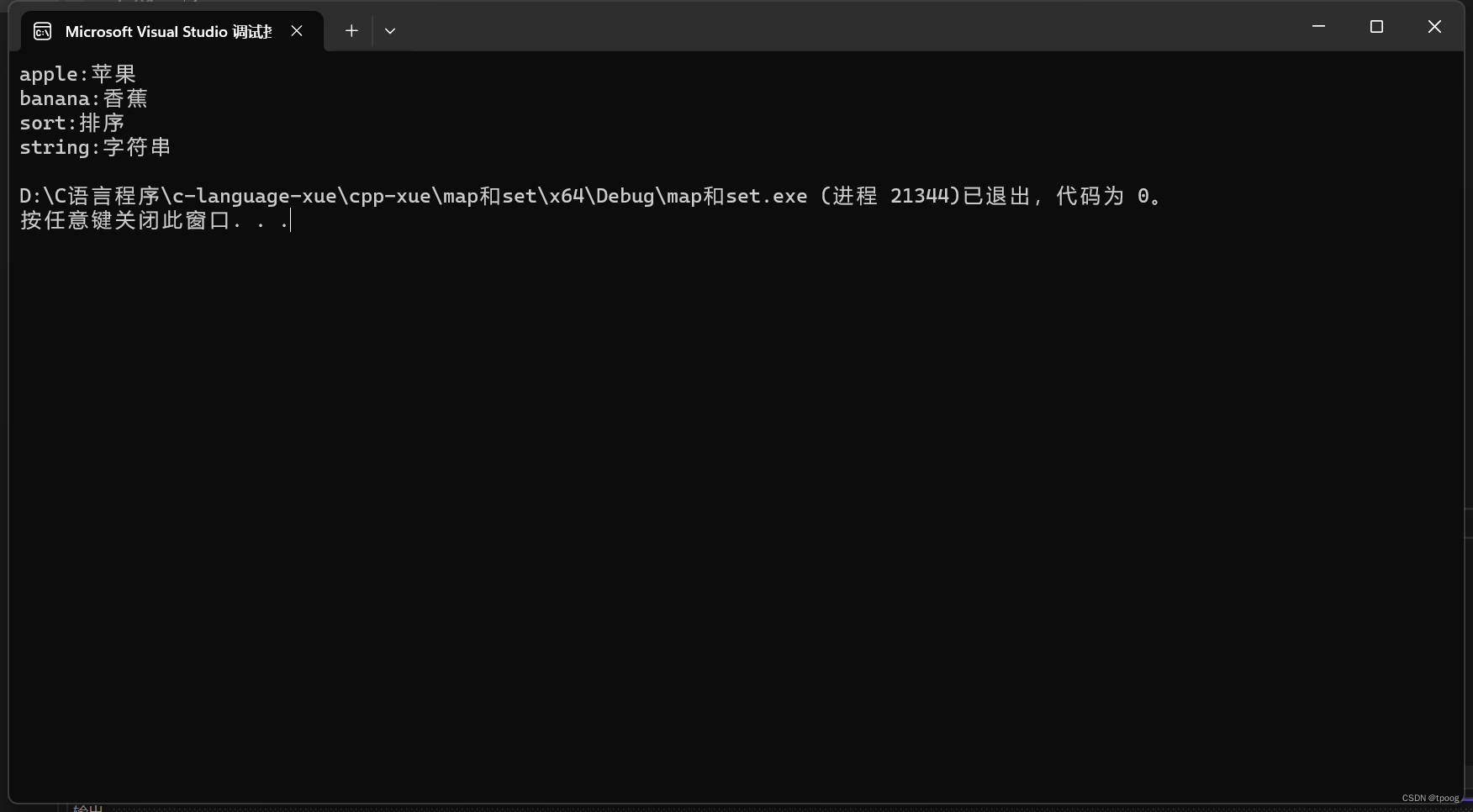
map<string, string> dict;
//匿名对象
dict.insert(pair<string, string>("sort", "排序"));
//有名对象
pair<string, string> kv("string", "字符串");
dict.insert(kv);
//{}:c++11支持的隐式类型转换
dict.insert({ "apple","苹果" });
//make_pair:c++98
dict.insert(make_pair("banana", "香蕉"));
我个人更喜欢make_pair这样的写法。
map<string, string> dict;
//匿名对象
dict.insert(pair<string, string>("sort", "排序"));
//有名对象
pair<string, string> kv("string", "字符串");
dict.insert(kv);
//{}:c++11支持的隐式类型转换
dict.insert({ "apple","苹果" });
//make_pair:c++98
dict.insert(make_pair("banana", "香蕉"));
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{
//cout << (*it).first << (*it).second << endl;
//it->==pair*;pair->first 优化成一个->
cout << it->first << it->second << endl;
++it;
}
这里我们要说一说
cout << it->first << it->second << endl;
这里省略了一个->,他的完整操作是operator调用->,返回了数据的指针(pair*),然后pair*再调用->。这里优化成了一个箭头。
还有一点要注意:map里面看数据重不重复,只看key,只要key相同就构成冗余
同样的map也有一个支持冗余的就是:multimap
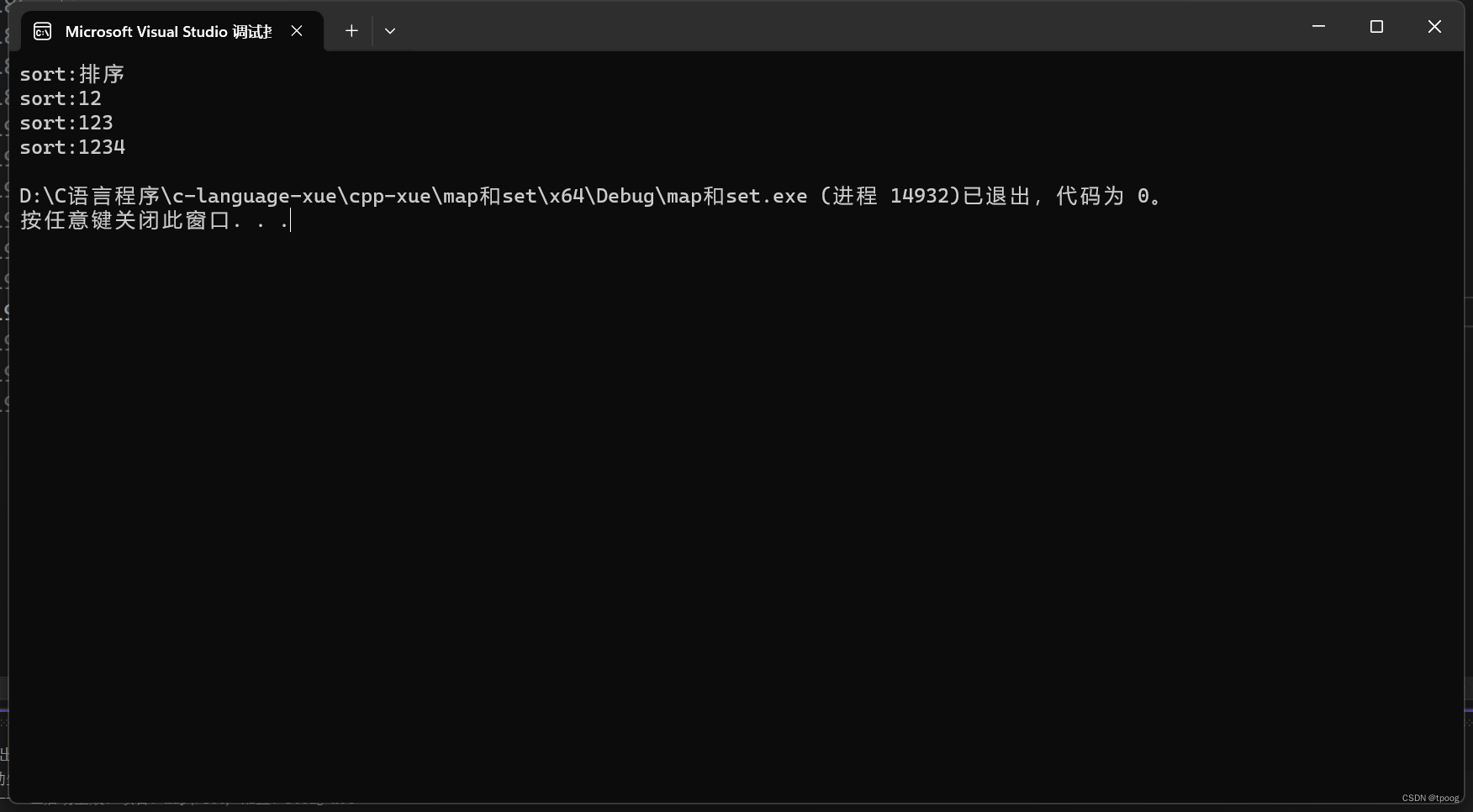
void map_test2()
{
multimap<string, string> dict;
dict.insert(pair<string, string>("sort", "排序"));
dict.insert(pair<string, string>("sort", "12"));
dict.insert(pair<string, string>("sort", "123"));
dict.insert(pair<string, string>("sort", "1234"));
for (auto& kv : dict)
{
cout << kv.first<<":" << kv.second << endl;
}
}
2.3
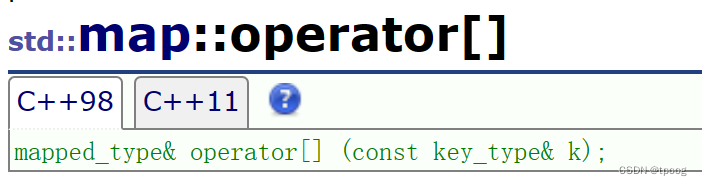

上面的翻译大致是:调用[]相当于调用这一大串。
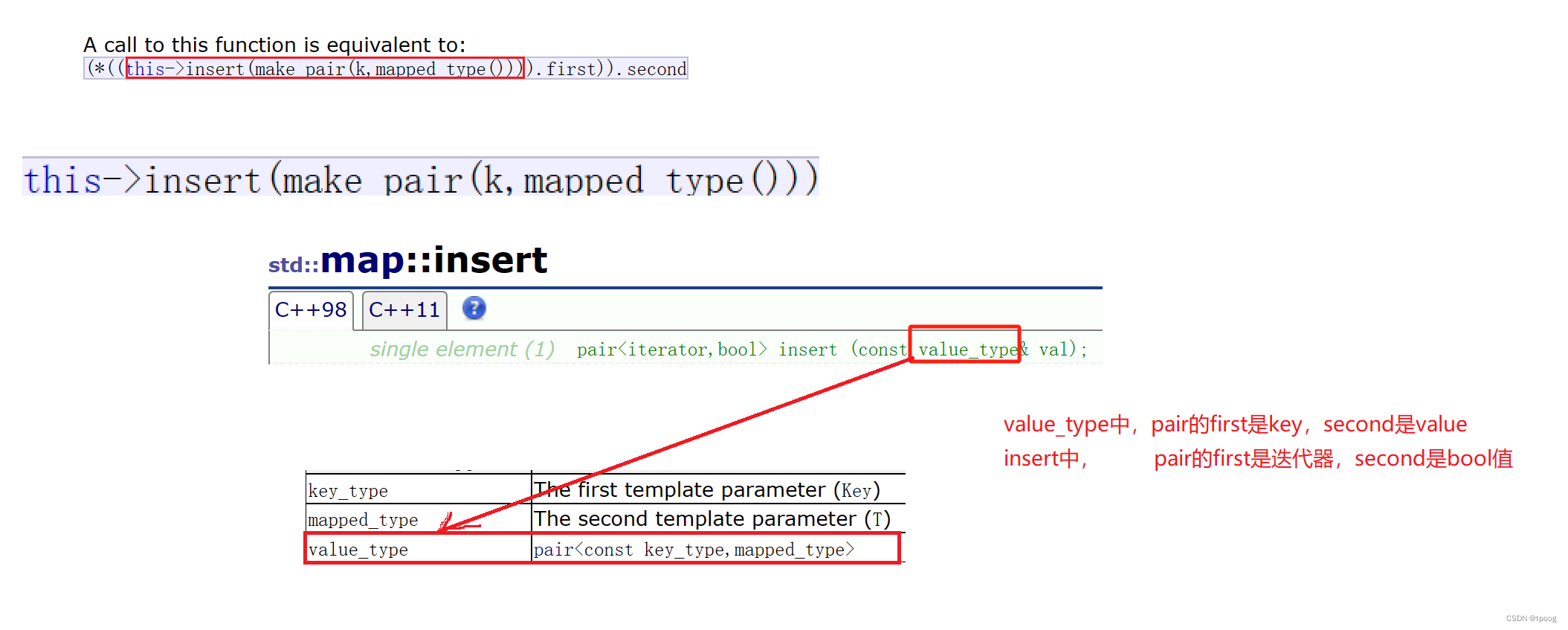
==intsert中的pair的first指向了被插入元素所在位置的迭代器。
string arr[] = { "香蕉","橘子","梨","苹果","草莓","香蕉","橘子", "香蕉","橘子", "香蕉","橘子", "香蕉","橘子",
"西瓜","榴莲" };
map<string, int> countMap;
for (auto& e : arr)
{
pair<map<string, int>::iterator, bool> ret;
ret = countMap.insert(make_pair(e, 1));
//如果不存在那就直接插入,如果存在那这个inset什么事情都不会干,此时这里的bool值就是false
if (ret.second == false)
{
//ret.first==iterator(被插入元素所在位置的迭代器),这个元素的second就是记录个数的
ret.first->second++;
}
}
ret.first==iterator(被插入元素所在位置的迭代器);
理解了[]的原理,下标还是非常的好用的。上面这个统计次数的代码,用下标只要一行。
for (auto& e : arr)
{
countMap[e]++;
}
总结
总的来说map和set就是我们已经学过的知识,知识换了包装而已,这里的重点就是要理解这个下标的原理,多通过代去深化自己的知识,下一节我们就要开始讲
AVL树和红黑树了。