温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
本项目通过集成网络爬虫技术,实时获取海量汽车数据;运用先进的ARIMA时序建模算法对数据进行深度挖掘和分析;结合flask web系统和echarts可视化工具,为用户提供直观、易用的操作界面。系统主要包含汽车销量分析、汽车品牌车系分析、汽车评分分析、汽车指导价分析、汽车价格预测和汽车个性化推荐等功能模块,旨在为汽车行业从业者、消费者及研究人员提供全面、准确的数据支持和服务。
B站详情及代码资料下载:基于大数据的汽车信息可视化分析预测与推荐系统_哔哩哔哩_bilibili
基于大数据的汽车信息可视化分析预测与推荐系统
2. 汽车信息采集
利用 requests、beautifulsoup等工具包,模拟采集并解析各品牌汽车的品牌、车系、评分、级别、车身结构、发动机、变速箱、指导价、销量等多维数据,经过数据清洗和格式化,并进行数据的存储:
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
soup = BeautifulSoup(response.text, 'lxml')
cars = soup.select('div.list-cont')
brand_cars = []
for car in cars:
try:
car_info = {'品牌': brand}
name = car.select('a.font-bold')[0].text
score = car.select('span.score-number')
if len(score) == 0:
score = '暂无'
else:
score = score[0].text
car_info['车系'] = name
car_info['评分'] = score
ul = car.select('ul.lever-ul')[0]
for li in ul.select('li'):
data = li.text.replace('\xa0', '').replace(' ', '').replace(' ', '').strip().split(':')
if '颜色' in data[0]: continue
if len(data) < 2: continue
car_info[data[0]] = data[1]
price = car.select('span.font-arial')[0].text
price = price.split('-')
if len(price) == 1:
car_info['最低指导价'] = price[0]
car_info['最高指导价'] = price[0]
else:
car_info['最低指导价'] = price[0] + '万'
car_info['最高指导价'] = price[1]
car_info['链接'] = url
brand_cars.append(car_info)
except:
print('error...')
continue汽车销量数据采集:
def factory_car_sell_count_spider():
"""
中国汽车分厂商每月销售量
https://XXXXXXX/factory.html
"""
base_url = 'https://XXXXXXX/factory-{}-{}-{}.html'
year_month = '201506'
factory_month_sell_counts = []
now_date = datetime.now().strftime("%Y%m")
while year_month < now_date:
for page_i in range(1, 5):
try:
url = base_url.format(year_month, year_month, page_i)
print(url)
resp = requests.get(url, headers=headers)
resp.encoding = 'utf8'
soup = BeautifulSoup(resp.text, 'lxml')
table = soup.select('table.xl-table-def')
trs = table[0].find_all('tr')
for tr in trs:
tds = tr.find_all('td')
if len(tds) < 4: continue
# 厂商logo
......
factory_month_sell_counts.append((year_month, factory_logo, factory, sell_count, ratio))
time.sleep(1)
except:
print('error...')
continue
# 下个月份
......3. 基于大数据的汽车信息可视化分析预测与推荐系统
3.1 系统首页与注册登录
3.2 汽车销量分析
该功能模块使用Python中的Pandas库对汽车销量数据进行分析和可视化。首先,通过读取汽车销量数据,将数据加载到Pandas的DataFrame对象中。然后,利用Pandas提供的数据处理和分析功能,对销量数据进行统计分析,最后,利用echarts库生成柱状图和饼状图,直观地展示汽车销量的分布情况和占比情况。

3.3 汽车品牌车系分析
分析不同汽车品牌的车系数量、与汽车类型的分布情况:

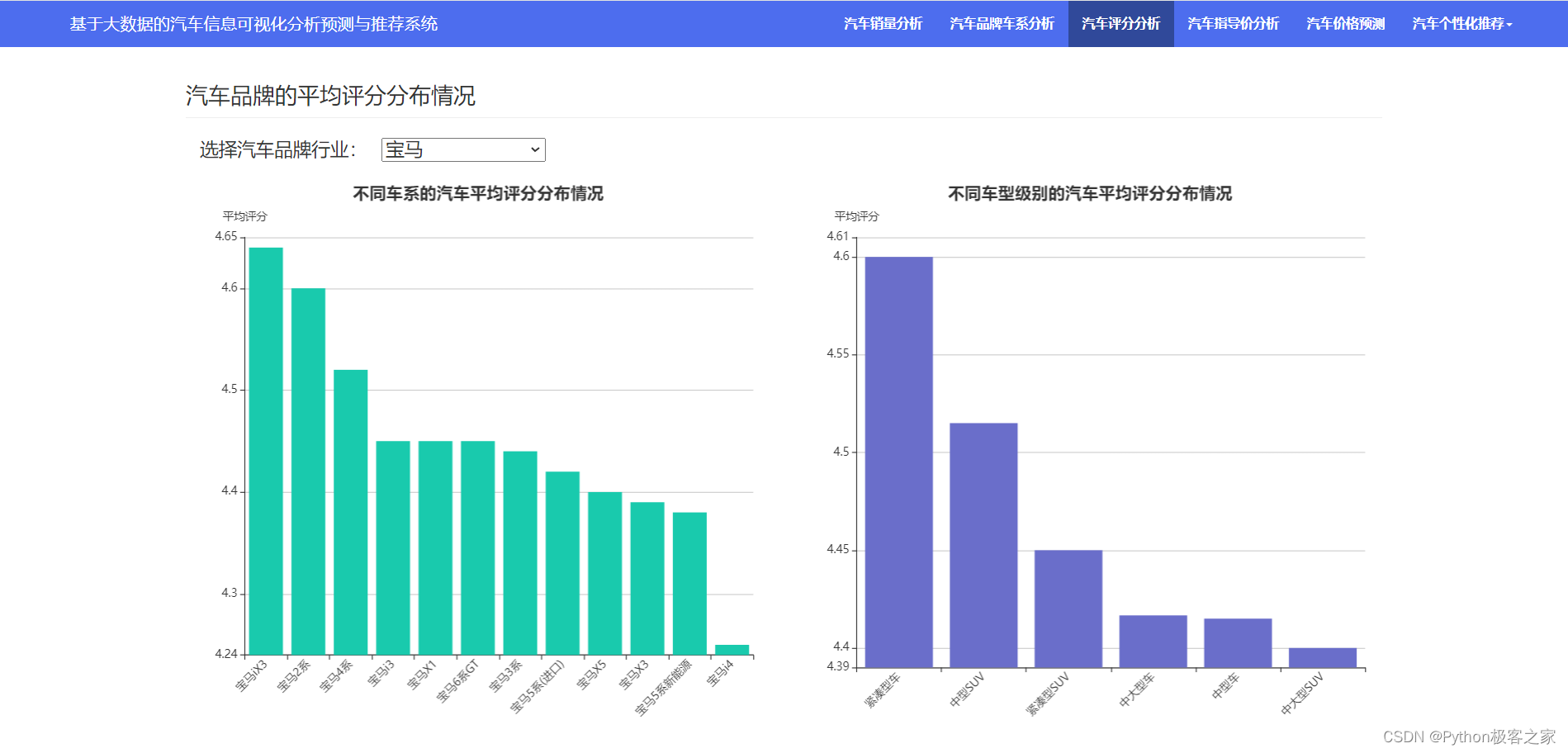
3.4 汽车评分分析
分析不同品牌汽车、不同车系、车型级别的评分分布情况:
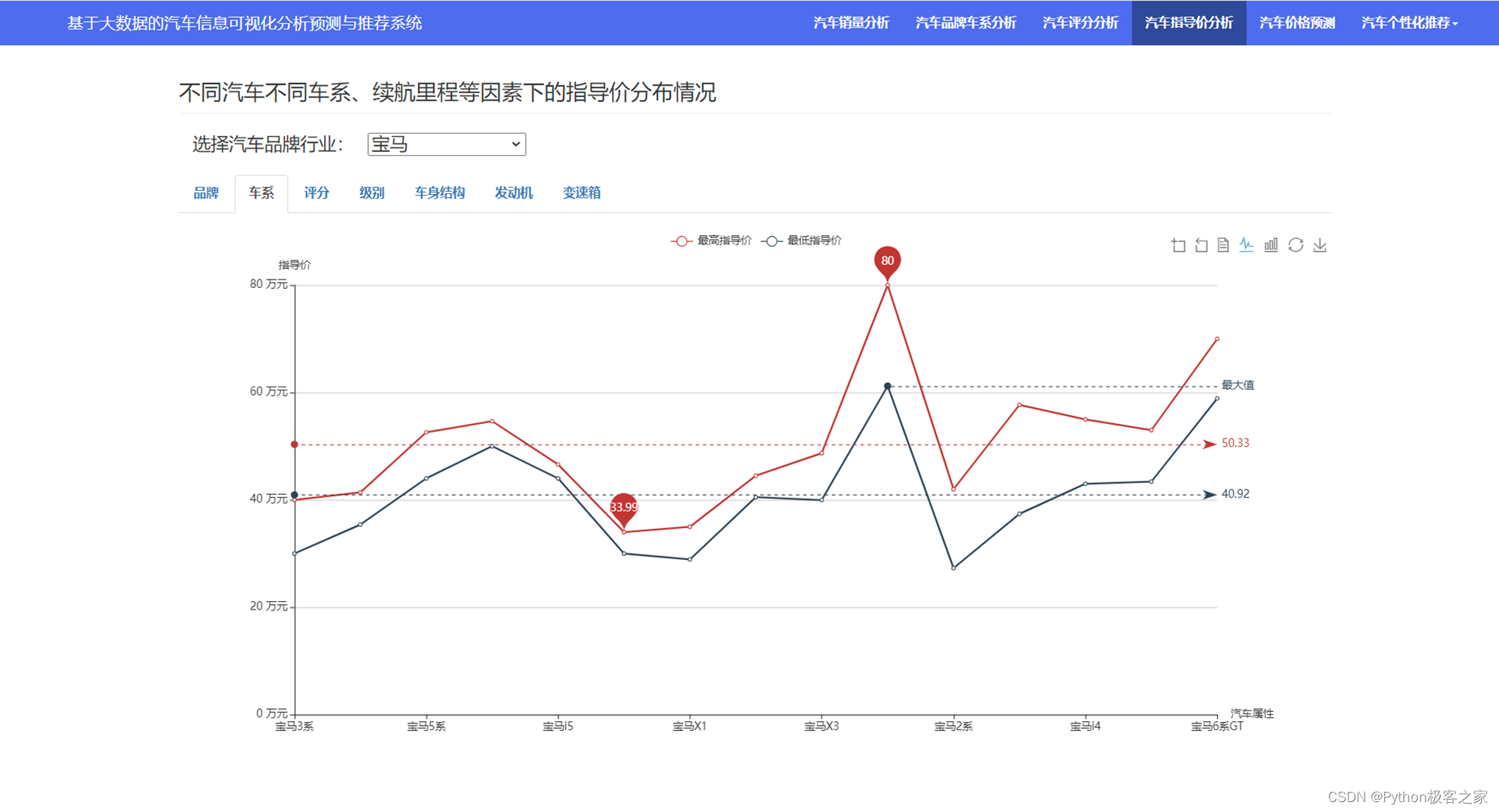
3.5 汽车指导价分析
分析不同汽车不同车系、续航里程等因素下的指导价分布情况:
3.6 基于决策树算法的汽车价格预测
利用 Xgboost 构建决策树回归算法,实现对汽车指导价的预测建模:
df_columns = dataset.columns.values
print('---> cv train to choose best_num_boost_round')
all_y = np.log1p(all_y)
dtrain = xgb.DMatrix(all_x, label=all_y, feature_names=df_columns)
xgb_params = {
'learning_rate': 0.01,
'max_depth': 4,
'eval_metric': 'rmse',
'objective': 'reg:linear',
'nthread': -1,
'silent': 1,
'booster': 'gbtree'
}
cv_result = xgb.cv(dict(xgb_params),
dtrain,
num_boost_round=4000,
early_stopping_rounds=100,
verbose_eval=100,
show_stdv=False,
)
best_num_boost_rounds = len(cv_result)
mean_train_logloss = cv_result.loc[best_num_boost_rounds -
11: best_num_boost_rounds - 1, 'train-rmse-mean'].mean()
mean_test_logloss = cv_result.loc[best_num_boost_rounds -
11: best_num_boost_rounds - 1, 'test-rmse-mean'].mean()
print('best_num_boost_rounds = {}'.format(best_num_boost_rounds))
print('mean_train_rmse = {:.7f} , mean_valid_rmse = {:.7f}\n'.format(
mean_train_logloss, mean_test_logloss))
print('---> training on total dataset to predict test and submit')
model = xgb.train(dict(xgb_params),
dtrain,
num_boost_round=best_num_boost_rounds)
# 特征重要程度
feature_importance = model.get_fscore()
feature_importance = sorted(
feature_importance.items(), key=lambda d: d[1], reverse=True) 3.7 汽车个性化推荐
3.7 汽车个性化推荐
3.7.1 基于内容的汽车品牌车型推荐
基于内容的汽车推荐,基于用户选择的汽车品牌、车型级别、和价格区间,进行符合筛选条件的汽车车型推荐:

3.7.2 基于用户行为的汽车车型推荐
针对用户选择喜欢的车型数据,构建用户画像特征向量、汽车特征向量,通过计算向量余弦相似度,进行汽车车型的推荐:
def cos_sim(x, y):
"""
余弦相似性
input: x(mat):以行向量的形式存储,可以是用户或者商品
y(mat):以行向量的形式存储,可以是用户或者商品
output: x和y之间的余弦相似度
"""
x = x.reshape(1, -1)
y = y.reshape(1, -1)
numerator = x * y.T # x和y之间的内积
denominator = np.sqrt(x * x.T) * np.sqrt(y * y.T)
return (numerator / (denominator + 0.000001))[0, 0]
def similarity(data):
"""
计算矩阵中任意两行之间的相似度
input: data(mat):任意矩阵
output: w(mat):任意两行之间的相似度
"""
m = np.shape(data)[0] # 用户的数量
# 初始化相似度矩阵
w = np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(i, m):
if j != i:
# 计算任意两行之间的相似度
w[i, j] = cos_sim(data[i,], data[j,])
w[j, i] = w[i, j]
else:
w[i, j] = 0
return w
def top_k(predict, k):
"""
为用户推荐前k个商品
input: predict(list):排好序的商品列表
k(int):推荐的商品个数
output: top_recom(list):top_k个商品
"""
top_recom = []
len_result = len(predict)
if k >= len_result:
top_recom = predict
else:
for i in range(k):
top_recom.append(predict[i])

4. 总结
本项目通过集成网络爬虫技术,实时获取海量汽车数据;运用先进的ARIMA时序建模算法对数据进行深度挖掘和分析;结合flask web系统和echarts可视化工具,为用户提供直观、易用的操作界面。系统主要包含汽车销量分析、汽车品牌车系分析、汽车评分分析、汽车指导价分析、汽车价格预测和汽车个性化推荐等功能模块,旨在为汽车行业从业者、消费者及研究人员提供全面、准确的数据支持和服务。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:

























](https://img-blog.csdnimg.cn/direct/0350c35cfed5410195639b4926a3a40d.png)