时间序列的表示
题外话:在自然界中,我们接触到的信号都是模拟信号,在手机、电脑等电子设备中存储的信号是数字信号。我们通常对模拟信号进行等间隔取样得到数字信号,这个数字信号也被称为序列。将模拟信号转换为数据信号的过程称为数字信号处理,现已成为一门独立的学科,其分支数字图像处理在人工智能领域发挥着重要的作用。
序列的规范化表示方法:
[ seq_len, feature_len ] 用来表示序列,其中seq_len为序列的长度、feature_len为表示序列中每个元素的维度。序列可以是数字化后的语音信号、可以是数字化后的图片、也可以是一句话等等。
GloVe编码方式的引入:
我们都知道pytorch中是不存在字符串类型的,但是文字信息又是我们长处理的数据,我们如何表示这种数据,答案是编码。其中最简单的编码方式one-hot,我们在处理手写数字识别的时候用的就是这种编码方式,建立一个10维的向量,每个位置表示一个数字,如果是这个数字则相应位置为1,否则为0。
0 :[ 1, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
1 :[ 0, 1, 0, 0, 0, 0, 0, 0, 0, 0 ]
……
9 :[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 ]
将相应的数字换为单词就可以表达每个单词。
one-hot的编码方式存在稀疏、高维的特点。稀疏:每一个向量只能用来表达一个单词;高维:一个向量的维度等于这个句子的单词数量,你也许感觉还可以,如果是一篇英语文章呢?这种编码方式代表了巨大的数据量。
由于one-hot的高度不实用性,GloVe编码方式随之诞生。GloVe表示了单词的相似性,具体怎么表示的我们看如下图:

左边的表示了与king的相似性,右边的表示了与queen的相似性。我们可以看到每个单词的后面都跟着一个数值,这个数值表示了与值对应单词的相似度,就比如kings后面的数值0.897245,便是了kings与king的形似度为0.897245。这个相似度是如何计算的呢?
使用两个单词之间的cos值表示,将每个单词看作一个向量,然后计算两向量之间的cos<w1, w2>如果你还不是很明白,就去看高中数学吧,或者看下图:

不知道这张图是否唤起了你沉睡的记忆?
接着介绍在序列在我们今天的主题RNN中是如何表示的,RNN里面提供了两种方法来表示序列:
第一种:[word num, b, word vec],其中word num表示单词的数量,b表示句子的数量,word vec表示单词的维度。
第二种:[b, word num, word vec],其中b表示句子的数量,word num表示单词的数量,word vec表示单词的维度。
这两种表示方法中的每个维度含义都是相同的,只是两者的顺序发生了改变,可以根据理解图片向量的含义来理解整体的含义。
GloVe实例:
import torch
import torchnlp # 自然语言处理模块,如果没有torchnlp 模块,用pip install pytorch-nlp 安装
import torch.nn as nn
from torchnlp import word_to_vector
from torchnlp.word_to_vector import GloVe
################ nn.Embedding ################
word_to_ix = {"hello": 0, "world": 1} # 编一个索引号
# 查表 Word vector lookup table,已经提前编好存储在pytorch中
lookup_tensor = torch.tensor([word_to_ix["hello"]], dtype=torch.long) # 得到一个索引idx
embeds = nn.Embedding(2, 5) # 实例化一个词向量表,其中2表示:一个有2个单词,5表示每个单词的词向量的维度或长度。
hello_embeds = embeds(lookup_tensor) # 根据索引查表,得到索引对应的feature,也就是word vector 的 representation
print(hello_embeds)
# tensor([[ 0.7305, -1.1242, -0.1810, -0.5458, -1.0004]],
# grad_fn=<EmbeddingBackward>)
# 这里没有初始化,nn.embedding这张表是随机生成的,得到的vector,非常random。
# 且通过查表方式得到的vector没有办法算梯度,不能优化。
# 怎样初始化,使用现成的 word2vec 或者GloVe
########## word2vec / GloVe ##########
# vectors=GloVe() # 查表操作,下载太慢了
vectors = GloVe('6B') # 840条词向量,每个词向量的维度是300个维度
vector = vectors["hello"]
print(vector.shape)
# torch.Size([300])
print(vector)什么是RNN?
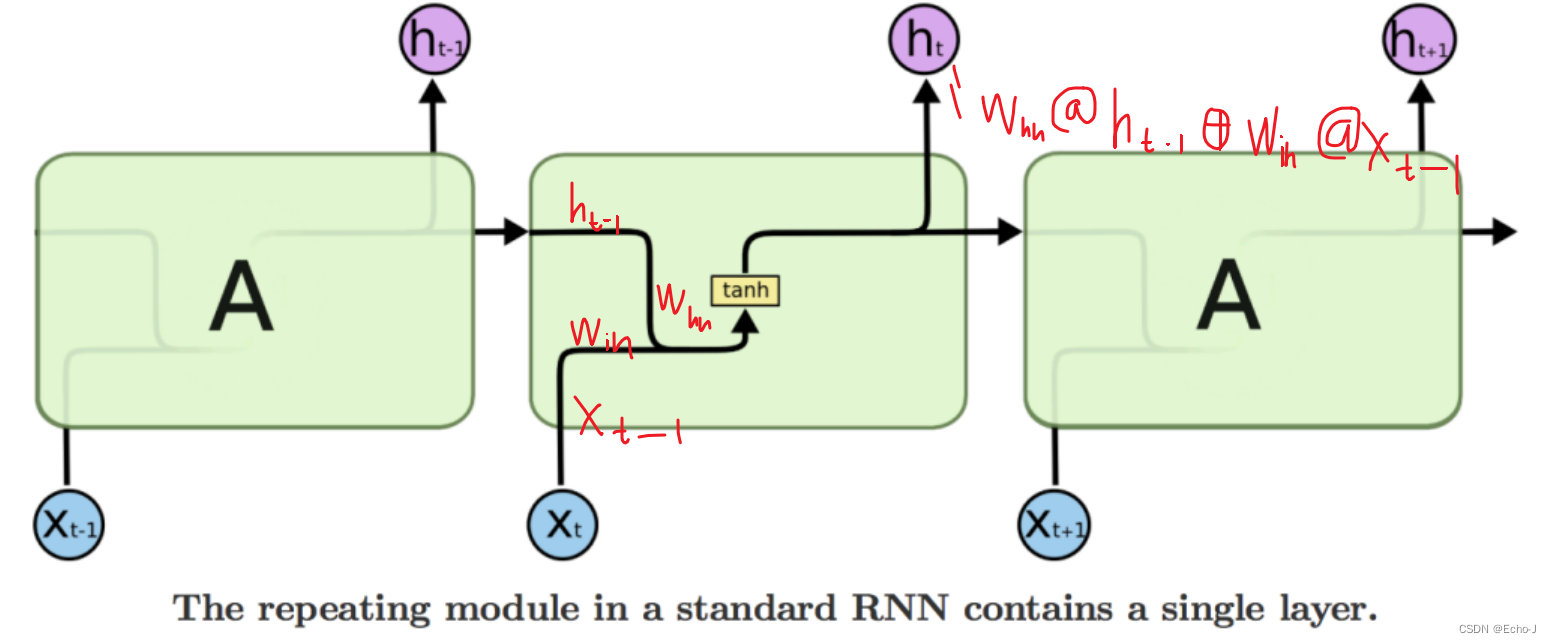
RNN全称为Recurrent Neural Network,中文名字“循环神经网络”。具体是什么,往下看:
当我们去做一个情感分析的时候,会尝试去评价一个句子是积极的还是消极的,先让我们以CNN的角度来看:
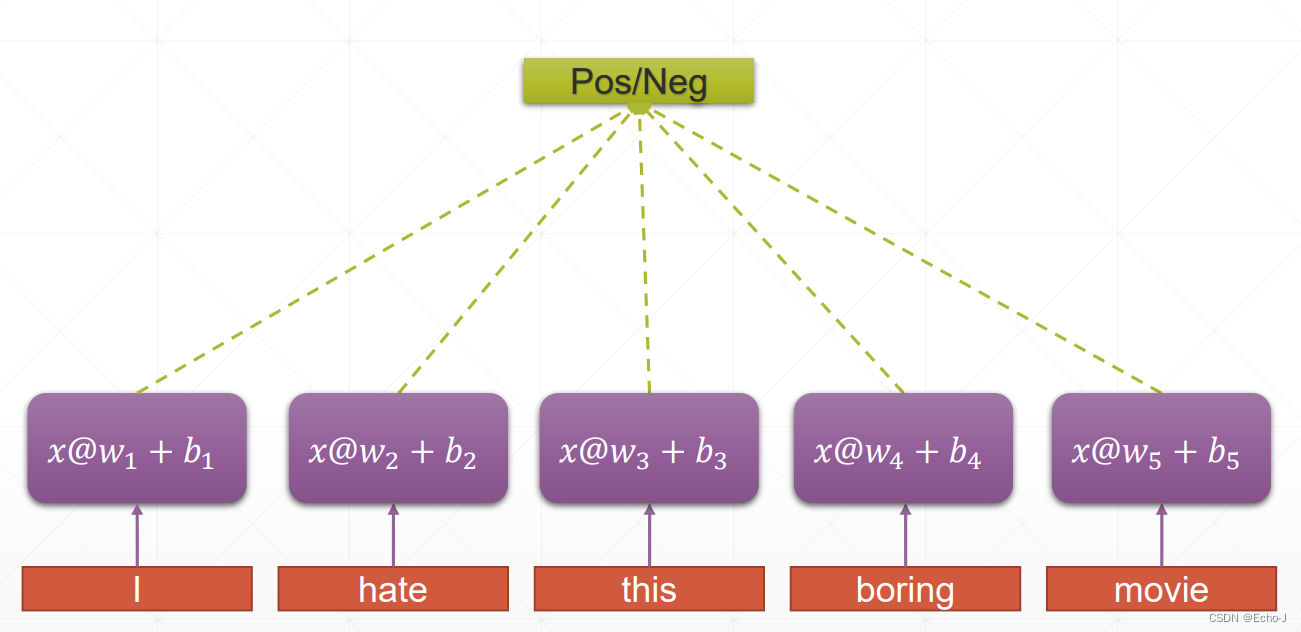
现在我们要分析I hate this boring movies这句话是消极的,还是积极的,我们将此句话使用一个[5, 100]的序列来表示,其中5表示一共有5个单词,100表示每个单词使用100个维度来表示。我们将每个单词都送进CNN,也就是将[100]进行线性运算,但是每个单词的weight和bias都是不一样的,这就意味着CNN是将每个单词单个处理的,丧失了语义,并且每个单词都会拥有2个参数,这意味着巨大的参数量。我们希望可以减少参数,并且将所有的单词联系起来,放在一个语境下去分析,由此权值共享的概念和长期记忆的概念被提出。
权值共享,简单明了,让所有的单词都共享同意对参数,如下图所示:

长期记忆,有一个单元来保存所有的信息,将每个单词串联起来,放在同一个语境下:
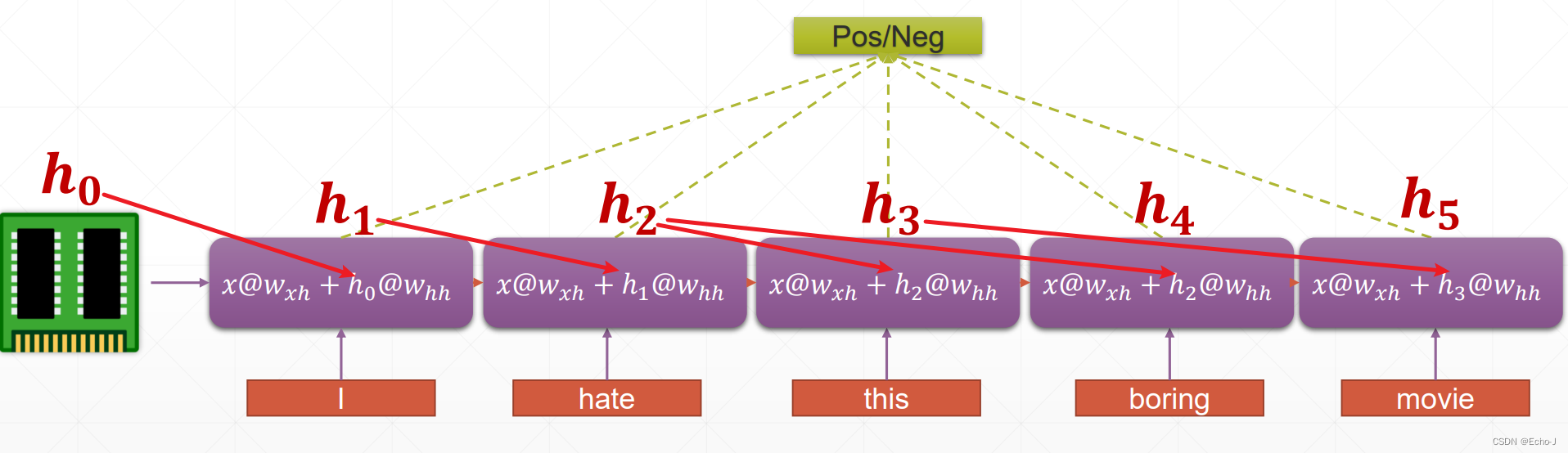
这个被用来保存所有信息为h0,每个单元的输出为h,请注意看红色箭头的指向,具体红色箭头指哪里由你自己决定。
一般我们将h0初始化为[0, 0, 0, ...],每次输入一个单词,比如序列为[5, 3, 100],送入的就是 [3, 100]。
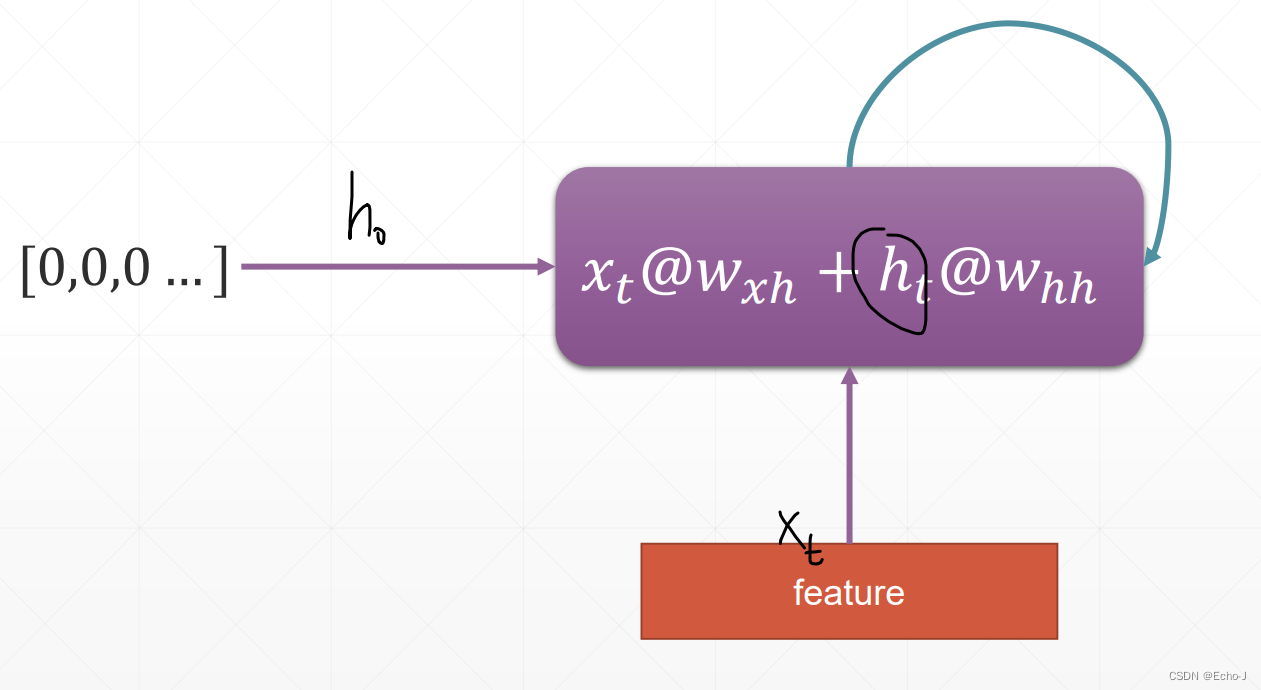
这个模型就被称为RNN。
RNN背后的数学原理:
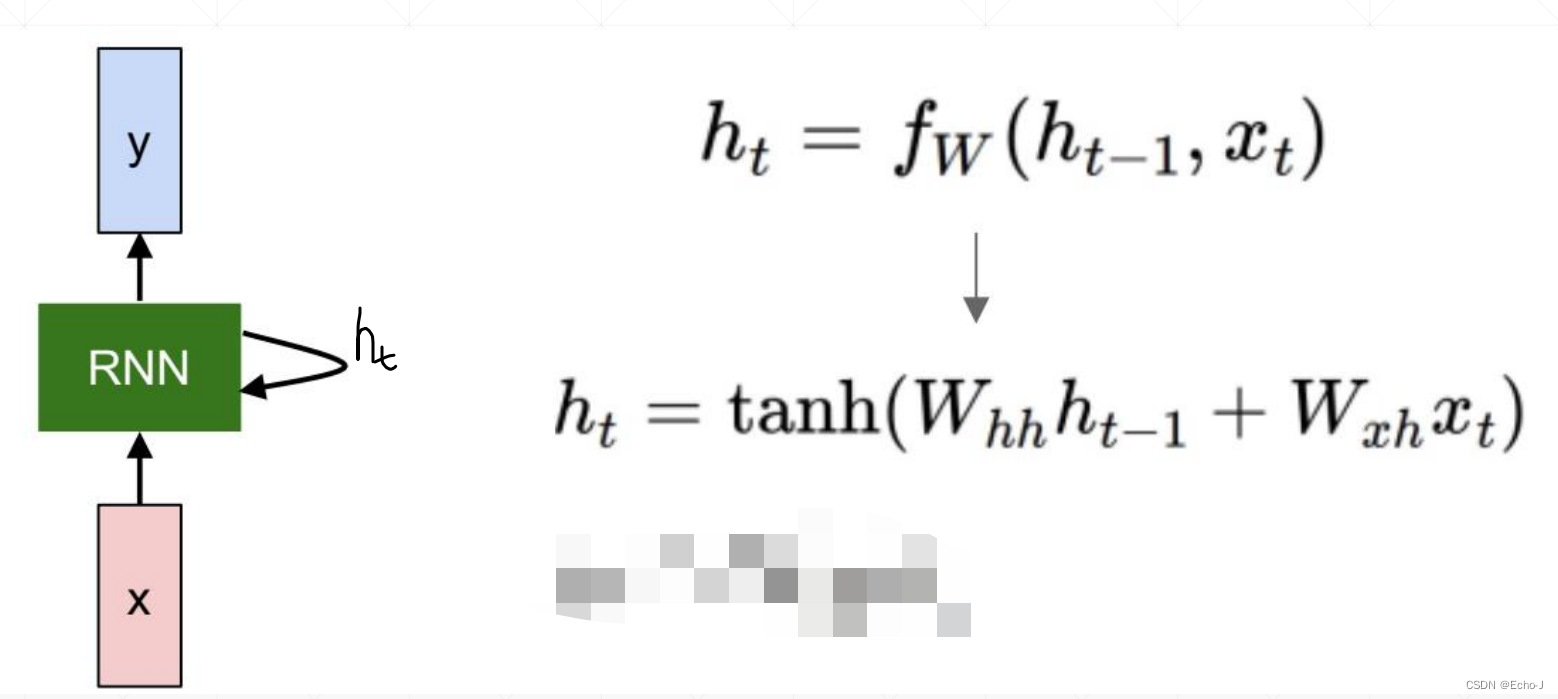

RNN的使用
前提:再来看这张图,我先解释一下这个图中每个数据的特征,其中整体的数据x:[seq len, batch, feature len],其中seq len表示单词的个数、batch表示句子的个数、feature len表示一个单词使用feature len个维度来表达;一个单词xt:[batch, feature len];Wxh:[hidden len, feature len]其中hidden len表示记忆单元的维度;ht:[batch, hidden len];Whh:[hidden len, hidden len]。可以使用
来表示紫色框中的公式,最后的结果就是[ batch, hidden len]。

代码实例,可以直接运行试试看,也可以改变一下feature len和hidden len:
from torch import nn
rnn = nn.RNN(100, 10) # RNN(feature len, hidden len)
print(rnn._parameters.keys())
# odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0'])
print(rnn.weight_hh_l0.shape, rnn.weight_ih_l0.shape)
# torch.Size([10, 10]) torch.Size([10, 100])
print(rnn.bias_hh_l0.shape, rnn.bias_ih_l0.shape)
# torch.Size([10]) torch.Size([10])在进行下面实例之前先明确两个概念:
out 是最后输出的集合,表示为[h0,h1,…,hi]的组合叠加
h 则是每一层最后隐藏单元的集合
一层RNN:
import torch
from torch import nn
# [input dim(feature dim/word vector),hidden dim,num layers(default Settings is 1)]
rnn = nn.RNN(input_size=100, hidden_size=20, num_layers=1)
print(rnn)
# RNN(100, 20)
# x:[seq len, batch, word vector]
x = torch.randn(10, 3, 100)
# out:[seq len,batch,hidden dim] [10,3,20]
# h0/ht:[num layers,batch,hidden dim] [1,3,20]
out, h = rnn(x, torch.zeros(1, 3, 20))
print(out.shape, h.shape)
# torch.Size([10, 3, 20]) torch.Size([1, 3, 20])一层RNN-Cell:
import torch
from torch import nn
# 1-layer
cell1 = nn.RNNCell(100, 20) # [word vec, h_dim]
h1 = torch.zeros(3, 20) # [b,h_dim]
for xt in x: # xt:每个数据,x:所有数据
h1 = cell1(xt, h1)
print(h1.shape)
# torch.Size([3, 20])多层:
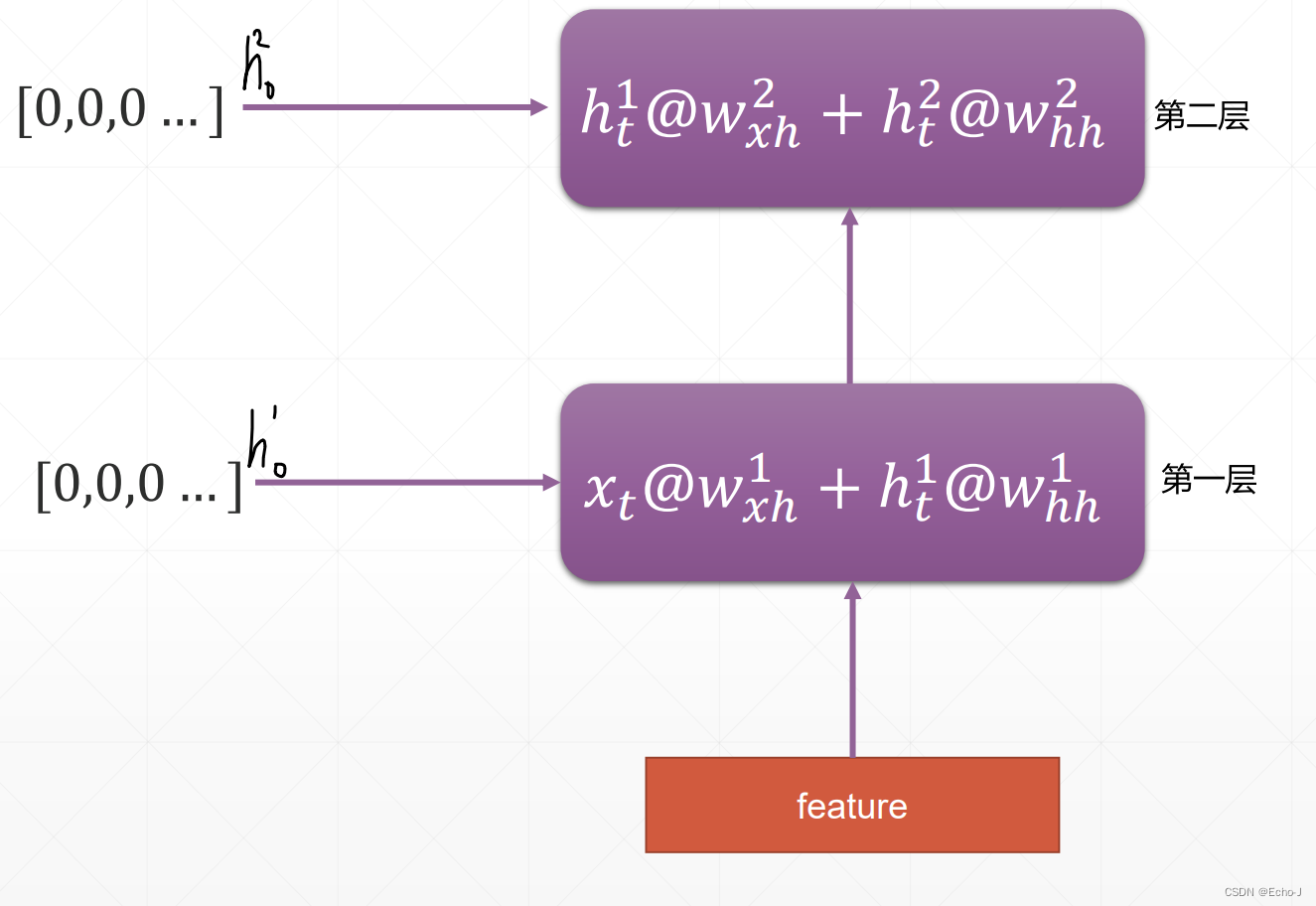
先来看一下处理后维度的变化:
from torch import nn
rnn = nn.RNN(100, 10, num_layers=2) # RNN(feature len, hidden len, num_layers)
print(rnn._parameters.keys())
# odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0', 'weight_ih_l1', 'weight_hh_l1', 'bias_ih_l1', 'bias_hh_l1'])
print(rnn.weight_hh_l0.shape, rnn.weight_ih_l0.shape)
# torch.Size([10, 10]) torch.Size([10, 100])
print(rnn.weight_hh_l1.shape, rnn.weight_ih_l1.shape)
# torch.Size([10, 10]) torch.Size([10, 10])多层RNN:
import torch
from torch import nn
rnn = nn.RNN(input_size=100, hidden_size=20, num_layers=4)
print(rnn)
# RNN(100, 20, num_layers=4)
x = torch.randn(10, 3, 100)
# out:[seq len,batch,hidden dim] [10,3,20]
# h0/ht:[num layers,batch,hidden dim] [4,3,20]
out, h = rnn(x, torch.zeros(4, 3, 20)) # rnn(所有的数据, h0)
# out, h = rnn(x) #与上一行等价,这里没有传h0进来
print(out.shape, h.shape)
# torch.Size([10, 3, 20]) torch.Size([4, 3, 20])多层RNN-Cell:
import torch
from torch import nn
cell1 = nn.RNNCell(100, 30) # [word vec,h_dim],100 dim reduce to 30
cell2 = nn.RNNCell(30, 20) # [word vec,h_dim],30 dim reduce to 20
h1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
for xt in x:
h1 = cell1(xt, h1) # 本层的输出h1作为了下一层的输入
h2 = cell2(h1, h2)
print(h2.shape)
# torch.Size([3, 20])时间序列的预测
############# 正弦函数预测(1 layer RNN) #############
# (1)构建RNN网络
# (2)training:构建优化器,迭代,加载正弦函数数据,定义loss,输出
# (3)testing
# (4)画图
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from matplotlib import pyplot as plt
num_time_steps = 50
input_size = 1
hidden_size = 16
output_size = 1
lr = 0.01
########构建RNN网络#######
class Net(nn.Module):
def __init__(self, ):
super(Net, self).__init__()
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=1,
batch_first=True, # [batch,seq len ,word vector/feature dim]
)
# 正态分布的权值初始化
for p in self.rnn.parameters(): # parameters:包含所有模型的迭代器.
nn.init.normal_(p, mean=0.0, std=0.001) # normal_:正态分布
# 连接层,对数据做处理 [49,16]→[49,1]
self.linear = nn.Linear(hidden_size, output_size) # 对输入数据做线性变换y=Ax+b
# 前向传播函数
def forward(self, x, hidden_prev):
out, hidden_prev = self.rnn(x, hidden_prev) # 前向网络参数:输入,h0
# out:[b, seq, h],torch.Size([1, 49, 16])
# ht:[b,num layers,hidden dim],torch.Size([1, 1, 16])
out = out.view(-1, hidden_size) # [1, seq, h]=>[seq, h] torch.Size([49, 16])
out = self.linear(out) # torch.Size([49, 1]), [seq, h] => [seq, 1]
out = out.unsqueeze(dim=0) # torch.Size([1, 49, 1]),要个 y做一个MSE,所以增加的维度要一致 [seq, 1] => [1, seq, 1]
return out, hidden_prev # torch.Size([1, 49, 1]),torch.Size([1, 1, 16])
########## 开始训练 ##############
model = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr)
hidden_prev = torch.zeros(1, 1, hidden_size) # h0:[b,num layers,hidden dim],[1,1,16]
for iter in range(6000):
# np.random.randint(low, high=None, size=None)
# 作用返回一个随机整型数,范围从低(包括)到高(不包括),即[low, high)。如果没有写参数high的值,则返回[0,low)的值。
# 65-74行慵懒生成数据
start = np.random.randint(3, size=1)[0] # 返回[0,3)的随机整型数,size=1表示维度为1,[0]取第0维的数
# print(start) # scalar
time_steps = np.linspace(start, start + 10, num_time_steps) # 等分数列,生成[start,start+10] 区间的50个等分数列
# print(time_steps) #(50,)
data = np.sin(time_steps) # 取正弦函数 (50,)
data = data.reshape(num_time_steps, 1) # (50, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1) # 第0-48的数字 x:(1,49,1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1) # 第1-49的数字 y:(1,49,1)
# 相当于用第0-48的数字预测第1-49的数字,往后预测1位
# 正式开始训练
output, hidden_prev = model(x, hidden_prev) # 将x和h0送进模型,得到output和ht
# tensor.detach()
# 返回一个新的tensor,从当前计算图中分离下来的,但是仍指向原变量的存放位置,
# 不同之处只是requires_grad为false,得到的这个tensor永远不需要计算其梯度,不具有grad
hidden_prev = hidden_prev.detach()
loss = criterion(output, y) # compute MSE of output and y
model.zero_grad()
loss.backward()
optimizer.step()
########### 进行测试 #########
if iter % 100 == 0: # 每100次输出结果
print("Iteration: {} loss {}".format(iter, loss.item()))
# 数据定义送进来
start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1) # 数据
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1) # 预测值
# 测试
predictions = [] # 先把预测的东西做一个空的数组
input = x[:, 0, :] # x从[1,49,1]=>[1,1]
for _ in range(x.shape[1]): # '_' 是一个循环标志
input = input.view(1, 1, 1) # x从[1,1]=>[1,1,1],即把seq变为1,曲线一个点一个点的动
(pred, hidden_prev) = model(input, hidden_prev)
input = pred # 接收刚才输出的pred,再次送入网络,seq为1,就可以实现一个点一个点的预测下去了。
predictions.append(pred.detach().numpy().ravel()[0]) # append 用于在列表末尾添加新的对象, ravel展平, [0]取数值
# 也就是说,将得到的预测点一个一个展示出来
# 画图
x = x.data.numpy().ravel() # 展平
y = y.data.numpy()
plt.scatter(time_steps[:-1], x.ravel(), s=90) # 原始X散点图 0-48, x,size=90
plt.plot(time_steps[:-1], x.ravel()) # 原始X曲线图 0-48, x
plt.scatter(time_steps[1:], predictions) # 预测曲线图 1-49, predictions,default size=20
plt.show()
预测结果:

RNN训练难题
从CNN模型的经验,RNN如果进行简单的叠加也会导致很差的结果,这个很差的结果主要有两种,梯度爆炸(Gradient Exploding)和梯度离散(Gradient Vanishing)。为什么会导致这种原因的发生?我们一起来看一下RNN的梯度推导公式:

如果还不明白,看下面,从小到大的心灵鸡汤:
 梯度爆炸解决:
梯度爆炸解决:
将w.grad限制在一个范围内,就是我们给定一个预值threshold then,如果梯度超过预值了我们就对梯度进行一个缩放,缩放规则为 w.grad = threshold / ||w.grad|| * w.grad。具体的代码表现形式:
loss = criterion(output, y)
model.zero_grad()
loss.backward()
for p in model.parameters():
print(p.grad.norm()) #打印出现在的W.grad,经验来讲,如果大于等于50就有可能梯度爆炸,如果等于10左右,就ok
torch.nn.utils.clip_grad_norm_(p, 10) #采用clip 将梯度降成<10
optimizer.step()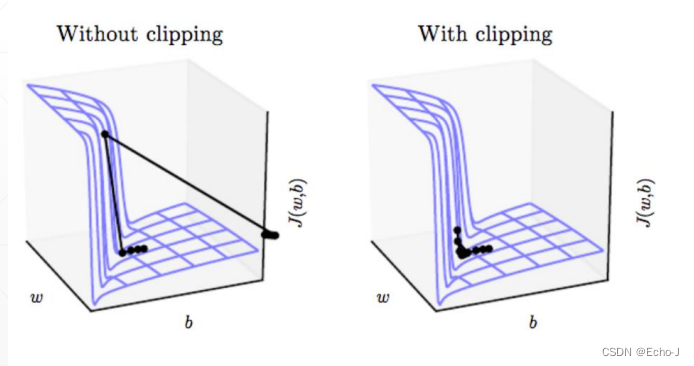
梯度离散解决——LSTM:
解决梯度离散的方法就是LSTM,但是为什么叫做LSTM?LSTM是 long-short-term-memory 的简称,下面来介绍一下具体为什么要叫 long-short-term-memory ,进行RNN中的时候我们定义了一个h0,用来贯穿语境,想象很美好,现实很骨感,没错h0只能记住最近的几个,前面的早忘到十万八千里了,这种现象称作 short-term-memory(短期记忆)。而让它脑子变得好使的就加了一个long,即 long-short-term-memory 。
先来回顾一下 short-term-memory
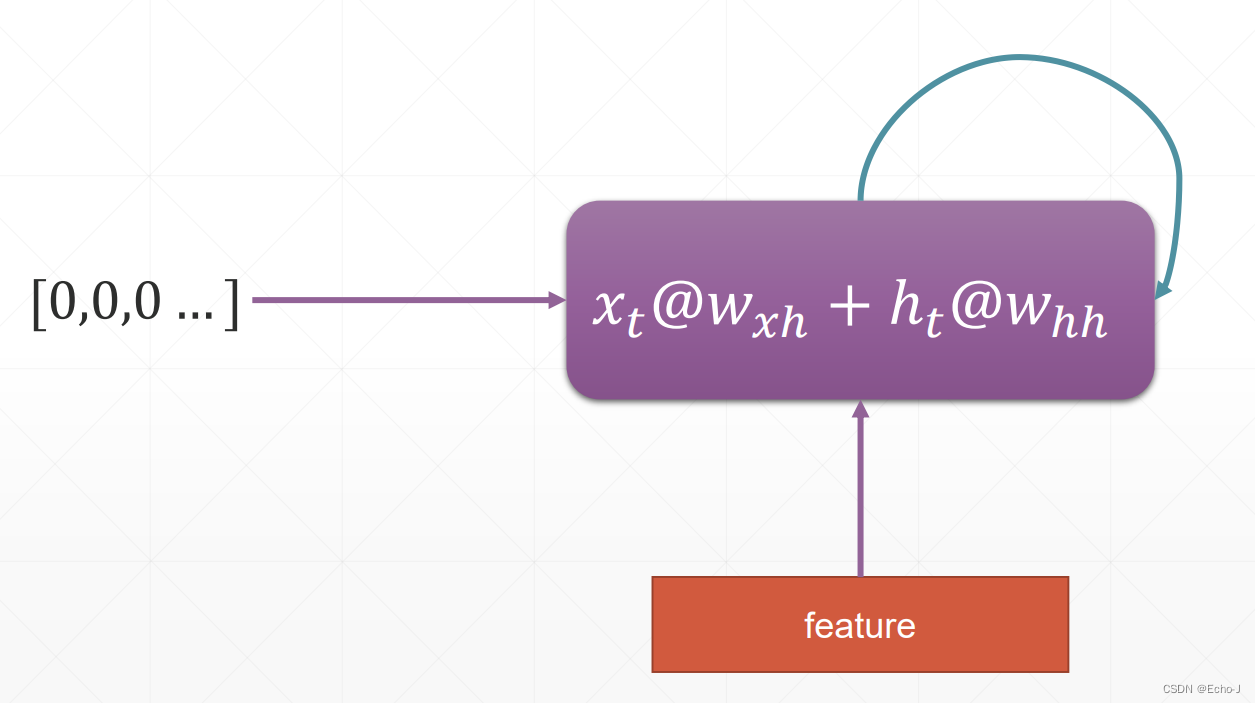
我们完全可以将上述模型换成如下形式:
 再来看一下LSTM,观察一下两者的区别:
再来看一下LSTM,观察一下两者的区别:

蓝色对应公式:
 ,其中Wf表示决定记住多少。
,其中Wf表示决定记住多少。
以下两个公式表示绿色的部分,这一步决定了 我们将要存储多少信息在细胞门里面。
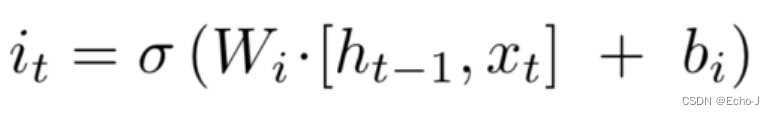 Wi表示获取多少现在的信息。
Wi表示获取多少现在的信息。
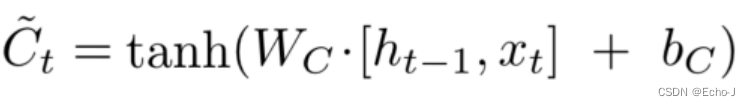
橙色对应公式,更新hidden里面的值:
![]()
第一个框:通过忘记之前决定要忘记的Ft乘于旧的Ct-1。
第二个框:决定更新多少的值it乘于新的状态值Ct(上面有个~)。
紫色的对应输出,这一步我们需要决定我们想要输出什么:
我们要输出的部分:
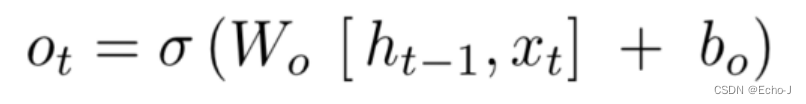
最终我们要输出的部分:
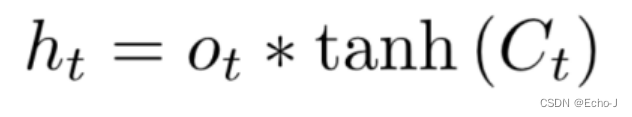
总的来说就是:

表达成公式就是如下样子:
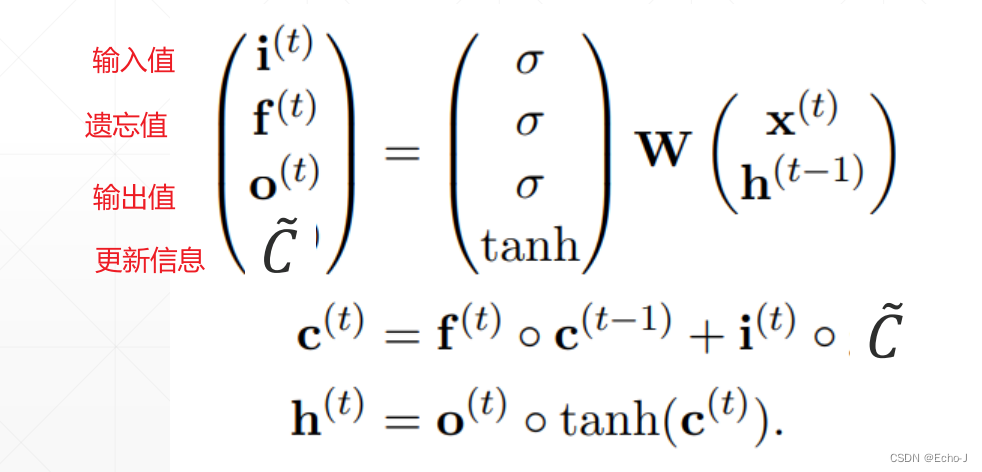 极值条件下(这个很像真值表,如果你学过《离散数学》或《数字电路与逻辑设计》的话,应该知道):
极值条件下(这个很像真值表,如果你学过《离散数学》或《数字电路与逻辑设计》的话,应该知道):
| 输入门 | 输出门 | 表现行为 |
| 0 | 1 | 记住先前的值 |
| 1 | 1 | 加入先前的值 |
| 0 | 0 | 清除值 |
| 1 | 0 | 覆盖原来的值 |
但是这种计算方法怎么解决了梯度离散的现象呢?让我们从数学公式的角度来分析一下原因:
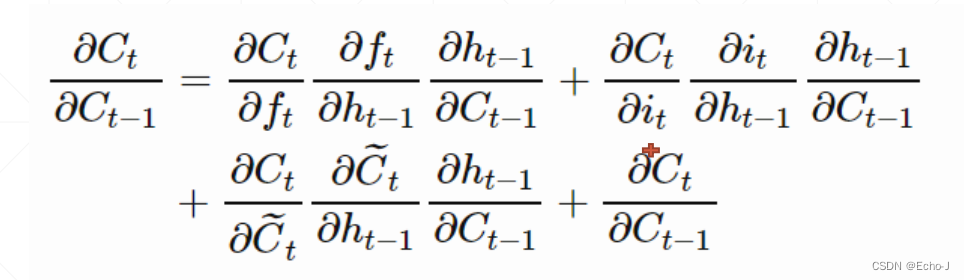
原来的累乘变成了累加,累加就有可能加正数和负数,这种形式的梯度很自然的就解决了梯度离散的问题。
LSTM的使用
由于LSTM如此强大,pytorch也提供了相关的类——nn.LSTM
nn.LSTM:
1、__init__
参数:input_size:feature len;hidden_size:h0的特征维度;num_layers:循环的层数,如果不填的话默认为1。
2、LSTM.forward()
参数:out, (ht, ct) = lstm(x, [ht_0, ct_0])
x: [seq, b , vec]; h/c: [num_layer, b, h]; out: [seq, b, h]
3、代码演示:
lstm = nn.LSTM(input_size=100, hidden_size=20, num_layers=4)
print(lstm)
# LSTM(100, 20, num_layers=4)
x = torch.randn(10, 3, 100)
out, (h, c) = lstm(x)
print(out.shape, h.shape, c.shape) # out:[seq, b, h] h/c:[num_layer, b, h]
# torch.Size([10, 3, 20]) torch.Size([4, 3, 20]) torch.Size([4, 3, 20])nn.LSTMCell:
1、__init__
参数:input_size:feature len;hidden_size:h0的特征维度;num_layers:循环的层数,如果不填的话默认为1。
2、LSTMCell.forward()
ht, ct = lstmcell(xt, [ht_1, ct_1])
xt: [b, word vec]
ht/ct: [b, h]
3、代码演示:
1-layer:
cell = nn.LSTMCell(input_size=100, hidden_size=20)
h = torch.zeros(3, 20)
c = torch.zeros(3, 20)
for xt in x:
h, c = cell(xt, [h, c])
print(h.shape, c.shape)
# torch.Size([3, 20]) torch.Size([3, 20])2-layer:
cell1 = nn.LSTMCell(input_size=100, hidden_size=30)
cell2 = nn.LSTMCell(input_size=30, hidden_size=20)
h1 = torch.zeros(3, 30)
c1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
c2 = torch.zeros(3, 20)
for xt in x:
h1, c1 = cell1(xt, [h1, c1])
h2, c2 = cell2(h1, [h2, c2])
print(h2.shape, c2.shape)
# torch.Size([3, 20]) torch.Size([3, 20])情感分类实战
Google CoLab:
在Google Colab中你可以获得连续12小时的使用、获得免费的K80 for GPU,Google Colab一般用来学习机器学习,是一个非常好用的工具,前提是你必须可以科学上网,可以使用Google。
########### 情感分类实战(基于IMDB数据集)#############
# 1 加载数据:
# 1.1 分割训练集测试集
# 1.2 创建vocabulary
# 1.3 创建 iterations
# 2 定义模型(class RNN):
# 2.1 __init__: 定义模型
# 2.2 forward:前向传播
# 2.3 使用预训练过的embedding 来替换随机初始化
# 3 训练模型 :
# 3.1 首先定义优化器和损失函数
# 3.2 定义一个函数用于计算准确率 def binary_acc
# 3.3 进入训练模式
# 4 评估模型(test)
# 5 运行
# 6 预测输出样例
import torch
import torchtext #(version:0.6.0)
from torch import nn, optim
from torchtext import data, datasets
import spacy #(version:3.3.0)
# nlp=spacy.load('en_core_web_sm')
print('GPU:', torch.cuda.is_available())
# 为CPU设置随机种子
torch.manual_seed(123)
############ 1 加载数据 ###########
######### 1.1 分割训练集测试集 ###########
# 两个Field对象定义字段的处理方法(文本字段、标签字段)
#Spacy 3.x以上的版本:tokenizer_language='en_core_web_sm',否则默认是tokenizer_language='en'
#TEXT = data.Field(tokenize='spacy')
TEXT = data.Field(tokenize='spacy',tokenizer_language='en_core_web_sm') #文本
LABEL = data.LabelField(dtype=torch.float) #标签
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
print('len of train data:', len(train_data)) # 25000
print('len of test data:', len(test_data)) # 25000
# torchtext.data.Example : 用来表示一个样本,数据+标签
print(train_data.examples[15].text) # 文本:句子的单词列表
print(train_data.examples[15].label) # 标签: 积极pos
#当我们把句子传进模型的时候,是按照一个个batch传进去的,而且每个batch中的句子必须是相同的长度。
#为了确保句子的长度相同,TorchText会把短的句子 pad到和最长的句子 等长。
########## 1.2 创建vocabulary ############
# vocabulary把每个单词一一映射到一个数字。
# 使用10k个单词来构建单词表(用max_size这个参数可以设定),所有其他的单词都用来表示。
# word2vec, glove
TEXT.build_vocab(train_data, max_size=10000, vectors='glove.6B.100d')
LABEL.build_vocab(train_data)
# 词典中应当有10002个单词,且有两个label,
# 可以通过TEXT.vocab和TEXT.label查询,
# 可以直接用stoi(stringtoint) 或者 itos(inttostring) 来查看单词表。
# print(len(TEXT.vocab)) # 10002
# print(TEXT.vocab.itos[:12]) # ['', '', 'the', ',', '.', 'and', 'a', 'of', 'to', 'is', 'in', 'I']
# print(TEXT.vocab.stoi['and']) # 5
# print(LABEL.vocab.stoi) # defaultdict(None, {'neg': 0, 'pos': 1})
############### 1.3 创建 iterations ############
# 每个iterator 迭代器 中各有两部分:词(.text)和标签(.label),其中 text 全部转换成数字了。
# BucketIterator会把长度差不多的句子放到同一个batch中,确保每个batch中不出现太多的padding。
batchsz = 30
device = torch.device('cuda:0')
train_iterator, test_iterator = data.BucketIterator.splits(
(train_data, test_data),
batch_size = batchsz,
device=device
)
################### 2 定义模型 ##########################
#这里的RNN是一个通称,应该叫Network
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(RNN, self).__init__()
# [0-10001] => [100]
# 参数1:embedding个数(单词数), 参数2:embedding的维度(词向量维度)
self.embedding = nn.Embedding(vocab_size, embedding_dim) #[10002,100]
# [100] => [256]
# bidirectional=True 双向LSTM,所以下面FC层使用 hidden_dim*2
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=2, #[100,256]
bidirectional=True, dropout=0.5)
# [256*2] => [1]
self.fc = nn.Linear(hidden_dim*2, 1)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
"""
x: [seq_len, b] vs [b, 3, 28, 28]
"""
# [seq, b, 1] => [seq, b, 100]
embedding = self.dropout(self.embedding(x))
# output: [seq, b, hid_dim*2]
# hidden/h: [num_layers*2, b, hid_dim]
# cell/c: [num_layers*2, b, hid_di]
output, (hidden, cell) = self.rnn(embedding)
# [num_layers*2, b, hid_dim] => 2 of [b, hid_dim] => [b, hid_dim*2]
# 双向LSTM,所以要把最后两个输出连接
hidden = torch.cat([hidden[-2], hidden[-1]], dim=1)
# [b, hid_dim*2] => [b, 1]
hidden = self.dropout(hidden)
out = self.fc(hidden)
return out
####### 使用预训练过的embedding 来替换随机初始化 ###############
rnn = RNN(len(TEXT.vocab), 100, 256) #词个数 10002 ,词嵌入维度 100 ,输出维度 256
#使用预训练过的embedding 来替换随机初始化
pretrained_embedding = TEXT.vocab.vectors
print('pretrained_embedding:', pretrained_embedding.shape) # torch.Size([10002, 100])
rnn.embedding.weight.data.copy_(pretrained_embedding) # .copy_() 这种带着下划线的函数均代表替换inplace
print('embedding layer inited.')
######### 3 训练模型 ##########
######### 3.1首先定义优化器和损失函数 #########
optimizer = optim.Adam(rnn.parameters(), lr=1e-3)
criteon = nn.BCEWithLogitsLoss().to(device) # BCEWithLogitsLoss是针对二分类的CrossEntropy
rnn.to(device)
# RNN(
# (embedding): Embedding(10002, 100)
# (rnn): LSTM(100, 256, num_layers=2, dropout=0.5, bidirectional=True)
# (fc): Linear(in_features=512, out_features=1, bias=True)
# (dropout): Dropout(p=0.5, inplace=False)
# )
######### 3.2 定义一个函数用于计算准确率 #########
import numpy as np
def binary_acc(preds, y):
"""
get accuracy
"""
preds = torch.round(torch.sigmoid(preds))
correct = torch.eq(preds, y).float() #correct is a tensor
acc = correct.sum() / len(correct)
return acc
######### 3.3 进入训练模式 #########
def train(rnn, iterator, optimizer, criteon):
avg_acc = []
rnn.train() # 表示进入训练模式
for i, batch in enumerate(iterator):
# batch.text 就是上面forward函数的参数text,压缩维度是为了和batch.label维度一致
pred = rnn(batch.text).squeeze(1) # [seq, b] => [b, 1] => [b]
loss = criteon(pred, batch.label)
# 计算每个batch的准确率
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
optimizer.zero_grad() # 清零梯度准备计算
loss.backward() # 反向传播
optimizer.step() # 更新训练参数
if i%100 == 0:
print(i, acc)
avg_acc = np.array(avg_acc).mean()
print('avg acc:', avg_acc)
################# 4 评估模型 ######################
#定义一个评估函数,和训练函数高度重合
def eval(rnn, iterator, criteon):
avg_acc = []
rnn.eval() # 表示进入测试模式
with torch.no_grad():
for batch in iterator:
# [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
avg_acc = np.array(avg_acc).mean()
print('>>test:', avg_acc)
############# 5 运行 ###########
for epoch in range(10):
train(rnn, train_iterator, optimizer, criteon) # 训练模型
eval(rnn, test_iterator, criteon) # 评估模型
# 跑的时候发现模型过拟合了
############## 6 预测输出样例 ##########
# for batch in test_iterator:
# # batch_size个预测
# preds = rnn(batch.text).squeeze(1)
# # preds = predice_test(preds) #?
# print(preds)
#
#
# i = 0
# for text in batch.text:
# # 遍历一句话里的每个单词
# for word in text:
# print(TEXT.vocab.itos[word], end=' ')
#
# print('')
# # 输出3句话
# if i == 3:
# break
# i = i + 1
#
# i = 0
# for pred in preds:
# idx = int(pred.item())
# print(idx, LABEL.vocab.itos[idx])
# # 输出3个结果(标签)
# if i == 3:
# break
# i = i + 1
# break
我是pytorch:2.1.2,torchtext:0.16.0+cpu,跑这段代码的时候会报错AttributeError: module 'torchtext.data' has no attribute 'Field',原因是因为torchtext0.12.0之后不存在Filed了,解决办法就是下载旧的版本,我是通过在命令行提示符执行
pip install torchtext==0.6.0成功解决了问题。
总结:
至此我的pytorch已经学习完毕,在这个过程中我通过写博客来督促自己学习,通过输出的过程中我解决了在听课时遇到的难点,并且思考了如何清晰的表达我的语言,才可以让阅读我博客的人觉得pytorch是如此轻松,并且使我更加对pytorch的知识点更加清晰,也明白了自己的很多不足,并且严重的意识到实践才是巩固知识的唯一途径。
在以后,我会着重于深度学习的应用,将所学知识用到AI安全方面,并且也会学习机器学习的知识以此加强对深度学习的理解。同样,为了加强我学习的动力,我将会继续采用blog记录的方式,将会开展AI-安全系列、机器学习系列,如果有对AI-安全感兴趣的小伙伴,请好好学习,然后发blog,也让我学习学习,我期待中国的AI-安全领域出现更多开放的学习资料,中国网络安全领域繁荣。
最后的最后,请允许我将我这段时间阅读中记下的至理名言放在这里:
啊,在我们化作灰烬之前,
充分享用人生。
黄泉之下,
可没有美酒,
没有琴弦,
没有歌妓,
没有明天。
 谁说啊呦不可爱?
谁说啊呦不可爱?