任务描述
收集9种以上的海洋生物图片,然后基于深度学习做一个分类模型,训练完成后,分类模型就可以对未知图片进行分类。
在之后随便传一张图片,分类模型就可以推理出这张图片上面的是什么海洋生物。
数据收集
初步搜索,整理清洗,得到了一些图片,一共11370张,是这类类别+每个类别的图片数量:
比目鱼 376
水母 590
海星 512
海牛 542
海狮 759
海蛇 116
海螺 430
海豚 487
海象 1190
海豹 482
海里的螃蟹 501
海鳗 506
海龟 611
澳洲龙虾 545
金枪鱼 178
马林鱼 321
鲑鱼 527
鲨鱼 605
鲸鱼 552
鲸鲨 556
鳐鱼 769
鳗鱼 215
数据处理
所执行的数据处理过程主要包括以下几个步骤:
数据预处理:
- 随机大小裁剪:使用
transforms.RandomResizedCrop(224),这个转换对图像进行随机大小和宽高比裁剪,裁剪后的图像大小为224x224像素。这样做可以提供缩放和剪裁的数据增强,并适应预期的神经网络输入尺寸。 - 随机水平翻转:通过
transforms.RandomHorizontalFlip()对图像执行随机的水平翻转,作为一种数据增强技术,使模型能够学习到水平翻转下的图像特征,增强泛化能力。 - 类型转换:
transforms.ToTensor()转换将PIL图像或NumPyndarray转换为FloatTensor,并将图像的像素值从[0,255]范围缩放到[0.0,1.0]范围。 - 标准化:
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])使用指定的均值和标准差对图像进行标准化。这些数值通常是ImageNet数据集上预训练模型使用的数值,使得输入分布与训练过程中的分布相匹配。
- 随机大小裁剪:使用
数据加载和采样:
- 使用ImageFolder从指定的数据集路径
dataset_path加载数据。这要求数据集是以文件夹方式组织的,每个类别一个文件夹。 ImbalancedDatasetSampler处理数据采样,旨在从不平衡的数据集中为每个批次采样,以确保在训练期间各类被公平地表示。DataLoader创建一个数据加载器,用于迭代提供数据,设置批量大小为64,使用了8个工作线程(num_workers)来并行加载数据。
- 使用ImageFolder从指定的数据集路径
数据集类别信息:
- 打印出
image_datasets.classes,这显示了所有类别的列表,即每个标签对应的类名。
- 打印出
模型训练
模型训练过程遵循以下几个关键步骤:
模型初始化:
- 使用预训练的EfficientNet B0作为基础模型,并在此基础上,通过自定义
MyEfficientNet类来适应特定的类别数(本例中为22类)。在该类中,原始EfficientNet B0的分类器被替换为一个新的线性层,以匹配目标任务的类别数。 - 模型使用预训练权重初始化,除了新的分类器层。这有助于加速训练并提高最终模型的性能,因为预训练模型已经学习了从大规模数据集(如ImageNet)提取有用特征的能力。
- 使用预训练的EfficientNet B0作为基础模型,并在此基础上,通过自定义
设置设备:
- 根据系统是否支持CUDA,自动选择使用GPU (
cuda:0) 还是CPU进行训练。
- 根据系统是否支持CUDA,自动选择使用GPU (
损失函数和优化器:
- 采用交叉熵损失(
CrossEntropyLoss)作为损失函数,这是多分类问题常用的损失函数。 - 使用带有学习率0.001的Adam优化器来更新模型的权重。
- 采用交叉熵损失(
迭代训练:
- 模型在给定的迭代次数(
num_epochs)内进行训练。每个epoch都包括一次对整个训练集的遍历。 - 在每次迭代中,将模型设置为训练模式。然后,通过
DataLoader加载小批量数据(inputs,labels),并执行以下步骤:
a. 将数据迁移到相应的设备(GPU或CPU)。
b. 在前向传递开始之前,清除之前迭代计算的梯度。
c. 执行前向传播,计算模型的输出。
d. 根据模型输出和真实标签计算损失。
e. 执行反向传播,计算损失对模型参数的梯度。
f. 更新模型参数。 - 每个epoch结束时,计算并打印该epoch的平均损失。
- 模型在给定的迭代次数(
模型保存:
- 在每个epoch的训练后,将模型的当前状态保存到磁盘上。这使得可以在之后加载训练好的模型进行推理或继续训练。
性能评估:
- 经过训练阶段后,模型切换到评估模式,以进行性能评估。
- 评估过程中不更新模型参数,并使用与训练相同的数据进行验证。
- 计算并打印模型在验证集上的准确率,这有助于监测模型在未见过的数据上的泛化能力。
记录和分析:
- 记录每个epoch训练的损失和验证准确率,方便后续分析模型训练过程中的性能变化。
通过上述步骤,模型逐渐学习从图像数据中提取有用的特征,并准确分类图像。每个epoch的训练和验证过程都旨在评估模型的性能和泛化能力,同时通过反复迭代优化,不断提高模型的准确率。
指标评测
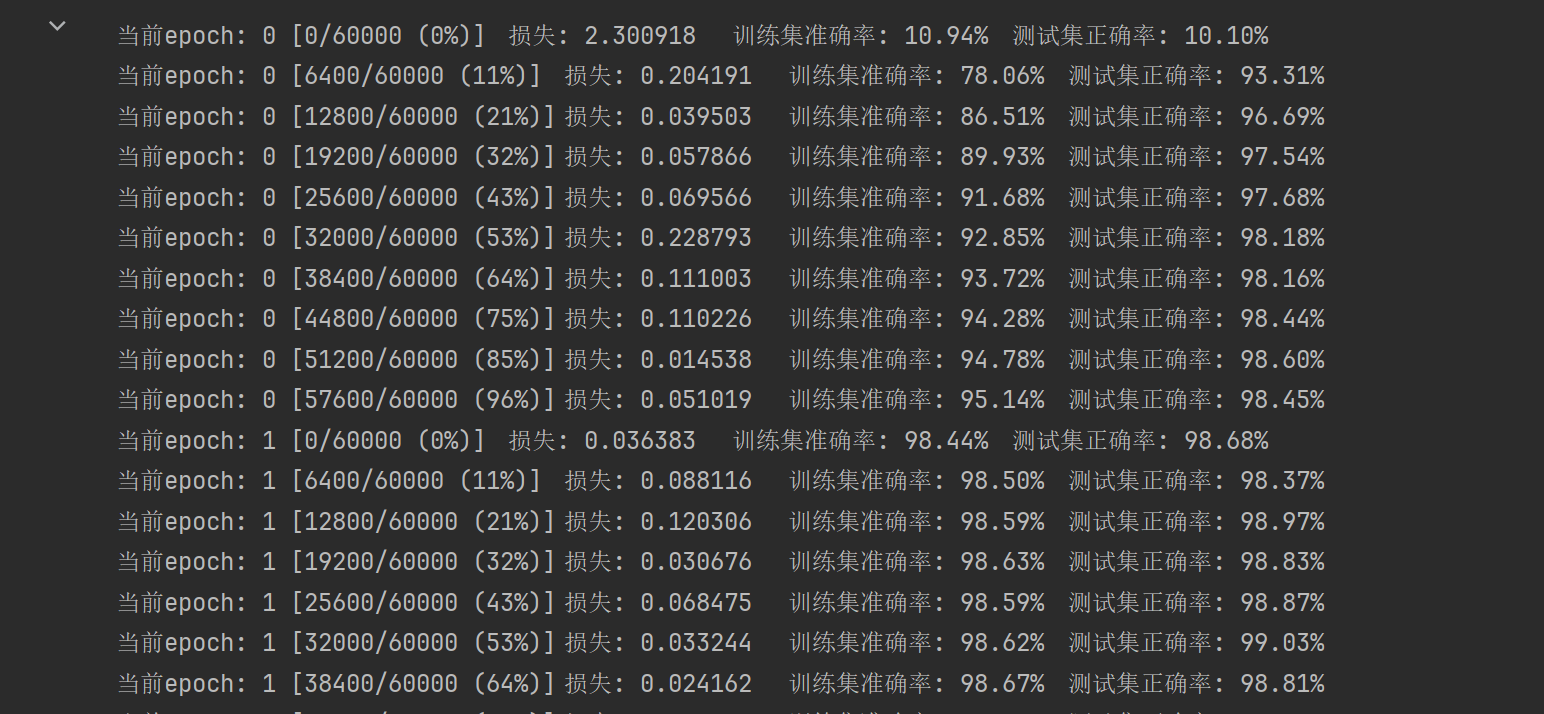
训练30轮,损失数值一直减少:
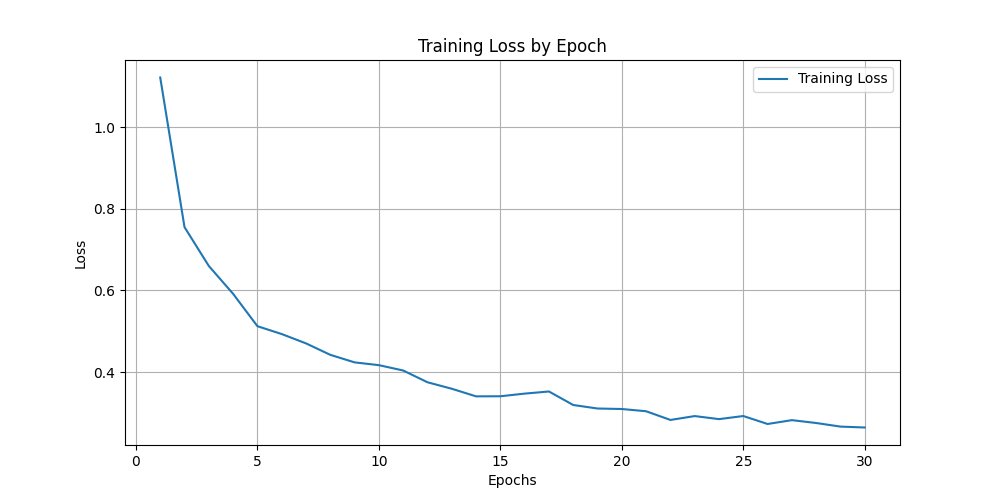
训练30轮,准确度一直提升:

最终结果:
Epoch 30/30, Loss: 0.2644
Validation Acc: 0.9302
web app
请注意,我们只是用了22个类别,没有其他类别,所以测试需要用22个类别以内的图片,不能传无关的图,因为模型没见过无关的图:
比目鱼 376
水母 590
海星 512
海牛 542
海狮 759
海蛇 116
海螺 430
海豚 487
海象 1190
海豹 482
海里的螃蟹 501
海鳗 506
海龟 611
澳洲龙虾 545
金枪鱼 178
马林鱼 321
鲑鱼 527
鲨鱼 605
鲸鱼 552
鲸鲨 556
鳐鱼 769
鳗鱼 215
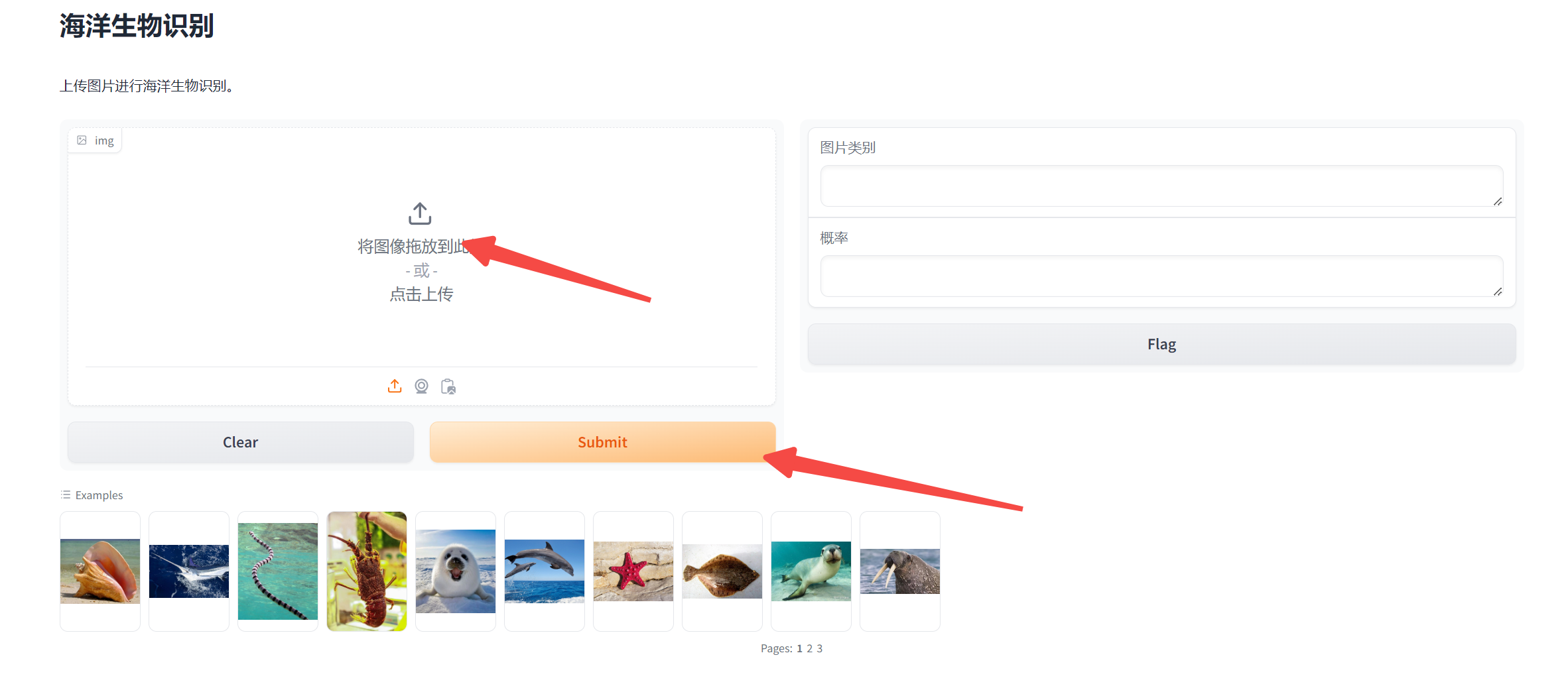
打开网页后,可以点击这里上传图片,然后点击提交,等待片刻,即可看到模型的推理结果。在最下方,也有示例图片,也可以点击某张示例图片后,就点击提交。
代码和帮助
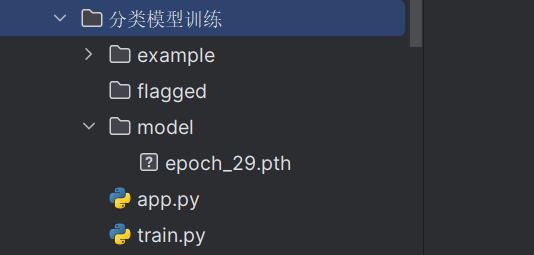
完整代码:
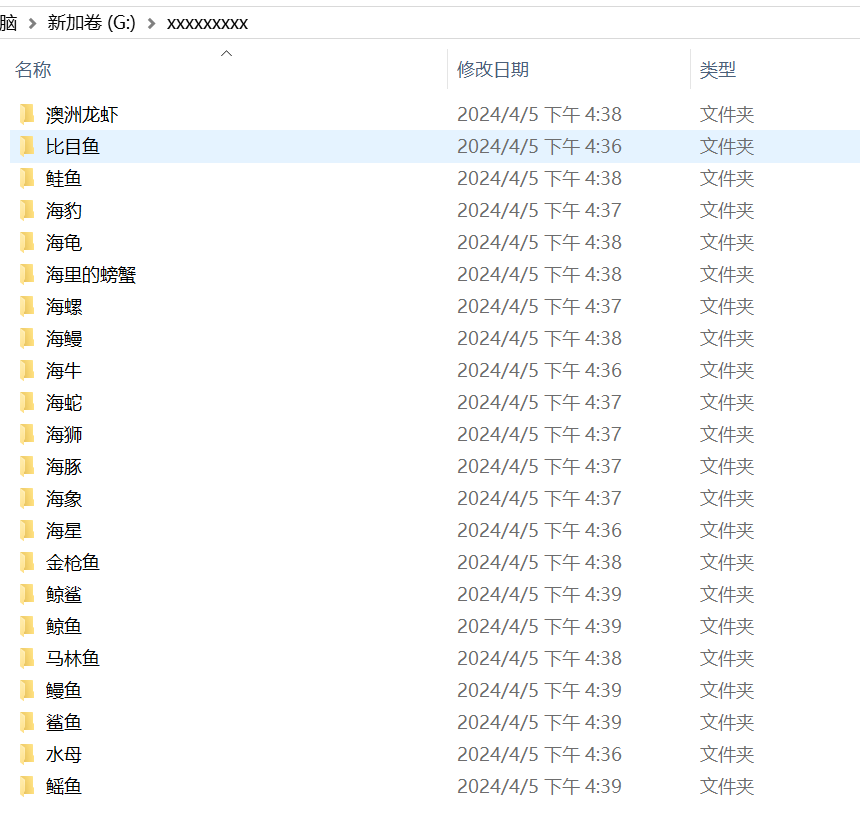
完整数据集:
下载:
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2