前言:
在 Flink 1.11 引入了 CDC 机制,CDC 的全称是 Change Data Capture,核心思想是:监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费,是目前非常成熟的同步数据库变更方案。 Flink CDC Connectors 是 Apache Flink 的一组源连接器,是可以从 MySQL、PostgreSQL 数据直接读取全量数据和增量数据的 Source Connectors.另外支持解析 Kafka 中 debezium-json 和 canal-json 格式的 Change Log,通过Flink 进行计算或者直接写入到其他外部数据存储系统(比如 Elasticsearch),或者将 Changelog Json 格式的 Flink 数据写入到 Kafka。
一、准备工作:
1、在连接hadoop的MySQL中建立flinkcdc数据库创建表test作为测试表
CREATE TABLE test (
id VARCHAR(20), -- 传感器ID
vc INT, -- 水位值
ts BIGINT, -- 时间戳
PRIMARY KEY(id)
);2、插入两条数据
INSERT INTO `flinkcdc`.`sensor_info` (`id`, `vc`, `ts`) VALUES ('s1', 150, 10000);
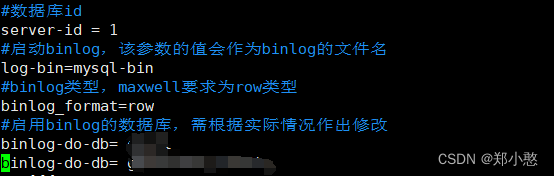
INSERT INTO `flinkcdc`.`sensor_info` (`id`, `vc`, `ts`) VALUES ('s2', 120, 20000);3、开启 MySQL Binlog 并重启 MySQL 。在hadoop上运行
sudo vim /etc/my.cnf添加红色框框中的此内容:(等号右边为自己的数据库名)
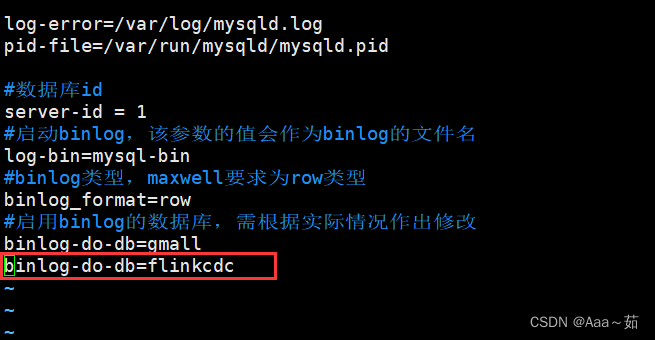
完成编辑后,按下Esc键退出插入模式,然后输入:wq命令保存更改并退出文件。
4、重启MySql服务器:
sudo systemctl restart mysqld5、查看MySql状态:
sudo systemctl start mysqld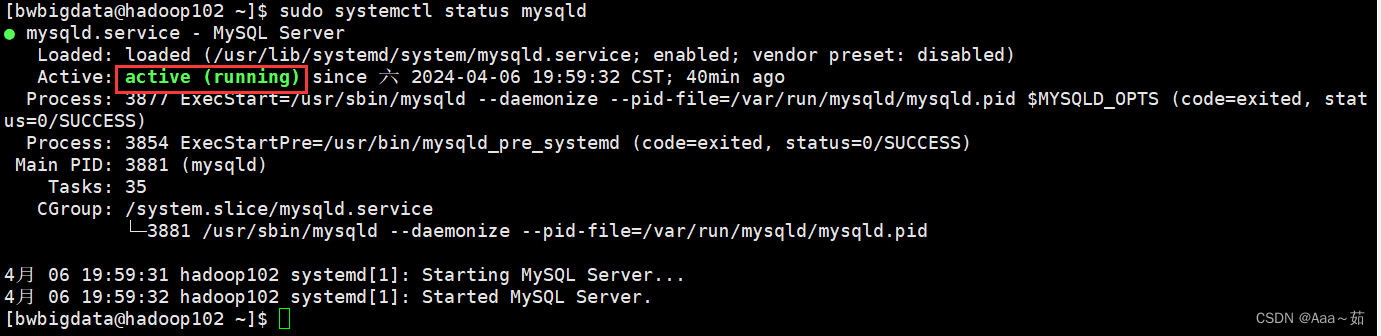
出现actiwe(running)即为成功
二、flinkSQL中使用flinkCDC
1、创建表环境
//环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
2、创建 数据源表
tEnv.executeSql("CREATE TABLE sensor_source (\n" +
" id STRING,\n" +
" ts BIGINT,\n" +
" vc INT,\n" +
" PRIMARY KEY(id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = 'hadoop102',\t\n" + //hadoop名称
" 'port' = '3306',\t\t\t\t\n" +
" 'username' = 'root',\n" + //mysql用户名
" 'password' = '****',\n" + //密码
" 'database-name' = 'flinkcdc',\n" + //数据库名
" 'table-name' = 'test',\n" + //表名
" 'jdbc.properties.useSSL' = 'false'\n" +
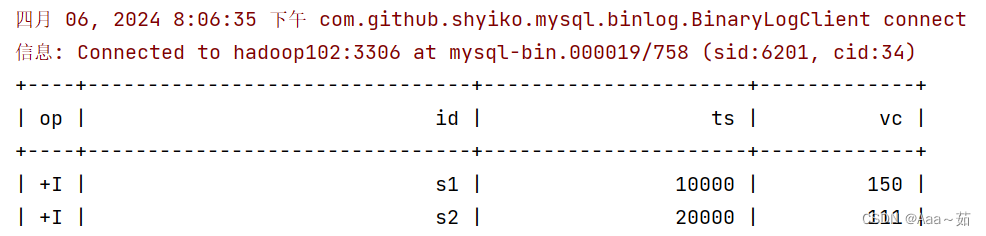
");");3、查询源表并打印
tEnv.executeSql("select * from sensor_source").print();运行效果如下:
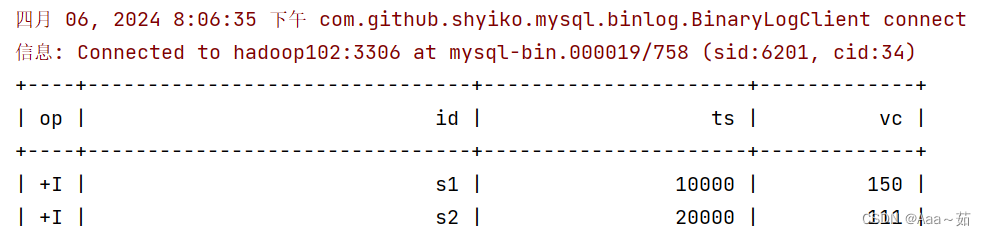
4、改变Mysql里面数据,修改S1的vc为100。则Flink CDC会自动捕获更改的数据。
运行效果如下: