酒店价格采集与可视化查询设计与实现开题报告
研究背景
随着互联网技术的飞速发展,人们获取信息的途径越来越多样化。特别是在旅游行业中,消费者对于酒店价格的透明度和实时性要求越来越高。美团、大众点评、抖音等平台作为信息聚合和分享的重要渠道,汇集了大量的酒店信息和用户评价,成为了消费者决策的重要参考。因此,研究如何从这些平台采集酒店价格信息,并设计一个可视化查询系统,对于提升用户体验和促进旅游行业的发展具有重要意义。
研究目的
本研究旨在设计并实现一个酒店价格采集与可视化查询系统,通过自动化技术从美团、大众点评、抖音等网站采集酒店价格信息,并提供一个直观、易用的可视化查询界面,使用户能够快速获取所需信息。
研究内容
1. 目标网站分析
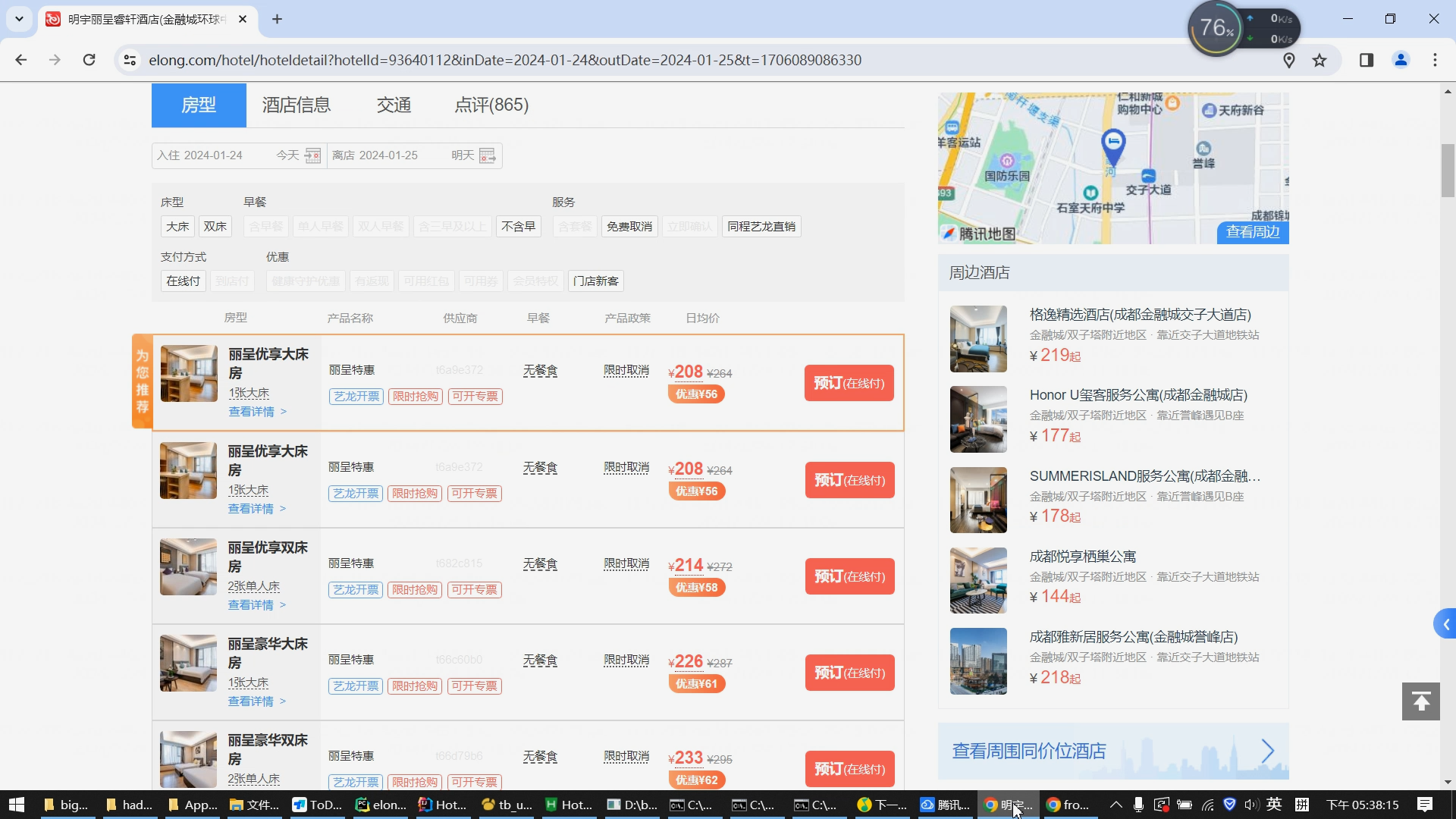
美团:作为中国领先的生活服务平台,美团拥有大量的酒店预订信息和用户评价。
大众点评:提供丰富的本地生活信息,包括酒店的价格、设施、服务等。
抖音:作为一个新兴的短视频平台,抖音上的旅游相关内容日益增多,包括酒店推荐和价格信息。
2. 酒店价格采集技术
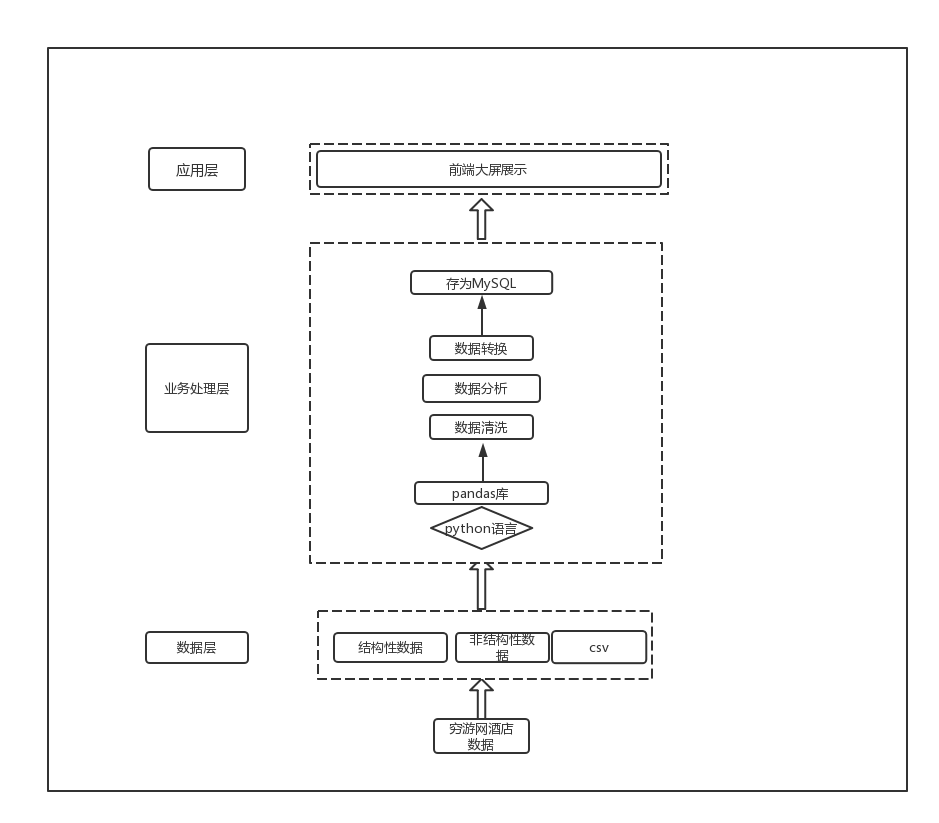
- 网络爬虫设计:针对目标网站设计并实现网络爬虫,能够自动化采集酒店价格和相关信息。
- 数据清洗与存储:对采集到的数据进行清洗和整理,确保数据的准确性和一致性,存储到数据库中。
3. 可视化查询系统设计
- 用户界面设计:设计直观、友好的用户界面,提供良好的用户体验。
- 查询功能实现:实现基于关键词、地理位置、价格区间等多维度的查询功能。
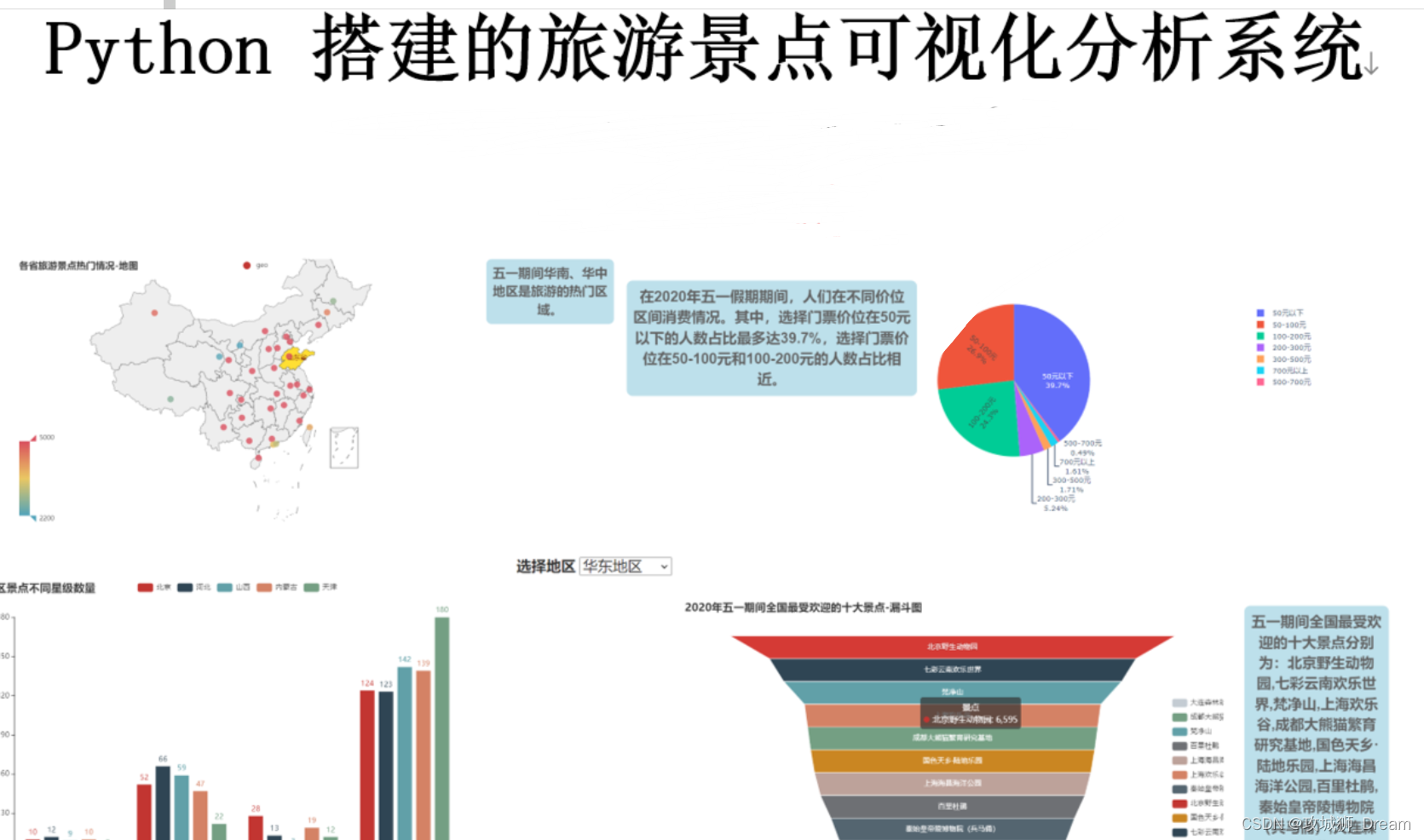
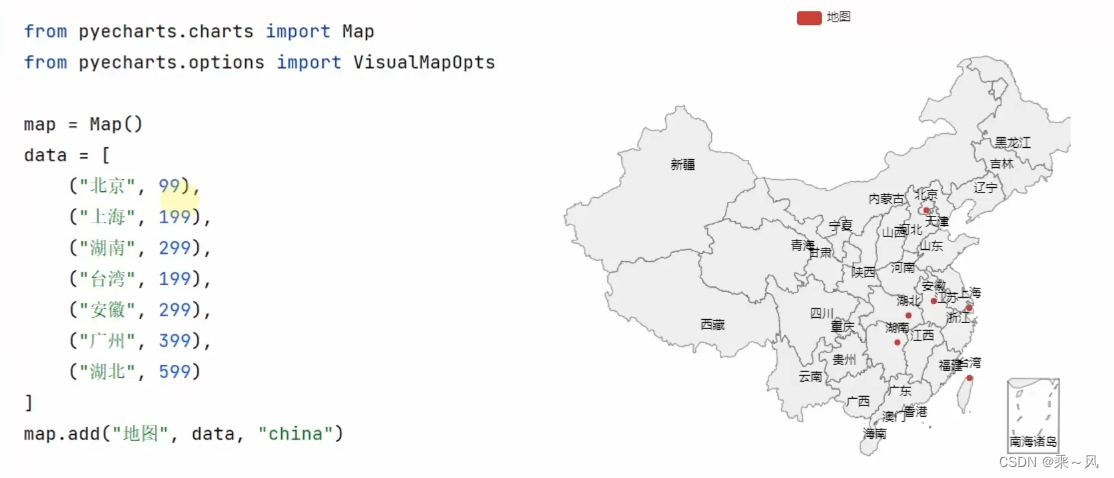
- 数据可视化:通过图表等形式直观展示酒店价格趋势和比较信息。
研究方法
- 文献调研:收集和分析相关领域的研究文献,了解当前的研究现状和发展趋势。
- 技术研究:研究网络爬虫、数据清洗、数据库设计、前端开发等相关技术。
- 系统开发:基于研究结果,开发酒店价格采集与可视化查询系统。
- 测试与评估:对系统进行测试,评估系统的性能和用户体验,并根据反馈进行优化。
预期成果
- 酒店价格数据库:构建一个包含多个平台酒店价格信息的数据库。
- 可视化查询系统:实现一个功能完善、操作简便的酒店价格可视化查询系统。
- 研究报告:撰写一份详细的研究报告,总结研究过程、方法和成果。
研究计划与时间安排
- 第1-2个月:进行文献调研和技术研究。
- 第3-5个月:设计并实现网络爬虫和数据存储方案。
- 第6-8个月:开发可视化查询系统的前端和后端。
- 第9-10个月:进行系统测试和评估,根据反馈进行优化。
- 第11-12个月:撰写研究报告,准备答辩材料。
结论
通过对美团、大众点评、抖音等平台的酒店价格信息进行采集和可视化查询,本研究将为用户提供一个全面、实时的酒店价格信息查询工具,有助于提升用户的决策效率和旅游体验。同时,该研究也将为旅游行业的信息化发展做出贡献。
```python
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
# 目标网站的URL,这里以美团为例
url = "https://www.meituan.com/hotel/"
# 发送HTTP请求
def get_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
print("Failed to retrieve the webpage")
return None
# 解析网页内容,提取酒店价格信息
def parse_page(html):
soup = BeautifulSoup(html, 'html.parser')
# 根据实际网页结构调整,这里假设每个酒店信息都在一个特定的div中
hotels = soup.find_all('div', class_='hotel-info')
hotel_data = []
for hotel in hotels:
name = hotel.find('div', class_='name').text
price = hotel.find('span', class_='price').text
# 其他需要的信息...
hotel_data.append([name, price])
return hotel_data
# 存储数据到CSV文件
def store_data(data, filename):
df = pd.DataFrame(data, columns=['Hotel Name', 'Price'])
df.to_csv(filename, index=False)
# 主函数
def main():
html = get_page(url)
if html:
hotel_data = parse_page(html)
store_data(hotel_data, 'hotel_prices.csv')
else:
print("Data retrieval failed.")
if __name__ == "__main__":
main()
在上述代码中,我们使用了requests库来发送HTTP请求,BeautifulSoup库来解析HTML内容,以及pandas库来处理和存储数据。这个例子仅用于教学目的,实际的爬虫可能需要处理更复杂的网页结构、分页、登录认证等问题。
此外,对于数据可视化部分,可以使用matplotlib、seaborn或plotly等Python库来创建图表。具体的可视化代码将取决于你希望展示的数据类型和格式。
请记住,在进行网络爬虫开发时,应遵守目标网站的robots.txt规则,并尊重版权和隐私政策。同时,频繁的请求可能会对目标网站造成负担,因此合理设置请求间隔和频率是很重要的。