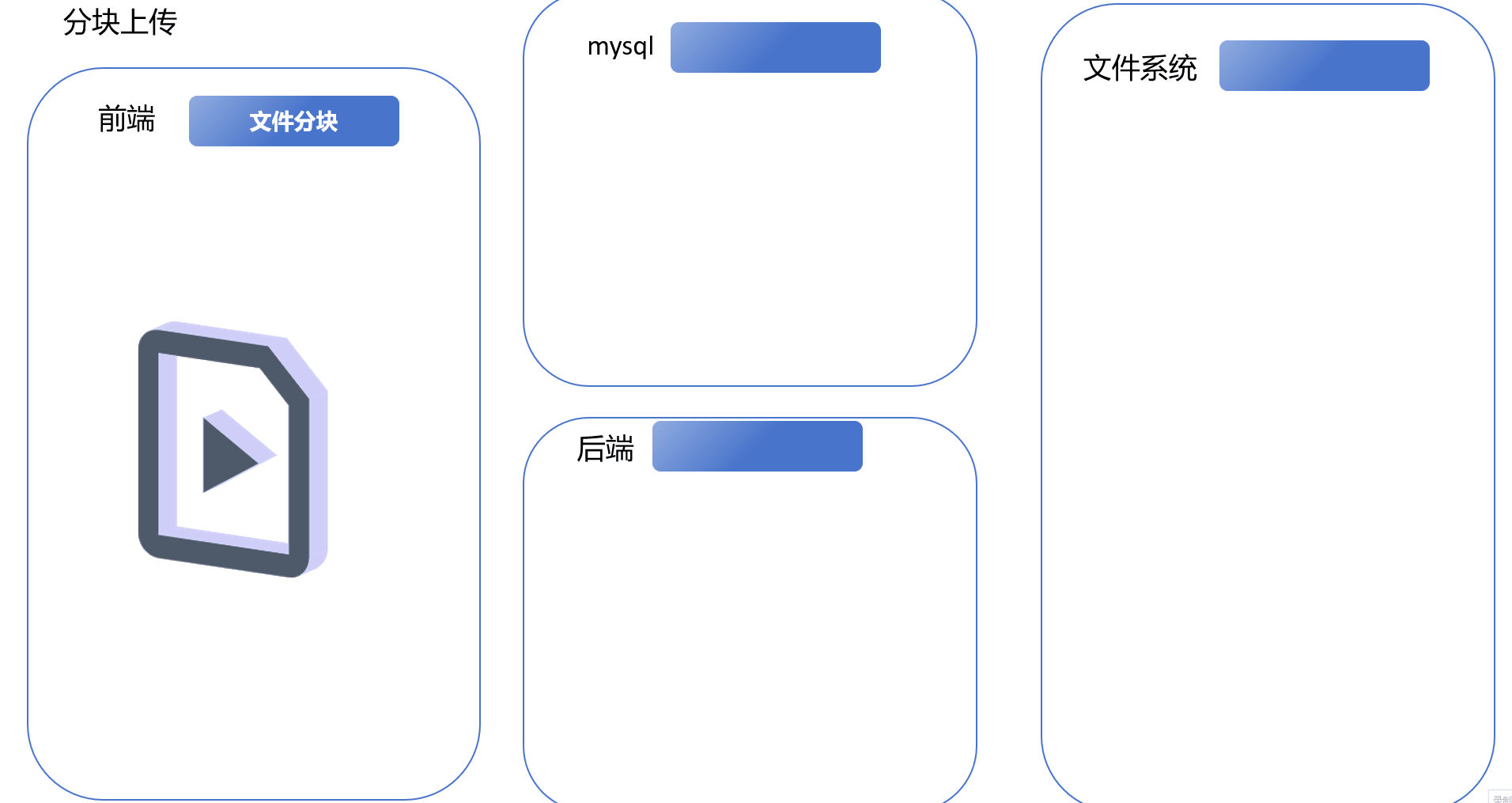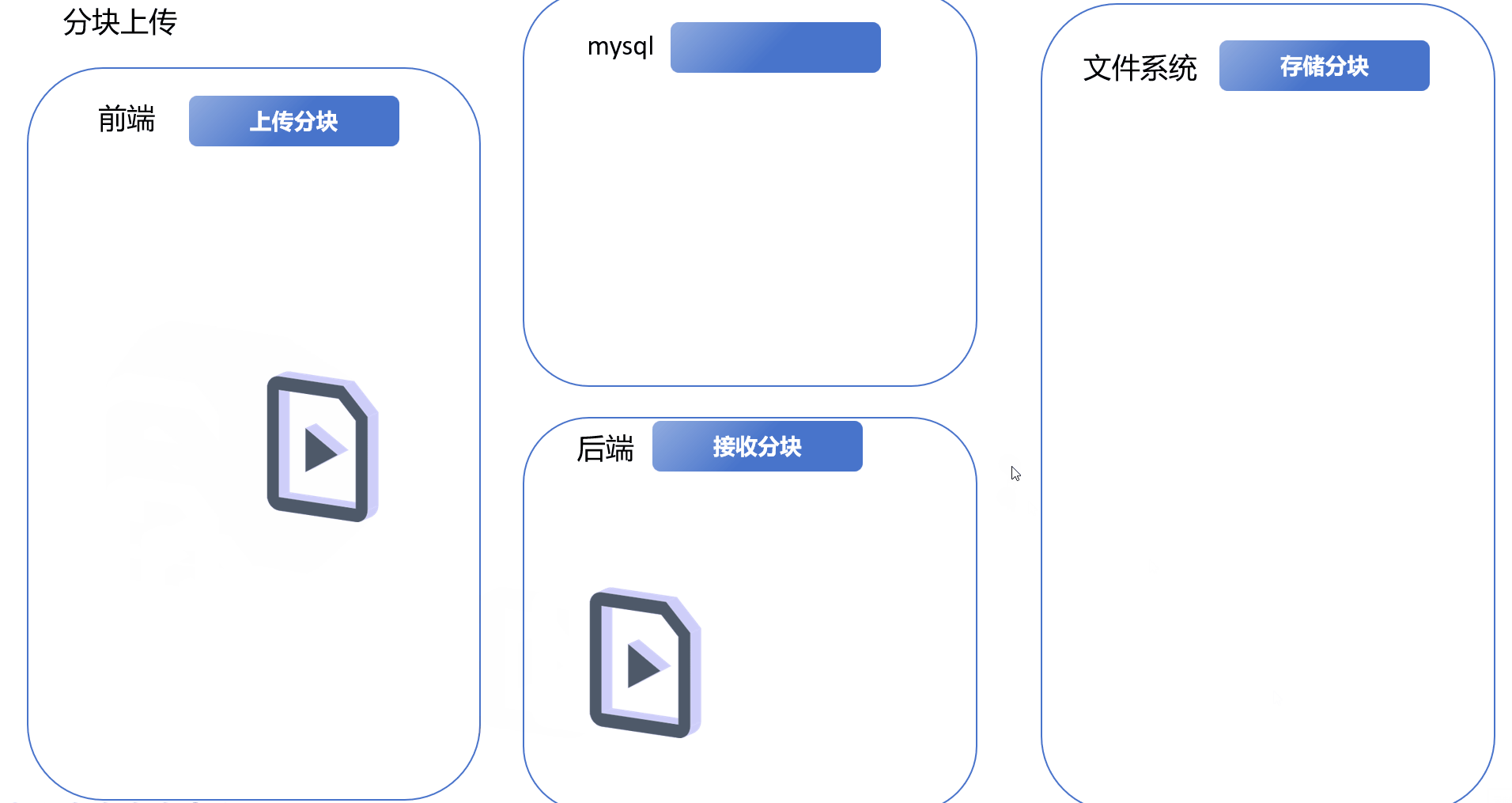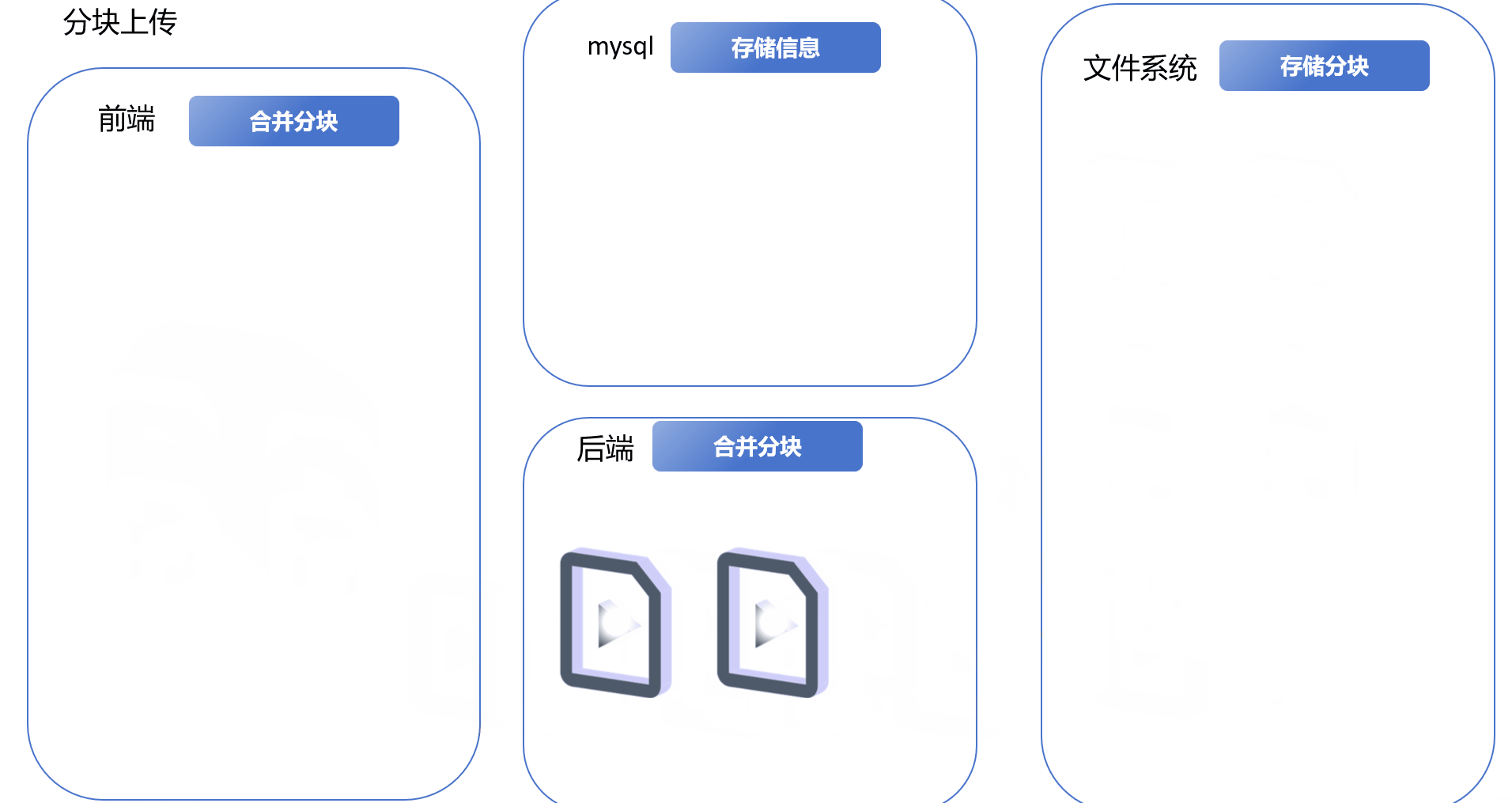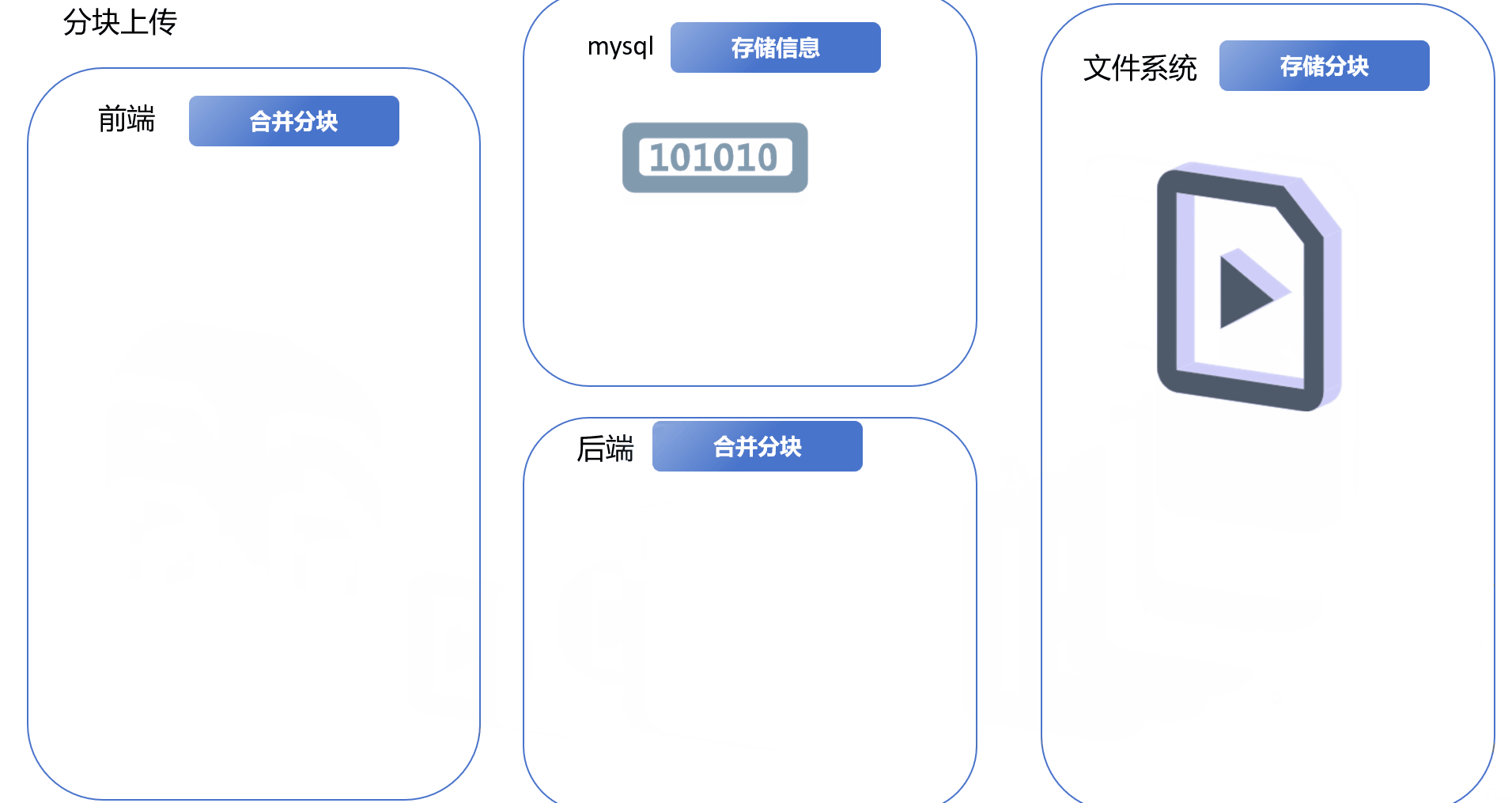
1.免密登录
2.flink StandAlone模式
3.Flink Yarn 模式 (on per 模式,on session 模式)
Flink概述
按照Apache官方的介绍,Flink是一个对有界和无界数据流进行状态计算的分布式处理引擎和框架。通俗地讲,Flink就是一个流计算框架,主要用来处理流式数据。其起源于2010年德国研究基金会资助的科研项目“Stratosphere”,2014年3月成为Apache孵化项目,12月即成为Apache顶级项目。Flinken在德语里是敏捷的意思,意指快速精巧。其代码主要是由 Java 实现,部分代码由 Scala实现。Flink既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型。
Flink安装部署
本地模式
本地模式即在linux服务器直接解压flink二进制包就可以使用,不用修改任何参数,用于一些简单测试场景。
下载安装包
直接在Flink官网下载安装包,如写作此文章时最新版为flink-1.11.1-bin-scala_2.11.tgz
上传并解压至linux
[root@vm1 myapp]# pwd
/usr/local/myapp
[root@vm1 myapp]# ll
总用量 435772
-rw-r--r--. 1 root root 255546057 2月 8 02:29 flink-1.11.1-bin-scala_2.11.tgz
解压到指定目录
[root@vm1 myapp]# tar -zxvf flink-1.11.1-bin-scala_2.11.tgz -C /usr/local/myapp/flink/
启动Flink
[root@vm1 ~]# java -version
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)
进入flink目录执行启动命令
[root@vm1 ~]# cd /usr/local/myapp/flink/flink-1.11.1/
[root@vm1 flink-1.11.1]# bin/start-cluster.sh
[root@vm1 flink-1.11.1]# jps
3577 Jps
3242 StandaloneSessionClusterEntrypoint
3549 TaskManagerRunner
执行Jps查看java进程,可以看到Flink相关进程已经启动。可以通过浏览器访问Flink的Web界面http://vm1:8081
关闭防火墙
查看linux防火墙状态
[root@vm1 ~]# systemctl status firewalld
临时关闭防火墙
[root@vm1 ~]# systemctl stop firewalld
永久关闭防火墙
[root@vm1 ~]# systemctl disable firewalld
关闭Flink
执行bin/stop-cluster.sh
集群模式
集群环境适合在生产环境下面使用,且需要修改对应的配置参数。Flink提供了多种集群模式,我们这里主要介绍standalone和Flink on Yarn两种模式。
Standalone模式
Standalone是Flink的独立集群部署模式,不依赖任何其它第三方软件或库。如果想搭建一套独立的Flink集群,不依赖其它组件可以使用这种模式。搭建一个标准的Flink集群,需要准备3台Linux机器。
Linux机器规划
节点类型 主机名 IP
Master vm1 192.168.174.136
Slave vm2 192.168.174.137
Slave vm3 192.168.174.138
在Flink集群中,Master节点上会运行JobManager(StandaloneSessionClusterEntrypoint)进程,Slave节点上会运行TaskManager(TaskManagerRunner)进程。
集群中Linux节点都要配置JAVA_HOME,并且节点之间需要设置ssh免密码登录,至少保证Master节点可以免密码登录到其他两个Slave节点,linux防火墙也需关闭。
设置免密登录
1)先在每一台机器设置本机免密登录自身
[root@vm1 ~]# ssh-keygen -t rsa
[root@vm1 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
在本机执行ssh登录自身,不提示输入密码则表明配置成功
[root@vm1 ~]# ssh vm1
Last login: Tue Sep 29 22:23:39 2020 from vm1
在其它机器vm2、vm3执行同样的操作:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh vm2
ssh vm3
2)设置vm1免密登录其它机器
把vm1的公钥文件拷贝到其它机器vm2、vm3上
[root@vm1 ~]# scp ~/.ssh/id_rsa.pub root@vm2:~/
[root@vm1 ~]# scp ~/.ssh/id_rsa.pub root@vm3:~/
登录到vm2、vm3,把vm1的公钥文件追加到自己的授权文件中
[root@vm2 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
[root@vm3 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
如果提示没有 ~/.ssh/authorized_keys目录则可以在这台机器上执行ssh-keygen -t rsa。不建议手动创建.ssh目录!
验证在vm1上ssh登录vm2、vm3是否无需密码,不需要密码则配置成功!
[root@vm1 ~]# ssh vm2
Last login: Mon Sep 28 22:31:22 2020 from 192.168.174.133
[root@vm1 ~]# ssh vm3
Last login: Tue Sep 29 22:35:25 2020 from vm1
执行exit退回到本机
[root@vm3 ~]# exit
logout
Connection to vm3 closed.
[root@vm1 ~]#
3)同样方式设置其它机器之间的免密登录
在vm2、vm3上执行同样的步骤
把vm2的公钥文件拷贝到vm1、vm3
[root@vm2 ~]# scp ~/.ssh/id_rsa.pub root@vm1:~/
[root@vm2 ~]# scp ~/.ssh/id_rsa.pub root@vm3:~/
[root@vm1 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
[root@vm3 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
把vm3的公钥文件拷贝到vm1、vm2
[root@vm3 ~]# scp ~/.ssh/id_rsa.pub root@vm1:~/
[root@vm3 ~]# scp ~/.ssh/id_rsa.pub root@vm2:~/
[root@vm1 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
[root@vm2 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
4)验证ssh免密码登录
[root@vm2 ~]# ssh vm1
[root@vm2 ~]# ssh vm3
[root@vm3 ~]# ssh vm1
[root@vm3 ~]# ssh vm2
设置主机时间同步
如果集群内节点时间相差太大的话,会导致集群服务异常,所以需要保证集群内各节点时间一致。
执行命令yum install -y ntpdate安装ntpdate
执行命令ntpdate -u ntp.sjtu.edu.cn 同步时间
Flink安装步骤
下列步骤都是先在Master机器上操作,再拷贝到其它机器(确保每台机器都安装了jdk)
解压Flink安装包
[root@vm1 myapp]# tar -zxvf flink-1.11.1-bin-scala_2.11.tgz -C /usr/local/myapp/flink/
修改Flink的配置文件flink-1.11.1/conf/flink-conf.yaml
把jobmanager.rpc.address配置的参数值改为vm1
jobmanager.rpc.address: vm1
修改Flink的配置文件flink-1.11.1/conf/workers
[root@vm1 conf]# vim workers
vm2
vm3
将vm1这台机器上修改后的flink-1.11.1目录复制到其他两个Slave节点
scp -rq /usr/local/myapp/flink vm2:/usr/local/myapp/
scp -rq /usr/local/myapp/flink vm3:/usr/local/myapp/
在vm1这台机器上启动Flink集群服务
执行这一步时确保各个服务器防火墙已关闭
进入flink目录/flink-1.11.1/bin执行start-cluster.sh
[root@vm1 ~]# cd /usr/local/myapp/flink/flink-1.11.1/
[root@vm1 flink-1.11.1]# bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host vm1.
Starting taskexecutor daemon on host vm2.
Starting taskexecutor daemon on host vm3.
查看vm1、vm2和vm3这3个节点上的进程信息
[root@vm1 flink-1.11.1]# jps
4983 StandaloneSessionClusterEntrypoint
5048 Jps
[root@vm2 ~]# jps
4122 TaskManagerRunner
4175 Jps
[root@vm3 ~]# jps
4101 Jps
4059 TaskManagerRunner
查看Flink Web UI界面,访问http://vm1:8081
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6tKRfsOg-1603003404551)(image-20201001000826062.png)]
8)提交任务执行
[root@vm1 flink-1.11.1]# bin/flink run ./examples/batch/WordCount.jar
提交任务可以在任意一台flink客户端服务器提交,本例中在vm1、vm2、vm3都可以
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AJKInteJ-1603003404554)(image-20201017200539366.png)]
停止flink集群
bin/stop-cluster.sh
10)单独启动、停止进程
手工启动、停止主进程StandaloneSessionClusterEntrypoint
[root@vm1 flink-1.11.1]# bin/jobmanager.sh start
[root@vm1 flink-1.11.1]# bin/jobmanager.sh stop
手工启动、停止TaskManagerRunner(常用于向集群中添加新的slave节点)
[root@vm1 flink-1.11.1]# bin/taskmanager.sh start
[root@vm1 flink-1.11.1]# bin/taskmanager.sh stop
Flink on YARN 模式
Flink on Yarn模式使用YARN 作为任务调度系统,即在YARN上启动运行flink。好处是能够充分利用集群资源,提高服务器的利用率。这种模式的前提是要有一个Hadoop集群,并且只需公用一套hadoop集群就可以执行MapReduce和Spark以及Flink任务,非常方便。因此需要先搭建一个hadoop集群。
Hadoop集群搭建
1)下载并解压到指定目录
从官网下载Hadoop二进制包,上传到linux服务器,并解压到指定目录。
[root@vm1 ~]# tar -zxvf hadoop-2.9.2.tar.gz -C /usr/local/myapp/hadoop/
1
2)配置环境变量
vim /etc/profile
export HADOOP_HOME=/usr/local/myapp/hadoop/hadoop-2.9.2/
export PATH=$PATH:$HADOOP_HOME/bin
执行hadoop version查看版本号
[root@vm1 hadoop]# source /etc/profile
[root@vm1 hadoop]# hadoop version
Hadoop 2.9.2
3)修改hadoop-env.sh文件
修改配置export JAVA_HOME=${JAVA_HOME}指定JAVA_HOME路径:
export JAVA_HOME=/usr/local/myapp/jdk/jdk1.8.0_261/
1
同时指定Hadoop日志路径,先创建好目录:
[root@vm1]# mkdir -p /data/hadoop_repo/logs/hadoop
1
再配置HADOOP_LOG_DIR
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
1
4)修改yarn-env.sh文件
指定JAVA_HOME路径
export JAVA_HOME=/usr/local/myapp/jdk/jdk1.8.0_261/
1
指定YARN日志目录:
[root@vm1 ~]# mkdir -p /data/hadoop_repo/logs/yarn
1
export YARN_LOG_DIR=/data/hadoop_repo/logs/yarn
1
4)修改core-site.xml
配置NameNode的地址fs.defaultFS、Hadoop临时目录hadoop.tmp.dir
NameNode和DataNode的数据文件都会存在临时目录下的对应子目录下
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
6)修改hdfs-site.xml
dfs.namenode.secondary.http-address指定secondaryNameNode的http地址,本例设置vm2机器为SecondaryNameNode
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm2:50090</value>
</property>
</configuration>
7)修改yarn-site.xml
yarn.resourcemanager.hostname指定resourcemanager的服务器地址,本例设置vm1机器为hadoop主节点
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>vm1</value>
</property>
</configuration>
8)修改mapred-site.xml
[root@vm1 hadoop]# mv mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
mapreduce.framework.name设置使用yarn运行mapreduce程序
9) 配置slaves
设置vm2、vm3为Hadoop副节点
[root@vm1 hadoop]# vim slaves
vm2
vm3
10)设置免密码登录
免密配置参考前文 设置服务器间相互免密登录
11)拷贝hadoop到其它机器
将在vm1上配置好的Hadoop目录拷贝到其它服务器
[root@vm1 hadoop]# scp -r /usr/local/myapp/hadoop/ vm2:/usr/local/myapp/
[root@vm1 hadoop]# scp -r /usr/local/myapp/hadoop/ vm3:/usr/local/myapp/
12)格式化HDFS
在Hadoop集群主节点vm1上执行格式化命令
[root@vm1 bin]# pwd
/usr/local/myapp/hadoop/hadoop-2.9.2/bin
[root@vm1 bin]# hdfs namenode -format
如果要重新格式化NameNode,则需要先将原来NameNode和DataNode下的文件全部删除,否则报错。NameNode和DataNode所在目录在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置
13)启动集群
直接启动全部进程
[root@vm1 hadoop-2.9.2]# sbin/start-all.sh
也可以单独启动HDFS
sbin/start-dfs.sh
也可以单独启动YARN
sbin/start-yarn.sh
14)查看web页面
要在本地机器http访问虚拟机先关闭linux防火墙,关闭linux防火墙请参照前文
查看HDFS Web页面:
http://vm1:50070/
查看YARN Web 页面:
http://vm1:8088/cluster
15)查看各个节点进程
[root@vm1 ~]# jps
5026 ResourceManager
5918 Jps
5503 NameNode
[root@vm2 ~]# jps
52512 NodeManager
52824 Jps
52377 DataNode
52441 SecondaryNameNode
[root@vm3 ~]# jps
52307 DataNode
52380 NodeManager
52655 Jps
16)停止Hadoop集群
[root@vm1 hadoop-2.9.2]# sbin/stop-all.sh
Hadoop集群搭建完成后就可以在Yarn上运行Flink了!
Flink on Yarn的两种方式
第1种:在YARN中预先初始化一个Flink集群,占用YARN中固定的资源。该Flink集群常驻YARN 中,所有的Flink任务都提交到这里。这种方式的缺点在于不管有没有Flink任务执行,Flink集群都会独占系统资源,除非手动停止。如果YARN中给Flink集群分配的资源耗尽,只能等待YARN中的一个作业执行完成释放资源才能正常提交下一个Flink作业。
第2种:每次提交Flink任务时单独向YARN申请资源,即每次都在YARN上创建一个新的Flink集群,任务执行完成后Flink集群终止,不再占用机器资源。这样不同的Flink任务之间相互独立互不影响。这种方式能够使得资源利用最大化,适合长时间、大规模计算任务。
下面分别介绍2种方式的具体步骤。
第1种方式
不管是哪种方式,都要先运行Hadoop集群
1)启动Hadoop集群
[root@vm1 hadoop-2.9.2]# sbin/start-all.sh
2)将flink依赖的hadoop相关jar包拷贝到flink目录
[root@vm1]# cp /usr/local/myapp/hadoop/hadoop-2.9.2/share/hadoop/yarn/hadoop-yarn-api-2.9.2.jar /usr/local/myapp/flink/flink-1.11.1/lib
[root@vm1]# cp /usr/local/myapp/hadoop/hadoop-2.9.2/share/hadoop/yarn/sources/hadoop-yarn-api-2.9.2-sources.jar /usr/local/myapp/flink/flink-1.11.1/lib
还需要 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar ,可以从maven仓库下载并放到flink的lib目录下。
3)创建并启动flink集群
在flink的安装目录下执行
bin/yarn-session.sh -n 2 -jm 512 -tm 512 -d
1
这种方式创建的是一个一直运行的flink集群,也称为flink yarn-session
创建成功后,可以访问hadoop任务页面,查看是否有flink任务成功运行:http://vm1:8088/cluster
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bIcGDTS0-1603003404558)(image-20201015212535158.png)]
创建成功后,flink控制台会输出web页面的访问地址,可以在web页面查看flink任务执行情况:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-91J9xKue-1603003404560)(image-20201015213139655.png)]
控制台输出http://vm2:43243 可以认为flink的Jobmanager进程就运行在vm2上,且端口是43243。指定host、port提交flink任务时可以使用这个地址+端口
4)附着到flink集群
创建flink集群后会有对应的applicationId,因此执行flink任务时也可以附着到已存在的、正在运行的flink集群
#附着到指定flink集群
[root@vm1 flink-1.11.1]# bin/yarn-session.sh -id application_1602852161124_0001
1
2
applicationId参数是上一步创建flink集群时对应的applicationId
5) 提交flink任务
可以运行flink自带的wordcount样例:
[root@vm1 flink-1.11.1]# bin/flink run ./examples/batch/WordCount.jar
在flink web页面 http://vm2:43243/ 可以看到运行记录:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZYwxhNTz-1603003404561)(image-20201015213038724.png)]
可以通过-input和-output来手动指定输入数据目录和输出数据目录:
-input hdfs://vm1:9000/words
-output hdfs://vm1:9000/wordcount-result.txt
第2种方式
这种方式很简单,就是在提交flink任务时同时创建flink集群
[root@vm1 flink-1.11.1]# bin/flink run -m yarn-cluster -yjm 1024 ./examples/batch/WordCount.jar
需要在执行上述命令的机器(即flink客户端)上配置环境变量YARN_CONF_DIR、HADOOP_CONF_DIR或者HADOOP_HOME环境变量,Flink会通过这个环境变量来读取YARN和HDFS的配置信息。
如果报下列错,则需要禁用hadoop虚拟内存检查:
Diagnostics from YARN: Application application_1602852161124_0004 failed 1 times (global limit =2; local limit is =1) due to AM Container for appattempt_1602852161124_0004_000001 exited with exitCode: -103
Failing this attempt.Diagnostics: [2020-10-16 23:35:56.735]Container [pid=6890,containerID=container_1602852161124_0004_01_000001] is running beyond virtual memory limits. Current usage: 105.8 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container.
修改所有hadoop机器(所有 nodemanager)的文件$HADOOP_HOME/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
重启hadoop集群再次运行
[root@vm1 hadoop-2.9.2]# sbin/stop-all.sh
[root@vm1 hadoop-2.9.2]# sbin/start-all.sh
[root@vm1 flink-1.11.1]# bin/flink run -m yarn-cluster -yjm 1024 ./examples/batch/WordCount.jar
任务成功执行,控制台输出如下。可以使用控制台输出的web页面地址vm3:44429查看任务。不过这种模式下任务执行完成后Flink集群即终止,所以输入地址vm3:44429时可能看不到结果,因为此时任务可能执行完了,flink集群终止,页面也访问不了了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XsBPibbF-1603003404563)(image-20201016000427565.png)]
上述Flink On Yarn的2种方式案例中分别使用了两个命令:yarn-session.sh 和 flink run
yarn-session.sh 可以用来在Yarn上创建并启动一个flink集群,可以通过如下命令查看常用参数:
[root@vm1 flink-1.11.1]# bin/yarn-session.sh -h
-n :表示分配的容器数量,即TaskManager的数量
-jm:设置jobManagerMemory,即JobManager的内存,单位MB
-tm:设置taskManagerMemory ,即TaskManager的内存,单位MB
-d: 设置运行模式为detached,即后台独立运行
-nm:设置在YARN上运行的应用的name(名字)
-id: 指定任务在YARN集群上的applicationId ,附着到后台独立运行的yarn session中
flink run命令既可以提交任务到Flink集群中执行,也可以在提交任务时创建一个新的flink集群,可以通过如下命令查看常用参数:
[root@vm1 flink-1.11.1]# bin/flink run -h
-m: 指定主节点(JobManger)的地址,在此命令中指定的JobManger地址优先于配置文件中的
-c: 指定jar包的入口类,此参数在jar 包名称之前
-p:指定任务并行度,同样覆盖配置文件中的值
flink run使用举例:
1)提交并执行flink任务,默认查找当前YARN集群中已有的yarn-session的JobManager
[root@vm1 flink-1.11.1]# bin/flink run ./examples/batch/WordCount.jar -input hdfs://vm1:9000/hello.txt -output hdfs://vm1:9000/result_hello
1
2)提交flink任务时显式指定JobManager的的host的port,该域名和端口是创建flink集群时控制台输出的
[root@vm1 flink-1.11.1]# bin/flink run -m vm3:39921 ./examples/batch/WordCount.jar -input hdfs://vm1:9000/hello.txt -output hdfs://vm1:9000/result_hello
1
3)在YARN中启动一个新的Flink集群,并提交任务
[root@vm1 flink-1.11.1]# bin/flink run -m yarn-cluster -yjm 1024 ./examples/batch/WordCount.jar -input hdfs://vm1:9000/hello.txt -output hdfs://vm1:9000/result_hello
Flink on Yarn集群HA
Flink on Yarn模式的HA利用的是YARN的任务恢复机制。Flink on Yarn模式依赖hadoop集群,这里可以使用前文中的hadoop集群。这种模式下的HA虽然依赖YARN的任务恢复机制,但是Flink任务在恢复时,需要依赖检查点产生的快照。快照虽然存储在HDFS上,但是其元数据保存在zk中,所以也需要一个zk集群,使用前文配置好的zk集群即可。




























![[Spring Cloud] gateway全局异常捕捉统一返回值](https://img-blog.csdnimg.cn/img_convert/fca859bfb0d31739f4139bd88bab9846.png)