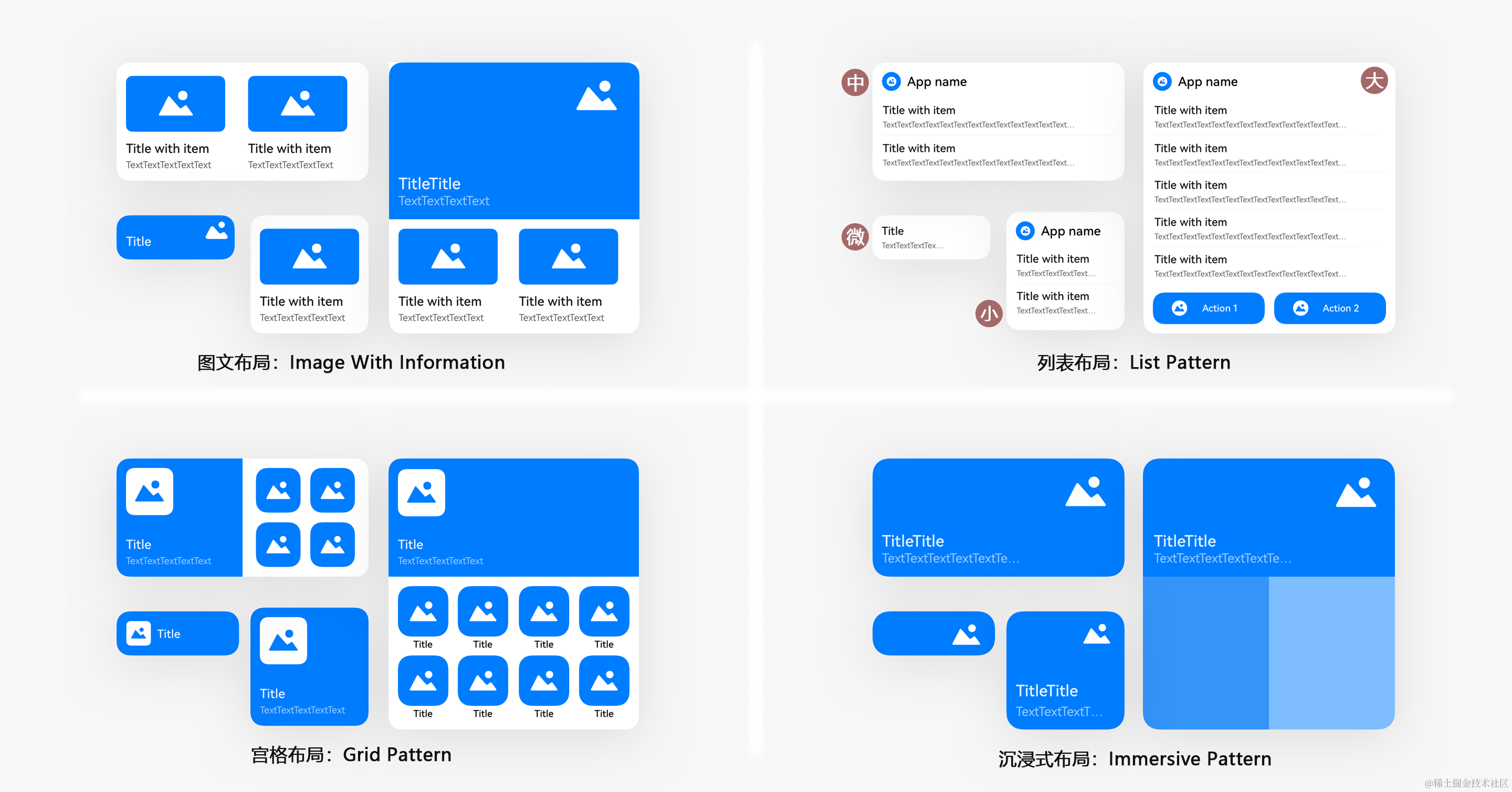
对于获取哔哩哔哩视频目录的方法我之前也有过搜索, 最先搜索到的是
var result = '';
var content = document.getElementsByClassName('list-box')[0].querySelectorAll('li');
for (var i = 0; i< content.length; i++){
temp = content[i].innerText.split('\n');
if (temp[temp.length-1].length < 6){
temp[temp.length-1] += ".00"
}
temp.join('\t')
result += temp;
result += '\n';
}
但是后来发现用不了, 然后就想着通过代码来实现
今天是 2024/4/4, 方法目前还能用, 但是有点麻烦, 各位可以自己看着改
先说一下需要注意的地方:
1.因为获取B站的视频目录就要去访问它的服务器, 有一定的爬虫性质, 所以为了防止过多的请求导致自己被拉入黑名单, 所以我请求一次之后就会直接把获取到的内容存到本地, 这样就相当于只访问了一次
2.代码是 python 编写的, 是我从别的地方看到后改了一下, 如果觉得是屎一样的代码, 请默喷
3.你需要在当前目录下新建一个文件, 文件名我自己定义的是: 'Bilibili视频目录.html'
4.注意文件名不要带上引号
5.下面会有操作流程, 把 response 中的内容整个复制到该文件中
6.现在如果通过 requests 库发请求的话, 貌似无法拿到具体的网页内容, 所以就只能自己去开发者工具找
流程:
打开开发者工具
选中 network
选中 all
顺着往左看有一个框框是过滤的, 输入视频地址你就可以找到这个请求
点一下后到右边找到 response, 需要复制里面的所有内容
代码如下:
import requests
import json
import os
from datetime import datetime
from bs4 import BeautifulSoup
# 参考链接:
# https://zhuanlan.zhihu.com/p/117569614
# https://blog.csdn.net/weixin_42914706/article/details/129112667
# pyinstaller --onefile --name=获取哔哩哔哩视频目录信息 D:\knowledge\python_reptile\python_reptile_scrapy\GetVideoCatalog.py
def print_directory(data):
soup = BeautifulSoup(data, 'html.parser')
target = 'window.__INITIAL_STATE__ ='
script_tags = soup.find_all('script')
# script_tags = soup.find_all(string='script')
# print(script_tags)
# find_all(self, name=None, attrs={}, recursive=True, string=None, limit=None, **kwargs)
# name 参数: 用于指定要查找的标签名称,可以是字符串、正则表达式、列表或 True。例如 soup.find_all('a') 会查找所有的 <a> 标签。
# attrs 参数: 用于指定要查找的标签的属性及对应的值。例如 soup.find_all(attrs={'class': 'title'}) 会查找所有具有 class="title" 属性的标签。
# recursive 参数: 用于指定是否递归查找子孙节点,默认为 True。如果设置为 False,则只会查找直接子节点。
# text 参数: 用于根据标签的文本内容进行查找。例如 soup.find_all(text='Hello') 会查找所有文本内容为 'Hello' 的标签。
# limit 参数: 用于限制返回结果的数量,即最多返回的匹配元素个数。
# string 参数: 与 text 参数类似,用于根据标签的字符串内容进行查找,但它仅匹配直接子节点的字符串内容。
count = 1
for script in script_tags:
script_text = script.get_text()
if target in script_text:
result = script_text.replace(target, "").split('};')[0] + '}'
json_data = json.loads(result)
with open(name + '.txt', 'w', encoding='utf-8') as file:
for index in json_data.get('videoData').get('pages'):
log = 'P{0} {1}'.format(count, index.get('part'))
file.write(log + '\n')
print(log)
count += 1
break
if __name__ == '__main__':
current_time = datetime.now().strftime("%Y%m%d%H%M%S")
# name = 'Bilibili视频目录_{0}'.format(current_time)
name = 'Bilibili视频目录'
file_name = name + '.html'
if not os.path.exists(file_name):
with open(file_name, 'w') as file:
print("文件创建成功")
file_size = os.path.getsize(file_name)
if file_size == 0:
url = input("请输入网址:")
print("网址: ", url)
res = requests.get(url)
if os.path.exists(file_name):
os.remove(file_name)
with open(file_name, 'w', encoding='utf-8') as f:
f.write(res.text)
print_directory(res.text)
else:
with open(file_name, 'r', encoding='utf-8') as f:
read = f.read()
print_directory(read)
# https://www.bilibili.com/video/BV1wh411d7it/