递归与树的深度优先搜索:探索它们之间的关系
递归是一种强大而优雅的编程技术,它允许我们通过将问题分解为更小的子问题来解决复杂的问题。另一方面,树的深度优先搜索(DFS)是一种遍历或搜索树形数据结构的常用算法。这两个概念看似不同,但实际上它们之间存在着紧密的联系。在本文中,我们将深入探讨递归和树的深度优先搜索之间的关系,并通过实际的例子来加深理解。
递归的基本概念
递归是一种编程技术,它允许函数在执行过程中调用自身。一个递归函数通常包含两个部分:基本情况和递归情况。基本情况是递归的终止条件,它定义了递归的最简单情况,当满足基本情况时,函数将直接返回结果。递归情况则是函数调用自身的部分,它将问题分解为更小的子问题,并递归地解决这些子问题。
以下是一个简单的递归函数示例,用于计算一个数的阶乘:
int factorial(int n) {
if (n == 0) { // 基本情况
return 1;
} else { // 递归情况
return n * factorial(n - 1);
}
}
在这个例子中,当 n 等于 0 时,函数直接返回 1,这是递归的基本情况。否则,函数将问题分解为更小的子问题,即计算 n-1 的阶乘,并将其与 n 相乘得到最终结果。
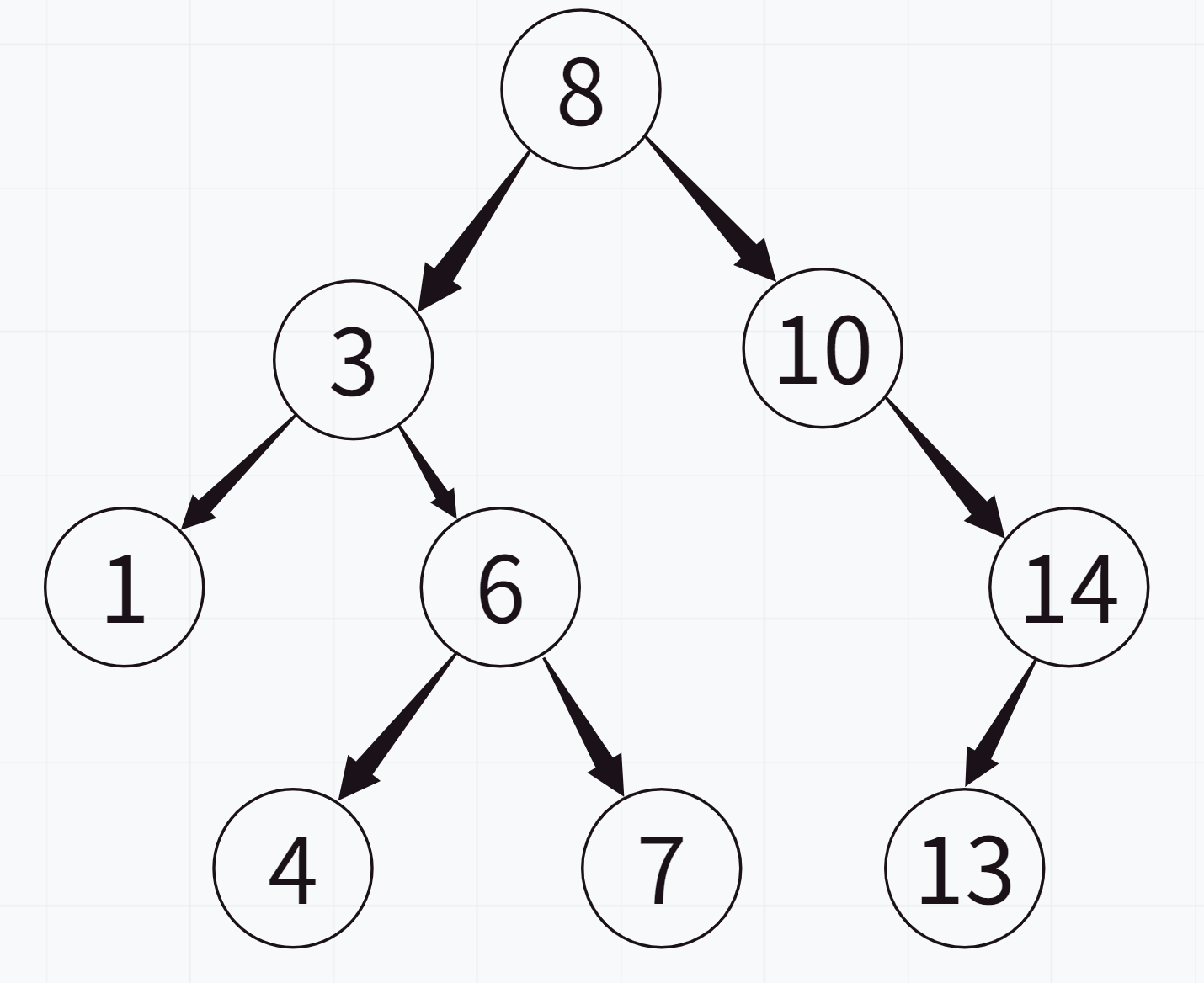
树的深度优先搜索
树是一种常见的数据结构,由节点和边组成。每个节点可以有零个或多个子节点,而没有子节点的节点称为叶节点。树的深度优先搜索(DFS)是一种遍历或搜索树形数据结构的算法。它从根节点开始,尽可能深地探索每个分支,直到达到叶节点,然后回溯到上一个节点,再探索其他分支。
以下是一个简单的树节点的定义和 DFS 遍历的示例代码:
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};
void dfs(TreeNode* node) {
if (node == nullptr) { // 基本情况
return;
}
cout << node->val << " "; // 访问当前节点
dfs(node->left); // 递归遍历左子树
dfs(node->right); // 递归遍历右子树
}
在 DFS 遍历中,我们首先访问当前节点,然后递归地遍历其左子树和右子树。当遇到空节点时,递归终止。
递归与树的深度优先搜索的关系
现在,让我们来探讨递归与树的深度优先搜索之间的关系。实际上,递归的执行过程可以看作是对一棵树进行深度优先搜索。
当我们调用一个递归函数时,它会创建一个新的函数调用,并将当前的状态保存在调用栈中。每个递归调用都对应着树中的一个节点,而函数的参数和局部变量则表示了节点的状态。当一个递归调用返回时,它会将结果传递给上一级调用,并从调用栈中弹出。这个过程与 DFS 遍历中的回溯非常相似。
让我们通过一个具体的例子来理解这种关系。
反转链表
考虑反转链表的问题。给定一个单向链表,我们需要将其反转,即原来的头节点变成尾节点,原来的尾节点变成头节点。
以下是使用递归解决该问题的示例代码:
struct ListNode {
int val;
ListNode* next;
ListNode(int x) : val(x), next(nullptr) {}
};
ListNode* reverseList(ListNode* head) {
if (head == nullptr || head->next == nullptr) { // 基本情况
return head;
}
ListNode* newHead = reverseList(head->next); // 递归反转子链表
head->next->next = head; // 将当前节点连接到子链表的尾部
head->next = nullptr; // 断开当前节点与原始子链表的连接
return newHead;
}
在这个递归解法中,我们将链表看作一个特殊的单分支树。每个节点只有一个子节点,即下一个链表节点。我们从头节点开始,递归地反转子链表,然后将当前节点连接到子链表的尾部,并断开当前节点与原始子链表的连接。
这个过程可以看作是对链表这棵特殊的树进行深度优先搜索。我们从头节点开始,尽可能深地探索链表,直到达到尾节点(基本情况)。然后,我们回溯到上一个节点,并进行相应的操作(将当前节点连接到子链表的尾部,断开与原始子链表的连接)。
合并两个有序链表
另一个例子是合并两个有序链表。给定两个按升序排列的链表,我们需要将它们合并成一个新的有序链表。
以下是使用递归解决该问题的示例代码:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if (l1 == nullptr) { // 基本情况
return l2;
}
if (l2 == nullptr) { // 基本情况
return l1;
}
if (l1->val <= l2->val) {
l1->next = mergeTwoLists(l1->next, l2); // 递归合并子链表
return l1;
} else {
l2->next = mergeTwoLists(l1, l2->next); // 递归合并子链表
return l2;
}
}
在这个递归解法中,我们同样将链表看作一棵特殊的树。我们从两个链表的头节点开始,比较它们的值,选择较小的节点作为合并后链表的头节点。然后,我们递归地合并该节点的下一个节点与另一个链表的子链表。
这个过程可以看作是对两棵树同时进行深度优先搜索。我们从两棵树的根节点开始,比较它们的值,选择较小的节点作为合并后树的根节点。然后,我们递归地合并该节点的子树与另一棵树的子树。
总结
通过上述分析和例子,我们可以看到递归和树的深度优先搜索之间有着紧密的联系。递归的执行过程可以看作是对一棵隐式的树进行深度优先搜索。每个递归调用都对应着树中的一个节点,函数的参数和局部变量表示了节点的状态。递归的展开和回溯过程与 DFS 遍历的过程非常相似。
理解递归和树的深度优先搜索之间的关系有助于我们更好地理解和设计递归算法。当面对一个问题时,我们可以尝试将其转化为树的形式,然后使用递归的思想来解决问题。这种方法在许多算法问题中都有广泛的应用,如树的遍历、图的搜索、分治算法等。
另一个需要注意的点是,递归算法的时间复杂度和空间复杂度与递归树的深度有关。递归树的深度决定了递归调用的次数和调用栈的最大深度。因此,在设计递归算法时,我们需要注意控制递归树的深度,避免出现栈溢出等问题。
总之,递归和树的深度优先搜索之间有着紧密的联系。理解这种关系可以帮助我们更好地理解和设计递归算法,将问题转化为树的形式,并使用递归的思想来解决问题。同时,我们也需要注意控制递归树的深度,以确保算法的效率和稳定性。
通过本文的讨论,我们深入探讨了递归和树的深度优先搜索之间的关系,并通过实际的例子加深了理解。希望这篇文章能够帮助读者更好地掌握递归的概念和应用,并在面对复杂问题时能够灵活运用递归的思想来解决问题。