目录
前言:
本篇来解释c/c++程序的翻译环境与运行环境中的过程,不同的编程语言的翻译环境类似,但是具体步骤可能有所差异,例如编译阶段,c/c++与java中的处理可能就不一样。
1.程序环境
在ANSI C的任何一种实现中,存在两种环境:
翻译环境:在这个环境中源代码被转换为了可执行的机器指令(二进制指令)。
执行环境:它用于实际执行代码。

2.翻译环境

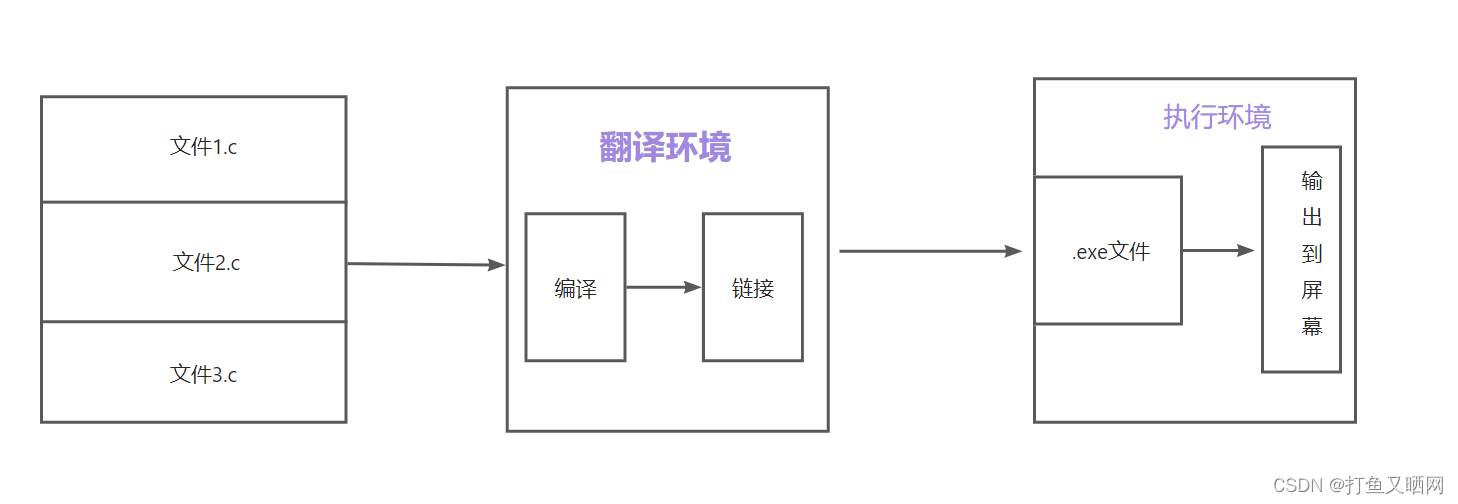
一个c语言项目可以由多个.c文件构成,那多个.c文件是怎么生成可执行程序的???

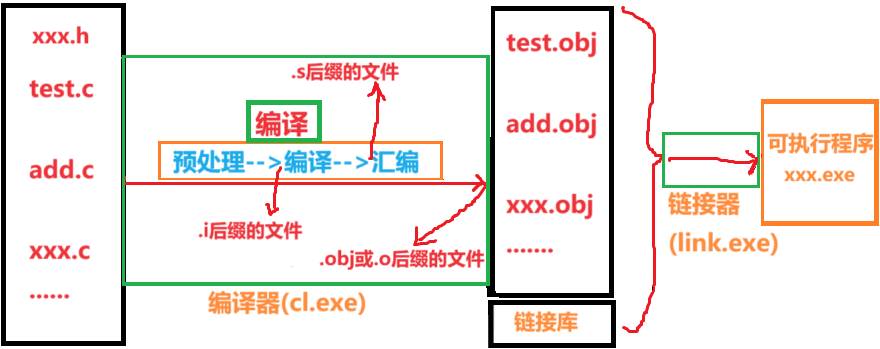
- 多个.c文件单独经过编译器,编译处理生成了对应的目标文件(在windows下目标文件是.obj,在linux下目标文件为.o)。
- 多个目标文件和链接库一起经过链接器的处理,最终生成了可执行程序。
- 链接库是指运行时库(它是支持程序运行的基本函数集合)或者第三方库。
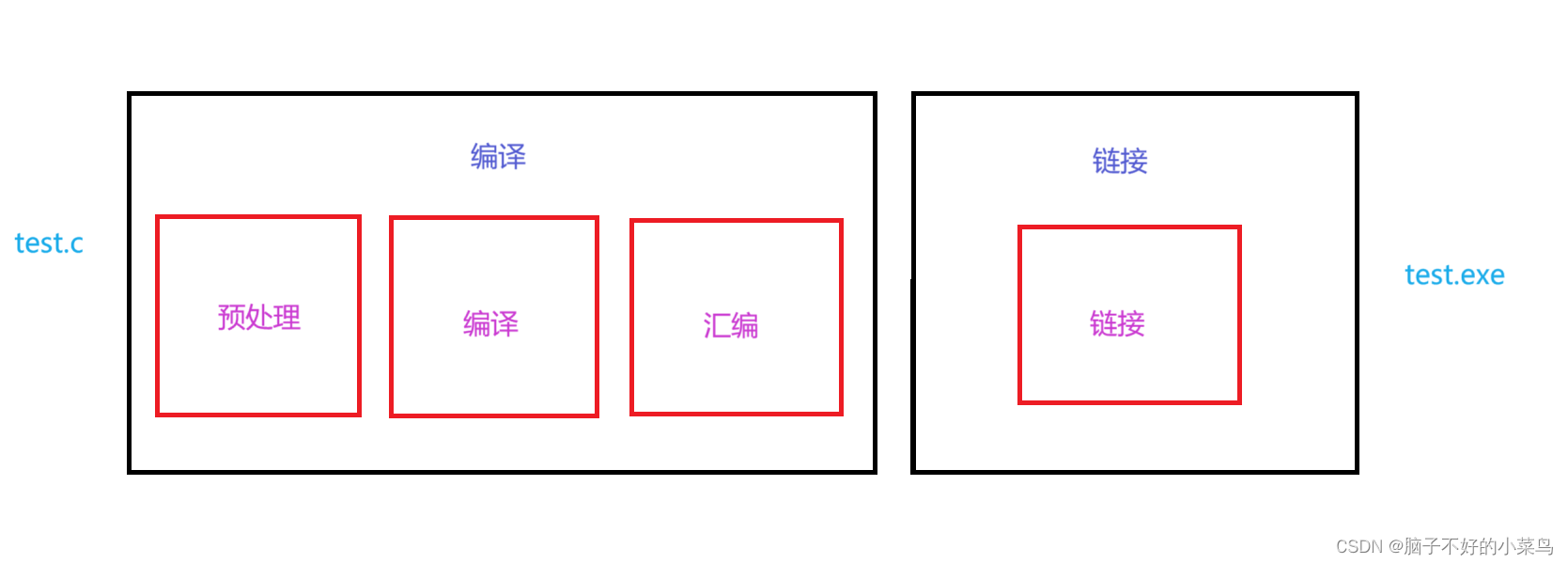
我们以linux下的gcc为例,将编译器处理拆分为3个过程:

3.预处理(预编译)
预处理(预编译)不同的书籍上叫法不一样,在gcc环境下对一个test.c文件进行预处理:
gcc -E test.c -o test.i
预处理阶段主要处理那些源文件以#开始的预编译指令:
• 将所有的 #define 删除,并展开所有的宏定义,也就是宏替换。• 处理所有的条件编译指令,如: #if 、 #ifdef 、 #elif 、 #else 、 #endif 。• 处理#include 预编译指令,将包含的头文件的内容插入到该预编译指令的位置。这个过程是递归进行的,也就是说被包含的头头件也可能包含其他头件,也就是头文件展开。• 删除所有的注释。• 添加行号和文件名标识,方便后续编译器生成调试信息等。• 或保留所有的#pragma的编译器指令,编译器后续会使用。
注意:
4.编译
编译过程就是将预处理后的文件进行一系列的:词法分析,语法分析,语义分析以及优化,生成对应的汇编代码文件。
linux命令,执行翻译环境到编译停止:
gcc -S test.i -o test.s假设对下面的代码进行编译时,就会有:
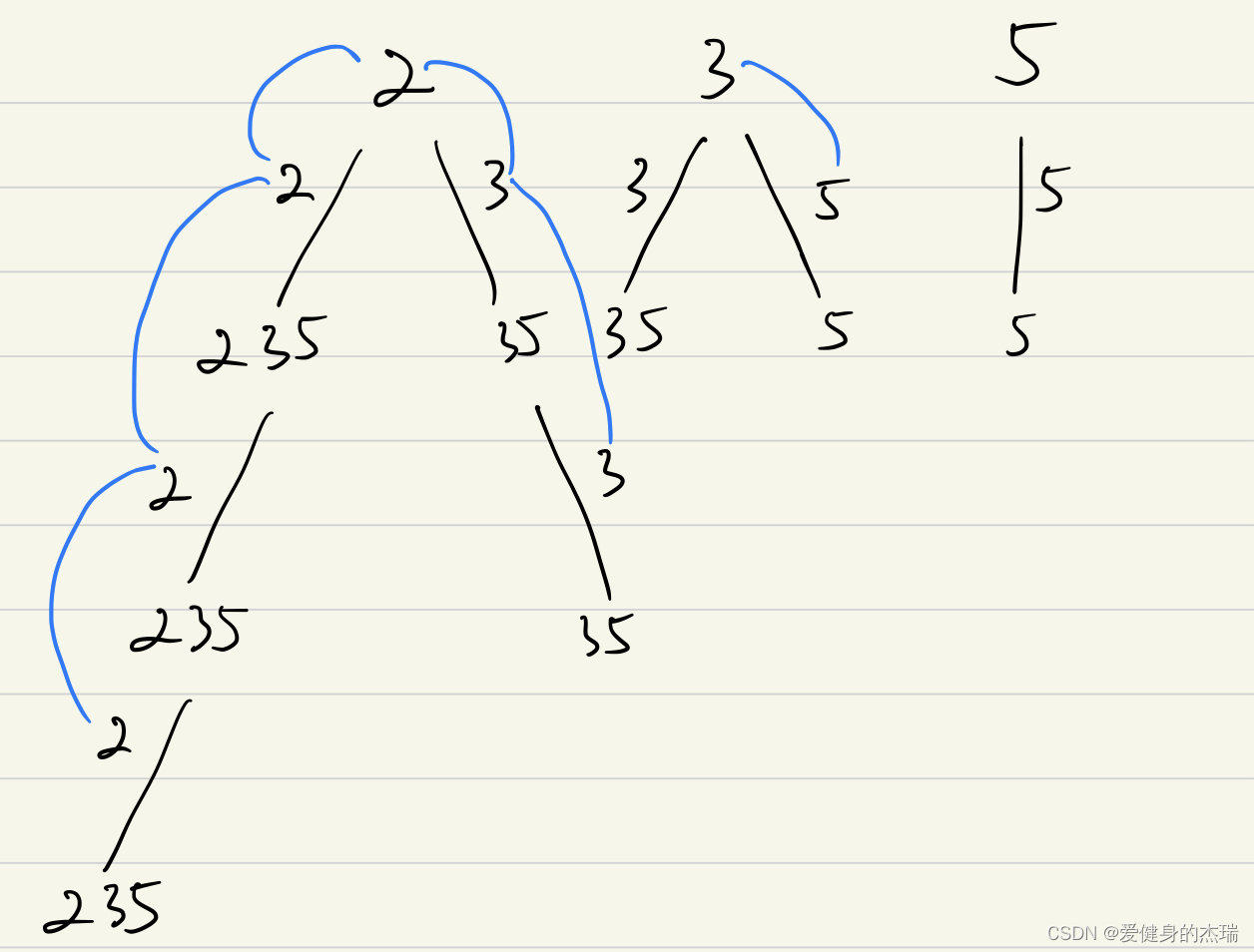
array[index] = (index+4)*(2+6);先经过词法分析,将源代码程序被输⼊扫描器,扫描器的任务就是简单的进行词法分析,把代码中的字符分割成一系列 的记号(关键字、标识符、字⾯量、特殊字符等),就会得到16个记号:、
例如:array为标识符,[,]分别为左方括号与右方括号,赋值乘加括号等。
接下来就是语法的分析,语法分析器,将对扫描产生的记号进行语法分析,从而产生语法树。这些语法树是以表达式为节点的树:
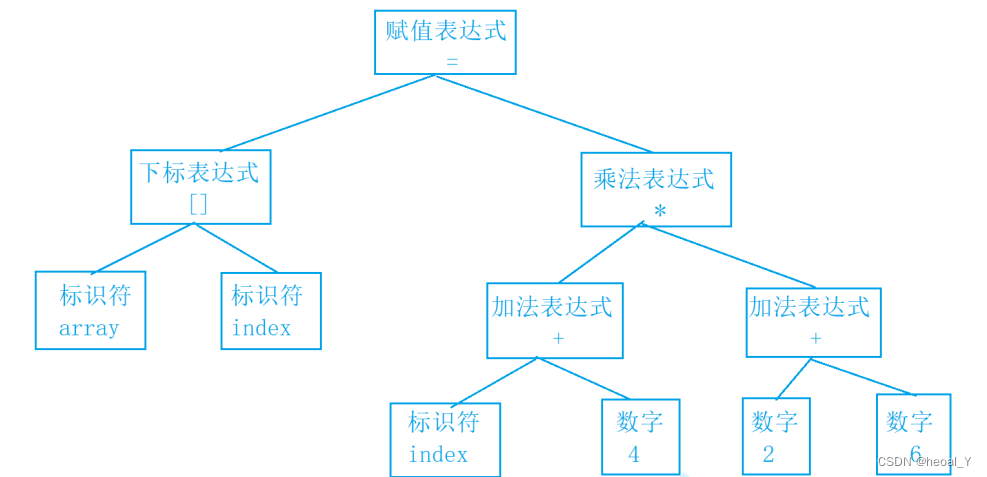
然后就是语义分析,
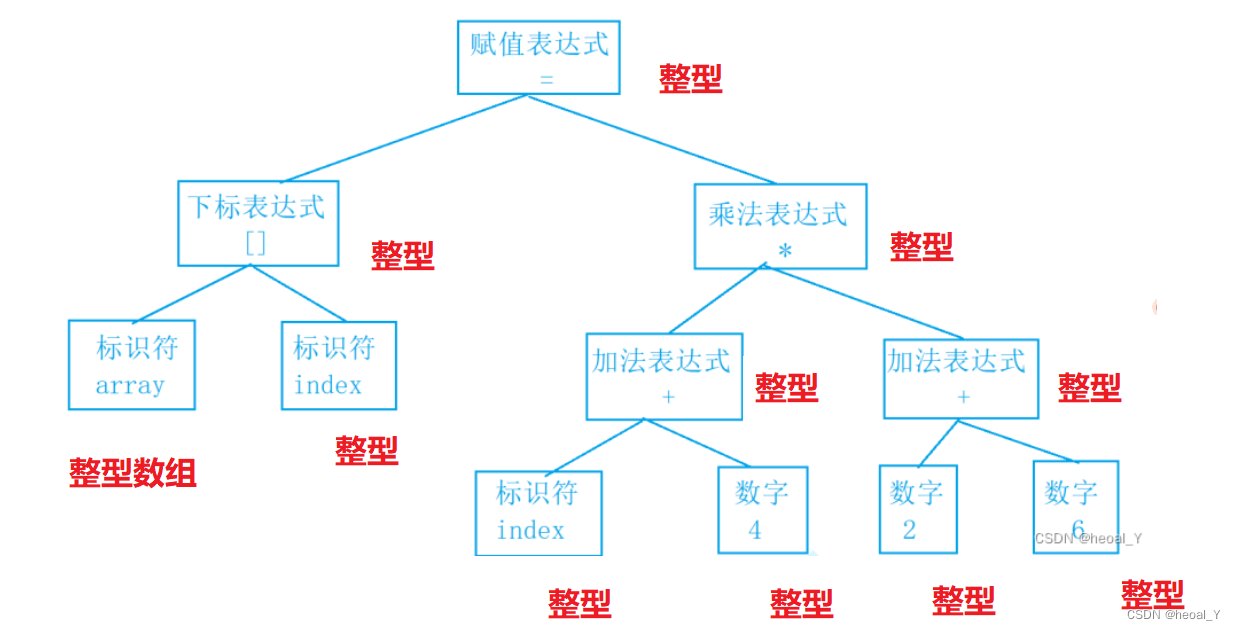
5.汇编
汇编指令:
gcc -c test.s -o test.o
6.链接
test.c:
#include <stdio.h>
//test.c
//声明外部函数
extern int Add(int x, int y);
//声明外部的全局变量
extern int g_val;
int main()
{
int a = 10;
int b = 20;
int sum = Add(a, b);
printf("%d\n", sum);
return 0;
}add.c:
int g_val = 2022;
int Add(int x, int y)
{
return x+y;
}我们已经知道,每个源文件都是单独经过编译器处理生成对应的目标文件。test.c 经过编译器处理生成 test.o ;add.c 经过编译器处理生成 add.o。我们在 test.c 的文件中使用了 add.c 文 件中的 Add 函数和 g_val 变量。我们在 test.c 文 件中每⼀次使用 Add 函数和 g_val 的时候必须确切的知道 Add 和 g_val 的地址,但是由于每个文件是单独编译的,在编译器编译 test.c 的时候并不知道 Add 函数和 g_val 变量的地址,所以暂时把调用Add 的指令的目标地址和 g_val 的地址搁置。 等待最后链接的时候由链接器根据引用的符号 Add 在其他模块中查找 Add 函数的地址 ,然后将 test.c 中所有引用到 Add 的指令重新修正,让他们的目标地址为真正的 Add 函数的地址,对于全局变量 g_val 也是类似的方法来修正地址。这个地址修正的过程也被叫做 重定向 。
具体内容可以参考《程序员的自我修养》。
我们只需要知道,在编译阶段,如果没有确定函数的地址,就会在链接阶段再去确定。也就是说当前文件只有声明没有定义,call的时候就没有地址,就需要去链接,链接就需要去符号表(这里的符号表也就是上面提到的)里面找函数的地址;而也有定义的,在编译阶段就能拿到地址,直接call函数的地址就能找到这个函数。
知道这一点,我们再联系一下c++的内联函数就知道:
为什么要在头文件中定义内联函数了(声明定义不分离),因为内联函数不进符号表,所以如果只在头文件声明内联函数,我们在其它文件要调用这个内联函数的时候,编译阶段拿不到地址,然后就会等到链接阶段去符号表里找这个函数的地址,内联函数不进符号表,所以就错了,所以如果要包带有内联函数的头文件,这个内联函数必须要有定义,就是为了让内联函数走不到链接的步骤就找到地址了。