目录
1.BF
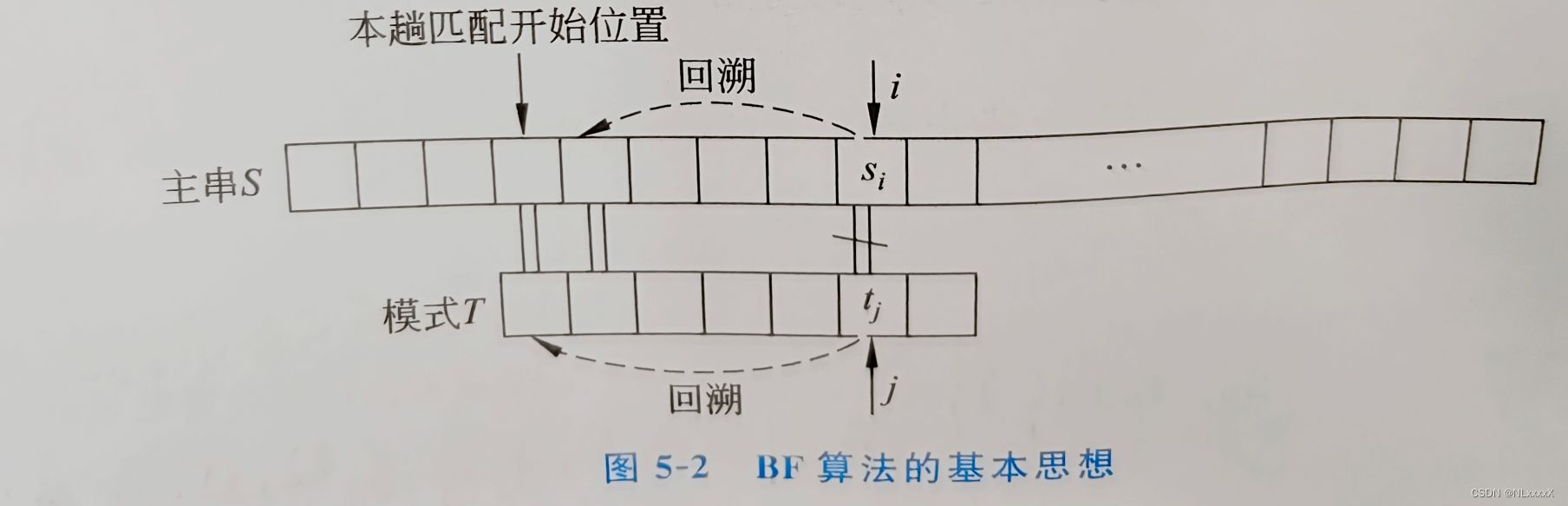
(1)算法思想——双指针
分别利用指针i、j指示主串master和模式串pattern中当前待比较的字符位置;
从master[0]和pattern[0]开始比较,若相等则继续逐个比较后续字符(i++,j++),若不相等则从主串的下一个字符(master[i-j+1])起再重新与模式串(pattern[0])比较。以此类推,直至整个模式串匹配完成,即匹配成功,否则匹配失败。
(2)算法实现
int find(const std::string &master, const std::string &pattern){
int i=0,j=0;
while(i<master.size() && j<pattern.size()){
if(master[i] == pattern[j]){
i++;
j++;
}else{
i=i-j+1; // 此时pattern[0]~pattern[j-1]已成功匹配,共j个字符,所以i需要回退j-1个字符
j=0;
}
}
if(j==pattern.size()){
return i-j; // 此时已匹配j==pattern.size()个字符,所以i比失配时还要多回退一个字符
}
return -1;
}(3)性能分析
考察:master="a string searching example consisting of simple text"、pattern="sting"
可以得到find(master,pattern)=32
其中,"while"语句的循环次数为41,即【find(master,pattern)+pattern.size()+4】,也就是说,除master中红色字符比较了2次以外,其余字符均只比较了一次。
考察:master="00000000001"、pattern="001"
可以得到find(master,pattern)=8
其中,"while"语句的循环次数为27,即【find(master,pattern)+pattern.size()+2+7*2】,也就是说,除master中红色字符比较了2次、蓝色字符比较了3次以外,其余字符均只比较了一次。
结论:
BF的算法在主串中存在多个和模式串“部分匹配”的子串的情况时,会引起指针i多次回溯,因此最坏时间复杂度T(n)=O(master.size()*pattern.size())。但在一般情况下,BF的时间复杂度近似于O(master.size()+pattern.size()),因此至今仍被采用
(4)算法改进——KMP引入
KMP算法可以在O(master.size()+pattern.size())内完成串匹配操作,其对BF算法的改进仅体现在失配时的策略上,具体为:
- 不回溯主串指针i
- 模式串指针j可以在O(1)内回溯到指定位置(仅改进后的KMP可以保证,后面会说)
2.KMP介绍
(1)串的最大相同前后缀
对于某个串而言:
- 前缀是从头部开始、不包含串尾字符的所有连续子串
- 后缀是从尾部开始、不包含串首字符的所有连续子串
- 最大相同前后缀就是所有前缀和后缀中,相等的且最长的
举个例子:
对于str="abcabc"
所有前缀:"a"、"ab"、"abc"、"abca"、"abcab"
所有后缀:"c"、"bc"、"abc"、"cabc"、"bcabc"
最大相同前后缀:"abc"
(2)最大相同前后缀在KMP中的作用
最大相同前后缀的长度可以作为失配时模式串指针回溯的参考
举个例子:
设在某次失配时已成功匹配j个字符。
① 若j>0:
对于已成功匹配的部分,设其最大相同前后缀的长度为k:
- pattern[0]~pattern[j-1]==master[i-j]~master[i-1]
- pattern[0]~pattern[k-1]==pattern[j-k]~pattern[j-1]
- master[0]~master[k-1]==master[i-k]~master[i-1]
因此我们只需要比较pattern[k]与master[i]即可(即令j=k,i不变)。
② 若j==0:
表示模式串第一个字符就匹配失败,故主串指针i不用回溯,还需前进一个位置,而模式串指针j不变。
(3)next数组
从左往右遍历模式串,对每个字符,都将其前面串的最大相同前后缀的长度求出来,然后依次存到一个一维数组里面,就构成了KMP的核心——next数组。下面我们分情况讨论next数组是如何求解的。
(4)next数组的求解
设模式串中当前字符为pattern[j]、pattern[0]~pattern[j-1]的最大相同前后缀长度为k。
① if(pattern[j]==pattern[k])
- pattern[0]~pattern[k-1]==pattern[j-k]~pattern[j-1](next[j]=k);
- pattern[0]~pattern[k-1]+pattern[k]==pattern[j-k]~pattern[j-1]+pattern[j]
故有:next[j+1]=k+1。
② if(pattern[j]!=pattern[k])
设next[k]=r:
- pattern[0]~pattern[k-1]==pattern[j-k]~pattern[j-1](next[j]=k);
- pattern[0]~pattern[r-1]==pattern[k-r]~pattern[k-1]
- pattern[j-k]~pattern[j-k+r-1]==pattern[j-r]~pattern[j-1]
因此,当pattern[j]!=pattern[k]时,需要转去判断pattern[j]与pattern[r](即pattern[next[k]])是否相等,若相等则转①,若不相等则继续转②。
③ 特别的
- 当j==0时,pattern[0]前面没有任何字符,此时令next[0]=-1
- 当j==1时,串pattern[0]没有相同的前后缀,此时next[1]=0
3.KMP实现
(1)数据结构
#include <iostream>
#include <vector>
#include <string>
class KMP{
public:
static std::vector<int> getNext(const::string &pattern);
static int find(const std::string &master, const std::string &pattern);
};(2)获取next数组
static std::vector<int> KMP::getNext(const string &pattern){
std::vector<int> next(pattern.size()+1);
next[0]=-1;// pattern[0]前面没有串
int j=1,k=next[j];
while(j<pattern.size()){
if(k==-1 || pattern[j]==pattern[k]){
next[j+1]=k+1;
j++;
k++;
}else{
k=next[k];// 转去比较pattern[j]和pattern[next[k]]
}
}
return next;
}(3)匹配
static int KMP::find(const std::string &master,const std::string pattern) {
vector<int> next=getNext(pattern);
int i=0,j=0;
while(i<master.size() && j<pattern.size()){
if(pattern[j]==master[i]){
i++;
j++;
}else if(j==0){
i++;
}else{
j=next[j];
}
}
if(j==pattern.size()){
return i-j;
}
return -1;
}(4)KMP改进
缺陷:
上面的函数getNext()中的next[j+1]=k+1存在缺陷,若有next[j+1]==j && pattern[j+1]==pattern[j],也即pattern[0]~pattern[j]中所有的字符均相等。此时若pattern[j+1]失配,势必导致模式串指针回溯到pattern[next[j+1]],也即pattern[j],然后发现pattern[j]与回溯前的pattern[j+1]一致,这就是重复比较。在这种情况下,模式串指针要经过j次重复比较才能回溯到指定位置pattern[0]。
举个例子:
master="aaabaaabaaaab"、pattern="aaaab":
- 按next数组的求解过程,得next={-1,0,1,2,3,0}
- 按KMP匹配过程,当pattern[3]!=master[3]时,要令j=next[j]=next[3]=2,然后比较pattern[2]和master[3]。而pattern[2]!=master[3],故又要令j=next[j]=next[2]=1,然后比较pattern[1]和master[3]。而pattern[1]!=master[3],故又要令j=next[j]=next[1]=0,然后比较pattern[0]和master[3]。然后i++,比较pattern[0]和master[4]......
在这种情况下,模式串指针j并未在O(1)内回溯到指定位置pattern[0]。
改进:
由上述分析可知,每当求得一个字符的next值时,我们只需要判断它与它前面串中的所有字符是否都相等,如果是则直接重置它的next值为0即可,这样可以使它在失配时直接回溯到指定位置pattern[0]。体现在代码中,也就是每当我们求得next[j+1]=k+1时,需要进一步判断next[j+1]==j && pattern[j+1]=pattern[j]是否成立,若成立则需令next[j+1]=0。
改进后的getNext()如下:
static std::vector<int> KMP::getNext(const string &pattern){
std::vector<int> next(pattern.size()+1);
next[0]=-1;// pattern[0]前面没有串
int j=1,k=next[j];
while(j<pattern.size()){
if(k==-1 || pattern[j]==pattern[k]){
next[j+1]=k+1;
// 改进
if(next[j+1]==j && pattern[j+1]==pattern[j]){
next[j+1]=0;
}
j++;
k++;
}else{
k=next[k];// 转去比较pattern[j]和pattern[next[k]]
}
}
return next;
}4.总结
- 虽然BF的时间复杂度T(n)=O(master.size()*pattern.size()),但在一般情况下,其实际执行时间近似于O(master.size()+pattern.size()),因此至今仍被采用
- KMP可以在T(n)=O(master.size()+pattern.size())内完成串匹配,这是以额外的空间S(n)=O(pattern.size()+1)为代价的
- KMP与BF的区别仅在于失配时的策略上,故仅当模式串与主串之间存在许多“部分匹配”的情况下才显得KMP比BF快。在“部分匹配”几乎不存在的情况下,BF的整体性能要优于KMP(两者时间开销近似,但空间开销差距大)
- KMP的最大特点是主串指针不需回溯,这对处理从外设输入的庞大文件很有效,可以一边输入一边匹配