什么是网页抓取?
网络爬虫也称为网络收集和网络数据收集。它指的是以程序方式读取和分析互联网上的内容的过程。网络爬取通常包括以下三个主要步骤:
数据挖掘:数据挖掘涉及查找数据源并将数据从该源拉取到用户可以操纵它的环境中,例如独立开发环境(IDE)。
数据解析:数据解析涉及读取并过滤数据以获取有价值的部分。可以将其想象为通过筛子筛选金子。
数据输出:数据输出涉及将获取的数据从IDE导出并应用于用户想要的任何用途。
网络爬虫通常指的是从HTML代码中提取、解析和输出数据。网页通常由HTML、CSS和JavaScript代码的组合组成。浏览器使这些元素变得可读。通过右键单击并检查页面,用户可以看到浏览器中哪些页面元素对应于HTML代码的哪些行。这对于了解应该进行爬取的内容很有帮助。
网络爬虫的案例
在各行业中,网络爬虫有许多常见的用例,包括以下几种:
价格监控和比较
零售商和电子商务企业会爬取竞争对手网站,以监控和比较价格。
股市分析
金融分析师会爬取股市网站,收集有关股票价格、公司新闻和财务报表的数据,以进行分析和预测。
房地产列表
房地产公司会爬取房地产网站,收集有关房地产列表、价格和市场趋势的数据。
招聘板监控
招聘机构和人力资源部门会爬取招聘板,查找符合特定标准的新工作列表。
新闻和内容聚合
媒体公司和新闻聚合器会爬取各种新闻站点,收集和策划内容供其平台使用。
潜在客户生成
企业会爬取网站以收集潜在客户的联系信息,例如电子邮件地址和电话号码。
研究和学术界
研究人员会爬取网站以收集用于学术研究、市场研究和其他分析目的的数据。
新闻业
记者会爬取网络以获取信息并验证事实以支持其报道。
旅游和酒店业
旅行社和聚合器会爬取航空公司、酒店和其他与旅行有关的网站,收集有关航班时间表、房间可用性和价格的数据。
社交媒体营销
品牌和营销人员会爬取社交媒体平台,以监控对其品牌的提及、跟踪情绪并获取有关客户喜好的见解。
SEO
SEO专业人员会爬取搜索引擎结果页面,以监控关键词排名并分析竞争对手的SEO策略。
事件监控
公司会爬取事件网站,以获取有关其行业中即将发生的事件、会议和研讨会的数据。
产品情感
电子商务企业会爬取产品评论网站,监控有关其产品的客户反馈和情感。
数据集成
开发人员会爬取网站以将这些网站的数据集成到其应用程序中。这是为人工智能和大型语言模型积累培训数据的方式。
体育统计
体育分析师和爱好者会爬取网站,以收集有关球员统计、比赛结果和球队表现的数据。

抓取网站的方法
爬取网站的方法有很多,需要不同程度的编码能力。
不需要编码的爬取方法包括以下几种:
手动复制粘贴
从网站手动复制数据并进行分析是最直接的爬取数据的方式。
浏览器开发工具
浏览器有许多内置工具,可以检查和提取网站元素。其中一个例子是检查功能,它显示网站的底层源代码。
浏览器扩展
可以将浏览器扩展添加到浏览器中,以执行特定的、基于模式的网页爬取。
RSS订阅
一些网站提供结构化数据的列表,以RSS订阅的形式呈现。
数据挖掘软件
诸如KNIME和RapidMiner之类的软件提供全面的数据科学和分析功能,其中包括网页爬取。
需要一些编码的爬取方法包括以下几种:
Beautiful Soup
Python的Beautiful Soup库是学习爬取的良好资源。它需要最少的编码知识,适用于一次性的HTML爬取项目。
API
许多网站提供结构化的API,允许用户进行数据爬取。使用API通常需要对数据格式(如JSON和XML)有基本的了解,以及对HTTP请求有基本的理解。
Scrapy
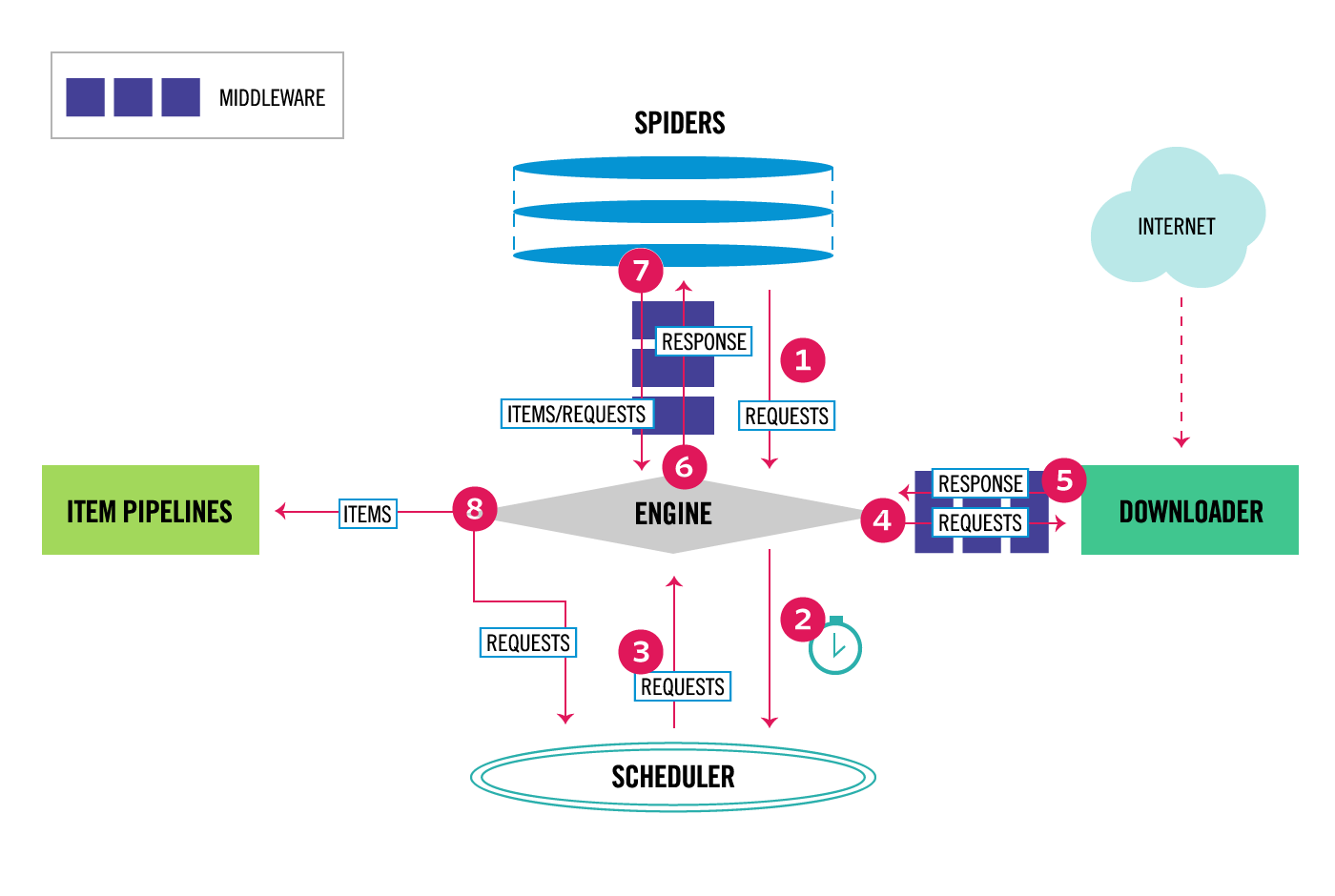
Python的Scrapy库可以用于更复杂的网页爬取任务。Scrapy功能强大,但对于新用户来说可能有一些难度。
JavaScript
在Node.js中使用Axios JavaScript库进行HTTP请求,使用Cheerio库进行HTML解析。
网页爬取框架
高级框架,如Apache Nutch,可以在大规模上实现网页爬取。