深度学习系列-python实现-初步学习构建神经网络
前言
在数字时代,数据已经成为了一种无处不在的资源。从商业分析到科学研究,从人工智能到机器学习,数据驱动的决策和预测已经成为了各行各业不可或缺的一部分。而在这一切的背后,神经网络和深度学习技术发挥着至关重要的作用。
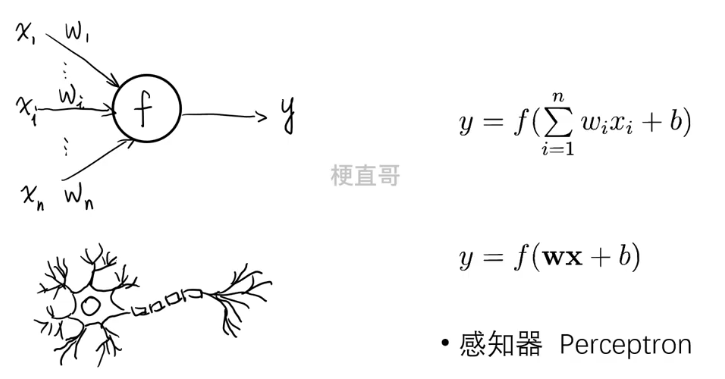
深度学习神经网络,是模拟人脑神经元连接和工作方式的一种计算模型。它们通过训练大量数据来学习和优化自身,从而能够处理复杂的模式和进行精确的预测。近年来,随着计算能力的提升和大数据的普及,深度学习已经在语音识别、图像识别、自然语言处理等领域取得了显著的突破。
Python,作为一种简洁、易读且功能强大的编程语言,已经成为深度学习领域的首选工具。它有着丰富的库和框架支持,如TensorFlow、PyTorch等,这些工具为神经网络的构建、训练和部署提供了极大的便利。
本系列博客旨在通过Python实现深度学习神经网络,帮助初学者从零开始,逐步掌握神经网络的基本原理和构建方法,通过实际的代码实现和案例分析来加深理解。
在本系列博客中,将遵循以下原则:
- 理论与实践相结合:不仅会讲解神经网络的理论知识,还会通过Python代码来实现这些模型,让读者能够在实践中加深理解。
- 循序渐进:将从简单的模型开始,逐步引入更复杂的模型和技术,让读者能够逐步掌握深度学习的核心知识和技能。
- 注重实用性:将通过真实的案例和数据集来演示神经网络的应用,让读者能够了解如何在实际问题中使用神经网络。
无论你是对深度学习感兴趣的初学者,还是希望提升自己在神经网络方面的技能的开发者,本系列博客都将为你提供有价值的参考和学习资源。
这里先做简单的例子让大家熟悉模型训练的步骤。
1.在Keras中加载MNIST数据集
深度学习模型的训练离不开数据的准备,特别是训练数据和测试数据的准备。以下是一个关于如何准备深度学习训练数据和测试数据的详细步骤:
一、数据收集
首先,需要收集与任务相关的数据。数据可以来源于各种渠道,如网络爬虫、公开数据集、自有数据库等。在收集数据时,需要确保数据的多样性和丰富性,以便模型能够学习到更多的特征和模式。
二、数据清洗与预处理
收集到的原始数据往往需要进行清洗和预处理,以提高数据的质量和可用性。这包括去除重复数据、处理缺失值、异常值、噪声等。同时,可能还需要对数据进行标准化、归一化等操作,以便于模型的训练。
三、数据标注
对于监督学习任务,需要对数据进行标注。标注是指为数据添加标签,以便模型能够学习到输入与输出之间的关系。标注的方式可以根据任务类型来选择,如分类任务可以使用类别标签,回归任务可以使用数值标签等。
四、划分训练集和测试集
将清洗和标注后的数据划分为训练集和测试集。训练集用于训练模型,使模型能够学习到数据的特征和规律;测试集用于评估模型的性能,即模型在未见过的数据上的表现。通常,训练集的比例会大于测试集,例如80%的数据用于训练,20%的数据用于测试。
五、数据增强
在某些情况下,为了增加模型的泛化能力,可以使用数据增强技术来扩充训练集。数据增强通过对原始数据进行变换(如旋转、裁剪、缩放等)来生成新的训练样本,从而增加模型的鲁棒性。
六、创建数据加载器
为了方便在训练过程中加载数据,可以创建数据加载器(DataLoader)。数据加载器可以自动将数据划分为批次(batch),并在训练过程中按批次加载数据。这有助于减少内存占用,提高训练效率。
通过以上步骤,可以准备好深度学习所需的训练数据和测试数据。在实际应用中,还需要根据具体的任务和数据特点进行相应的调整和优化。同时,随着技术的不断发展,新的数据处理和增强技术也会不断涌现,为深度学习的应用提供更多可能性。
本次实验中,在Keras中加载MNIST数据集,是一个相对简单的过程,因为Keras内置了MNIST数据集的加载功能。MNIST是一个大型的手写数字数据库,常用于训练和测试图像处理系统。以下是如何在Keras中加载MNIST数据集的步骤:
首先,需要确保你已经安装了TensorFlow和Keras。可以使用pip来安装它们:pip install tensorflow
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
#准备训练数据和测试数据
#每个图像都是一个28x28的NumPy数组,像素值介于0和255之间。
#标签是一个整数数组,表示每个图像中的数字(0到9)。
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
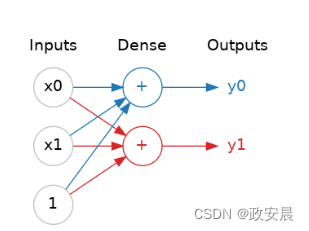
2.构建简单的神经网络模型
在这个示例中,创建了一个Sequential模型,这是一个线性堆叠层的模型。添加了一个具有128个神经元和ReLU激活函数的Dense(全连接)层作为隐藏层。添加了一个softmax激活函数的Dense层作为输出层,它有10个神经元,对应10个不同的数字类别。
在编译模型时,使用了rmsprop优化器和SparseCategoricalCrossentropy损失函数,还指定了监控指标:准确率。
from tensorflow import keras
from tensorflow.keras import layers
#Sequential通过堆叠许多层,构建出深度神经网络。
model = keras.Sequential([
#添加了一个具有512个神经元和ReLU激活函数的Dense(全连接)层作为隐藏层。
layers.Dense(512, activation="relu"),
#添加了一个Dense层作为输出层,它有10个神经元,对应10个不同的数字类别,使用softmax激活函数。
layers.Dense(10, activation="softmax")
])
#编译模型
model.compile(optimizer="rmsprop",#定义优化器
loss="sparse_categorical_crossentropy",#定义损失函数
metrics=["accuracy"]) #准确率指标
3.训练模型
在Keras中训练模型涉及使用模型的fit方法,该方法将迭代训练数据集多次(即“epochs”),并在每次迭代中使用指定数量的样本(即“batch_size”)来更新模型的权重。以下是如何使用Keras的fit方法来训练一个简单的神经网络模型的步骤:
model.fit(train_images, train_labels, epochs=5, batch_size=128)

在上面的代码中,model.fit方法接收以下参数:
- train_images 和 train_labels:训练数据和对应的标签。
- epochs:整数,指定整个数据集将被遍历的次数。每个epoch表示模型已经看到了整个数据集一次。
- batch_size:整数,指定用于梯度下降的每个批次中的样本数。
fit方法返回一个History对象,该对象包含训练过程中的损失和评估指标的值。通过访问history.history字典,你可以获取每个epoch的损失和指标值。
在训练过程中,Keras会显示每个epoch结束时的损失和准确率。如果你设置了validation_data,它还会显示验证集上的损失和准确率。这些信息可以帮助你监控模型的训练过程,并决定是否需要调整模型的参数或结构。
4.模型的预测和评估
一旦你训练好了一个神经网络模型,你可以使用它来对新的数据进行预测,并评估它在测试集上的性能。以下是如何使用Keras中的模型进行预测和评估的步骤。
应用模型进行预测:
test_digits = test_images[0:10]
predictions = model.predict(test_digits)
predictions[0]

# 将预测结果转换为类别标签
predictions[0].argmax() #7
模型评估
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"test_acc: {test_acc}")
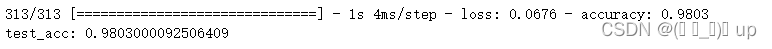
在上面的代码中,model.predict方法用于对测试集数据进行预测。它返回的是一个NumPy数组,其中包含了模型对每个样本的预测结果。这些预测结果是模型的输出层(logits)的原始值,因此需要使用np.argmax函数来找到每个样本预测概率最高的类别索引,从而得到最终的类别标签。
model.evaluate方法用于评估模型在测试集上的性能。它返回测试损失和准确率。损失是一个衡量模型预测与真实标签之间差距的指标,而准确率则是正确分类的样本比例。
请注意,预测和评估通常是在模型训练完成后进行的,确保你使用的是训练好的模型权重。如果你在训练过程中使用了回调函数来保存最佳模型,你可能需要加载这个最佳模型来进行预测和评估。
5.总结
在这个过程中,学习了神经网络的基本概念和原理,还通过实际的代码实现和案例分析,加深了对这些知识的理解。学会了如何准备数据、设计网络结构、选择优化算法、以及评估模型的性能。