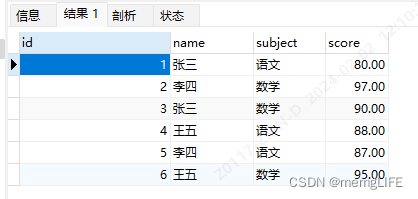
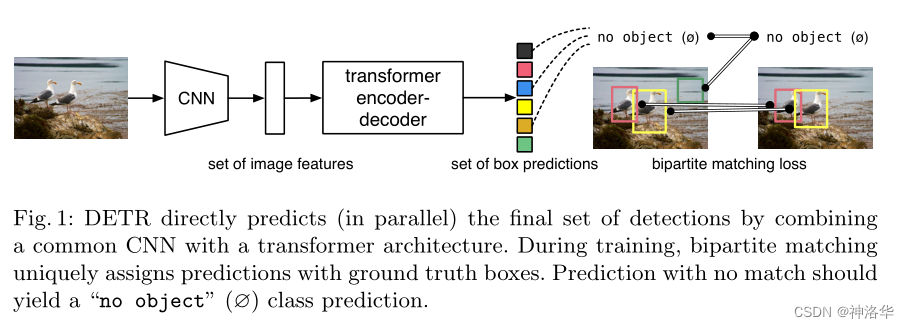
一、数据列转行
import pandas as pd # 导入 pandas 库
def pivot_excel_data(input_file, output_file):
"""
将 Excel 文件中的数据行转换为列,并保存为新的 Excel 文件
Parameters:
input_file (str): 输入的 Excel 文件路径
output_file (str): 输出的 Excel 文件路径
Returns:
None
"""
# 读取 Excel 数据
df = pd.read_excel(input_file, sheet_name='Sheet1')
# 使用 pivot_table() 函数将数据行转换为列
df_pivot = df.pivot_table(index='店铺', columns='新费用类型', values='金额').reset_index()
# 将处理后的数据保存到新的 Excel 文件
df_pivot.to_excel(output_file, index=False)
# 调用函数进行数据处理
input_file = 'C:\\Users\\Administrator\\Desktop\\新数据_处理后.xlsx'
output_file = 'converted_data.xlsx'
pivot_excel_data(input_file, output_file)
二、数据行转列
import pandas as pd # 导入 pandas 库
def melt_excel_data(input_file, output_file):
"""
将 Excel 文件中的数据列转换为行,并保存为新的 Excel 文件
Parameters:
input_file (str): 输入的 Excel 文件路径
output_file (str): 输出的 Excel 文件路径
Returns:
None
"""
# 读取 Excel 数据
df = pd.read_excel(input_file, sheet_name='Sheet1')
# 使用 melt() 函数将数据列转换为行
df_melted = df.melt(id_vars=['店铺'], var_name='费用类型', value_name='金额')
# 将处理后的数据保存到新的 Excel 文件
df_melted.to_excel(output_file, index=False)
# 调用函数进行数据处理
input_file = 'C:\\Users\\Administrator\\Desktop\\converted_data.xlsx'
output_file = 'converted_data2.xlsx'
melt_excel_data(input_file, output_file)