在大数据处理和分析领域,ClickHouse以其卓越的性能和高效的查询能力而备受瞩目。许多企业和开发者选择ClickHouse作为其数据处理的核心引擎,主要源于其出色的查询速度和数据处理能力。那么,ClickHouse为何能够如此快速地处理数据呢?本文将从多个方面解析其快速背后的原因。
1. 列式存储引擎
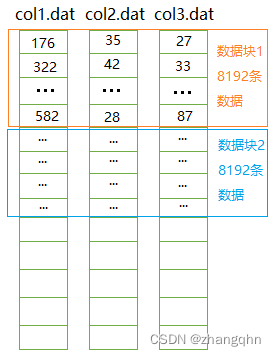
ClickHouse采用列式存储引擎,这是其高效性能的关键所在。与传统的行式存储不同,列式存储将同一列的数据存储在一起,这种设计使得数据读取和查询更加高效。在查询过程中,系统只需扫描查询涉及的列,而无需读取整行数据,从而大大减少了I/O操作,提高了查询速度。
2. 向量化执行引擎
ClickHouse采用了向量化执行引擎,这也是其高效性能的重要原因。向量化执行引擎能够将多个操作合并成单个向量操作,减少了函数调用和内存分配的次数,从而提高了执行效率。此外,向量化执行还使得数据在内存中的布局更加紧凑,减少了缓存未命中的概率,进一步提升了性能。
3. 数据压缩与编码
ClickHouse支持多种数据压缩和编码算法,这些算法能够有效地减少数据的存储空间并提高查询性能。通过选择合适的压缩和编码策略,ClickHouse能够在保证数据准确性的同时,减少数据的存储空间和I/O操作,从而加速查询过程。
4. 多线程与分布式处理
ClickHouse充分利用了现代计算机的多核特性,实现了多线程处理。这使得在查询过程中,多个核心可以同时工作,提高了整体的处理速度。此外,ClickHouse还支持分布式处理,能够将查询任务拆分成多个子任务并在多个节点上并行执行,进一步提高了处理速度。
5. 优化器与索引
ClickHouse内置了强大的查询优化器,能够自动对查询进行优化,选择最优的执行计划。此外,ClickHouse还支持多种索引类型,能够加速数据的查找和过滤过程。这些优化措施使得ClickHouse在面对复杂查询时仍能保持高效的性能。


















![[NSSRound#8 Basic]MyPage](https://img-blog.csdnimg.cn/direct/521abcd9449b4a5bb2c182daaec11764.png)