RoBERTa是BERT的另一个有趣且流行的变体。研究人员发现,BERT的训练远未收敛,所以他们提出了几种对BERT模型预训练的方法。RoBERTa本质上是BERT,它只是在预训练中有以下变化。
- 在掩码语言模型构建任务中使用动态掩码而不是静态掩码。
- 不执行下句预测任务,只用掩码语言模型构建任务进行训练。
- 以大批量的方式进行训练。
- 使用字节级字节对编码作为子词词元化算法。
1 使用动态掩码而不是静态掩码
我们已经知道要使用掩码语言模型构建任务和下句预测任务对BERT模型进行预训练。在掩码语言模型构建任务中,我们随机掩盖15%的标记,让网络预测被掩盖的标记。
我们以句子We arrived at the airport in time为例,在添加标记[CLS]和[SEP]后,我们得到如下标记列表。
tokens = [ [CLS], we, arrived, at, the, airport, in, time, [SEP] ]
然后,随机掩盖15%的标记。
tokens = [ [CLS], we, [MASK], at, the, airport, in, [MASK], [SEP] ]
现在,将这些标记送入BERT,并训练它预测被掩盖的标记。注意,在预处理阶段,我们只做了一次掩码处理,且在多次迭代训练中预测相同的掩码标记,这被称为静态掩码。而RoBERTa使用的是动态掩码。让我们通过一个例子来了解动态掩码的工作原理。
首先,我们将一个句子复制10份。假设例句仍为We arrived at the airport in time,我们将其复制10份。然后,随机掩盖这10个句子中的15%的标记,并且每个句子中都有不同的标记被掩盖,如图所示。

我们对该模型进行40轮全数据遍历训练。在每次训练中,句子中被掩盖的标记都不同。对于第一轮全数据遍历,句子1被送入模型;对于第二轮全数据遍历,句子2被送入模型,以此类推,如图所示。
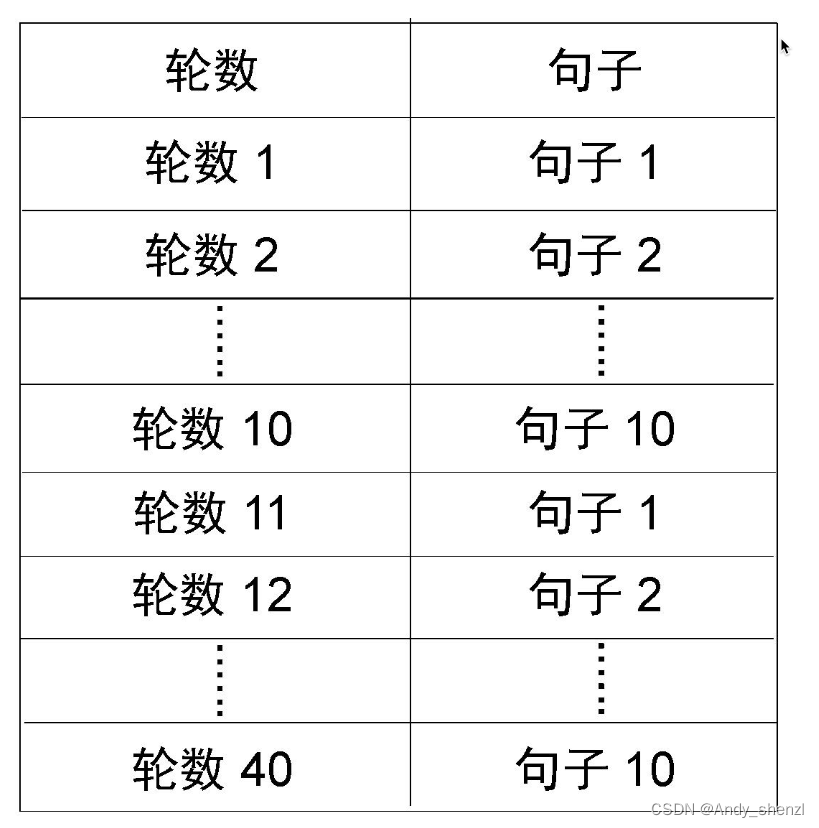
具有相同掩码标记的句子会出现在4轮中。例如,句子1出现在轮数1、轮数11、轮数21和轮数31中,句子2出现在轮数2、轮数12、轮数22和轮数32中。通过这种方式,我们使用了动态掩码而不是静态掩码来训练RoBERTa模型。
2 移除下句预测任务
研究人员发现,下句预测任务对于预训练BERT模型并不是真的有用,因此只需用掩码语言模型构建任务对RoBERTa模型进行预训练。为了更好地理解移除下句预测任务的重要性,我们将进行以下实验。
- 片段对+下句预测:在这种情况下,用下句预测任务训练BERT模型。这类似于训练标准BERT模型的方式,输入由少于512个标记的片段对组成。
- 句子对+下句预测:同样用下句预测任务来训练BERT模型,输入由一个句子对组成。这个句子对可以从一个文件的连续部分采样,也可以从不同的文件中采样,且输入的标记少于512个。
- 完整句:这个实验是在没有下句预测任务的情况下训练BERT模型。输入是一个完整的句子,从一个或多个文件中连续采样而得。输入最多由512个标记组成。如果输入到达一个文件的末尾,那么就从下一个文件开始采样。
- 文档句:同样是在没有下句预测任务的情况下训练BERT模型。它与完整句类似,输入也是由一个完整的句子组成的,但只从一个文件中采样。也就是说,如果输入到达一个文件的末尾,就不会从下一个文件中采样。
研究人员使用以上4个实验预训练了BERT模型,并在多个数据集上评估了该模型,数据集包括SQuAD、MNLI-m、SST-2和RACE。下图显示了BERT模型在SQuAD数据集上的F1分数以及在MNLI-m、SST-2和RACE上的准确度分数。
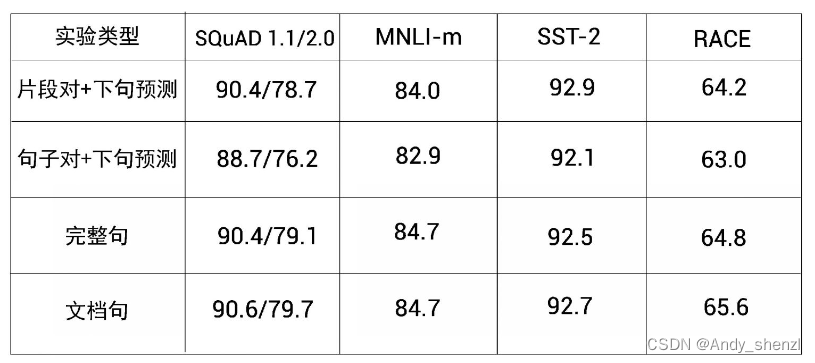
结果来自论文“RoBERTa: A Robustly Optimized BERT Pretraining Approach”。
BERT在完整句和文档句中的性能更好,而在这两个实验中,都没有执行下句预测任务。
在文档句中,只从单一文件中采样,这比在完整句中从不同文件中采样的性能要好。但在RoBERTa中,因为文档句中的批量大小不同,所以使用了完整句的采样方法。
我们小结一下,在RoBERTa中,我们只用掩码语言模型构建任务来训练模型。输入是一个完整的句子,它是从一个或多个文件中连续采样而得的。输入最多由512个标记组成。如果输入到达一个文件的末尾,那么就从下一个文件开始采样。
3 用更多的数据集进行训练
我们用多伦多图书语料库和英语维基百科数据集对BERT进行预训练,这两个数据集的大小共有16 GB。除了这两个数据集,还可以使用CC-News(Common Crawl-News)、Open WebText和Stories(Common Crawl的子集)对RoBERTa进行预训练。
因此,RoBERTa模型共使用5个数据集进行预训练。这5个数据集的大小之和为160GB。
4 以大批量的方式进行训练
我们知道,BERT的预训练有100万步,批量大小为256。而RoBERTa将采用更大的批量进行预训练,即批量大小为8000,共30万步。它还可以用同样的批量大小进行更长时间的预训练,比如50万步。
但为什么要增加批量大小?用大批量训练的优势是什么?答案是用较大的批量进行训练可以提高模型的速度和性能。
5 使用字节级字节对编码作为子词词元化算法
我们知道BERT使用WordPiece作为子词词元化算法,也知道WordPiece的工作原理与字节对编码类似,它根据相似度而不是出现频率来合并符号对。但是,与BERT不同,RoBERTa使用字节级字节对编码作为子词词元化算法。
在前面,我们已经学习了字节级字节对编码的工作原理。字节级字节对编码的工作原理与字节对编码非常相似,但它不是使用字符序列,而是使用字节级序列。BERT使用的词表有30000个标记,而RoBERTa使用的词表有50000个标记。下面,让我们进一步了解RoBERTa词元分析器。
5.1 探索RoBERTa词元分析器
首先,导入必要的库模块。
from transformers import RobertaConfig, RobertaModel, RobertaTokenizer
然后,下载并加载预训练的RoBERTa模型。
model = RobertaModel.from_pretrained('roberta-base')
接着,检查一下RoBERTa模型的配置。我们从输出结果中可以看到,在加载的RoBERTa-base模型中,有12层编码器、12个注意力头和768个隐藏神经元,如下所示。
model.config
RobertaConfig {
"_name_or_path": "roberta-base",
"architectures": [
"RobertaForMaskedLM"
],
"attention_probs_dropout_prob":0.1,
"bos_token_id":0,
"eos_token_id":2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob":0.1,
"hidden_size":768,
"initializer_range":0.02,
"intermediate_size":3072,
"layer_norm_eps":1e-05,
"max_position_embeddings":514,
"model_type": "roberta",
"num_attention_heads":12,
"num_hidden_layers":12,
"pad_token_id":1,
"type_vocab_size":1,
"vocab_size":50265
}
下载并加载RoBERTa词元分析器。
tokenizer = RobertaTokenizer.from_pretrained("roberta-base")
以句子It was a great day为例,使用RoBERTa模型对其进行标记。
tokenizer.tokenize('It was a great day')
以上代码的输出如下。
['It', 'Ġwas', 'Ġa', 'Ġgreat', 'Ġday']
可以看到,以上序列为句子的标记,但那个Ġ字符是什么?它用来表示一个空格。RoBERTa词元分析器将所有空格替换为Ġ字符。除了第一个标记外,Ġ出现在所有标记之前,这是因为在句子中,除了第一个标记之前没有空格,其他标记之前都有空格。假设对同一句进行标记,在句子的第一个单词前面添加空格,如下所示。
tokenizer.tokenize(' It was a great day')
['ĠIt', 'Ġwas', 'Ġa', 'Ġgreat', 'Ġday']
可以看到,由于在第一个标记的前面添加了一个空格,因此现在所有的标记前面都有Ġ字符。
我们再看一个例句,假设对句子I had a sudden epiphany进行标记。
tokenizer.tokenize('I had a sudden epiphany')
以上代码的输出如下。
['I', 'Ġhad', 'Ġa', 'Ġsudden', 'Ġep', 'iphany']
因为epiphany不存在于词表中,所以它被分割成子词ep和iphany。我们也可以看到空格被替换成了Ġ字符。
小结一下,RoBERTa是BERT的一个变体,它只使用掩码语言模型构建任务进行预训练。与BERT不同的是,它使用了动态掩码而不是静态掩码,而且使用大批量进行训练。它使用字节级字节对编码作为子词词元化算法,词表大小为50000。