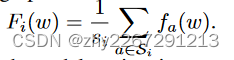学习目标:
- 联邦学习概述,让你了解联邦学习
学习内容:
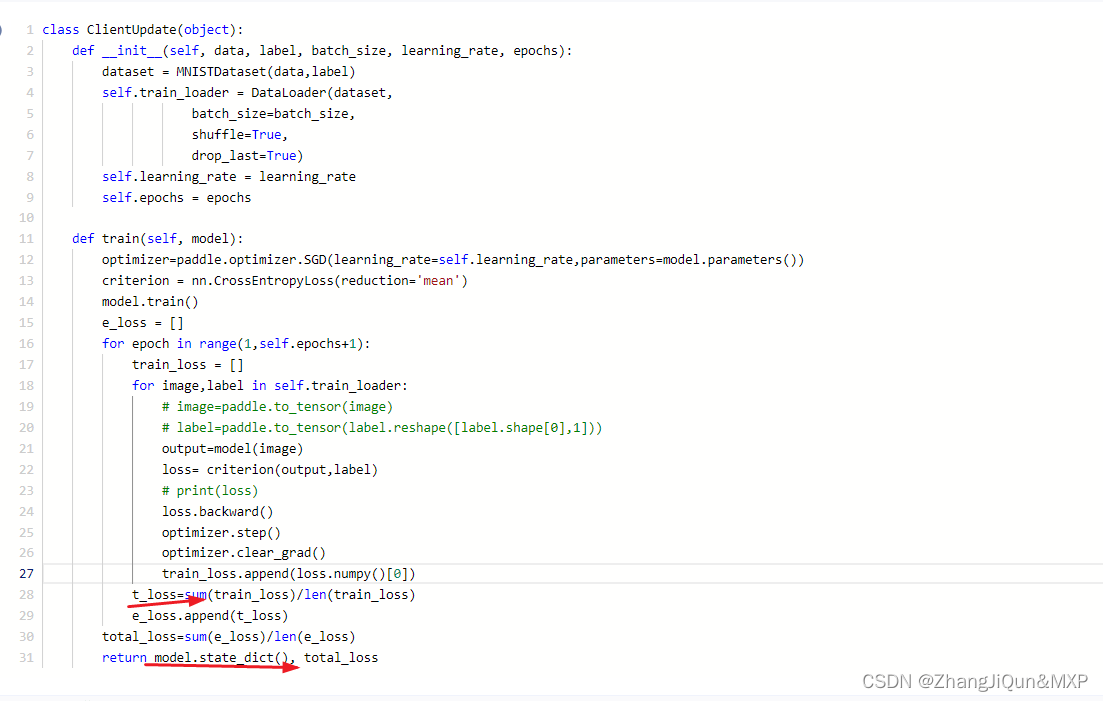
联邦学习是一种机器学习范式,它允许多个设备或服务器协同训练一个共享的模型,同时保持各自数据的隐私。这种方法特别适用于数据分散在多个设备上且难以集中处理的情况,如移动设备上的用户数据。
联邦学习的核心概念
- 数据隐私:参与者的数据不离开其设备,只有模型参数或更新信息在网络中传输。
- 模型共享:所有参与者共同训练一个全局模型,而不是各自训练独立的模型。
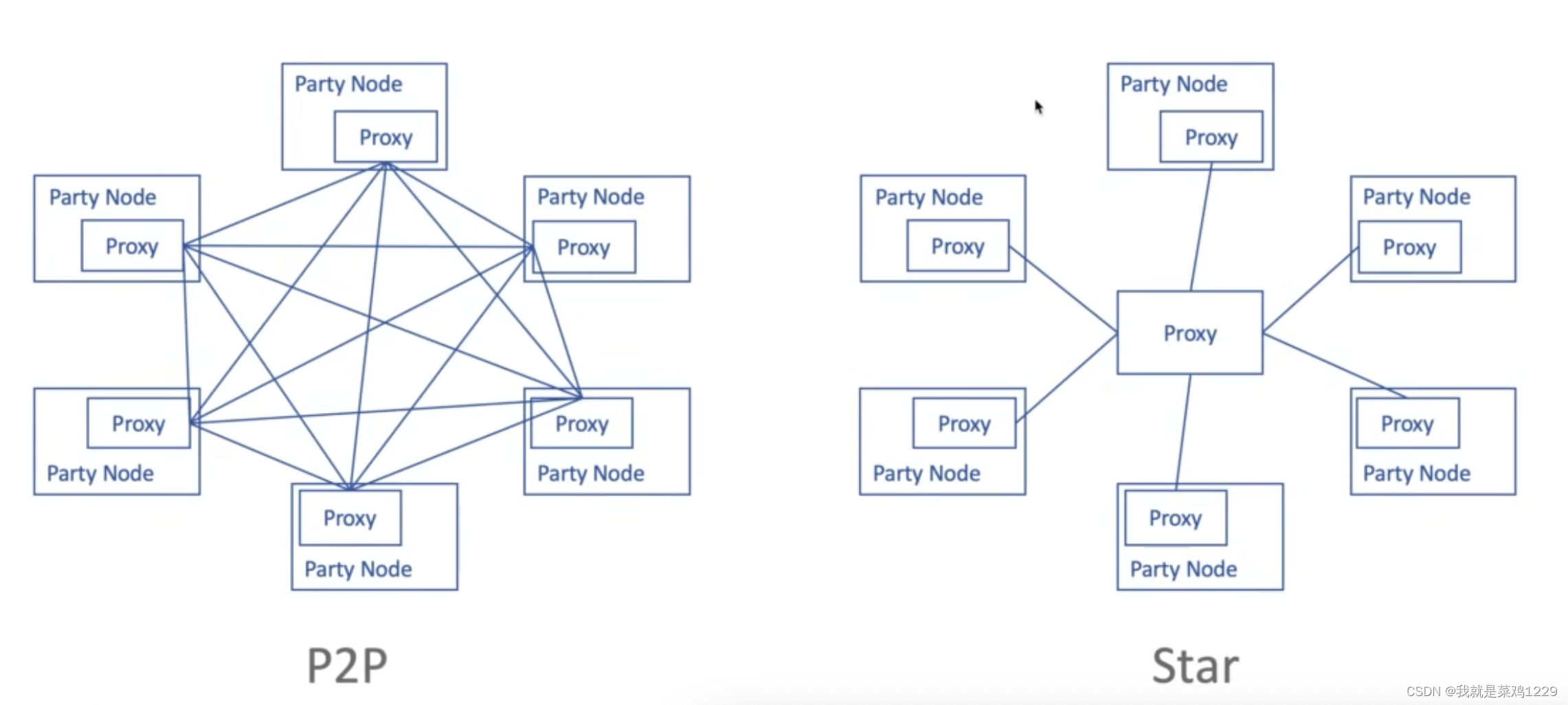
- 通信效率:通过仅交换必要的模型信息,减少了数据传输量,提高了通信效率。
联邦学习的主要类型
- 横向联邦学习:适用于数据特征相同但样本不同的情况,如不同地区的医院共同训练一个疾病诊断模型。
- 纵向联邦学习:适用于数据特征不同但样本相同的情况,如不同公司共同训练一个信用评分模型。
- 迁移联邦学习:结合了迁移学习的概念,适用于数据特征和样本都不完全相同的情况。
联邦学习的应用场景
- 移动设备:智能手机应用可以在本地更新推荐系统或语音识别模型,而不需要上传用户数据。
- 医疗健康:医院可以在保护患者隐私的前提下,共同训练更准确的诊断模型。
- 金融服务:银行可以合作开发反欺诈或信用评估模型,同时保护客户的财务数据。
联邦学习的挑战
- 数据异构性:不同参与者的数据可能具有不同的分布,这可能会影响模型的性能。
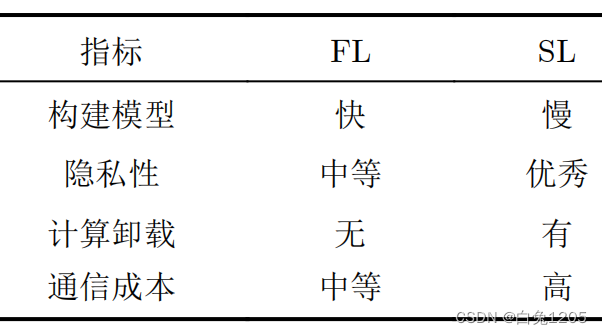
- 通信成本:虽然联邦学习减少了数据传输,但模型更新的传输仍可能导致较高的通信成本。
- 安全性和隐私:需要确保在模型训练过程中不会泄露敏感信息。
联邦学习是解决数据孤岛问题、保护数据隐私的有效方法,它在多个领域展现出巨大的潜力。