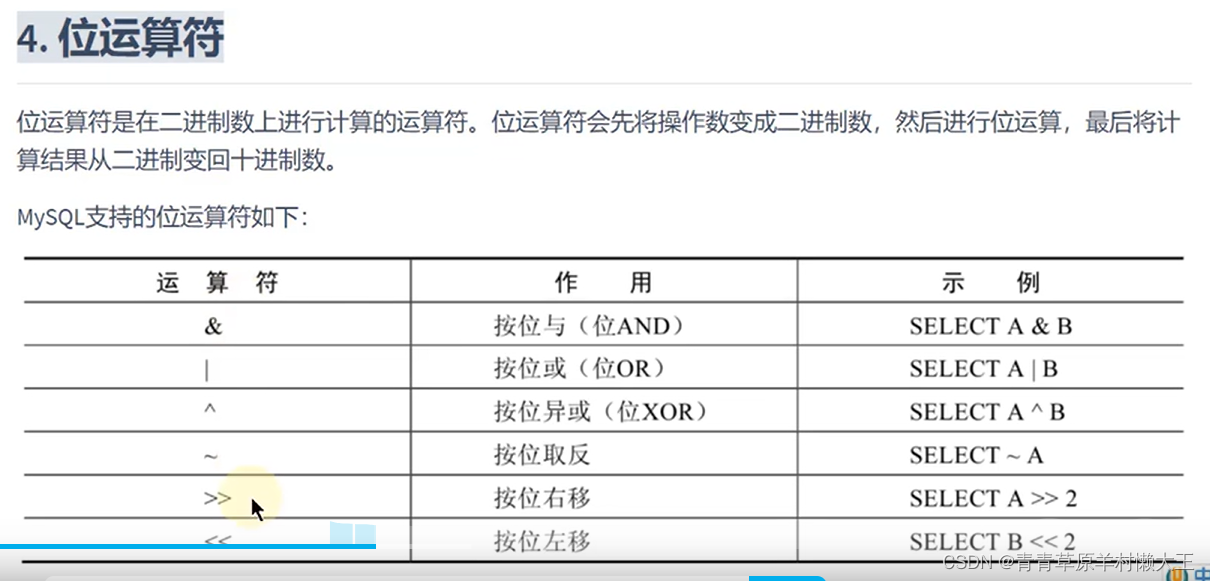
CentLoss实现
前言
参考文章:史上最全MNIST系列(三)——Centerloss在MNIST上的Pytorch实现(可视化)
源码:Gitee或Github都有上传,保留了最优版,对最优版调整了一些参数看效果
Gitee传送门:点击这里跳转Gitee源码库
Github传送门:点击这里跳转Github源码库
--------------------无---------------情---------------分---------------割---------------线--------------------
贴心省流:最优效果见文末的v5版
v1
一开始实现的效果还行,但!是!
我忘记参数了(0.0!!)
于是,开始了漫长的尝试。。。
效果

v2
网络结构
self.hidden_layer = nn.Sequential(
ConvLayer(1, 32, 3, 1, 1),
ConvLayer(32, 32, 3, 1, 1),
nn.MaxPool2d(2),
ConvLayer(32, 64, 3, 1, 1),
ConvLayer(64, 64, 3, 1, 1),
nn.MaxPool2d(2),
ConvLayer(64, 128, 3, 1, 1),
ConvLayer(128, 128, 3, 1, 1),
nn.MaxPool2d(2)
)
self.fc = nn.Sequential(
nn.Linear(128 * 3 * 3, 12)
)
批次和学习率
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=512)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 30, gamma=0.9)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.01, momentum=0.9)
效果

结论
分类效果不明显
v2_2
v2基础上仅修改了网络结构
网络结构
self.hidden_layer = nn.Sequential(
ConvLayer(1, 32, 3, 1, 1),
ConvLayer(32, 32, 3, 1, 1),
nn.MaxPool2d(2),
ConvLayer(32, 64, 3, 1, 1),
ConvLayer(64, 64, 3, 1, 1),
nn.MaxPool2d(2),
ConvLayer(64, 128, 3, 1, 1),
ConvLayer(128, 128, 3, 1, 1),
nn.MaxPool2d(2)
)
self.fc = nn.Sequential(
nn.Linear(128 * 3 * 3, 2)
)
self.output_layer = nn.Sequential(
nn.Linear(2, 10)
)
批次和学习率
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=512)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 30, gamma=0.9)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.01, momentum=0.9)
效果

结论
输出12–>2+10,分类效果明确,但未完全分开
v2_3
v2_2基础上仅修改了学习率
网络结构
self.hidden_layer = nn.Sequential(
ConvLayer(1, 32, 3, 1, 1),
ConvLayer(32, 32, 3, 1, 1),
nn.MaxPool2d(2),
ConvLayer(32, 64, 3, 1, 1),
ConvLayer(64, 64, 3, 1, 1),
nn.MaxPool2d(2),
ConvLayer(64, 128, 3, 1, 1),
ConvLayer(128, 128, 3, 1, 1),
nn.MaxPool2d(2)
)
self.fc = nn.Sequential(
nn.Linear(128 * 3 * 3, 2)
)
self.output_layer = nn.Sequential(
nn.Linear(2, 10)
)
批次和学习率
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=512)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.8)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 30, gamma=0.8)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.01, momentum=0.8)
效果

结论
动量0.9–>0.8,分类效果不明显
v2_4
v2_2基础上仅修改了学习率
网络输出:2+10
self.hidden_layer = nn.Sequential(
ConvLayer(1, 32, 3, 1, 1),
ConvLayer(32, 32, 3, 1, 1),
nn.MaxPool2d(2),
ConvLayer(32, 64, 3, 1, 1),
ConvLayer(64, 64, 3, 1, 1),
nn.MaxPool2d(2),
ConvLayer(64, 128, 3, 1, 1),
ConvLayer(128, 128, 3, 1, 1),
nn.MaxPool2d(2)
)
self.fc = nn.Sequential(
nn.Linear(128 * 3 * 3, 2)
)
self.output_layer = nn.Sequential(
nn.Linear(2, 10)
)
批次和学习率
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=512)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 30, gamma=0.9)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.5, momentum=0.9)
效果

结论
center_loss学习率0.01–>0.5,分类效果不明显
v3
网络结构
self.hidden_layer = nn.Sequential(
ConvLayer(1, 32, 5, 1, 1),
ConvLayer(32, 32, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(32, 64, 5, 1, 1),
ConvLayer(64, 64, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(64, 128, 5, 1, 1),
ConvLayer(128, 128, 5, 1, 2),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(128, 12)
)
批次和学习率
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=1024)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.002, momentum=0.8)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 20, gamma=0.8)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.7)
效果

v3_2
v3基础上修改学习率
网络结构
class MainNet(nn.Module):
def __init__(self):
super().__init__()
self.hidden_layer = nn.Sequential(
ConvLayer(1, 32, 5, 1, 1),
ConvLayer(32, 32, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(32, 64, 5, 1, 1),
ConvLayer(64, 64, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(64, 128, 5, 1, 1),
ConvLayer(128, 128, 5, 1, 2),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(128, 12)
)
# self.output_layer = nn.Sequential(
# nn.Linear(2, 10)
# )
def forward(self, _x):
h_out = self.hidden_layer(_x)
h_out = h_out.reshape(-1, 128)
# feature = self.fc(h_out)
# outs = self.output_layer(feature)
outs = self.fc(h_out)
return outs
批次和学习率
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=1024)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.8)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 30, gamma=0.8)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.01, momentum=0.8)
效果

v4
网络结构
class MainNet(nn.Module):
def __init__(self):
super().__init__()
self.hidden_layer = nn.Sequential(
ConvLayer(1, 32, 5, 1, 1),
ConvLayer(32, 32, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(32, 64, 5, 1, 1),
ConvLayer(64, 64, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(64, 128, 5, 1, 1),
ConvLayer(128, 128, 5, 1, 2),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(128, 2)
)
self.output_layer = nn.Sequential(
nn.Linear(2, 10)
)
def forward(self, _x):
h_out = self.hidden_layer(_x)
h_out = h_out.reshape(-1, 128)
feature = self.fc(h_out)
outs = self.output_layer(feature)
return torch.cat((feature, outs), dim=1)
批次和学习率
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=1024)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.8)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 30, gamma=0.8)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.1, momentum=0.8)
效果

v4_2
v4基础上修改了学习率
网络结构
class MainNet(nn.Module):
def __init__(self):
super().__init__()
self.hidden_layer = nn.Sequential(
ConvLayer(1, 32, 5, 1, 1),
ConvLayer(32, 32, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(32, 64, 5, 1, 1),
ConvLayer(64, 64, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(64, 128, 5, 1, 1),
ConvLayer(128, 128, 5, 1, 2),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(128, 2)
)
self.output_layer = nn.Sequential(
nn.Linear(2, 10)
)
def forward(self, _x):
h_out = self.hidden_layer(_x)
h_out = h_out.reshape(-1, 128)
feature = self.fc(h_out)
outs = self.output_layer(feature)
return torch.cat((feature, outs), dim=1)
批次和学习率
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=1024)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.8)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 30, gamma=0.8)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.01, momentum=0.8)
效果

结论
centerloss优化器学习率0.1–>0.01,分类效果明显
更换批次
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=256)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.8)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 30, gamma=0.8)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.01, momentum=0.8)
效果

结论
批次1024–>256,计算速度加快,分类速度减慢
v4_3
v4基础上修改了学习率
网络结构
class MainNet(nn.Module):
def __init__(self):
super().__init__()
self.hidden_layer = nn.Sequential(
ConvLayer(1, 32, 5, 1, 1),
ConvLayer(32, 32, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(32, 64, 5, 1, 1),
ConvLayer(64, 64, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(64, 128, 5, 1, 1),
ConvLayer(128, 128, 5, 1, 2),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(128, 2)
)
self.output_layer = nn.Sequential(
nn.Linear(2, 10)
)
def forward(self, _x):
h_out = self.hidden_layer(_x)
h_out = h_out.reshape(-1, 128)
feature = self.fc(h_out)
outs = self.output_layer(feature)
return torch.cat((feature, outs), dim=1)
批次和学习率
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=1024)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.8)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 30, gamma=0.8)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.5, momentum=0.8)
效果

结论
centerloss优化器学习率0.1–>0.5,分类效果明显
v5
加深网络,修改centerloss计算(取消平方根),修改学习率
centerloss计算
# return lamda / 2 * torch.mean(torch.div(torch.sqrt(torch.sum(torch.pow(_x - center_exp, 2), dim=1)), count_exp))
return lamda / 2 * torch.mean(torch.div(torch.sum(torch.pow((_x - center_exp), 2), dim=1), count_exp))
网络结构
self.hidden_layer = nn.Sequential(
# ConvLayer(1, 32, 5, 1, 2),
ConvLayer(3, 32, 5, 1, 2),
ConvLayer(32, 64, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(64, 128, 5, 1, 2),
ConvLayer(128, 256, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(256, 512, 5, 1, 2),
ConvLayer(512, 512, 5, 1, 2),
nn.MaxPool2d(2, 2),
ConvLayer(512, 256, 5, 1, 2),
ConvLayer(256, 128, 5, 1, 2),
ConvLayer(128, 64, 5, 1, 2),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
# nn.Linear(64, 2)
nn.Linear(64 * 2 * 2, 2)
)
self.output_layer = nn.Sequential(
nn.Linear(2, 10)
)
批次和学习率
data_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=256)
# ...
net_opt = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(net_opt, 20, gamma=0.8)
c_l_opt = torch.optim.SGD(center_loss_fn.parameters(), lr=0.5)
效果
MNIST



CIFAR10



CIFAR100




![NNDL卷积神经网络-<span style='color:red;'>使用</span>预训练resnet<span style='color:red;'>18</span><span style='color:red;'>实现</span><span style='color:red;'>CIFAR</span>-<span style='color:red;'>10</span><span style='color:red;'>分类</span> [HBU]](https://img-blog.csdnimg.cn/direct/b4feba68d11a4015b235b66046fb288b.png)