定位慢查询

💖 开源工具
- 调试工具:Arthas(阿尔萨斯)
- 运维工具:Prometheus(普罗米修斯)、Skywalking

💖 MySQL 慢查询日志

# 开启 MySQL 慢查询日志开关
slow_query_log=1
# 设置慢查询日志的时间为 2 秒,SQL 语句执行时间超过 2 秒,就会视为慢查询,记录慢查询日志
long_query_time=2
配置完毕之后,通过以下指令重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息
/var/lib/mysql/localhost-slow.log

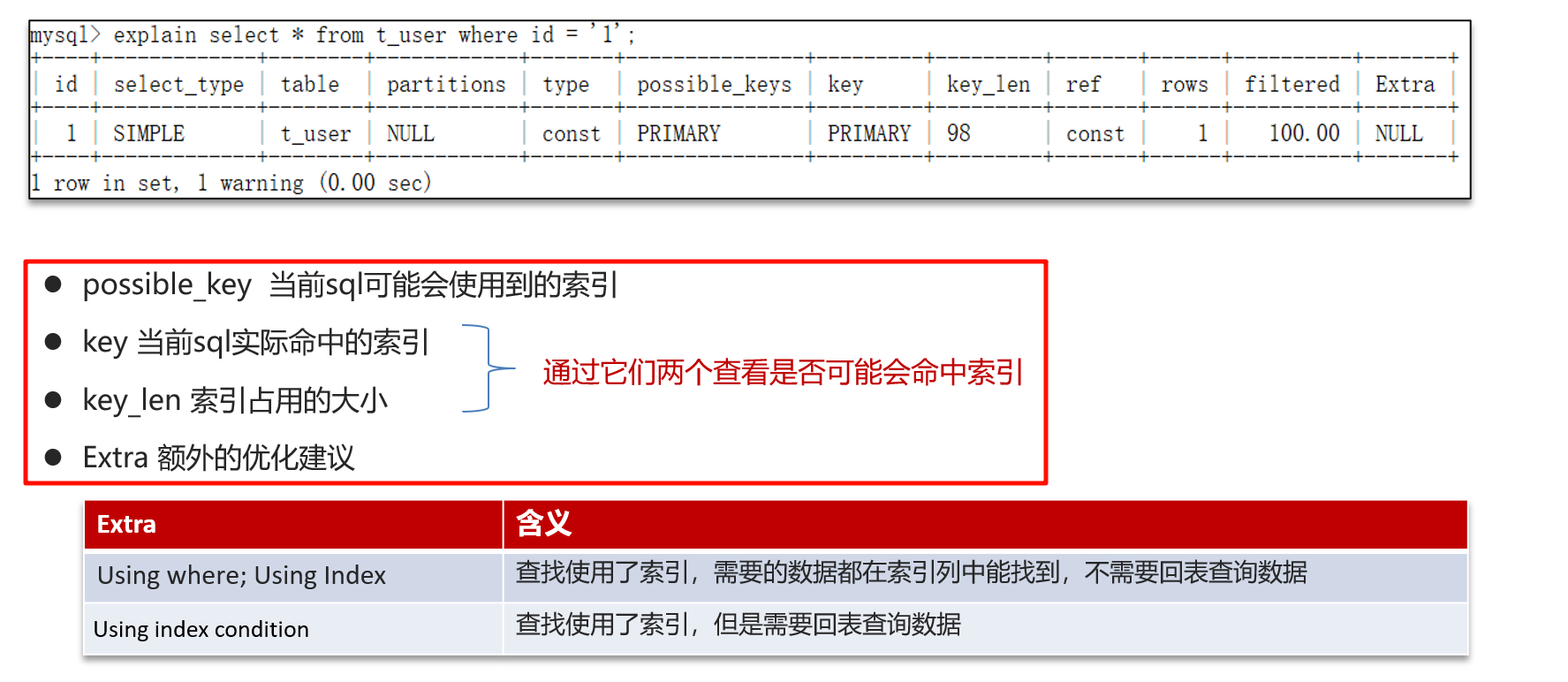
慢SQL分析
可以采用 EXPLAIN 或者 DESC 命令获取 MySQL 如何执行 SELECT 语句的信息

MySQL 存储引擎
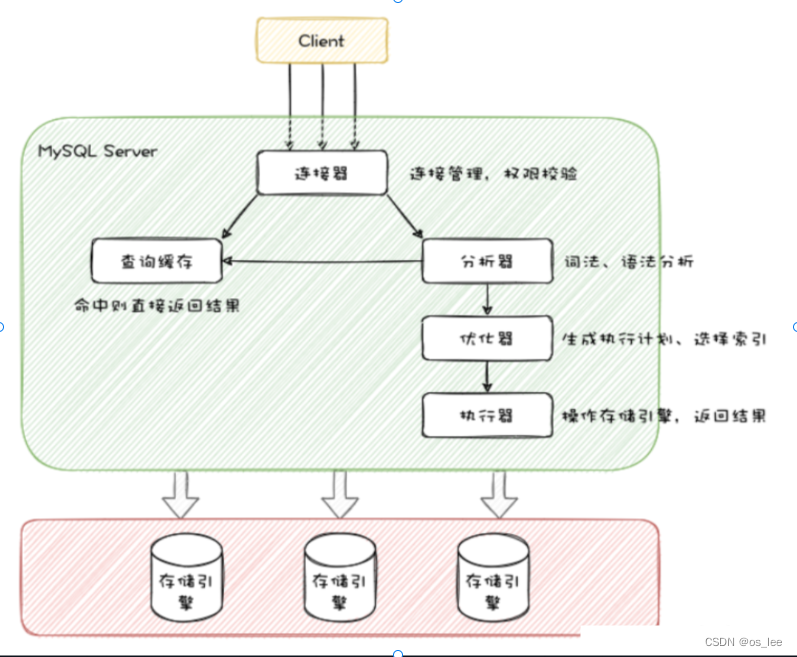
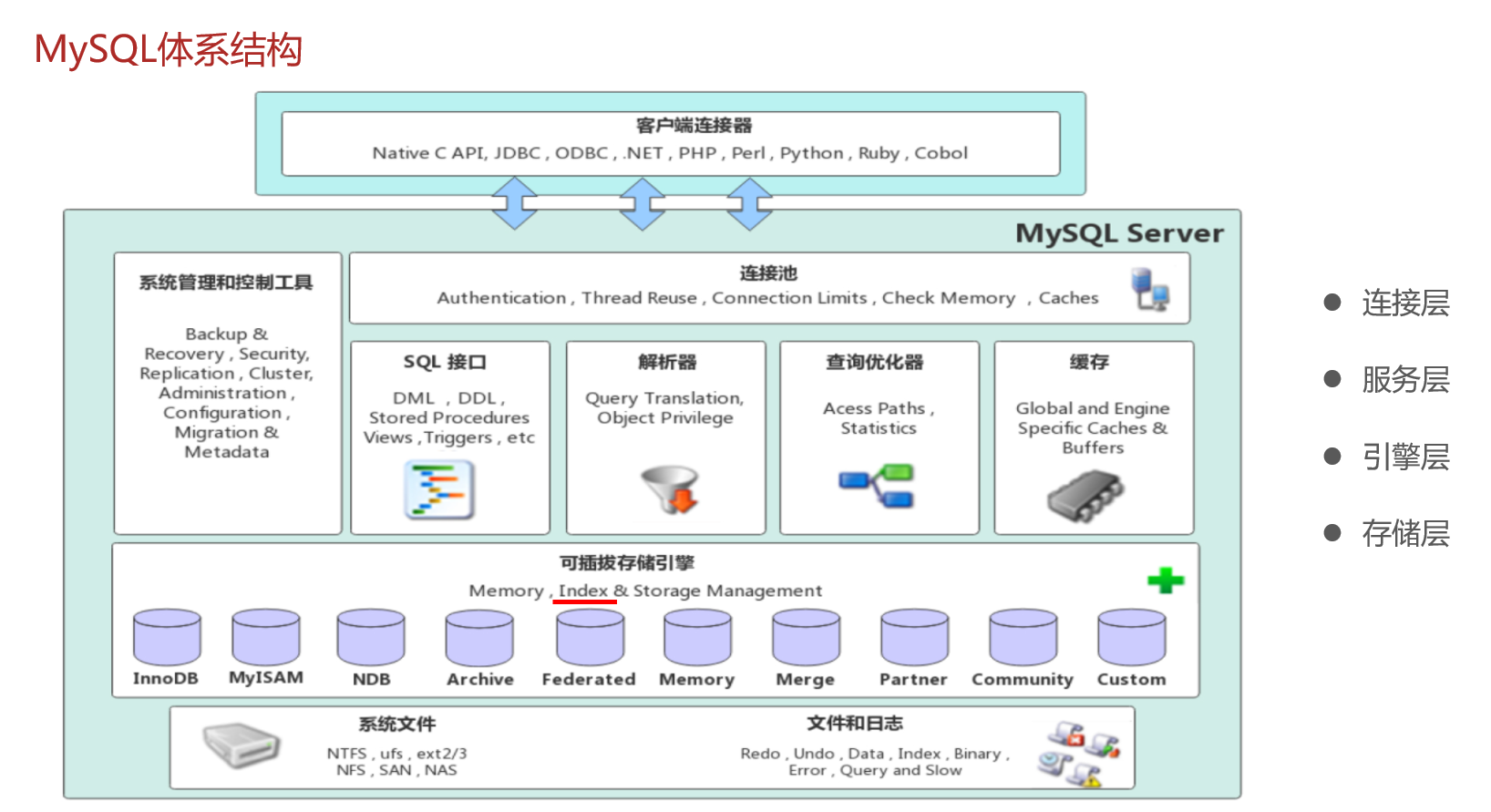
💖 MySQL 体系结构
四层:连接层、服务层、引擎层、存储层。
💖 存储引擎类型
存储引擎就是存储数据、建立索引、更新查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也可以称为 表类型。

MEMORY:把数据存储在内存
💖 InnoDB
- 介绍
- 兼顾高可靠性和高性能的通用存储引擎,在MySQL5.5 之后,InnoDB 是 MySQL默认的存储引擎
- 特点
- DML 操作遵循ACID模型,支持事务
- 行级锁
- 支持外键 FOREIGN KEY 约束,保证数据的完整性和正确性
- 文件
- xxx.ibd:xxx代表的是表名,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm、sdi)、数据和索引
- xxx.frm 存储表结构(MySQL8.0时,合并在表名.ibd中)
索引
索引(index)是帮助MySQL高效获取数据的数据结构,主要是用来提高数据检索的效率,降低数据库的IO成本,同时通过索引列对数据进行排序,降低数据排序的成本,也能降低了CPU的消耗。
💖 底层数据结构
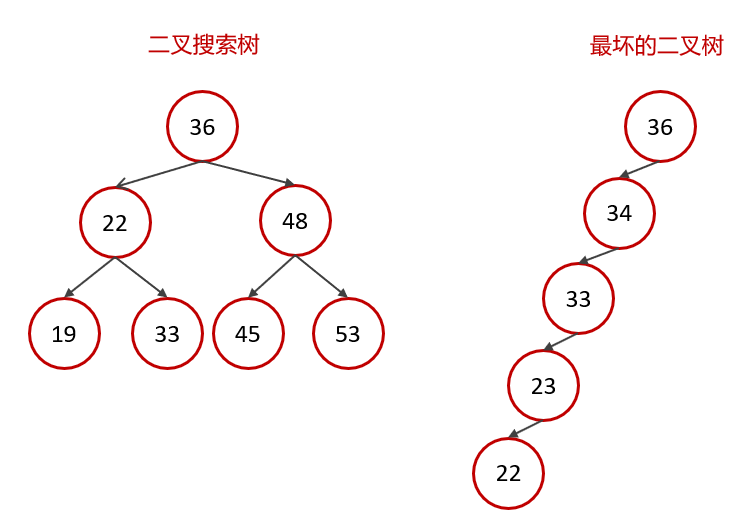
🐷 二叉搜索树
效率不稳定,最坏的情况是 O(n)
🐷 红黑树
解决了二叉搜索树不平衡的问题,但是当数据量过大时,树的层数会很多,查询效率较好但不是最优

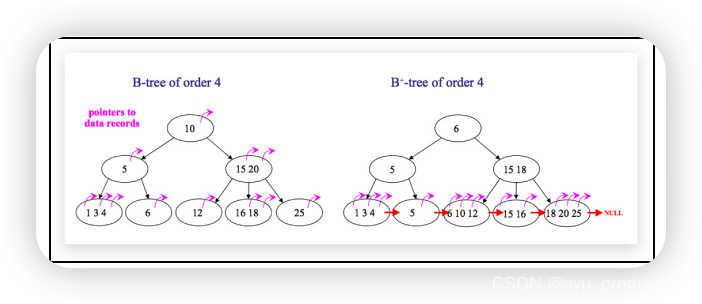
🐷 B 树
B-Tree,B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。
以一颗最大度数(max-degree)为 5(5阶) 的b-tree为例,那这个B树每个节点最多存储 4个key。
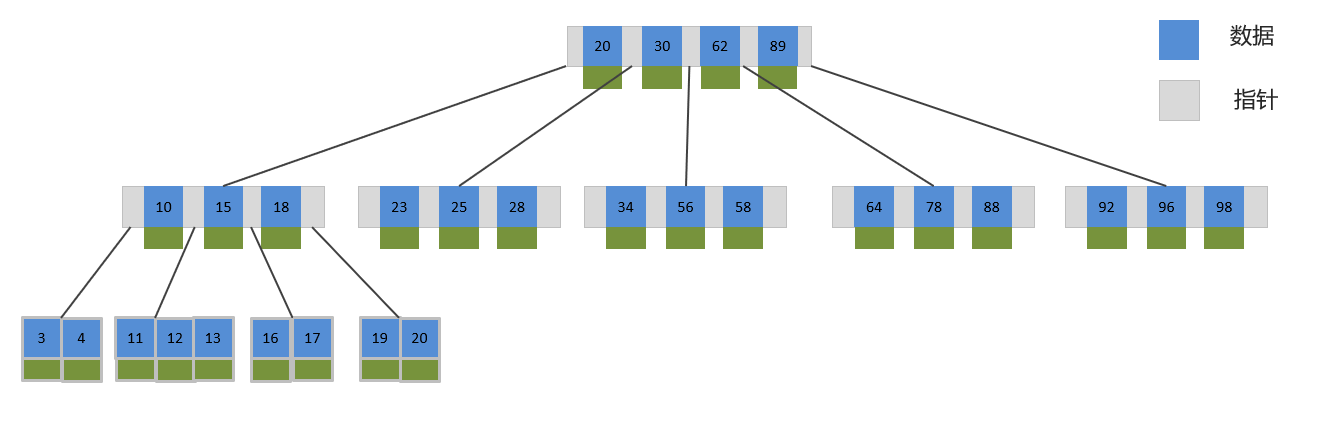
💛 B+ 树
B+Tree 是在 BTree 基础上的一种优化,使其更适合实现外存储索引结构,InnoDB 存储引擎就是用 B+Tree实现其索引结构

B+ 树 vs B树
- B树所有节点都存储数据,B+树只在叶子节点存储数据
- B+树的叶子节点是一个双向链表
B+ 树的优势
- 磁盘读写代价低(只需在叶子节点那层进行磁盘IO,中间的查询过程节点无需操作)
- 查询效率更加稳定(数据都存储在叶子节点)
- 便于区间查询(叶子节点双向链表)
💖 索引分类

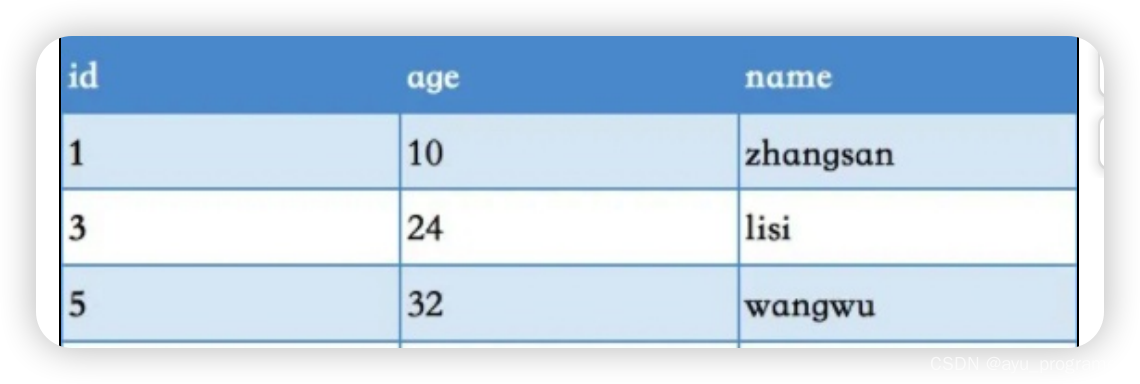
聚簇索引
主要是指数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个,一般情况下用主键作为聚簇索引的索引列非聚簇索引(二极索引)
值的是数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多个,一般我们自己定义的索引都是非聚簇索引
💛 回表查询
回表:就是通过二级索引找到对应的主键值,然后再通过主键值找到聚集索引中所对应的整行数据
覆盖索引不需要回表查询
💖 覆盖索引
覆盖索引是指 select查询 语句使用了索引,需要返回的列全部出现在索引中
- 如果我们使用主键 id 查询,它会直接走聚簇索引查询,聚簇索引中包含所有数据,肯定是覆盖索引
- 如果按照二级索引查询数据的时候,返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用select *,尽量在返回的列中都包含添加索引的字段
💖 深度分页
超大分页一般是指在数据量比较大时,我们使用了 limit分页查询,并且需要对数据进行排序,这个时候效率就很低,我们可以采用覆盖索引和子查询来解决
- 先分页查询数据的 id字段,确定了id之后,再用子查询来过滤,只查询这个id列表中的数据就可以了
💖 索引创建原则
- 数据量较大时,查询多 增删少的表(单表超 10 万数据,提高查询性能)
- 针对常用作查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
- 选择区分度高的列
- 字符串类型:较长时,建立前缀索引
- 前缀索引能有效减小索引文件的大小,让每个索引页可以保存更多的索引值,从而提高了索引查询的速度。但前缀索引也有它的缺点,不能在 order by 或者 group by 中触发前缀索引,也不能把它们用于覆盖索引
- 尽量使用联合索引,可以更好地实现索引覆盖
- 控制数量,越多的索引导致维护索引结构的代价也越大,反而降低增删改的效率
- 索引列尽可能创建 非空(NOT NULL)列,方便优化器更好地选择要使用的索引。
💖 索引失效
- 违反最左匹配原则
- 相当于多级目录,不能跳过上一级目录直接查询下一级目录,比如字典按拼音查字,先查第一个 字母,才能在第一个字母的基础上 按第二个字母查
- 使用了范围查询的列 右边的索引列失效(不可用)
- 范围查询本身也不一定生效,优化器会计算符合条件的数据比例,视情况使用索引
- 在索引列上使用函数、运算操作,失效
- 字符串不加 引号,导致查询优化器进行类型转换使用了函数操作,失效
- 原因:有操作,索引的条件就会有变动,变动之后就查不了,比如查字典查“ha”,h 变成了 其他字母,那就没法子查了
- 以 % 开头的模糊查询,失效
SQL 优化
当然有索引一席之地,参考上文
💖 表设计优化

💖 SQL 语句优化

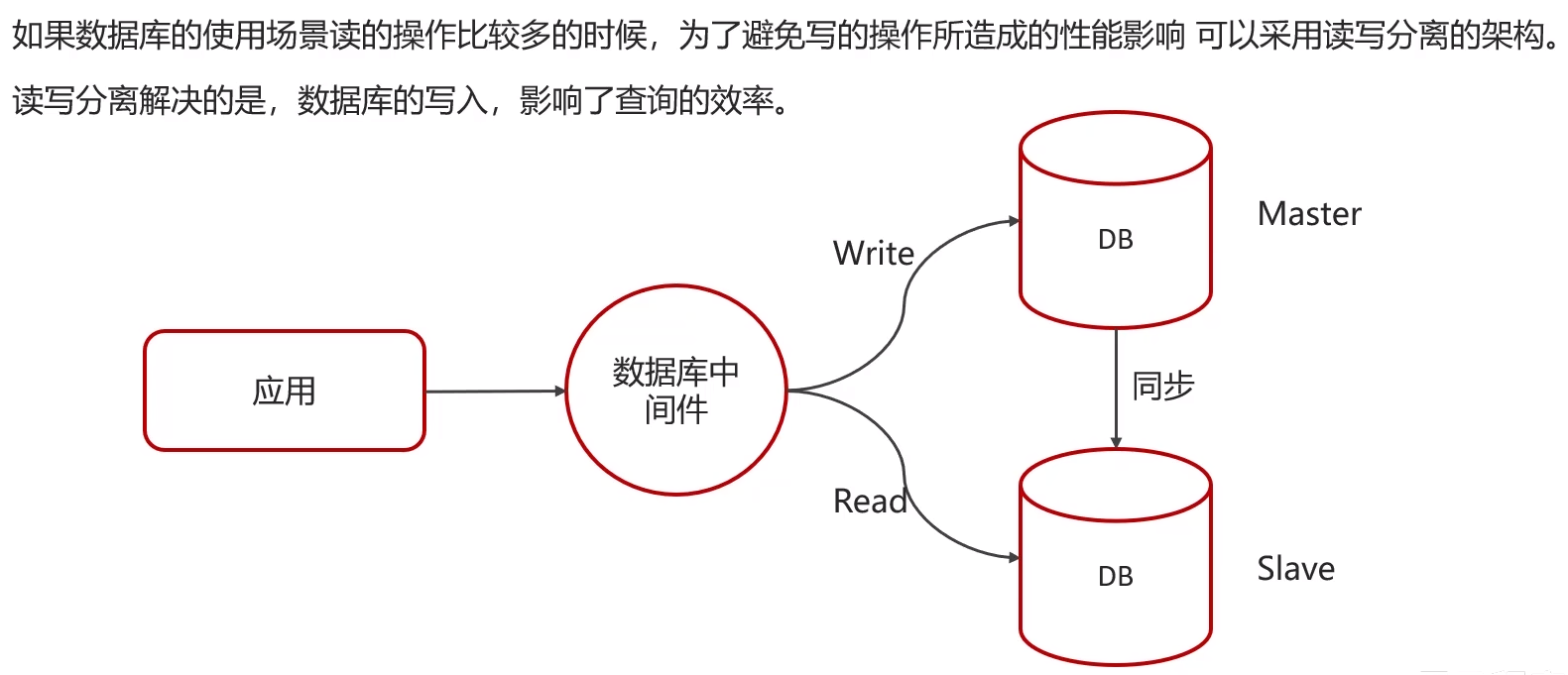
💖 主从复制 读写分离
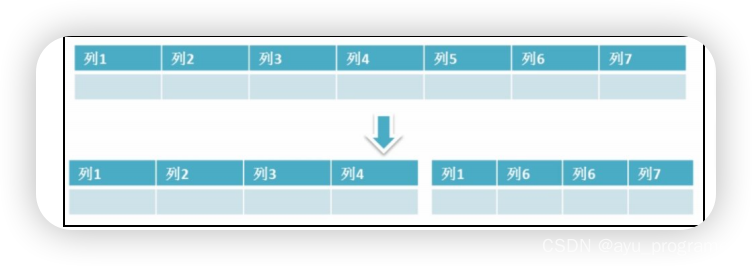
其实还有个分库分表
![[<span style='color:red;'>MySQL</span><span style='color:red;'>面试</span><span style='color:red;'>题</span>]<span style='color:red;'>myql</span><span style='color:red;'>优化</span>及其他<span style='color:red;'>面试</span><span style='color:red;'>题</span>](https://img-blog.csdnimg.cn/direct/4bc500fd7bd4487894d9e761e5df5c44.png)