一、描述C语言中的错误处理机制
C语言中的错误处理机制主要依赖于返回值、错误码以及条件编译指令。C语言本身并没有像一些更高级的语言(如Java或Python)那样提供异常处理机制,而是依赖于程序员显式地检查错误并采取相应的行动。
以下是一些C语言中常用的错误处理策略:
返回值检查:许多C语言库函数在发生错误时会返回一个特殊的值(通常是NULL或特定的错误码)。程序员在调用这些函数后需要检查返回值,以确定是否发生了错误。例如,
malloc函数在无法分配内存时会返回NULL。
c复制代码
int *ptr = malloc(10 * sizeof(int)); |
|
if (ptr == NULL) { |
|
// 错误处理代码 |
|
} |
全局错误变量:有些函数使用全局变量来报告错误。这些全局变量通常在函数调用后设置,然后程序员可以检查这些变量的值来确定是否发生了错误。例如,
errno是一个在C标准库中定义的全局变量,用于报告系统调用的错误。
c复制代码
#include <errno.h> |
|
FILE *fp = fopen("nonexistent.txt", "r"); |
|
if (fp == NULL) { |
|
printf("Error opening file: %s\n", strerror(errno)); |
|
} |
- 错误码:一些函数通过特定的错误码来报告错误。这些错误码通常是函数返回值的一部分,或者通过另一个参数返回。程序员需要查阅函数的文档以了解可能的错误码以及它们的含义。
- 条件编译指令:C语言中的
#ifdef、#ifndef、#if等预处理指令可以用于在编译时根据条件包含或排除代码。这可以用于错误处理,例如,在调试模式下包含额外的错误检查代码,而在生产模式下则不包含。 - 自定义错误处理函数:程序员也可以编写自己的错误处理函数,这些函数可以根据需要执行特定的操作,如打印错误消息、记录日志或执行清理操作。这些函数可以在需要的地方调用,以提供统一的错误处理机制。
需要注意的是,C语言中的错误处理通常需要程序员显式地进行,这意味着程序员需要仔细检查和处理每一个可能的错误情况。虽然这种方式可能相对繁琐,但它也提供了更大的灵活性和控制力,使程序员能够根据自己的需求定制错误处理策略。
二、解释线程同步和互斥的概念
线程同步和互斥是并发编程中的两个重要概念,它们主要用于协调多个线程的执行,以防止数据冲突和不一致。
线程同步指的是当有一个线程在对内存进行操作时,其他线程都不可以对这个内存地址进行操作,直到该线程完成操作,其他线程才能对该内存地址进行操作。同步的目的是为了避免数据混乱,解决与时间有关的错误。简言之,线程同步就是线程排队,一个线程的执行依赖另一个线程的消息,当它没有得到另一个线程的消息时应等待,得到消息被唤醒。通过这种方式,线程同步使得多个线程能够协调工作,从而保持数据的一致性。
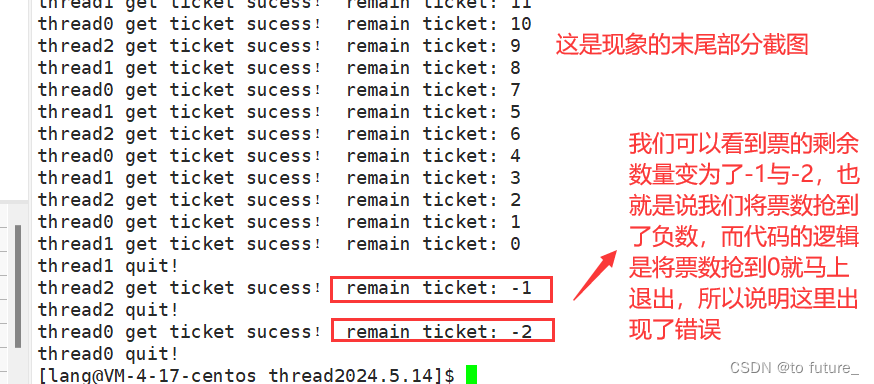
线程互斥则是指对于共享的进程系统资源,在各单个线程访问时的排它性。当有若干个线程都要使用某一共享资源时,任何时刻最多只允许一个线程去使用,其他要使用该资源的线程必须等待,直到占用资源者释放该资源。线程互斥可以看成是一种特殊的线程同步,它确保了同一时刻只有一个线程能够访问共享资源,从而防止了访问冲突。
总结来说,线程同步和互斥都是为了在多线程环境中确保数据的一致性和安全性。同步更侧重于协调线程的执行顺序,而互斥则更侧重于防止对共享资源的并发访问。在实际编程中,通常需要根据具体需求选择使用线程同步或互斥,或者结合使用两者来实现更复杂的并发控制。



![<span style='color:red;'>C</span>++多<span style='color:red;'>线</span><span style='color:red;'>程</span>学习[四]:多<span style='color:red;'>线</span><span style='color:red;'>程</span><span style='color:red;'>的</span>通信<span style='color:red;'>和</span><span style='color:red;'>同步</span>、<span style='color:red;'>互斥</span>锁、超时锁、共享锁](https://img-blog.csdnimg.cn/direct/b671cc8e11ad4d77b8b518408b4dd028.png)