目录
摘要
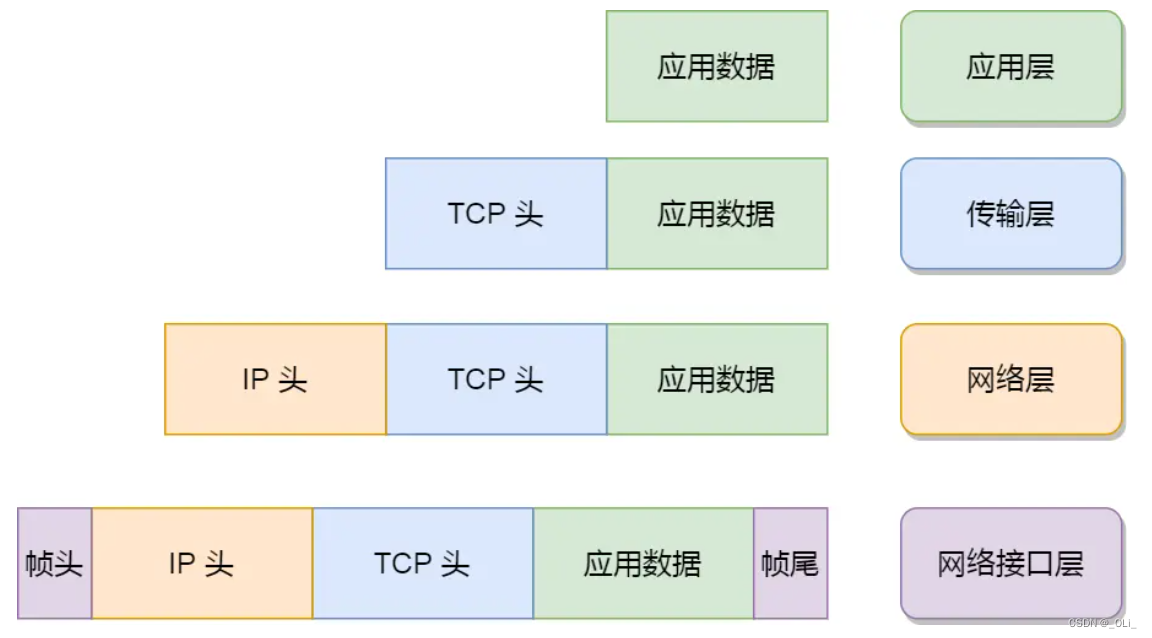
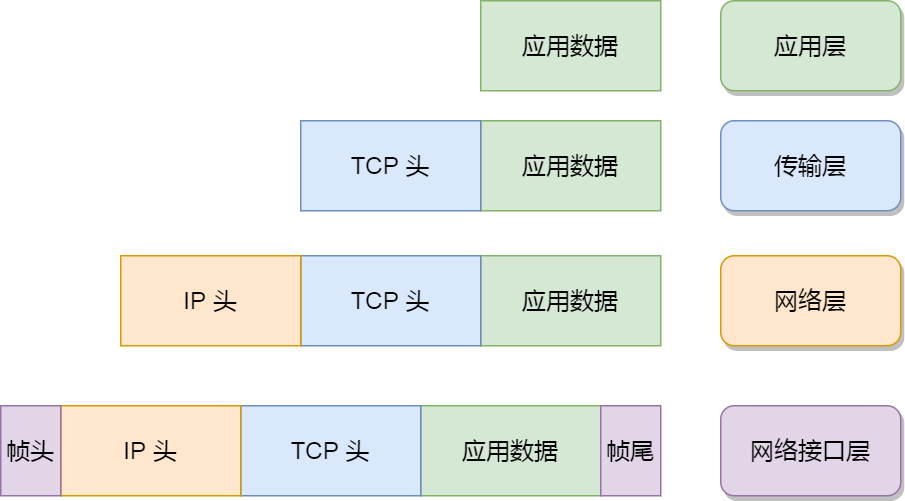
一个网络包的发送,始于应用层,经层层协议栈的封装,终于网卡。今天来循着一个网络包的足迹👣,深入学习一下 Linux 下发送数据的处理流程。
文中引用 Linux 内核源码基于版本 2.6.34,并做了一些删减以提高可读性。

当你手头正好有一个 scoket ,并且开辟了一个 buf,就会情不自禁的想要把这个 buf 塞给 socket 发送出去![]() 。虽然我们有多个方法可用,但请从 send 开始吧~
。虽然我们有多个方法可用,但请从 send 开始吧~
1 从 send 开始
嗯,send 系统调用做的事非常的简单,就是调了一下 sys_sendto。从这里就可以看出来了,sys_send 调用封装了 sys_sendto,两者只有参数的差别:
// net/socket.c
SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len,
unsigned, flags)
{
return sys_sendto(fd, buff, len, flags, NULL, 0);
}
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len,
unsigned, flags, struct sockaddr __user *, addr,
int, addr_len)
{
struct socket *sock;
// 查找 socket
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
iov.iov_base = buff;
iov.iov_len = len;
msg.msg_name = NULL;
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
if (addr) {
err = move_addr_to_kernel(addr, addr_len, (struct sockaddr *)&address);
if (err < 0)
goto out_put;
msg.msg_name = (struct sockaddr *)&address;
msg.msg_namelen = addr_len;
}
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
msg.msg_flags = flags;
// 发送数据
err = sock_sendmsg(sock, &msg, len);
}在 sendto 系统调用中,主要是把 socket 查出来,然后调用 sock_sendmsg,并在其内部一层层调用封装后的函数,并最终通过 inet_sendmsg 将数据丢到协议栈就完事儿~
2 传输层
inet_sendms 是 AF_INET 协议族提供的一个通用函数,内部会区分根据不同的 socket 类型,调用其提前注册好的回调函数。
// net\ipv4\af_inet.c
int inet_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,
size_t size)
{
struct sock *sk = sock->sk;
/* We may need to bind the socket. */
if (!inet_sk(sk)->inet_num && inet_autobind(sk))
return -EAGAIN;
return sk->sk_prot->sendmsg(iocb, sk, msg, size);
}我们要看的是 tcp 协议,所以这里的 sendmsg 自然就是 tcp 的 tcp_sndmsg 方法啦:
// net\ipv4\tcp.c
int tcp_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,
size_t size)
{
flags = msg->msg_flags;
timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
// 检查连接状态
if ((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT))
if ((err = sk_stream_wait_connect(sk, &timeo)) != 0)
goto out_err;
// 获取最大报文段长度
mss_now = tcp_send_mss(sk, &size_goal, flags);
// 获取用户传递的数据和 flag
iovlen = msg->msg_iovlen;
iov = msg->msg_iov;
copied = 0;
// 遍历用户传递的每块数据
while (--iovlen >= 0) {
int seglen = iov->iov_len;
unsigned char __user *from = iov->iov_base; // 数据块地址
iov++;
while (seglen > 0) {
int copy = 0;
int max = size_goal;
// 获取tcp socket 的发送队列
skb = tcp_write_queue_tail(sk);
if (tcp_send_head(sk)) {
if (skb->ip_summed == CHECKSUM_NONE)
max = mss_now;
copy = max - skb->len;
}
// 构造 skb,涉及数据拷贝
if (copy <= 0) {
new_segment:
if (!sk_stream_memory_free(sk))
goto wait_for_sndbuf;
skb = sk_stream_alloc_skb(sk,
select_size(sk, sg),
sk->sk_allocation);
if (!skb)
goto wait_for_memory;
// 待发送 skb 入发送队列
skb_entail(sk, skb);
}
if (skb_tailroom(skb) > 0) {
if (copy > skb_tailroom(skb))
copy = skb_tailroom(skb);
// 把用户空间数据拷贝到内核空间:第一次拷贝
if ((err = skb_add_data(skb, from, copy)) != 0)
goto do_fault;
}
// 检查是否可以发送数据包
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now);
continue;
wait_for_sndbuf:
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
wait_for_memory:
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH);
if ((err = sk_stream_wait_memory(sk, &timeo)) != 0)
goto do_error;
mss_now = tcp_send_mss(sk, &size_goal, flags);
}
}
}
tcp_sendmsg 很长,主要涉及以下几件事情:
- 构造 skb,拷贝用户态数据到 skb 中
- 将 skb 加入 socket 的发送队列
- 判断发送条件是否成立决定是否发送
tcp_sndmsg中有两个发送方法:
// net\ipv4\tcp.c
void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss,
int nonagle)
{
/* If we are closed, the bytes will have to remain here.
* In time closedown will finish, we empty the write queue and
* all will be happy.
*/
if (unlikely(sk->sk_state == TCP_CLOSE))
return;
if (tcp_write_xmit(sk, cur_mss, nonagle, 0, GFP_ATOMIC))
tcp_check_probe_timer(sk);
}
// net\ipv4\tcp_output.c
void tcp_push_one(struct sock *sk, unsigned int mss_now)
{
struct sk_buff *skb = tcp_send_head(sk);
BUG_ON(!skb || skb->len < mss_now);
tcp_write_xmit(sk, mss_now, TCP_NAGLE_PUSH, 1, sk->sk_allocation);
}可见其还是殊途同归,都调用了 tcp_write_xmit 方法,只不过参数有点差异罢了,普通发送流程默认是启用了 nagle 算法的:
// net\ipv4\tcp_output.c
static int tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
// 依次处理待发送的 skb
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
tso_segs = tcp_init_tso_segs(sk, skb, mss_now);
BUG_ON(!tso_segs);
// 测试拥塞窗口是否满足发送条件
cwnd_quota = tcp_cwnd_test(tp, skb);
if (!cwnd_quota)
break;
// 测试发送窗口是否满足发送条件
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now)))
break;
if (tso_segs == 1) {
// 测试 nagle 算法是否满足发送条件
if (unlikely(!tcp_nagle_test(tp, skb, mss_now,
(tcp_skb_is_last(sk, skb) ?
nonagle : TCP_NAGLE_PUSH))))
break;
}
...
// 发送
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
/* Advance the send_head. This one is sent out.
* This call will increment packets_out.
*/
tcp_event_new_data_sent(sk, skb);
tcp_minshall_update(tp, mss_now, skb);
sent_pkts++;
if (push_one)
break;
}
if (likely(sent_pkts)) {
tcp_cwnd_validate(sk);
return 0;
}
return !tp->packets_out && tcp_send_head(sk);
}tcp_write_xmit 中处理了 tcp 的拥塞控制、流量控制窗口条件、nagle 算法满足发送要求,就继续调用 tcp_transmit_skb 方法了:
// net\ipv4\tcp_output.c
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it,
gfp_t gfp_mask)
{
// 克隆 skb: 实际上只克隆了 skb 元数据,即头部(第二次拷贝,仅头部)
// 数据部分跟原 skb 共享,毕竟内核不会修改用户数据,拷贝它干啥?
if (likely(clone_it)) {
if (unlikely(skb_cloned(skb)))
skb = pskb_copy(skb, gfp_mask);
else
skb = skb_clone(skb, gfp_mask);
if (unlikely(!skb))
return -ENOBUFS;
}
...
// 设置 tcp 头中各字段
th = tcp_hdr(skb);
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(tp->rcv_nxt);
*(((__be16 *)th) + 6) = htons(((tcp_header_size >> 2) << 12) |
tcb->flags);
if (unlikely(tcb->flags & TCPCB_FLAG_SYN)) {
/* RFC1323: The window in SYN & SYN/ACK segments
* is never scaled.
*/
th->window = htons(min(tp->rcv_wnd, 65535U));
} else {
th->window = htons(tcp_select_window(sk));
}
th->check = 0;
th->urg_ptr = 0;
/* The urg_mode check is necessary during a below snd_una win probe */
if (unlikely(tcp_urg_mode(tp) && before(tcb->seq, tp->snd_up))) {
if (before(tp->snd_up, tcb->seq + 0x10000)) {
th->urg_ptr = htons(tp->snd_up - tcb->seq);
th->urg = 1;
} else if (after(tcb->seq + 0xFFFF, tp->snd_nxt)) {
th->urg_ptr = 0xFFFF;
th->urg = 1;
}
}
tcp_options_write((__be32 *)(th + 1), tp, &opts);
if (likely((tcb->flags & TCPCB_FLAG_SYN) == 0))
TCP_ECN_send(sk, skb, tcp_header_size);
icsk->icsk_af_ops->send_check(sk, skb->len, skb);
if (likely(tcb->flags & TCPCB_FLAG_ACK))
tcp_event_ack_sent(sk, tcp_skb_pcount(skb));
if (skb->len != tcp_header_size)
tcp_event_data_sent(tp, skb, sk);
if (after(tcb->end_seq, tp->snd_nxt) || tcb->seq == tcb->end_seq)
TCP_INC_STATS(sock_net(sk), TCP_MIB_OUTSEGS);
// 调用网络层发送接口
err = icsk->icsk_af_ops->queue_xmit(skb, 0);
if (likely(err <= 0))
return err;
tcp_enter_cwr(sk, 1);
return net_xmit_eval(err);
}在这各方法中,克隆了一个 skb 出来,为什么需要克隆?因为网络层发送 skb 之后,底层最终会释放掉这个 skb,而 tcp 是可靠连接,在传输层维护了发送队列,如果对端没有响应,是要进行丢包重传的,所以原始 skb,tcp 要自己留着。故而这里是第二次拷贝了,只不过需要注意的是,这里并不涉及用户数据的拷贝,而是 skb 元数据的拷贝,提升了效率。
3 网络层
数据到了网络层。queue_xmit 也是个回调方法,由网络层注入到传输层的。实际对应的方法是 ip_queue_xmit :
int ip_queue_xmit(struct sk_buff *skb, int ipfragok)
{
// 检查路由表是否已经有了
rt = skb_rtable(skb);
if (rt != NULL)
goto packet_routed;
// 没有路由项则进行填充
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (rt == NULL) {
__be32 daddr;
/* Use correct destination address if we have options. */
daddr = inet->inet_daddr;
if(opt && opt->srr)
daddr = opt->faddr;
{
...
security_sk_classify_flow(sk, &fl);
if (ip_route_output_flow(sock_net(sk), &rt, &fl, sk, 0))
goto no_route;
}
sk_setup_caps(sk, &rt->u.dst);
}
// 填充路由项
skb_dst_set(skb, dst_clone(&rt->u.dst));
packet_routed:
if (opt && opt->is_strictroute && rt->rt_dst != rt->rt_gateway)
goto no_route;
// ip 包头设置
skb_push(skb, sizeof(struct iphdr) + (opt ? opt->optlen : 0));
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (inet->tos & 0xff));
if (ip_dont_fragment(sk, &rt->u.dst) && !ipfragok)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->u.dst);
iph->protocol = sk->sk_protocol;
iph->saddr = rt->rt_src;
iph->daddr = rt->rt_dst;
/* Transport layer set skb->h.foo itself. */
if (opt && opt->optlen) {
iph->ihl += opt->optlen >> 2;
ip_options_build(skb, opt, inet->inet_daddr, rt, 0);
}
ip_select_ident_more(iph, &rt->u.dst, sk,
(skb_shinfo(skb)->gso_segs ?: 1) - 1);
skb->priority = sk->sk_priority;
skb->mark = sk->sk_mark;
// 走发送流程
return ip_local_out(skb);
}网络层通过查询路由表,将路由项缓存到 skb 中,这样数据包就知道下一步怎么走了,然后设置完 ip 包头就走到了 ip_local_out:
// net\ipv4\ip_output.c
int ip_local_out(struct sk_buff *skb)
{
int err;
// 流经 netfilter 框架的 local_out
err = __ip_local_out(skb);
if (likely(err == 1))
// 发送数据
err = dst_output(skb);
return err;
}
int __ip_local_out(struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
ip_send_check(iph);
return nf_hook(PF_INET, NF_INET_LOCAL_OUT, skb, NULL, skb_dst(skb)->dev,
dst_output);
}
经过 netfilter 的 local_out 的蹂躏 ,如果 skb 幸存了下来,那就会接着通过 dst_output 进行发送了:
,如果 skb 幸存了下来,那就会接着通过 dst_output 进行发送了:
static inline int dst_output(struct sk_buff *skb)
{
return skb_dst(skb)->output(skb);
}dst_output 就是通过 skb 的路由项,找到对应的路由方法 output,这里实际是调用的是 ip_output 了:
// net\ipv4\ip_output.c
int ip_output(struct sk_buff *skb)
{
struct net_device *dev = skb_dst(skb)->dev;
IP_UPD_PO_STATS(dev_net(dev), IPSTATS_MIB_OUT, skb->len);
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(PF_INET, NF_INET_POST_ROUTING, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
} 这里设置了 skb 的协议信息,然后又被 netfilter 框架的 post_routing 蹂躏一番 ,如果 skb 侥幸通过了 post_routing,那么就会走到 ip_finish_output 了:
,如果 skb 侥幸通过了 post_routing,那么就会走到 ip_finish_output 了:
static int ip_finish_output(struct sk_buff *skb)
{
// 根据 mtu 判断是否需要分片
if (skb->len > ip_skb_dst_mtu(skb) && !skb_is_gso(skb))
return ip_fragment(skb, ip_finish_output2);
else
return ip_finish_output2(skb);
}ip_finish_output 分两种情况,大于 mtu 的要经过分片再发送,小于 mtu 的可以直接发送。为了简单起见,我们直接看发送流程:
static inline int ip_finish_output2(struct sk_buff *skb)
{
/* Be paranoid, rather than too clever. */
if (unlikely(skb_headroom(skb) < hh_len && dev->header_ops)) {
struct sk_buff *skb2;
skb2 = skb_realloc_headroom(skb, LL_RESERVED_SPACE(dev));
if (skb2 == NULL) {
kfree_skb(skb);
return -ENOMEM;
}
if (skb->sk)
skb_set_owner_w(skb2, skb->sk);
kfree_skb(skb);
skb = skb2;
}
// 传递给邻居子系统
if (dst->hh)
return neigh_hh_output(dst->hh, skb);
else if (dst->neighbour)
return dst->neighbour->output(skb);
...
}ip_finish_output2 中把数据传输到了邻居子系统,实际就是四层协议栈中的网络接口层了。
4 网络接口层
4.1 邻居子系统
邻居子系统位于数据链路层与网络层直接,在这里主要是查找或者创建邻居项,在创造邻居项的时候,有可能会发出实际的 arp 请求。然后封装一下 MAC 头,将发送过程再传递到更下层的网络设备子系统。
// net\core\neighbour.c
int neigh_resolve_output(struct sk_buff *skb)
{
struct dst_entry *dst = skb_dst(skb);
struct neighbour *neigh;
__skb_pull(skb, skb_network_offset(skb));
// 没有邻居的 mac 地址的话还需要发送 arp 进行解析
if (!neigh_event_send(neigh, skb)) {
int err;
struct net_device *dev = neigh->dev;
if (dev->header_ops->cache && !dst->hh) {
write_lock_bh(&neigh->lock);
if (!dst->hh)
neigh_hh_init(neigh, dst, dst->ops->protocol);
// 把 mac 地址(neigh->ha) 设置套帧头
err = dev_hard_header(skb, dev, ntohs(skb->protocol),
neigh->ha, NULL, skb->len);
write_unlock_bh(&neigh->lock);
}
if (err >= 0)
// 数据帧交给网络子系统发送
rc = neigh->ops->queue_xmit(skb);
else
goto out_kfree_skb;
}
}4.2 网络设备子系统
邻居子系统已经填好了 skb 头的 mac 地址,接下来就是真正的发送逻辑了:
// net\core\dev.c
int dev_queue_xmit(struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
struct Qdisc *q;
...
// 将 skb 各片段线性化到一个连续缓冲区
if (skb_needs_linearize(skb, dev) && __skb_linearize(skb))
goto out_kfree_skb;
// 如果数据包的部分校验和还未完成,那么在这里完成校验和计算
if (skb->ip_summed == CHECKSUM_PARTIAL) {
skb_set_transport_header(skb, skb->csum_start -
skb_headroom(skb));
if (!dev_can_checksum(dev, skb) && skb_checksum_help(skb))
goto out_kfree_skb;
}
gso:
// 选择一个发送队列:RingBuf
txq = dev_pick_tx(dev, skb);
q = rcu_dereference_bh(txq->qdisc);
// 有队列,就继续发送
if (q->enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
// 没有队列说明是回环设备或者隧道设备
if (dev->flags & IFF_UP) {
...
}
}由于现代网卡为了提升性能大多支持多队列,所以这里当然要选择一个合适的队列了,选择好之后就通过 __dev_xmit_skb 进行发送了:
// net\core\dev.c
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev,
struct netdev_queue *txq)
{
...
// 排队发送
rc = qdisc_enqueue_root(skb, q);
qdisc_run(q);
}qdisc_run 是 __qdisc_run 的简单封装:
void __qdisc_run(struct Qdisc *q)
{
unsigned long start_time = jiffies;
// 依次从队列中取 skb 进行发送
while (qdisc_restart(q)) {
// 如果需要被调度出去,则延迟发送剩余的 skb
if (need_resched() || jiffies != start_time) {
__netif_schedule(q);
break;
}
}
}在这里,实际的发送还一直都是占用原进程对应的系统态时间,只有当进程需要被调度出去的时候,才会通过软中断将剩余的 skb 发送出去。
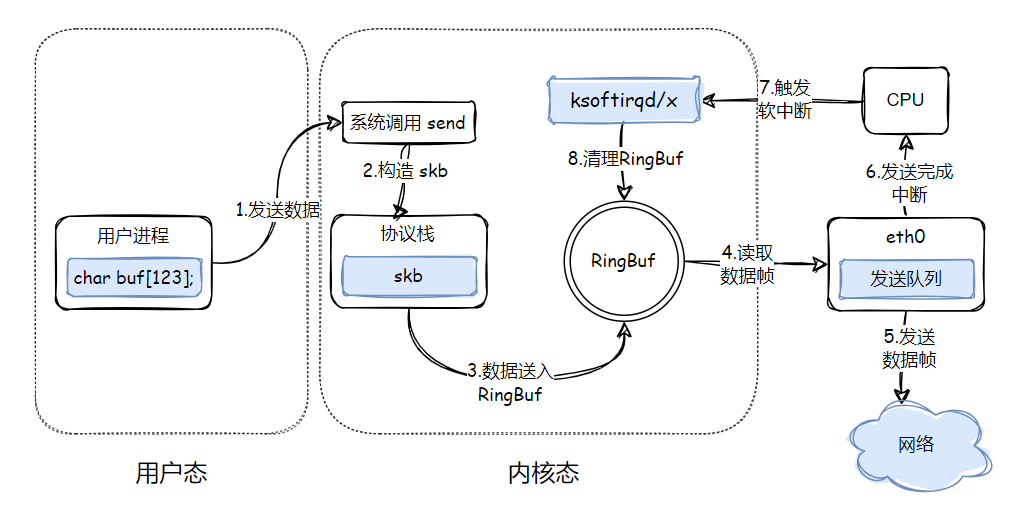
通过 /proc/softirqs 看到的接收软中断要比发送软中断高几个数量级,这里就是第一个原因:大部分数据包的发送占用原进程的系统时间进行发送,只有被调度出去后,剩余的 skb 才会通过发送软中断取发送。
[root@centos ~]# cat /proc/softirqs
CPU0 CPU1
HI: 0 1
TIMER: 87639029 63839412
NET_TX: 0 0
NET_RX: 3495365 3180870
// net\sched\sch_generic.c
static inline int qdisc_restart(struct Qdisc *q)
{
struct netdev_queue *txq;
struct net_device *dev;
spinlock_t *root_lock;
struct sk_buff *skb;
// skb 出队
skb = dequeue_skb(q);
if (unlikely(!skb))
return 0;
root_lock = qdisc_lock(q);
dev = qdisc_dev(q);
txq = netdev_get_tx_queue(dev, skb_get_queue_mapping(skb));
// 发送
return sch_direct_xmit(skb, q, dev, txq, root_lock);
}qdisc_restart 从队列中出队一个 skb,继续调用 sch_direct_xmit 发送:
// net\sched\sch_generic.c
int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev, struct netdev_queue *txq,
spinlock_t *root_lock)
{
if (!netif_tx_queue_stopped(txq) && !netif_tx_queue_frozen(txq))
ret = dev_hard_start_xmit(skb, dev, txq);
return ret;
}
// net\core\dev.c
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq)
{
...
rc = ops->ndo_start_xmit(skb, dev);
if (rc == NETDEV_TX_OK)
txq_trans_update(txq);
}最终走到网卡驱动注册的回调方法 ndo_start_xmit 进行发送。
4.3 软中断发送剩余的 skb
前面 __qdisc_run 中在当前进程被调度出去后,发送队列剩余的包怎么处理呢?继续看下看这里的处理流程。__netif_schdule 内部最终调用了 __netif_reschedule:
// net\core\dev.c
static inline void __netif_reschedule(struct Qdisc *q)
{
struct softnet_data *sd;
unsigned long flags;
local_irq_save(flags);
sd = &__get_cpu_var(softnet_data);
q->next_sched = sd->output_queue;
sd->output_queue = q;
raise_softirq_irqoff(NET_TX_SOFTIRQ);
local_irq_restore(flags);
}可以看到,在 __netif_reschedule 中,触发了一个 NET_TX_SOFTIRQ 软中断,即剩下的包要走软中断发送了。NET_TX_SOFTIRQ 软中断对应的中端处理函数是 net_tx_action:
static void net_tx_action(struct softirq_action *h)
{
// 获取每 cpu 上的发送队列
struct softnet_data *sd = &__get_cpu_var(softnet_data);
...
// 如果有 output_queue,说明不是回环或隧道设备
if (sd->output_queue) {
struct Qdisc *head;
local_irq_disable();
head = sd->output_queue;
sd->output_queue = NULL;
local_irq_enable();
// 遍历 qdiscs 列表
while (head) {
struct Qdisc *q = head;
spinlock_t *root_lock;
head = head->next_sched;
root_lock = qdisc_lock(q);
if (spin_trylock(root_lock)) {
smp_mb__before_clear_bit();
clear_bit(__QDISC_STATE_SCHED,
&q->state);
// 一样是调用 qdisc_run 进行发送
qdisc_run(q);
spin_unlock(root_lock);
} else {
if (!test_bit(__QDISC_STATE_DEACTIVATED,
&q->state)) {
__netif_reschedule(q);
} else {
smp_mb__before_clear_bit();
clear_bit(__QDISC_STATE_SCHED,
&q->state);
}
}
}
}
}发送软中断这里首先会获取 softnet_data,跟我们在接收软中断中看到的操作类似。随后又是调用 qdisc_run 进行数据发送,这一点有跟在进程内核态中发送数据的流程一样了。
4.4 硬中断又触发软中断
网卡具体的发送处理流程就不一一细看了,不是我们关注的重点。重点看下发送完成后是怎么清理的?
// net\core\dev.c
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
list_add_tail(&n->poll_list, &__get_cpu_var(softnet_data).poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
local_irq_restore(flags);
}发送完成后,网卡发出了硬中断,硬中断中触发软中断就只有这一个流程:还是通过 __napi_schedule 来触发。这就有意思了,发送完成后触发清理的软中断仍然是 NET_RX_SOFTIRQ,这是 bug 吗?进入软中断的回调函数 igb_poll 看一下:
static int igb_poll(struct napi_struct *napi, int budget)
{
// 清理发送队列 RingBuf
if (q_vector->tx_ring)
tx_clean_complete = igb_clean_tx_irq(q_vector);
// 接收处理
if (q_vector->rx_ring)
igb_clean_rx_irq_adv(q_vector, &work_done, budget);
}没毛病,确实是在接收软中断中清理了发送队列。
还记得前面那个问题吗?通过 /proc/softirqs 看到的接收软中断要比发送软中断高几个数量级,这里就是第二个原因:发送完成的清理操作发的的接收软中断,而不是发送软中断!
总结
看了这么多,有必要总结下形成更好的记忆。发送一个数据包的过程中,干了这么几件事:
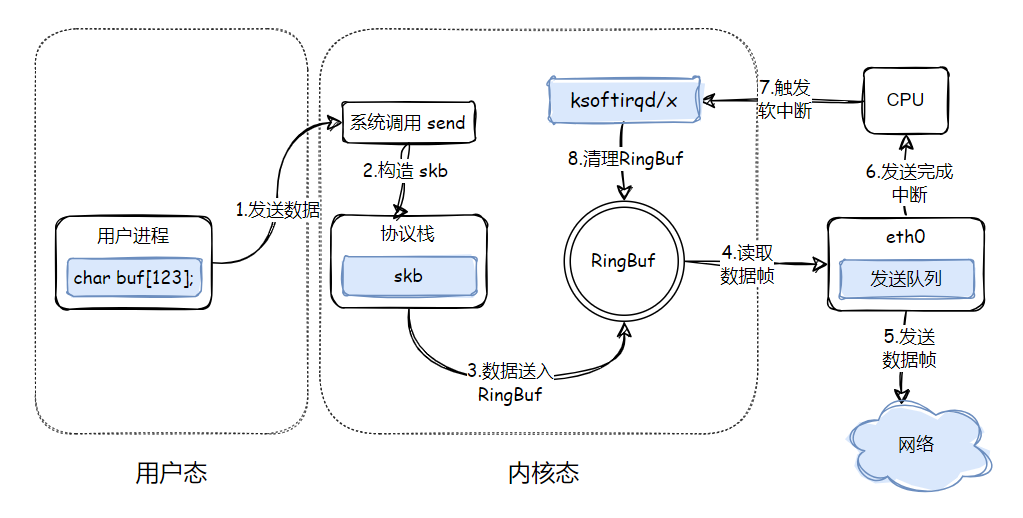
- 用户态调用 send 方法发送数据
- 内核态调用系统调用,sys_sendto 中将 skb 给到 AF_INET 协议族
- 协议族发包方法中根据 socket 类型调用对应的处理方法:对于 tcp 则是 tcp_sndmsg
- tcp_sndmsg 中构造好 skb(拷贝数据),将 skb 加入 socket 发送队列,判断满足发送条件就进行发送
- 对于需要发送的包,还要进一步检查拥塞窗口、流控窗口、nagle 算法是否满足条件,满足条件的才进一步发送给网络层
- 网络层对 skb 进行克隆(拷贝 skb 头),查询路由表,填充 ip 包头,通过 ip_local_out 发送,这里需要经过 netfilter 框架 local_out 点
- 接着还是网络层,查包头中的路由项,找到对应的路由方法 output,在这里需要经过 netfilter 框架的 post_routing 点
- 接着判断 skb 是否需要分片(如果需要分片,会涉及到用户数据的拷贝)
- 随后数据被交给邻居子系统,填充 mac 地址,这里可能需要发送 arp 协议
- 接着数据到达网络设备子系统,选择合适的发送队列进行数据的发送操作
- 大部分的数据包在进程内核态被发送完,占用进程内核态时间。当进程需要被调度出去,触发发送软中断 NET_TX_SOFTIRQ
- 发送软中断中会对剩余的 skb 接着进行发送
- 网卡发送完成,发出硬中断,硬中断触发接收软中断 NET_RX_SOFTIRQ
- 在接收软中断中,完成对 RingBuf 中已发送数据的清理





















![[答疑]《人人都是产品经理》书中的用例图是不是错了](https://img-blog.csdnimg.cn/img_convert/530c763a0edf185537f4938406fbb8a6.png)








![[Flutter]环境判断](https://img-blog.csdnimg.cn/direct/b9443b429608478e8fc7829dc0094626.png)