斯坦福大学客座教授吴恩达(Andrew Ng)© 林志佳
美国斯坦福大学教授吴恩达(Andrew Ng)
人工智能智能体(AI Agents)似乎将引领 AI 行业新的发展趋势。
近日红杉资本(Sequoia)在美国举行的AI Ascent活动上,Sequoia 三位合伙人 Sonya Huang、Pat Grady 以及 Konstantine Buhler 汇集了 100 位领先的 AI 创始人和研究人员,一起探讨了 AI 的机会、现状以及影响等话题。
其中,AI 领域重要人物、斯坦福大学计算机科学系和电气工程系的客座教授、Landing.ai和Coursera联合创始人、Google Brain创建者吴恩达(Andrew Ng)围绕AI Agent话题进行了一场演讲。
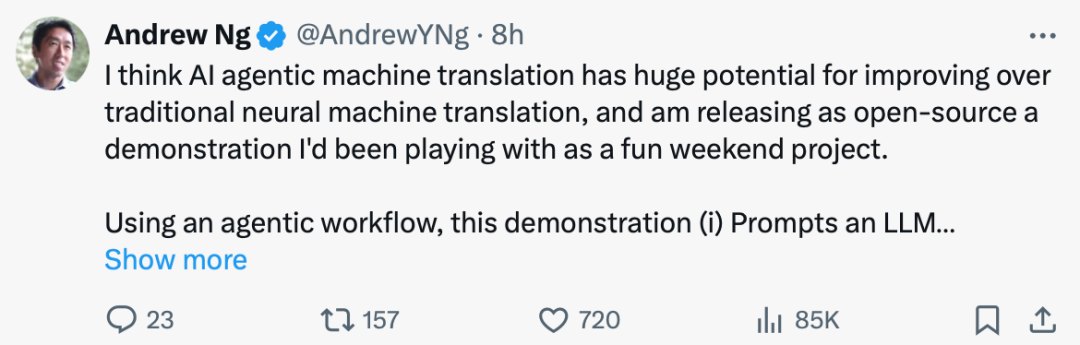
吴恩达表示,AI Agents 代表了人工智能的未来发展方向。输入Prompt 让大模型生成文章,就像让一个人写作,但不能用回退键(删除修改)。AI Agents 的工作方式跟人类更相像。
根据吴恩达分享的数据,你使用 GPT-3.5 进行零样本提示,它的正确率是48%。GPT-4 的表现要好得多,正确率是 67%。但是如果你在 GPT-3.5 的基础上建立一个 AI 智能体的工作流,它甚至能比 GPT-4 做得更好。
换句话说,如果我们现在基于 GPT-4 做一个 AI 智能体的工作流,甚至可以提前到达 GPT-5 的水平。

https://images.tmtpost.com/uploads/images/2024/03/f93c9dfc7bad7946dcd6a16f2a7772f1_1711863471.png© 林志佳
具体来说,吴恩达认为,AI Agents 有四种设计模式:
一、反思(让模型检查和修正自己的输出);
二、工具(调用搜索、代码执行等外部工具);
三、规划(拆解复杂任务,制定执行计划);
四、多 Agent 协作(让模型扮演不同角色,通过协作完成任务)
吴恩达坦言,Agents工作流的出现,语言模型的能力有望在今年得到显著提升。随之而来的是,Token生成速度变得至关重要,甚至比大模型能力提升更重要,甚至还要让模型花更多时间推理和迭代。(大模型要生成大量token来自己阅读和推理,速度越快越好)
吴恩达在演讲中对GPT-5、Claude-5、Gemini2充满期待。
他认为,在Agentic方法加持下,未必要等到最新最强的模型才能体验到交互式AI的威力。“AGI 仍然是一个遥远的目标,但Agentic工作流无疑是通往AGI的重要一步。”
对于未来 AI 的发展,吴恩达提及,一方面,人类会慢慢适应和智能体协作解决任务的新模式,很多任务不再像搜索引擎那样,你输入问题马上得到结果,而是异步的,你给 AI 提供一个任务,然后 AI 会去完成,完成后再通知你,类似于老板和员工的关系;另一方面,AI 智能体的能力也会越来越强,越来越快。
值得注意的是,除了吴恩达之外,此次红杉资本AI Ascent活动中,还邀请了OpenAI 创始成员、前特斯拉 AI 高级总监,AI 大神 Andrej Karpathy;Mistral AI创始人Arthur Mensch;Anthropic 联合创始人兼总裁 Daniela Amodei 等人多位 AI 领域的大咖人物。
其中,Andrej Karpathy的对话内容引起多方关注。他不仅剖析了 OpenAI 背后故事和 AGI 技术发展前景,而且还谈及特斯拉CEO马斯克(Elon Musk)的人格魅力等。
Andrej表示,几年前,AGI 看起来还很遥远,但现在它似乎近在咫尺。目前的发展方向是构建类似“大型语言模型操作系统 (LLMOS)”的平台,它可以连接文本、图像、音频等各种模态,并与现有的软件基础设施相结合。
Andrej透露,OpenAI 正在构建 LLMOS 平台,并可能会提供一些默认应用程序,但这并不意味着其他公司没有机会。Karpathy 认为,就像早期的 iPhone 应用一样,现在人们正在探索 LLM 的功能和局限性,未来将出现一个充满活力的应用生态系统,针对不同领域进行微调。
“我认为在算法方面,我想了很多的一个问题是扩散模型和自回归模型之间的明显区别。它们都是表示概率分布的方法。事实证明,不同的模态显然适合其中之一。我认为可能有一些空间来统一它们,或者以某种方式将它们联系起来。”Andrej表示。
Andrej指出,仅仅拥有资金和计算资源并不足以训练出这些模型,还需要基础设施、算法和数据方面的专业知识。他还强调了完全开源模型的重要性,因为它们允许更深入的定制和改进。
不过,目前,大模型依然面临弥合扩散模型和其他生成模型之间的差距,提高模型运行的能量效率,改进模型的精度和稀疏性等问题,尤其是冯·诺依曼架构具有局限性的。
Andrej坦言,他从马斯克(Elon Musk)的合作中学到了很多东西,包括,保持团队精简、强大和技术性;营造充满活力和高强度的文化氛围;领导者与团队保持紧密联系;以及积极消除瓶颈并快速做出决策。
“我想说,马斯克管理公司的方式非常独特。我觉得人们并没有真正意识到它有多特别。即便是听别人讲,你也很难完全理解。我觉得这很难用语言描述。我甚至都不知道从何说起。但这确实是一种非常独特、与众不同的方式。
用我的话说,他在管理全球最大的创业公司。我觉得我现在也很难描述清楚,这可能需要更长时间来思考和总结。不过首先,他喜欢由实力强大且技术含量高的小团队来组成公司。
在其他公司,发展的过程中团队规模往往会变大。而马斯克则总是反对团队过度扩张。为了招募员工,我不得不做很多努力。我必须恳求他允许我招人。
另外,大公司通常很难摆脱绩效不佳的员工。而马斯克则更愿意主动裁人。事实上,为了留住一些员工,我不得不据理力争,因为他总是默认要裁掉他们。
所以第一点就是,保持一支实力强劲、技术过硬的小团队。绝对不要有那种非技术型的中层管理。这是最重要的一点;第二点则是他如何营造工作氛围,以及当他走进办公室时给人的感觉。
他希望工作环境充满活力。人们四处走动,思考问题,专注于令人兴奋的事物。他们或是在白板上写写画画,或是在电脑前敲代码。他不喜欢一潭死水,不喜欢办公室里没有生机。
他也不喜欢冗长的会议,总是鼓励人们在会议毫无意义时果断离场。你真的能看到,如果你对会议毫无贡献也没有收获,那就可以直接走人,他非常支持这一点。我想这在其他公司是很难见到的。
所以我认为营造积极向上的工作氛围是他灌输的第二个重要理念。也许这其中还包括,当公司变大后,往往会过度呵护员工。而在他的公司不会如此。公司的文化就是你要拿出百分之百的专业能力,工作节奏和强度都很高。
我想最后一点或许是最独特、最有趣也最不寻常的,就是他与团队如此紧密地联系在一起。
通常一个公司的CEO是一个遥不可及的人,管理着5层下属,只和副总裁沟通,副总裁再和他们的下属主管沟通,主管再和经理层沟通,你只能和直属上司对话。但马斯克经营公司的方式完全不同。他会亲自来到办公室,直接与工程师交谈。
我们开会时,会议室里经常是50个人和马斯克面对面,他直接跟工程师对话。他不想只是和副总裁、主管们说话。
通常一个CEO会把99%的时间花在和副总裁沟通上,而他可能有50%的时间在和工程师交流。所以如果团队规模小且高效,那么工程师和代码就是最可信的信息源。他们掌握第一手的真相。马斯克要直接和工程师交流,以了解实际情况,讨论如何改进。
所以我想说,他与团队联系紧密,而不是遥不可及,这一点非常独特。
此外,他在公司内部行使权力的方式也不同寻常。比如如果他与工程师交谈,了解到一些阻碍项目进展的问题。比如工程师说,“我没有足够的GPU来运行程序”,他会记在心里。如果他两次听到类似的抱怨,他就会说:“好,这是个问题。那现在的时间表是什么?什么时候能解决?”
如果得不到满意的答复,他会说,“我要和GPU集群的负责人谈谈”,然后有人就会打电话给那个负责人,他会直截了当地说:“现在就把集群容量翻一倍。从明天开始每天向我汇报进展,直到集群规模扩大一倍。”
对方可能会推脱说还要经过采购流程,需要6个月时间之类的。这时马斯克就会皱起眉头,说:“好,我要和黄仁勋谈谈。”然后他就会直接铲除项目障碍。
所以我认为大家并没有真正意识到他是如何深度参与各项工作,扫清障碍,施加影响力的。
老实说,离开这样的环境去一家普通公司,你真的会想念这些独特的地方。”Andrej表示。
Andrej还鼓励创业者,认为CEO首先专注于构建性能最佳的模型,然后再考虑降低成本;其次,积极分享经验和知识,促进生态系统的健康发展;最后,创业者需要关注,如何帮助初创公司在与大科技公司的竞争中取得成功。
“通向AGI 的道路更像是一段旅程,而不是一个目的地,但我认为这种智能体工作流可能帮助我们在这个非常长的旅程上迈出一小步。”吴恩达在演讲结尾表示。

https://images.tmtpost.com/uploads/images/2024/03/287070b1db726f6bd120c3a51b6c91ae_1711863472.png© 林志佳
以下是吴恩达的演讲全文,由@baoyu.io进行翻译整理,钛媒体App编辑进行部分人工修正:
我期待与大家分享我在 AI 智能体方面的发现,我认为这是一个令人兴奋的趋势,所有涉及 AI 开发的人都应该关注。同时,我也对所有即将介绍的"未来趋势"充满期待。
所以,让我们来谈谈 AI 智能体。
现在,我们大多数人使用大语言模型的方式就像这样,通过一个无智能体的工作流程,我们输入一段提示词,然后生成一段答案。这有点像你让一个人编写一篇关于某个主题的文章,我说你只需要坐在键盘前,一气呵成地把文章打出来,就像不允许使用退格键一样。尽管这项任务非常困难,但大语言模型的优秀表现却令人惊讶。
与此相对,一个有 AI 智能体的工作流可能是这样的。让 AI 或者大语言模型写一篇文章的提纲。需要在网上查找一些东西吗?如果需要,那就去查。然后写出初稿,并阅读你自己写的初稿,思考哪些部分需要修改。然后修改你的初稿,然后继续前进。所以这个工作流是迭代的,你可能会让大语言模型进行一些思考,然后修改文章,再进行一些思考,如此反复。很少有人意识到,这种方式的结果更好。这些 AI 智能体的工作流程的效果让我自己都感到惊讶。
我要做一个案例研究。我的团队分析了一些数据,用的是一个名为"人类评估基准"的编程基准,这是 OpenAI 几年前发布的。这个基准包含一些编程问题,比如给出一个非空的整数列表,求出所有奇数元素或者奇数位置上的元素之和。答案可能是这样一段代码片段。现在,我们很多人会使用零样本提示,意思是我们告诉 AI 写代码,然后让它一次就运行。谁会这样编程?没有人会这样。我们只是写下代码然后运行它。也许你会这样做。我做不到。
所以事实上,如果你使用 GPT 3.5 进行零样本提示,它的正确率是 48%。GPT-4 的表现要好得多,正确率是 67%。但是,如果你在 GPT 3.5 的基础上建立一个 AI 智能体的工作流,它甚至能比 GPT-4 做得更好。如果你将这种工作流应用于 GPT-4,效果也非常好。你会注意到,带有 AI 智能体工作流的 GPT 3.5 实际上优于 GPT-4。这意味着这将对我们构建应用程序的方式产生重大影响。
AI 智能体这个术语被广泛讨论,有很多咨询报告讨论关于 AI 智能体,AI 的未来等等。我想更实质性地与你分享我在 AI 智能体中看到的一些常见设计模式。这是一个复杂混乱的领域,有大量的研究,大量的开源项目。有很多东西正在进行。但我试图更贴切地概述 AI 智能体的现状。
反思是我认为我们大多数人应该使用的一个工具。它确实很有效。我认为它应该得到更广泛的应用。这确实是一种非常稳健的技术。当我使用它们时,我总能让它们正常工作。至于规划和多智能体协作,我认为它是一个新兴的领域。当我使用它们时,有时我会对它们的效果感到惊讶。但至少在此刻,我不能确定我总是能让它们稳定运行。所以让我在接下来的几页幻灯片中详细介绍这四种设计模式。如果你们中有人回去并亲自尝试,或者让你们的工程师使用这些模式,我认为你会很快看到生产力的提升。
所以,关于反思,这是一个例子。比如说,我要求一个系统为我编写一项任务的代码。然后我们有一个编程智能体,只需给它一个编码任务的提示,比如说,定义一个执行任务的函数,编写一个这样的函数。一个自我反思的例子就是,你可以这样对大语言模型进行提示。这是一段为某个任务编写的代码。然后把它刚生成的完全一样的代码再呈现给它。然后让它仔细检查这段代码是否正确、高效且结构良好,像这样提出问题。结果显示,你之前提示编写代码的同一大语言模型可能能够发现像第五行的 bug 这样的问题,并修复它。等等。如果你现在把它自己的反馈再次呈现给它,它可能会创作出版本二的代码,这个版本可能比第一个版本表现得更好。虽然不能保证,但是在大多数情况下,这种方法在许多应用中值得尝试。提前透露一下,如果你让它运行单元测试,如果它没有通过单元测试,那么你可以询问它为什么没有通过单元测试?进行这样的对话,也许我们可以找出原因,没能通过单元测试,所以你应该尝试改变一些东西,然后生成 V3 版本的代码。顺便说一句,对于那些想要了解更多关于这些技术的人,我对这些技术感到非常兴奋。对于讲解的每个部分,我都在底部附有一些推荐阅读的资料,希望能提供更多的参考。
再次预一下多智能体系统,我描述的是一个编程智能体,你可以提示它和自己进行这样的对话。这个想法的一个自然演变就是,不只有一个编程智能体,你可以设定两个智能体,一个是编程智能体,另一个是评审智能体。这些都可能基于同一款大语言模型,只是我们提供的提示方式不同。我们对一方说,你是编程专家,请写代码。对另一方我们会说,你是代码审查专家,请审查这段代码。实际上,这样的工作流程非常便于实施。我认为这是一种非常通用的技术,能够适应各种工作流程。这将显著提升大语言模型的性能。
第二种设计模式是使用工具。你们中的许多人可能已经看到过基于大语言模型的系统如何使用工具。左边是来自副驾驶的截图,右边是我从 GPT-4 中提取的部分内容。然而,如果你让今天的大语言模型去回答网页搜索中哪款复印机最好这样的问题,它会生成并运行代码。实际上,有很多不同的工具,被许多人用来进行分析,收集信息,采取行动,提高个人效率。
早期在工具使用方面的研究,大部分来自计算机视觉社区。因为在大语言模型出现之前,它们无法处理图像。所以,唯一的选择就是让大语言模型生成一个可以操作图像的函数,比如生成图像或者进行物体检测等。因此,如果你仔细研究相关文献,你会发现很多工具使用的研究看似起源于视觉领域,因为在 GPT-4 和 LLaVA 等出现之前,大语言模型对图像一无所知。这就是工具的使用,它扩大了大语言模型的应用范围。
接下来是规划。对于那些还未深入研究规划算法的人,我觉得很多人都会谈到 ChatGPT 的震撼时刻,那种前所未有的感觉。我觉得你们可能还没有使用过规划算法。有很多人会感叹,哇,我没想到 AI 智能体能做得这么好。我曾经进行过现场演示,当某件事情失败了,AI 智能体会重新规划路径来规避失败。事实上,已经有好几次我被自己的 AI 系统的自主能力所震惊了。
我曾经从一篇关于 GPT 模型的论文中改编过一个例子,你可以让它生成一张女孩正在读书的图片,与图片中的男孩姿势一致,例如,example.jpeg,然后它会描述新图片中的男孩。利用现有的 AI 智能体,你可以决定首先确定男孩的姿势,然后找到合适的模型,可能在 HuggingFace 这个平台上,来提取姿势。接下来,你需要找到一个后处理图像的模型,合成一张根据指令的女孩的图片,然后使用图片转化为文本,最后使用文本转化为语音的技术。
目前,我们有一些 AI 智能体,虽然它们并不总是可靠,有时候会有些繁琐,不一定能成功,但是一旦它们成功了,效果是相当惊人的。有了这种智能体循环的设计,有时候我们甚至可以从之前的失败中恢复过来。我发现我已经开始在一些工作中使用这样的研究型智能体,我需要一些研究,但是我并不想自己去搜索,花费大量的时间。我会将任务交给研究型智能体,过一会儿再回来看它找到了什么。有时候它能找到有效的结果,有时候则不行。但无论如何,这已经成为我个人工作流程的一部分了。
最后一个设计模式是多智能体协作。这个模式可能看起来有些奇怪,但实际效果比你想象的要好得多。左边是一篇名为"Chat Dev"的论文的截图,这个项目是完全开放的,实际上已经开源了。许多人可能见过那些炫耀的社交媒体发布的"Devin"的演示,在我的笔记本电脑上也可以运行"Chat Dev"。"Chat Dev"是一个多智能体系统的例子,你可以设置一个大语言模型(LLM)去扮演软件工程公司的 CEO、设计师、产品经理,或者测试员等角色。你只需要告诉 LLM,你现在是 CEO,你现在是软件工程师,然后它们就会开始协作,进行深入的对话。如果你告诉它们去开发一个游戏,比如 GoMoki 游戏,它们会花几分钟来编写代码,测试,迭代,然后生成出惊人的复杂程序。虽然并不总是成功,我也遇到过失败的情况,但有时它的表现让人惊叹,而且这个技术正在不断进步。另外,另一种设计模式是让不同的智能体辩论,你可以有多个不同的智能体,比如 ChatGPT 和 Gemini 进行辩论,也是一种有效提升性能的模式。所以,让多个模拟的 AI 智能体协同工作,已经被证明是一个非常强大的设计模式。
总的来说,这些就是我观察到的设计模式,我认为如果我们能在工作中应用这些模式,我们可以更快地提升 AI 效果。我相信智能体推理设计模式将会是一个重要的发展方向。
这是我的最后一张幻灯片。我预计,人工智能能做的任务将在今年大幅度扩展,这是由于智能体工作流的影响。有一点人们可能难以接受的是,当我们向 LLM 发送提示词时,我们希望马上得到回应。实际上,十年前我在谷歌进行的一项名为"大盒子搜索"的讨论中,我们输入很长的提示词。我当时未能成功推动这一点,因为当你进行网络搜索时,你希望在半秒钟内得到回应,这是人性。我们喜欢即时的反馈。但是对于很多智能体工作流程,我认为我们需要学会将任务委派给 AI 智能体,并且耐心等待几分钟,甚至可能需要等待几个小时来获取回应。就像我看到的许多新手经理,他们将任务委派给别人,然后五分钟后就去查看情况,这并不高效,我们也需要对一些 AI 智能体这样做,尽管这非常困难。我以为我听到了一些笑声。
另外,快速生成 token 是一个重要的趋势,因为我们在不断迭代这些智能体工作流程。LLM 为自己阅读生成 token,能够比任何人都快速生成 token 更棒。我认为,甚至来自稍微质量低点的 LLM,也能快速生成更多的 token,可能会得到好的结果,相比之下,从质量更好的 LLM 中慢速生成 token,也许会不尽如人意。这个观点可能会引起一些争议,因为它可能让你在这个过程中多转几圈,就像我在第一张幻灯片上展示的 GPT-3 和智能体架构的结果一样。
坦率地说,我非常期待 Claude 4,GPT-5,Gemini 2.0, 以及正在建设中的所有其他精彩模型。在我看来,如果你期待在 GPT-5 零样本学习上运行你的项目,你可能会发现,通过在早期模型上使用智能体和推理,你可能比预期更早地接近 GPT-5 性能水平。我认为这是一个重要的趋势。
诚实地说,通向通用人工智能的道路更像是一段旅程,而不是一个目的地,但我认为这种智能体工作流可能帮助我们在这个非常长的旅程上迈出一小步。
谢谢。