DuckDB 中的外部聚合
大多数分组聚合查询仅生成几个输出行。 例如,“过去十年中有多少航班从每个欧洲首都出发?”为每个欧洲首都生成一行,即使包含所有航班信息的表有数百万行也是如此。 情况并非总是如此,因为“每个客户在过去十年中下了多少个订单?”为每个客户生成一行,可能是数百万个,这大大增加了查询的内存消耗。 但是,即使聚合不适合内存,DuckDB 仍然可以完成查询。
前言
与大多数数据库系统(即服务器)不同,DuckDB 用于各种环境,这些环境可能没有太多内存。 但是,某些数据库查询(如具有许多唯一组的聚合)需要大量内存。 我写这篇文章的笔记本电脑有 16 GB 的 RAM。 如果查询需要 20 GB,该怎么办? 如果发生这种情况:
Out of Memory Error: could not allocate block of size X (Y/Z used)
查询将中止。 可悲的是,我们无法下载更多RAM。 但幸运的是,这款笔记本电脑还具有 1 TB 存储空间的快速 SSD。 在许多情况下,我们不需要将所有 20 GB 的数据同时存储在内存中,我们可以暂时将一些数据存储在存储中。 如果我们在需要时将其加载回去,我们仍然可以完成查询。 我们必须谨慎使用存储,因为尽管现代 SSD 速度很快,但它们仍然比内存慢得多。
一、内存管理
大多数数据库系统将持久性数据存储在“页面”上。 根据要求,可以从存储中的数据库文件中读取这些页面,放入内存中,并在必要时再次写回。 通常的智慧是使所有页面大小相同:这允许交换页面并避免内存和存储碎片。 启动数据库时,会为这些页面分配和保留一部分内存,称为“缓冲池”。 负责管理缓冲池的数据库组件恰如其分地称为“缓冲区管理器”。
剩余内存保留用于短期内存分配,即临时内存分配,例如用于聚合的哈希表。 这些分配以不同的方式完成,这很好,因为如果有许多独特的组,哈希表可能需要非常大,因此我们无论如何都无法使用固定大小的页面。 如果我们的临时数据多于内存中的数据,那么像聚合这样的运算符必须决定何时有选择地将数据写入存储中的临时文件。
…至少,这是传统的做事方式。 这对 DuckDB 来说意义不大。 为什么我们要以如此不同的方式管理持久性和临时性数据? 区别在于持久性数据应该持久化,而临时数据不应该持久化。 为什么缓冲区管理器不能同时管理两者?
DuckDB 的缓冲区管理器不是传统的。 大多数持久性和临时性数据存储在固定大小的页面上,并由缓冲区管理器管理。 缓冲区管理器会尝试充分利用您的内存。 这意味着我们不会为缓冲池保留一部分内存。 这允许 DuckDB 将所有内存用于持久性数据,而不仅仅是一部分(如果这最适合您的工作负载)。 如果您正在执行需要大量内存的大型聚合,DuckDB 可以从内存中逐出持久数据,以释放大型哈希表的空间。
由于 DuckDB 的缓冲区管理器管理所有内存,包括持久数据和临时数据,因此在选择何时将临时数据写入存储时,它比聚合等运算符要好得多。 将卸载的责任留给缓冲区管理器也节省了我们在每个需要处理不适合内存的数据的操作员中实现对临时文件的读取和写入数据的工作量。
为什么其他数据库系统中的缓冲区管理器不管理临时数据? 有两个问题:内存碎片和无效引用。
内存碎片
查询运算符中使用的哈希表和其他数据结构不像用于持久性数据的页面那样具有固定大小。 我们也不希望内存中漂浮着大量大小可变的页面,以及固定大小的页面,因为这会导致内存碎片。
理想情况下,我们会对所有内存分配使用固定大小,但这不是一个好主意:有时,处理查询的最有效方法需要分配,例如,一个大数组。 因此,我们决定对几乎所有的分配使用固定大小。 这些短期分配在使用后会立即解除分配,这与永久数据的固定大小页面不同,后者是保留的。 这些分配不会导致彼此之间的碎片,因为 DuckDB 在可能的情况下用于分配内存的 jemalloc 使用大小类对分配进行分类,并为它们维护单独的领域。
无效引用
临时数据通常不能按原样写入存储,因为它通常包含指针。 例如,DuckDB 实现了 Umbra 提出的字符串类型,该类型具有固定的宽度。 长度超过 12 个字符的字符串不存储在字符串类型中,而是存储在其他位置,而是存储指向此“其他位置”的指针。
当我们想要将数据卸载到存储时,这会产生一个问题。 假设存储长度超过 12 个字符的字符串的“其他地方”是缓冲区管理器可以随时卸载到存储以释放一些内存的页面之一。 如果页面被卸载然后重新加载,则它很可能会加载到内存中的其他地址中。 指向长字符串的指针现在无效,因为它们仍然指向上一个地址!
写入包含存储指针的数据的常用方法是先序列化它。 当它读回内存时,必须再次反序列化。(反)序列化可能是一项昂贵的操作,因此存在像 Arrow Flight 这样的数据格式,它们试图将成本降至最低。 但是,我们不能在这里使用 Arrow,因为 Arrow 是列优先布局,但行优先布局对于哈希表更有效。
我们可以创建一个 Arrow Flight 的行主要版本,但我们可以完全避免(反)序列化: 我们创建了一个专门的行优先页面布局,该布局实际上使用旧的无效指针在将数据读回内存后重新计算新的有效指针。
页面布局将固定大小的行和可变大小的数据(如字符串)放在单独的页面上。 查询的行大小是固定的:发出 SQL 查询后,DuckDB 会创建并执行查询计划。 因此,甚至在执行上述计划之前,我们已经知道我们需要哪些列、它们的类型以及这些类型的宽度。
如下图所示,需要少量的“元数据”来重新计算指针。 固定大小的行存储在“行页面”中,可变大小的行存储在“Var Pages”中。
请记住,固定大小的行中有指向可变大小数据的指针。 元数据描述哪些固定大小的行指向哪个 Var Page 以及 Var Page 的最后一个已知地址。 例如,元数据 1 描述了存储在行页 1 中偏移量为 0 的 5 行,变量大小的数据存储在地址为 的 Var 页 1 中。0x42
假设缓冲区管理器决定卸载 Var Page 1。 当我们再次请求 Var Page 1 时,它会加载到地址 . 这 5 行中的指针现在无效。 例如,其中一行包含指针 ,这意味着它以偏移量存储在 Var Page 1 中。 我们可以通过将偏移量添加到页面的新地址来重新计算指针:。 指针重新计算是针对字符串存储在同一行和变量页上的行进行的,因此每次行页或变量页已满时,我们都会创建一个新的元数据。0x5000x480x48 - 0x42 = 60x500 + 6 = 0x506
指针重新计算相对于(反)序列化的优势在于可以延迟完成。 我们可以通过将 MetaData 中的指针与指向页面的当前指针进行比较来检查 Var Page 是否已卸载。 如果指针相同,则不必重新计算指针。
外部聚合
现在我们已经弄清楚了如何处理临时数据,现在终于到了谈论哈希聚合的时候了。 第一个重大挑战是并行执行聚合。
DuckDB 使用 Morsel-Driven Parallelism 并行化查询执行,这实质上意味着查询运算符(如聚合)必须具有并行性感知能力。 这与计划驱动的并行性不同,后者使操作员无法意识到并行性。
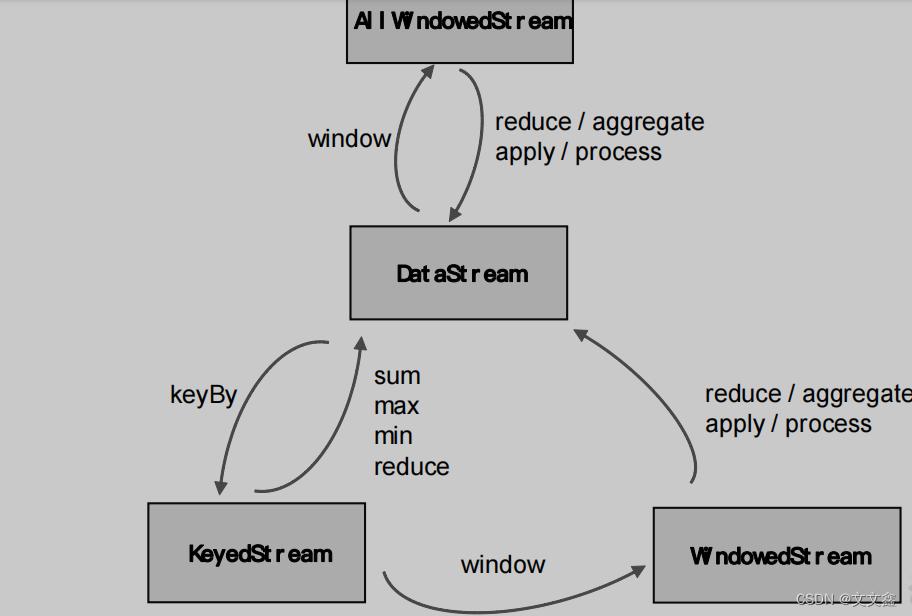
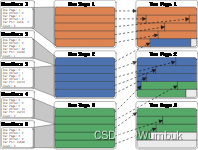
简要总结一下我们关于聚合的第一篇博文:在 DuckDB 中,所有活动线程都有自己的线程本地哈希表,它们将输入数据放入其中。 这将使线程保持忙碌状态,直到读取所有输入数据。 多个线程的哈希表中可能具有完全相同的组。 因此,必须组合线程本地哈希表才能完成分组聚合。 这可以通过对哈希表进行分区并分配每个线程来合并来自每个分区的数据来并行完成。 在大多数情况下,我们仍然使用相同的方法。 您将在下图中看到这一点,它说明了我们的新实现。
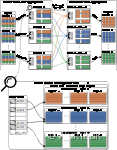
我们称第一阶段为线程本地预聚合。 输入数据是小块,大约有 100,000 行。 它们被分配给活动线程,这些线程将它们沉入其线程本地哈希表中,直到读取所有输入数据。 我们使用线性探测来解决碰撞,并使用盐来减少处理所述碰撞的开销。 这在我们的第一篇关于聚合的博客文章中进行了解释,因此我在这里不再重复。
现在我们已经解释了什么没有改变,我们可以谈谈什么已经改变了。 与上次相比,第一个区别是我们分区的方式。 例如,以前,如果我们有 32 个线程,则每个线程将创建 32 个哈希表,每个分区一个。 这总共有 1024 个哈希表,当更多线程处于活动状态时,这些哈希表无法很好地扩展。 现在,每个线程都有一个哈希表,但每个哈希表中的数据都是分区的。 数据也存储在我们之前介绍的专用页面布局中,以便可以轻松地将其卸载到存储中。
第二个区别是,在线程本地预聚合期间,哈希表的大小不会调整。 我们保持哈希表的大小较小,从而减少了此阶段的缓存未命中量。 这意味着哈希表在某个时候会满。 当它已满时,我们重置它并重新开始。 我们可以这样做,因为我们将在第二阶段稍后完成聚合。 当我们重置哈希表时,我们会“取消固定”存储实际数据的页面,这会告诉我们的缓冲区管理器,它可以在需要释放内存时将它们写入存储。
这两项更改共同导致第一阶段的内存需求较低。 每个线程只需要在内存中保留一个小哈希表。 我们可能会通过多次填充哈希表来收集大量数据,但如果需要,缓冲区管理器可以卸载几乎所有数据。
对于第二阶段,分区聚合,交换线程本地分区数据,每个线程将单个分区的数据合并到哈希表中。 这个阶段与以前基本相同,只是我们现在有时创建的分区比线程多得多。 为什么?一个分区的哈希表可能适合内存,但 8 个线程可以同时组合一个分区,我们可能无法在内存中容纳 8 个分区。 这个问题的简单解决方案是过度分区。 如果我们创建的分区多于线程,例如,32 个分区,则分区的大小会更小,并且 8 个线程将同时合并 32 个分区中的 8 个,这几乎不需要那么多的内存
实验
仅生成几个唯一组的聚合可以很容易地放入内存中。 为了评估我们的外部哈希聚合实现,我们需要具有许多唯一组的聚合。 为此,我们将使用类似数据库的 H2O.ai 操作基准测试,我们已经复活了该基准测试,现在正在维护该基准测试。 具体来说,我们将使用未压缩的 50 GB 文件。 H2O.ai 基准测试的源代码可以在这里找到。 您可以从 https://blobs.duckdb.org/data/G1_1e9_2e0_0_0.csv.zst 自行下载文件(压缩 18.8 GB)。G1_1e9_2e0_0_0.csv.zst
我们使用来自基准测试的以下查询来加载数据:
SET preserve_insertion_order = false;
CREATE TABLE y (
id1 VARCHAR, id2 VARCHAR, id3 VARCHAR,
id4 INT, id5 INT, id6 INT, v1 INT, v2 INT,
v3 FLOAT);
COPY y FROM 'G1_1e9_2e0_0_0.csv.zst' (FORMAT CSV, AUTO_DETECT true);
CREATE TYPE id1ENUM AS ENUM (SELECT id1 FROM y);
CREATE TYPE id2ENUM AS ENUM (SELECT id2 FROM y);
CREATE TABLE x (
id1 id1ENUM, id2 id2ENUM, id3 VARCHAR,
id4 INT, id5 INT, id6 INT, v1 INT, v2 INT,
v3 FLOAT);
INSERT INTO x (SELECT * FROM y);
DROP TABLE IF EXISTS y;
H2O.ai 聚合基准由 10 个查询组成,这些查询的唯一组数量各不相同:
-- Query 1: ~100 unique groups
CREATE OR REPLACE TABLE ans AS
SELECT id1, sum(v1) AS v1
FROM x
GROUP BY id1;
-- Query 2: ~10,000 unique groups
CREATE OR REPLACE TABLE ans AS
SELECT id1, id2, sum(v1) AS v1
FROM x
GROUP BY id1, id2;
-- Query 3: ~10,000,000 unique groups
CREATE OR REPLACE TABLE ans AS
SELECT id3, sum(v1) AS v1, avg(v3) AS v3
FROM x
GROUP BY id3;
-- Query 4: ~100 unique groups
CREATE OR REPLACE TABLE ans AS
SELECT id4, avg(v1) AS v1, avg(v2) AS v2, avg(v3) AS v3
FROM x
GROUP BY id4;
-- Query 5: ~1,000,000 unique groups
CREATE OR REPLACE TABLE ans AS
SELECT id6, sum(v1) AS v1, sum(v2) AS v2, sum(v3) AS v3
FROM x
GROUP BY id6;
-- Query 6: ~10,000 unique groups
CREATE OR REPLACE TABLE ans AS
SELECT
id4,
id5,
quantile_cont(v3, 0.5) AS median_v3,
stddev(v3) AS sd_v3
FROM x
GROUP BY id4, id5;
-- Query 7: ~10,000,000 unique groups
CREATE OR REPLACE TABLE ans AS
SELECT id3, max(v1)-min(v2) AS range_v1_v2
FROM x
GROUP BY id3;
-- Query 8: ~10,000,000 unique groups
CREATE OR REPLACE TABLE ans AS
SELECT id6, v3 AS largest2_v3
FROM (
SELECT id6, v3, row_number() OVER (
PARTITION BY id6
ORDER BY v3 DESC) AS order_v3
FROM x
WHERE v3 IS NOT NULL) sub_query
WHERE order_v3 <= 2;
-- Query 9: ~10,000 unique groups
CREATE OR REPLACE TABLE ans AS
SELECT id2, id4, pow(corr(v1, v2), 2) AS r2
FROM x
GROUP BY id2, id4;
-- Query 10: ~1,000,000,000 unique groups
CREATE OR REPLACE TABLE ans AS
SELECT id1, id2, id3, id4, id5, id6, sum(v3) AS v3, count(*) AS count
FROM x
GROUP BY id1, id2, id3, id4, id5, id6;
基准测试页面上的结果是使用 AWS EC2 实例获取的。 在这种情况下,所有查询都可以轻松放入内存中,并且拥有许多线程也不会损害性能。 DuckDB 只需 8.58 秒即可完成最大的查询 10,该查询返回 10 亿个唯一组。 然而,许多人不会使用如此强大的机器来处理数字。 在我的笔记本电脑(2020 款 MacBook Pro)上,一些较小的查询将适合内存,例如查询 1,但查询 10 肯定不适合。c6id.metal
结论
DuckDB 正在不断改进其超大于内存的查询处理能力。 在这篇博文中,我们展示了 DuckDB 用于从存储中溢出和加载数据的一些技巧。 这些技巧是在 DuckDB 的外部哈希聚合中实现的,该聚合从 0.9.0 开始发布。 我们在 H2O.ai 基准测试中进行了哈希聚合,DuckDB 可以在只有 16 GB 内存的笔记本电脑上完成所有 50 GB 的查询。