> 作者:დ旧言~
> 座右铭:松树千年终是朽,槿花一日自为荣。> 目标:手撕哈希表的闭散列和开散列
> 毒鸡汤:谁不是一边受伤,一边学会坚强。
> 专栏选自:C嘎嘎进阶
> 望小伙伴们点赞👍收藏✨加关注哟💕💕

🌟前言
我们已经模拟实现了哈希表,当然需要用哈希表来封装相关容器,最初的map和set封装是用红黑树,所以我们就不再封装了map和set,来封装它们的同胞兄弟unordered_map与unordered_set。对比前面map和set的封装还是比较简单的,咱们走起吧!!!
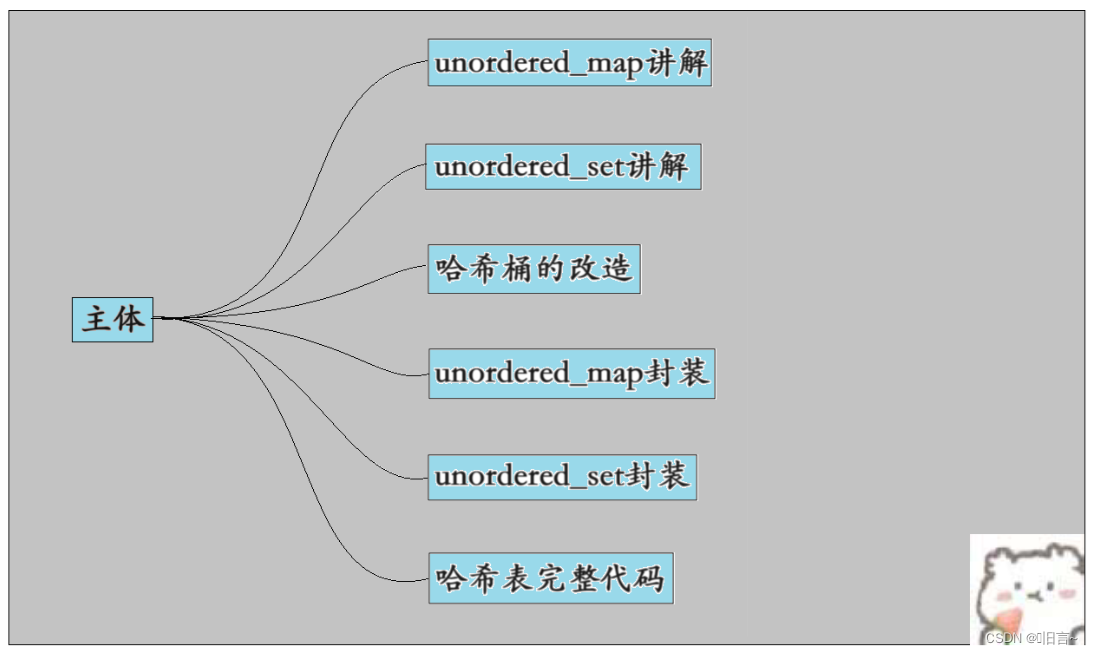
⭐主体
学习开散列实现unordered_map与unordered_set的封装咱们按照下面的图解:
🌙unordered_map讲解
概念:
unordered_map其实就是与map相对应的一个容器。学过map就知道,map的底层是一个红黑树,通过中序遍历的方式可以以有序的方式遍历整棵树。而unordered_map,正如它的名字一样,它的数据存储其实是无序的,这也和它底层所使用的哈希结构有关。而在其他功能上,unordered_map和map基本上就是一致的。
特点:
- unordered_map是用于存储<key, value>键值对的关联式容器,它允许通过key快速的索引到对应的value。
- 在内部,unorder_map没有对<key, value>按照任何特定的顺序排序,为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的<key, value>键值对放在相同的桶中。
- unordered_map容器的搜索效率比map快,但它在遍历元素自己的范围迭代方面效率就比较低。
- 它的迭代器只能向前迭代,不支持反向迭代。
拓展:
从大结构上看,unordered_map和map的模板其实没有太大差距。学习了map和set我们就应该知道,map是通过T来告诉红黑树要构造的树的存储数据类型的,unordered_map也是一样的,但是它的参数中多了Hash和Pred两个参数,这两个参数都传了仿函数,主要和哈希结构有关。
使用:
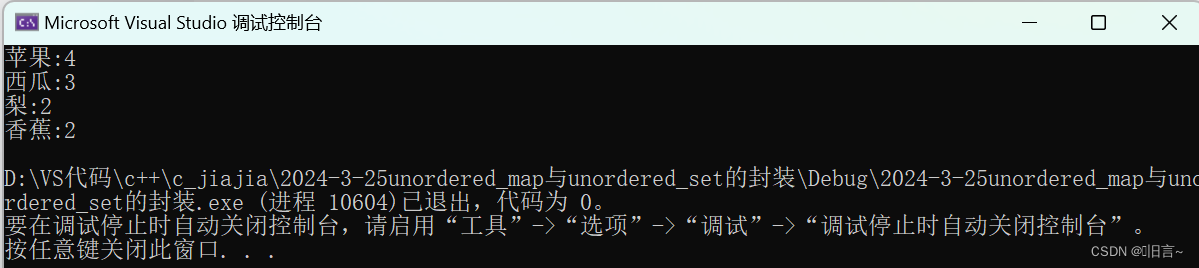
统计水果个数:
int main() { string arr[] = { "西瓜","西瓜", "苹果", "梨", "苹果", "香蕉", "苹果", "梨", "香蕉", "苹果", "西瓜" }; unordered_map<string, int> count; for (auto& e : arr) { count[e]++; } for (auto e : count) { cout << e.first << ":" << e.second << endl; } return 0; }
🌙unordered_set讲解
概念:
unordered_set其实也是一样的,从功能上来看和set并没有什么区别,只是由于地层数据结构的不同,导致unordered_set的数据是无序的,但是查找效率非常高。
特点:
- 无序性:unordered_set中的元素没有特定的顺序,不会根据插入的顺序或者元素的值进行排序。
- 唯一性:unordered_set中的元素是唯一的,不允许重复的元素。
- 快速查找:unordered_set使用哈希表实现,可以在平均常数时间内进行查找操作,即使在大型数据集上也能保持高效。
- 插入和删除效率高:unordered_set的插入和删除操作的平均时间复杂度为常数时间,即O(1)。
- 高效的空间利用:unordered_set使用哈希表来存储元素,不会浪费额外的空间。
- 不支持修改操作:由于unordered_set中的元素是唯一的,不支持直接修改元素的值,需要先删除旧值,再插入新值。
- 迭代器失效:在进行插入和删除
拓展:
unordered_set相较于set,多了Hash和Pred两个参数。这两个参数都是传了仿函数,和unordered_map与map之间的关系都是一样的。
使用:
存储整数:
int main() { unordered_set<int> v; v.insert(7); v.insert(2); v.insert(3); v.insert(5); v.insert(4); v.insert(8); v.insert(7); unordered_set<int>::iterator it = v.begin(); while (it != v.end()) { cout << *it << " "; it++; } cout << endl; return 0; }

🌙哈希桶的改造
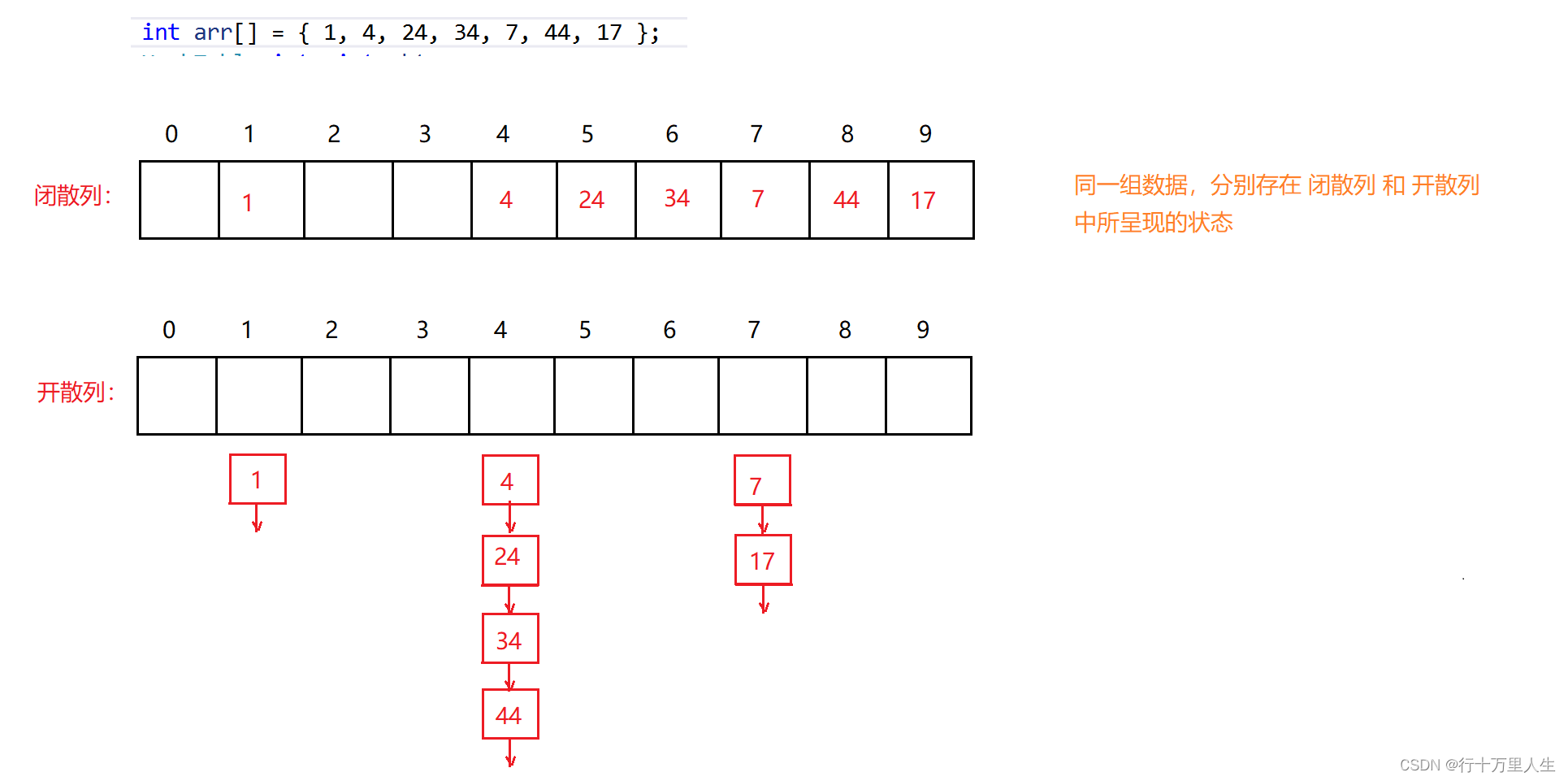
可以我们原先的哈希桶的写法,这里我们只改造开散列:【C++】手撕哈希表的闭散列和开散列
💫结构修改
步骤:
首先,这里实现的哈希桶需要能够同时支持unordered_map和unordered_set的调用。因此,在传入的数据中就需要有一个T,来标识传入的数据类型。同时,还需要有Hash函数和KeyOfT来分别对传入的数据转换为整形和获取传入数据的key值,主要是提供给使用了KV模型的数据。
其次,哈希桶其实是保存在一个顺序表中的,每个下标对应的位置上都是桶的头节点,每个桶中的数据以单链表的方式链接起来。因此,我们就需要一个vector来存储结构体指针,这个结构体中包含了当前节点存储的数据和下一个节点的位置。当然,还有有一个_n来记录顺序表中数据的个数。
代码:
//开散列
namespace hash_bucket
{
// 定义结点
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{}
};
// 哈希表
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash >
//友元 使 __HashIterator中可以调用HashTable的私有
friend struct __HashIterator;
typedef HashNode<T> Node;
public:
typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> iterator;
typedef __HashIterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;
private:
vector<Node*> _tables; //指针数组
size_t _n = 0; //存储数据有效个数
};
}注意:
哈希桶hash_bucket中
需要将其内部的 HashNode 的参数进行修改
将原来的模板参数 K,V 改为 T
同样由于不知道传入数据的是K还是K V类型的 ,所以 使用 T 类型的data代替
之前实现的模板参数 K ,V分别代表 key 与value
修改后 , 第一个参数 拿到单独的K类型,是为了 使用 Find erase接口函数的参数为K
第二个参数 T 决定了 拿到的是K类型 还是 K V 类型
上面的代码中有一个迭代器的重命名和迭代器结构体的友元声明。重命名是为了方便后续的使用。友元声明则和迭代器的实现有关,这里先不过多讲解。
💫构造函数
代码如下:
// 析构函数
~HashTable()//析构
{
for (auto& cur : _tables)
{
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
cur = nullptr;
}
}💫插入函数
步骤:
在插入时,首先要先查看哈希桶中是否存在相同键值,存在就直接返回当前位置。第二步就是要查看哈希桶中的元素个数与哈希桶的容量之间的负载因子,如果等于1,就需要进行扩容。第三步则是开始插入节点。先找到映射位置,然后新建一个节点连接到对应的数组下标的空间中即可。
注意:
insert()函数返回的是pair<iterator, bool>,这是为了后续实现 [ ] 重载做准备。
代码:
// 插入元素
pair<iterator, bool> insert(const T& data)//插入
{
KeyOfT kot;
//若对应的数据已经存在,则插入失败
iterator it = Find(kot(data));
if (it != end())
{
return make_pair(it, false);
}
Hash hash;
//负载因子==1时扩容
if (_n == _tables.size())
{
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
// 创建 newsize个数据,每个数据都为空
vector<Node*>newtables(newsize, nullptr);
for (auto& cur : _tables)
{
while (cur)
{
//保存下一个旧表节点
Node* next = cur->_next;
size_t hashi = hash(kot(cur->_data)) % newtables.size();
//将旧表节点头插到新表节点中
cur->_next = newtables[hashi];
newtables[hashi] = cur;
cur = next;
}
}
_tables.swap(newtables);
}
size_t hashi = hash(kot(data)) % _tables.size();
//头插
Node* newnode = new Node(data);//新建节点
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(iterator(newnode, this), true);
}💫查找函数
步骤:
查找数据很简单。先通过hash函数计算出要查找的数据键值所对应的位置,如果对应的位置上存储的是空,说明不存在,直接返回。如果不为空,则比对键值,相同返回,不相同向下找直到为空。
代码:
// 查找函数
iterator Find(const K& key)
{
Hash hash;
KeyOfT kot;
//若表刚开始为空
if (_tables.size() == 0)
{
return end();
}
size_t hashi = hash(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur, this);
}
cur = cur->_next;
}
return end();
}💫删除函数
步骤:
在删除时,首先要调用hash函数获取关键码,根据对应位置上找。如果该位置存的数据为空,则表示不存在,返回;如果不为空,就比较键值,相同为找到,删除,不同就继续向下找直到为空。
注意:
哈希桶与哈希表不同,要删除数据时不能使用find()函数搜索。因为哈希桶中的数据是用单链表链接起来的,用find()就无法知道节点的父节点,进而无法链接链表。
代码:
// 删除函数
bool Erase(const K& key)
{
Hash hash;
KeyOfT kot;
size_t hashi = hash(key) % _tables.size();
Node* prev = nullptr;//用于记录前一个节点
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr)//要删除节点为头节点时
{
_tables[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
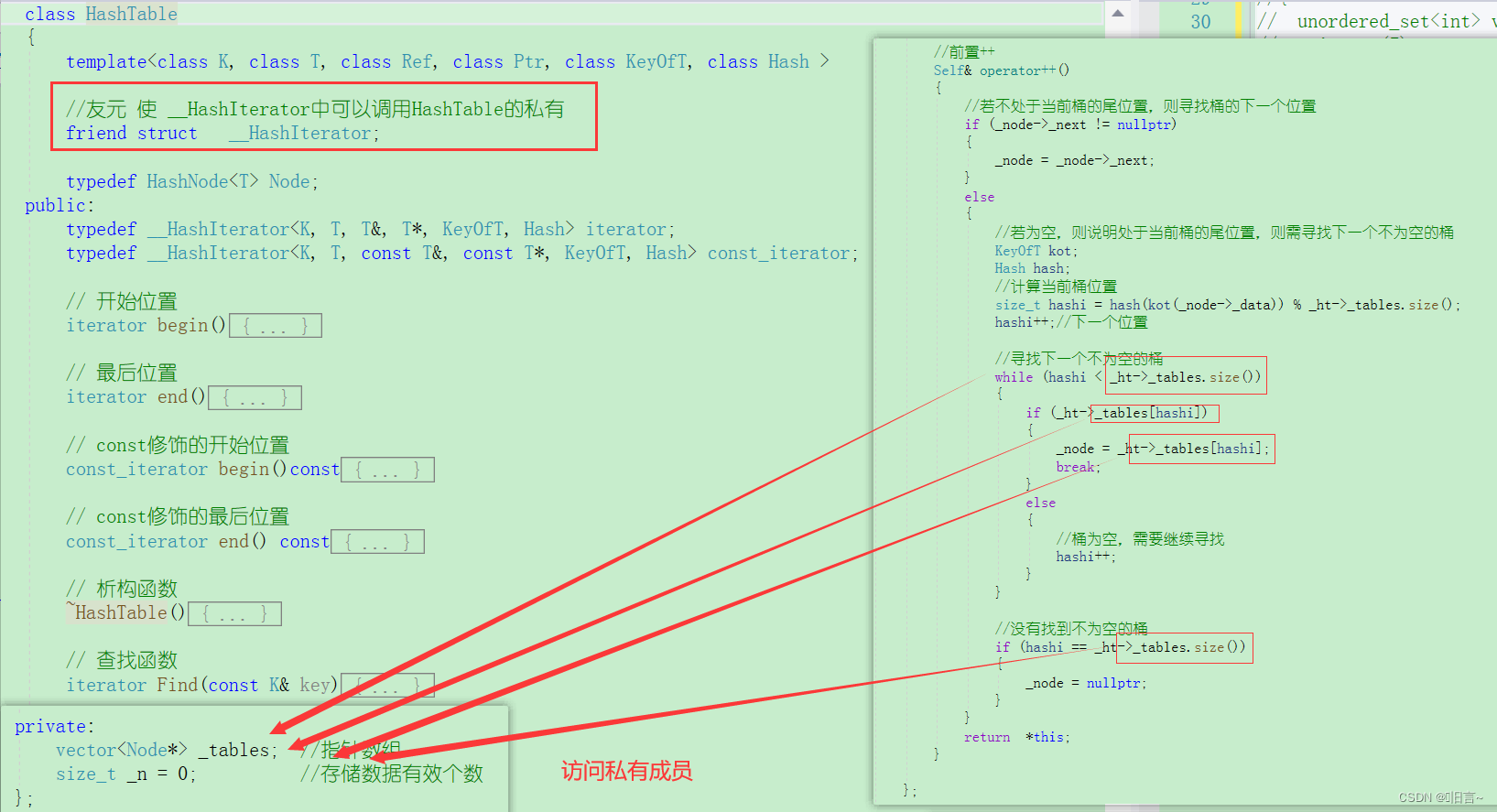
}💫迭代器实现
步骤:
迭代器的结构体中首先要有哈希桶的指针。当然,迭代器的结构体中还需要有一个数据的指针,用于初始化迭代器,获取对应位置上的内容。
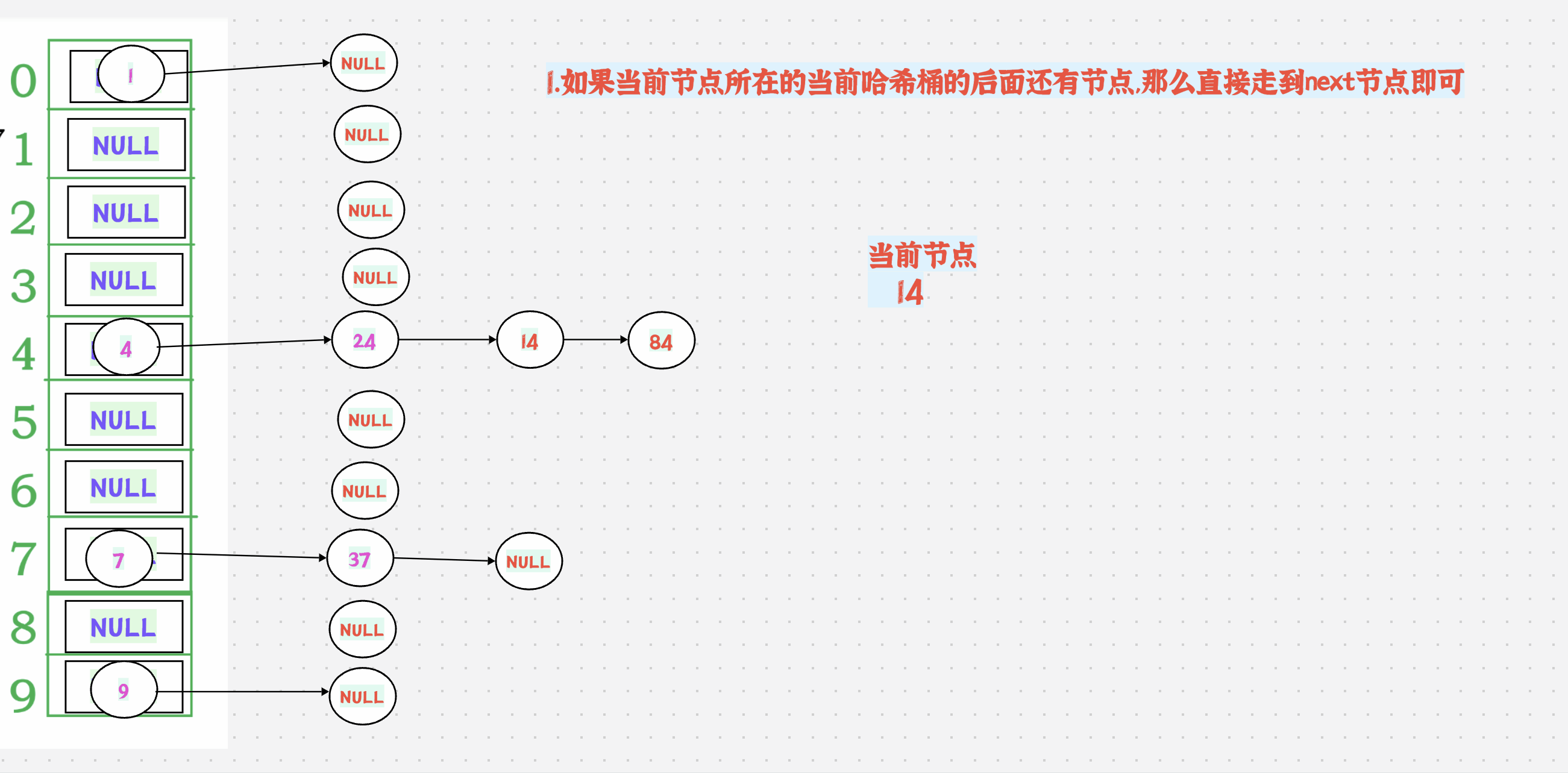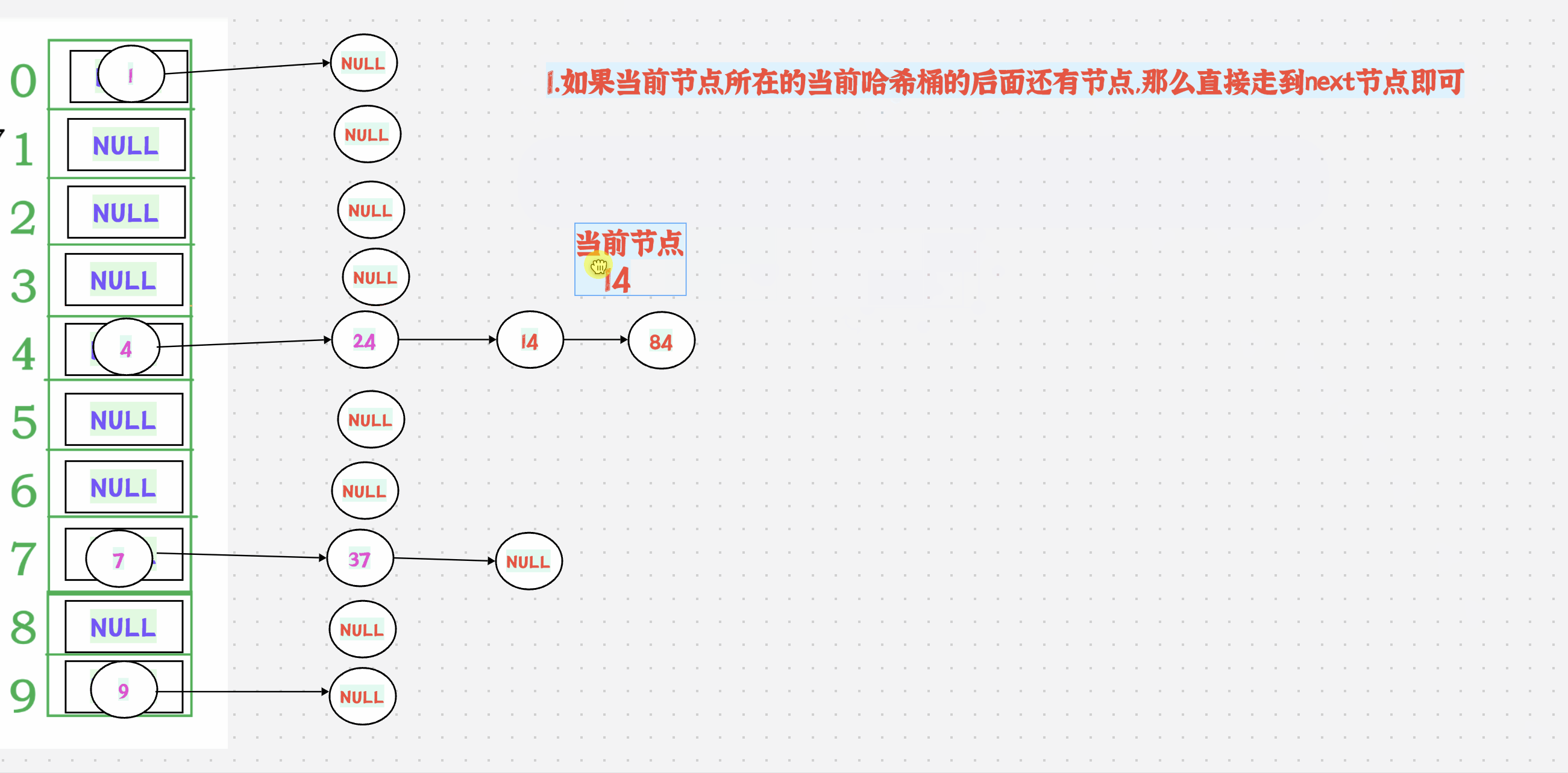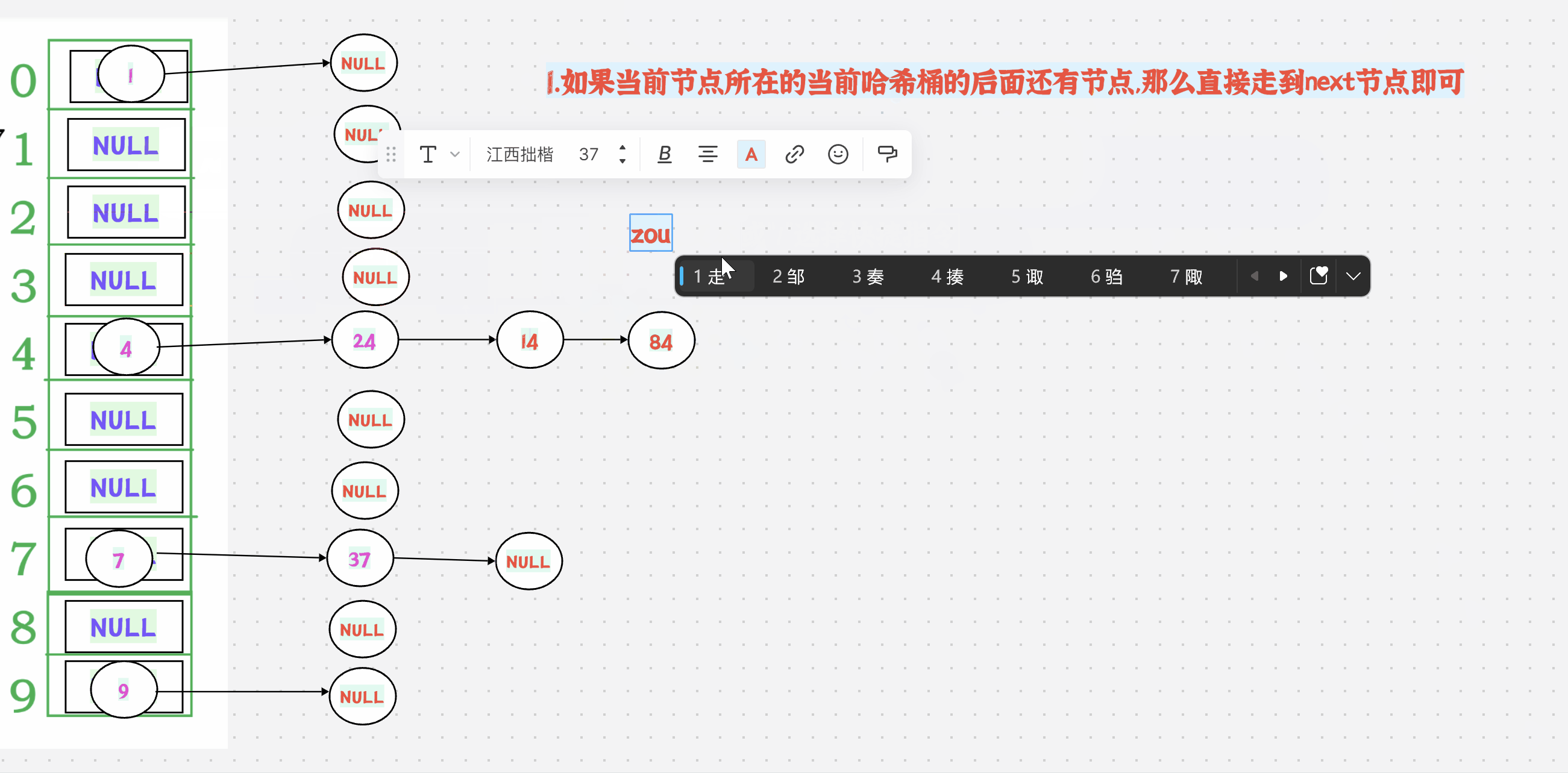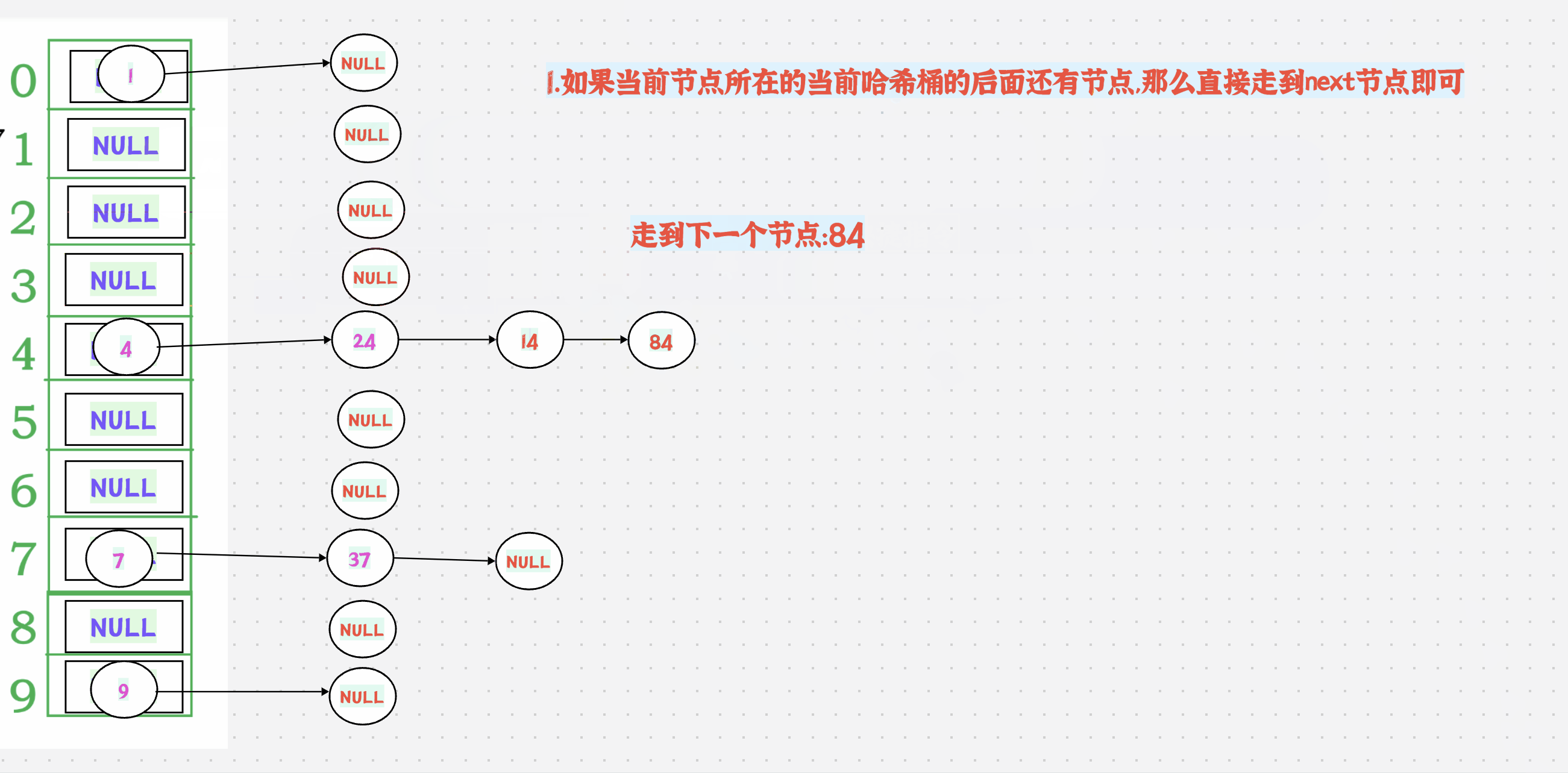
判断当前节点是否为空,不为空则返回;为空就说明当前下标对应的位置上已经没有数据了,就调用hash函数获取该节点的关键码。++关键码走向下一个下标,不为空则返回;为空则继续走,直到找到不为空的位置或结束。
图解:

注意:
哈希桶的begin()要返回的是第一个不为空的桶,而不是第一个节点
代码:
//迭代器
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash >
struct __HashIterator
{
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyOfT, Hash> HT;
typedef __HashIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;
//定义一个普通迭代器
typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;
Node* _node; //节点的指针
HT* _ht; //哈希表
// 初始化列表
__HashIterator(Node* node, HT* ht)
:_node(node), _ht(ht)
{}
// 初始化列表const
__HashIterator(const Iterator& it)
:_node(it._node), _ht(it._ht)
{}
Ref operator*() // 取值
{
return _node->_data;
}
Ptr operator->() // 指向
{
return &_node->_data;
}
bool operator!=(const Self& s) //使用节点的指针进行比较
{
return _node != s._node;
}
//前置++
Self& operator++()
{
//若不处于当前桶的尾位置,则寻找桶的下一个位置
if (_node->_next != nullptr)
{
_node = _node->_next;
}
else
{
//若为空,则说明处于当前桶的尾位置,则需寻找下一个不为空的桶
KeyOfT kot;
Hash hash;
//计算当前桶位置
size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();
hashi++;//下一个位置
//寻找下一个不为空的桶
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];
break;
}
else
{
//桶为空,需要继续寻找
hashi++;
}
}
//没有找到不为空的桶
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
};💫友元声明
解析:
在++迭代器的时候,会使用到哈希表指针,哈希表指针又会使用到HashTable中的_tables。HashTable中的_tables是私有成员,在类外是不能访问的。解决这个问题可以在HashTable中写一个公有的访问函数,也可以采用友元。
图解:
🌙unordered_map封装
代码如下:
#include"HashTable.h"
namespace lyk
{
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
// 仿函数
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename hash_bucket::HashTable<K, pair<const K, V>,
MapKeyOfT, Hash>::iterator iterator;
// 开始位置
iterator begin()
{
return _ht.begin();
}
// 结束位置
iterator end()
{
return _ht.end();
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
return ret->first->second;
}
// 插入函数
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.insert(kv);
}
// 查找函数
iterator find(const K& key)
{
return _ht.Find();
}
// 删除函数
bool erase(const K& key)
{
return _ht.Erase(key);
}
private:
hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;
};
// 测试一
void test_map1()
{
unordered_map<int, int> v;
v.insert(make_pair(1, 1));
v.insert(make_pair(3, 3));
v.insert(make_pair(10, 10));
v.insert(make_pair(2, 2));
v.insert(make_pair(8, 8));
unordered_map<int, int>::iterator it = v.begin();
while (it != v.end())
{
cout << it->first << ":" << it->second << " ";
++it;
}
cout << endl;
}
// 测试二
void test_map2()
{
unordered_map<string, string> dict;
dict.insert(make_pair("sort", ""));
dict.insert(make_pair("left", ""));
dict.insert(make_pair("right", "ұ"));
for (auto& kv : dict)
{
kv.second += 'y';
cout << kv.first << ":" << kv.second << endl;
}
}
};🌙unordered_set封装
代码如下:
#include"HashTable.h"
namespace lyk
{
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
// 仿函数
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename hash_bucket::HashTable<K, K, SetKeyOfT, Hash>::const_iterator iterator;
typedef typename hash_bucket::HashTable<K, K, SetKeyOfT, Hash>::const_iterator const_iterator;
// 开始位置
iterator begin()
{
return _ht.begin();
}
// 结束位置
iterator end()
{
return _ht.end();
}
// 开始位置const修饰
const_iterator begin() const
{
return _ht.begin();
}
// 结束位置const修饰
const_iterator end() const
{
return _ht.end();
}
// 插入
pair<iterator, bool> insert(const K& key)
{
return _ht.insert(key);
}
// 查找
iterator find(const K& key)
{
return _ht.Find();
}
// 删除
bool erase(const K& key)
{
return _ht.Erase(key);
}
private:
hash_bucket::HashTable<K, K, SetKeyOfT, Hash> _ht;
};
// 测试代码
void test_set1()
{
unordered_set<int> us;
us.insert(3);
us.insert(1);
us.insert(5);
us.insert(15);
us.insert(45);
us.insert(7);
unordered_set<int>::iterator it = us.begin();
while (it != us.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for (auto e : us)
{
cout << e << " ";
}
cout << endl;
}
}
🌙哈希表完整代码
#include <iostream>
#include <string>
#include <vector>
using namespace std;
// 仿函数
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
//特化 -- 仿函数
template<>
struct HashFunc<string> // 仿函数
{
// 将字符串转化为整数
size_t operator()(const string& key)
{
size_t hash = 0;
for (auto ch : key)
{
hash *= 131;
hash += ch;
}
return hash;
}
};
//开散列
namespace hash_bucket
{
// 定义结点
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{}
};
// 前置声明 (像函数声明一样)
template<class K, class T, class KeyOfT, class Hash>
class HashTable;
//迭代器
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash >
struct __HashIterator
{
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyOfT, Hash> HT;
typedef __HashIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;
//定义一个普通迭代器
typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;
Node* _node; //节点的指针
HT* _ht; //哈希表
// 初始化列表
__HashIterator(Node* node, HT* ht)
:_node(node), _ht(ht)
{}
// 初始化列表const
__HashIterator(const Iterator& it)
:_node(it._node), _ht(it._ht)
{}
Ref operator*() // 取值
{
return _node->_data;
}
Ptr operator->() // 指向
{
return &_node->_data;
}
bool operator!=(const Self& s) //使用节点的指针进行比较
{
return _node != s._node;
}
//前置++
Self& operator++()
{
//若不处于当前桶的尾位置,则寻找桶的下一个位置
if (_node->_next != nullptr)
{
_node = _node->_next;
}
else
{
//若为空,则说明处于当前桶的尾位置,则需寻找下一个不为空的桶
KeyOfT kot;
Hash hash;
//计算当前桶位置
size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();
hashi++;//下一个位置
//寻找下一个不为空的桶
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];
break;
}
else
{
//桶为空,需要继续寻找
hashi++;
}
}
//没有找到不为空的桶
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
};
// 哈希表
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash >
//友元 使 __HashIterator中可以调用HashTable的私有
friend struct __HashIterator;
typedef HashNode<T> Node;
public:
typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> iterator;
typedef __HashIterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;
// 开始位置
iterator begin()
{
Node* cur = nullptr;
size_t i = 0;
//找到第一个不为空的桶
for (i = 0; i < _tables.size(); i++)
{
cur = _tables[i];
if (cur)
{
break;
}
}
//迭代器返回 第一个桶 和哈希表
//this 作为哈希表本身
return iterator(cur, this);
}
// 最后位置
iterator end()
{
return iterator(nullptr, this);
}
// const修饰的开始位置
const_iterator begin()const
{
Node* cur = nullptr;
size_t i = 0;
//找到第一个不为空的桶
for (i = 0; i < _tables.size(); i++)
{
cur = _tables[i];
if (cur)
{
break;
}
}
//迭代器返回 第一个桶 和哈希表
//this 作为哈希表本身
return const_iterator(cur, this);
}
// const修饰的最后位置
const_iterator end() const
{
return const_iterator(nullptr, this);
}
// 析构函数
~HashTable()//析构
{
for (auto& cur : _tables)
{
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
cur = nullptr;
}
}
// 查找函数
iterator Find(const K& key)
{
Hash hash;
KeyOfT kot;
//若表刚开始为空
if (_tables.size() == 0)
{
return end();
}
size_t hashi = hash(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur, this);
}
cur = cur->_next;
}
return end();
}
// 删除函数
bool Erase(const K& key)
{
Hash hash;
KeyOfT kot;
size_t hashi = hash(key) % _tables.size();
Node* prev = nullptr;//用于记录前一个节点
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr)//要删除节点为头节点时
{
_tables[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
// 插入元素
pair<iterator, bool> insert(const T& data)//插入
{
KeyOfT kot;
//若对应的数据已经存在,则插入失败
iterator it = Find(kot(data));
if (it != end())
{
return make_pair(it, false);
}
Hash hash;
//负载因子==1时扩容
if (_n == _tables.size())
{
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
// 创建 newsize个数据,每个数据都为空
vector<Node*>newtables(newsize, nullptr);
for (auto& cur : _tables)
{
while (cur)
{
//保存下一个旧表节点
Node* next = cur->_next;
size_t hashi = hash(kot(cur->_data)) % newtables.size();
//将旧表节点头插到新表节点中
cur->_next = newtables[hashi];
newtables[hashi] = cur;
cur = next;
}
}
_tables.swap(newtables);
}
size_t hashi = hash(kot(data)) % _tables.size();
//头插
Node* newnode = new Node(data);//新建节点
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(iterator(newnode, this), true);
}
private:
vector<Node*> _tables; //指针数组
size_t _n = 0; //存储数据有效个数
};
}🌟结束语
今天内容就到这里啦,时间过得很快,大家沉下心来好好学习,会有一定的收获的,大家多多坚持,嘻嘻,成功路上注定孤独,因为坚持的人不多。那请大家举起自己的小手给博主一键三连,有你们的支持是我最大的动力💞💞💞,回见。