系列文章:
目录
5. ods->dwd:维表关联方案及维表加工、导入hbase
?面试题:
5. ods->dwd:维表关联方案及维表加工、导入hbase
5.1 维表关联方案
凡是维表是业务库中的表,关联时都可以用这个方案
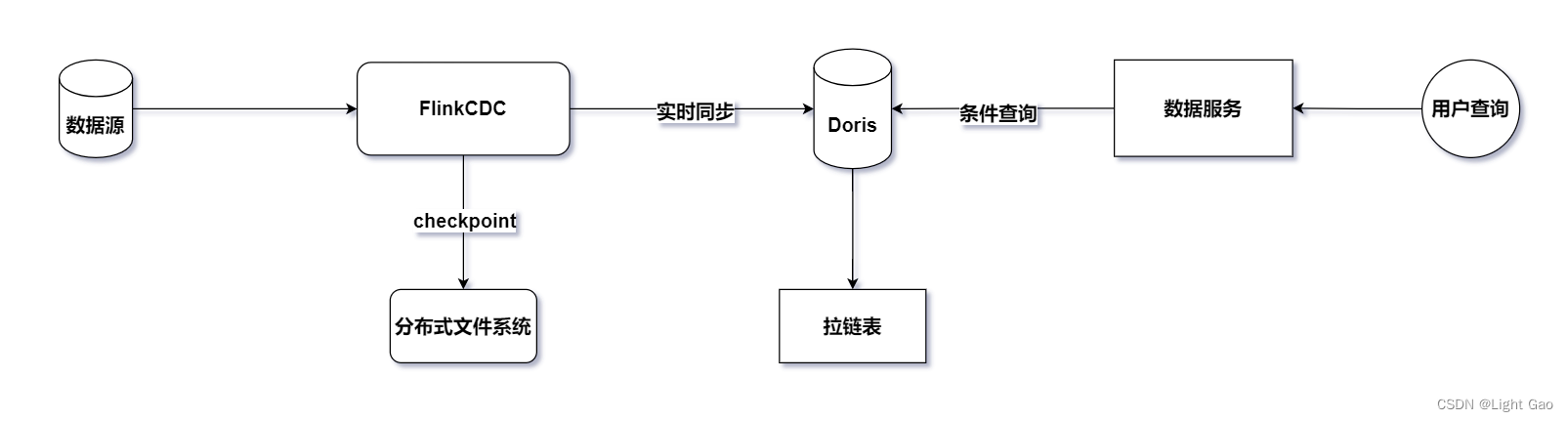
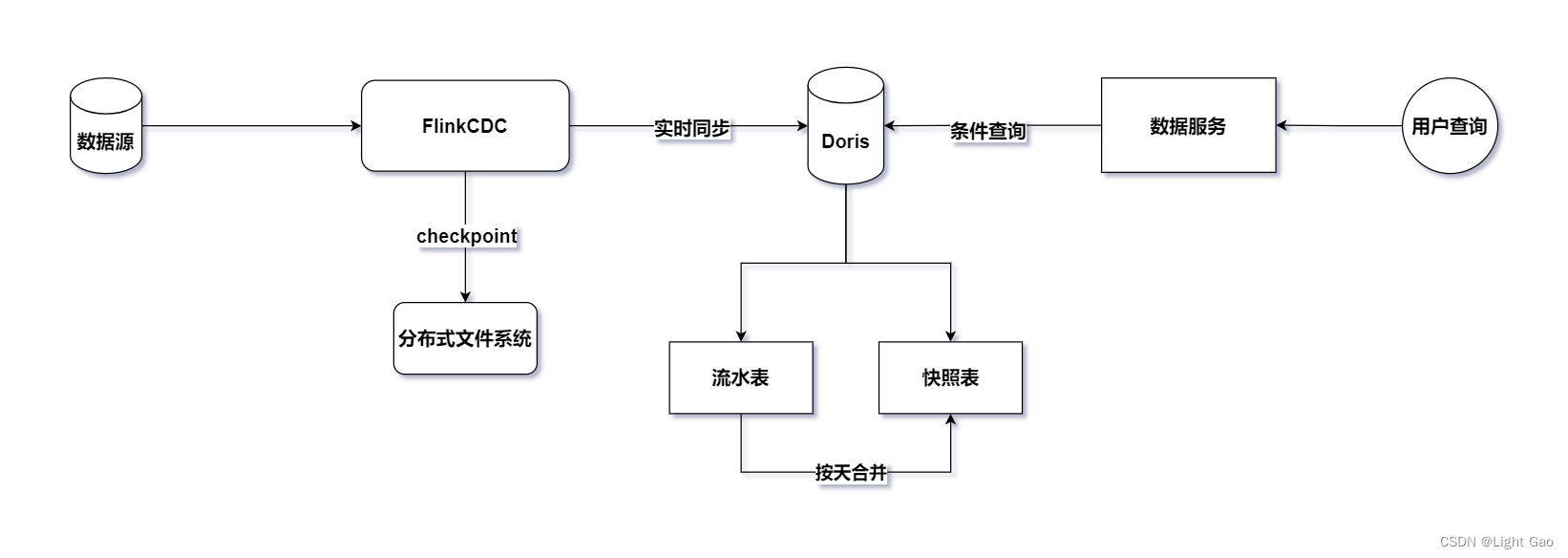
先用cdc把业务库中的数据同步到hbase中,关联的时候用lookup去关联
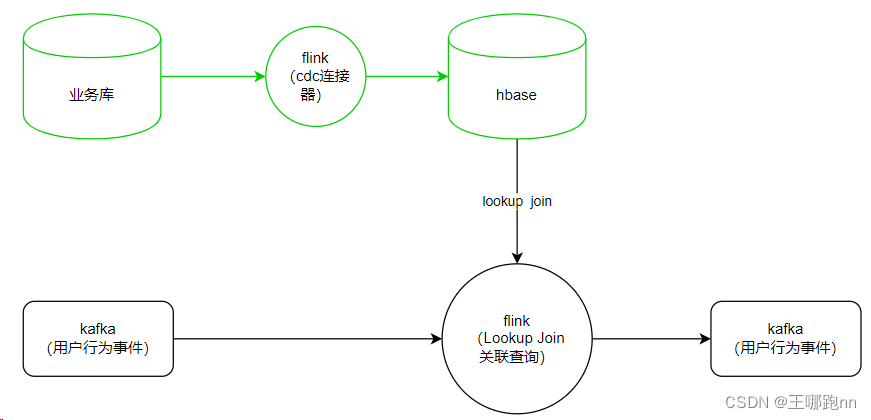
5.2 退维后结果去向
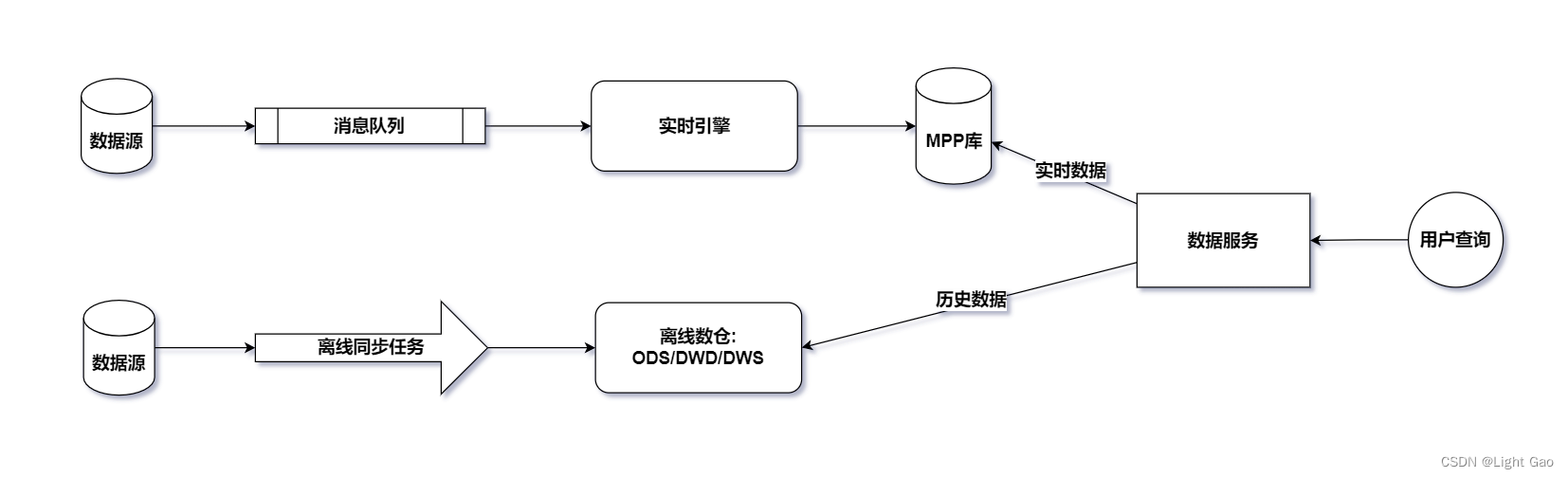
退维后的数据落地到DWD层的存储系统Kafka中(提供给后续的流式计算),同时,也可以选择冗余一份明细数据写入doris(最近一周)
5.3 创建维表:基础业务库表数据同步到hbase
临时表以tmp_开头,后面参照DWD、DWS相应的命名规范。
名称的各部分之间以"_"(下划线)连接
DIM层命名规范
DIM层数据主要存储公共的维表和一些配置信息等,因此其命名规范如下:
1.表名命名:dim.<公共类型>_<维描述>
2.公共类型:dim代码类的维表
3.维描述:描述维度对象实体,如日期 、地域等。
举例:资源池表:dim.dim_resource_pool_info_df
这里的flink代码可以用chatgpt prompt生成
5.3.1 cdc 读取mysql数据,生成临时映射表
这是mysql建表语句
CREATE TABLE `ums_member` (
`id` bigint NOT NULL AUTO_INCREMENT,
`member_level_id` bigint DEFAULT NULL,
`username` varchar(64) DEFAULT NULL COMMENT '用户名',
`password` varchar(64) DEFAULT NULL COMMENT '密码',
`nickname` varchar(64) DEFAULT NULL COMMENT '昵称',
`phone` varchar(64) DEFAULT NULL COMMENT '手机号码',
`status` int DEFAULT NULL COMMENT '帐号启用状态:0->禁用;1->启用',
`create_time` datetime DEFAULT NULL COMMENT '注册时间',
`icon` varchar(500) DEFAULT NULL COMMENT '头像',
`gender` int DEFAULT NULL COMMENT '性别:0->未知;1->男;2->女',
`birthday` date DEFAULT NULL COMMENT '生日',
`city` varchar(64) DEFAULT NULL COMMENT '所做城市',
`job` varchar(100) DEFAULT NULL COMMENT '职业',
`personalized_signature` varchar(200) DEFAULT NULL COMMENT '个性签名',
`source_type` int DEFAULT NULL COMMENT '用户来源',
`integration` int DEFAULT NULL COMMENT '积分',
`growth` int DEFAULT NULL COMMENT '成长值',
`luckey_count` int DEFAULT NULL COMMENT '剩余抽奖次数',
`history_integration` int DEFAULT NULL COMMENT '历史积分数量',
`modify_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_username` (`username`),
UNIQUE KEY `idx_phone` (`phone`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8 COMMENT='会员表';
这是映射表的示例代码:
// 建表,映射业务库mysql中的用户注册信息表
tenv.executeSql(
" create table ums_member_mysql( "+
" id bigint, "+
" member_level_id bigint, "+
" username string, "+
" phone string, "+
" status int, "+
" create_time timestamp(3) , "+
" gender int, "+
" birthday date , "+
" city string, "+
" job string, "+
" source_type int, "+
" integration int, "+
" growth int, "+
" luckey_count int, "+
" history_integration int, "+
" modify_time timestamp(3), "+
" primary key (username) not enforced "+
" ) with ( "+
" 'connector' = 'mysql-cdc', "+
" 'hostname' = 'hadoop01', "+
" 'port' = '3306', "+
" 'username' = 'root', "+
" 'password' = '123456', "+
" 'database-name' = 'realtimedw', "+
" 'table-name' = 'ums_member' "+
" ) "
);
以上是MySQL建表语句映射为Flink的建表SQL语句。
请学习并理解它,接下来我会向你反馈一个新的mysql建表语句,请依据此帮我生成对应的Flink建表SQL语句。~mysql DDL~
请注意:
1. 映射表名设置为在mysql表名的基础上加上在前面加上tmp_,在后面加上_mysql
2. connector,hostname,username,password,database-name和我提供的样例保持一致,table-name为刚刚我提供的mysql表名
3. primary key请帮我设置为username
4. mysql DDL中的comment不需要映射进映射表建表语句中
5. 请帮我生成完整的sql 映射代码,包括tenv.executeSql()以及双引号格式等5.3.2 将目标表映射到Hbase中,生成临时映射表
这是mysql映射表
tenv.executeSql(
" create table ums_member_mysql( "+
" id bigint, "+
" member_level_id bigint, "+
" username string, "+
" phone string, "+
" status int, "+
" create_time timestamp(3) , "+
" gender int, "+
" birthday date , "+
" city string, "+
" job string, "+
" source_type int, "+
" integration int, "+
" growth int, "+
" luckey_count int, "+
" history_integration int, "+
" modify_time timestamp(3), "+
" primary key (username) not enforced "+
" ) with ( "+
" 'connector' = 'mysql-cdc', "+
" 'hostname' = 'hadoop01', "+
" 'port' = '3306', "+
" 'username' = 'root', "+
" 'password' = '123456', "+
" 'database-name' = 'realtimedw', "+
" 'table-name' = 'ums_member' "+
" ) "
);
// 建表,映射hbase中的用户注册信息维表
tenv.executeSql(
" CREATE TABLE ums_member_hbase ( "+
" username STRING, "+
" f ROW< "+
" id bigint, "+
" member_level_id bigint, "+
" phone string, "+
" status int, "+
" create_time timestamp(3), "+
" gender int, "+
" birthday date, "+
" city string, "+
" job string, "+
" source_type int, "+
" integration int, "+
" growth int, "+
" luckey_count int, "+
" history_integration int, "+
" modify_time timestamp(3)>, "+
" primary key(username) not enforced "+
" ) WITH ( "+
" 'connector' = 'hbase-2.2', "+
" 'table-name' = 'dim_ums_member', "+
" 'zookeeper.quorum' = 'hadoop01:2181' "+
" ) "
);
// 插入sql
tenv.executeSql(
" INSERT INTO ums_member_hbase "+
" SELECT "+
" username, "+
" row(id,member_level_id,phone,status,create_time, "+
" gender,birthday,city,job,source_type,integration, "+
" growth,luckey_count,history_integration,modify_time) as f "+
" FROM ums_member_mysql "
);
以上是MySQL映射表建表语句和Hbase的映射表语句,我们需要将从mysql中读出来的数据映射进Hbase中进行存储
请学习并理解它,接下来我会向你反馈一个新的MySQL映射表建表语句,请依据此帮我生成对应的Hbase的映射表语句,以及inser sql语句。~mysql 映射表建表语句~
请注意:
1. 映射表名设置为在mysql表名的基础上将_mysql替换为_hbase
2. connector,zookeeper.quorum和我提供的样例保持一致,table-name为MySQL映射表建表语句中的table-name前面加上dim_
3. 此外,在这张表中,primary key对应的username为行键,需要单独声明一下,而其余的列将作为f列族中的各个列。
5. 请帮我生成完整的sql 映射代码,包括tenv.executeSql()以及双引号格式等
6. 其中primary key(usename)行键声明时不要忘记后面加上 not enforced?面试题:
🧀为什么要用lookup join?
因为业务库中的表只会被监听一次,而用户行为则会反复发生,不适合用双流join。如果用双流join的话,就必须把数据放在状态里,但是用户行为数据量很大,系统支撑不了
🧀为什么要把数据同步到hbase?
业务库需要负载公司的业务功能,如果直接去关联业务表的话,会给业务系统的联机库带来巨大的查询压力,这是显然不合适的
🧀为什么要保留一份数据在doris里面?
doris中的数据,主要是我们做好的各类轻度聚合数据,并提供给分析师进行各类灵活实时分析;但是,只要是聚合过的数据,就一定会有信息的丢失;难么就有可能出现分析师的某些需求无法从聚合数据中计算得出,必须要查询明细数据;所以,我们才在此冗余一份明细数据写入doris,来应对这种场景;但是这种场景通常只会查询最近一段时期的数据,所以,我们在此最多保留最近近一个月的明细)
6. 常用术语解释
6.1 事实表
事实表描述业务过程的度量、以可加数据为主题,每一行代表一个可以观察的实体或事件.。例如事实表可以记录每一笔销售交易的具体细节,比如销售金额、销售数量、销售日期、销售地点等。
6.2 维度表
维度表描述事实所处的环境、面向分析,代表针对事实的一种分类。也就是说,维度表就是用来描述事实的,例如,在零售业务中,维度表可以包括产品维度、时间维度、地点维度、客户维度等,用来描述销售交易发生的环境和相关属性。,这些信息组合在一起就是维度表
6.3 维度建模中的三种模型
本项目采用星型模型
星型模型
由一个事实表和一堆维度表组成:维表只和事实表关联,维表之间没有关系;每个维表都有一个维作为主键,所有这些维的主键组合成
事实表的主键;以事实表为核心,维表围绕事实表呈星型分布;多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一
定的冗余;例如:在资源池维度表中,存在区域-西南,大区-西南大区的省份西藏,以及区域-西南,大区-西南大区的省份四川两条记录,那么区域-西南和大区-西南大区的信息分别存储了两次,即存在冗余。
雪花模型
一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展;它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表
都连接到主维度表而不是事实表;例如将资源池维表又分解为区域,大区,省份等维表。通过最大限度地减少数据存储量以及联合较小的维表来改
善查询性能。雪花型结构去除了数据冗余。
星座模型
一个复杂的应用往往会在数据仓库中存放多个事实表,这时就会出现多个事实表共享某一个或多个维表的情况,这就是事实星座。
?面试题:
🧀星型模型和雪花模型的区别
星型模式是以事实表为中心,所有的维度表直接连接在事实表上,像星星一样。
雪花模型是对星型模型的扩展,一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,就像多个雪花连接在一起。