随着数据量的爆发增长,传统集中式数据库面临极大的挑战:
- 性能瓶颈:数据规模爆发增长,传统集中式数据库难以维持数据量大时的性能,而分布式数据库的性能可以水平扩展;
- 缺失混合负载能力:数据量爆发增长带来对数据分析(OLAP)需求的增长。企业需要使用两套系统分别支撑事务交易(OLTP)和数据分析(OLAP),不仅造成了大量的数据冗余,同时增加了系统的复杂度和运维难度。而分布式数据库的混合负载能力可大幅度提升分析的时效性,减少数据冗余,并大大提高灵活性;
- 高昂成本:集中式数据库水平扩展难,可靠性需要付出高昂的成本。而分布式数据库的架构支持灵活扩展,实现高可用方案的成本较低。
分布式数据库与单机数据库的不同在于其可以将核心功能扩展到多台节点,甚至多个地域,包括事务管理、数据存储和数据查询等。从实现方式上看,分布式数据库主要有3种不同的技术路线:
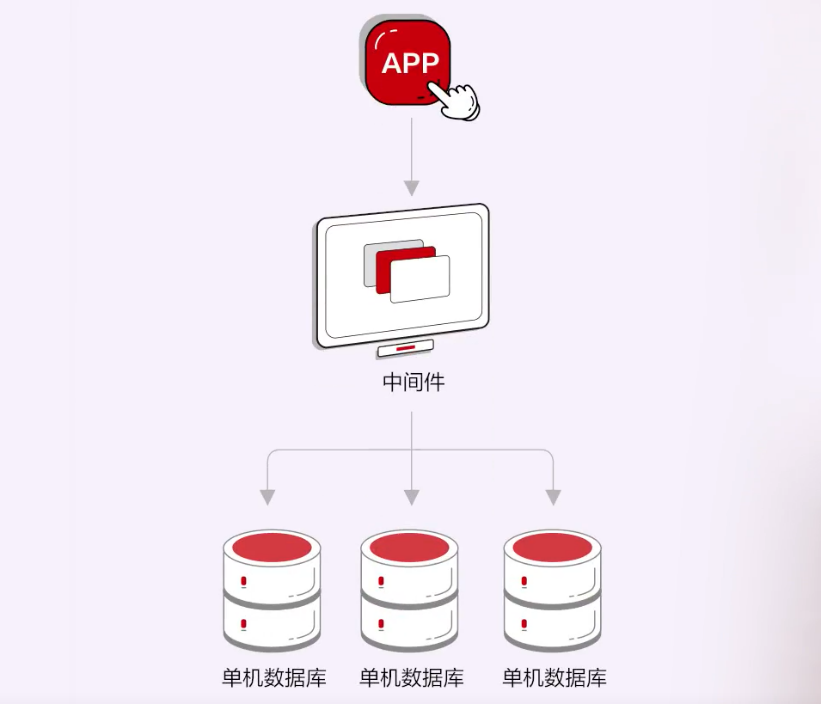
1. 分布式中间件 + 单机数据库。
这条路线本质上是分布式系统由两部分组成:
a) 上层是分布式中间件:维护一套统一的分片规则,提供SQL 解析,请求转发和结果合并的能力。
b) 底层单机数据库:开源MySQL或PG单机数据库,提供数据存储和执行能力。
这种方式主要使用比较成熟的内核来解决扩展性的问题,所以生态友好、成本较低,也比较容易实现。
不过,缺点也显而易见。比如功能降级、在全局事务能力和高可用等方面存在短板,需要有针对性增强,导致整个方案的复杂度高、机器冗余多。最重要的是,因为使用的是开源产品的内核,数据库会始终受制于开源代码修改、专利、发行方式等很多方面的风险,这种形式显然无法满足当前国内金融、政企客户的需求。
2. 基于分布式存储的分布式数据库。
这种形态基于分布式存储,再叠加数据库能力。大部分公有云数据库采用这条技术路线。华为云GaussDB(for MySQL)就是这种形态的典型代表。
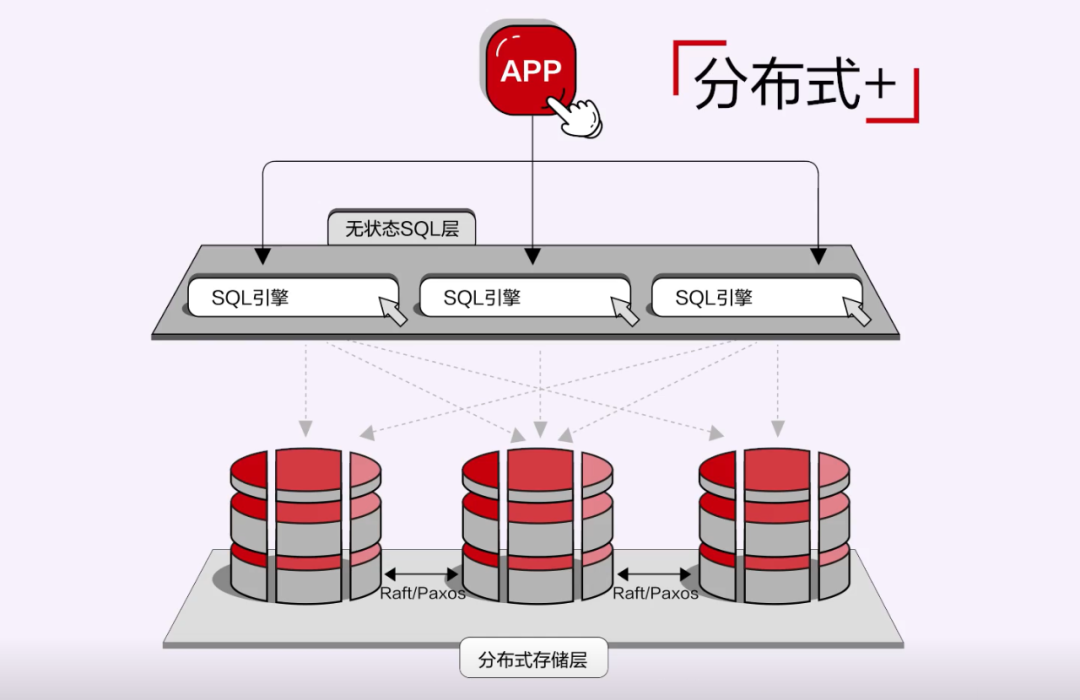
这条路线有限地解决了扩展性问题,数据一致性主要依赖分布式存储引擎。上层的计算节点无状态,共享存储提供跨节点读写。这种架构充分利用分布式存储提供的高级特性,更容易形成技术竞争力。但是这种架构的扩展性有限,尤其是写节点。
另外,这种架构对底座(分布式存储)有比较重的依赖,线下实现的成本高。
3. 原生分布式数据库。
这种形态是基于分布式数据库理论实现的分布式数据库。这条路线是根据分布式一致性协议做底层设计。原生分布式数据库将分布式存储、事务和计算结合在一起,数据由系统自动打散并存储多个副本,通过一致性协议保证多个副本和事务的一致性。
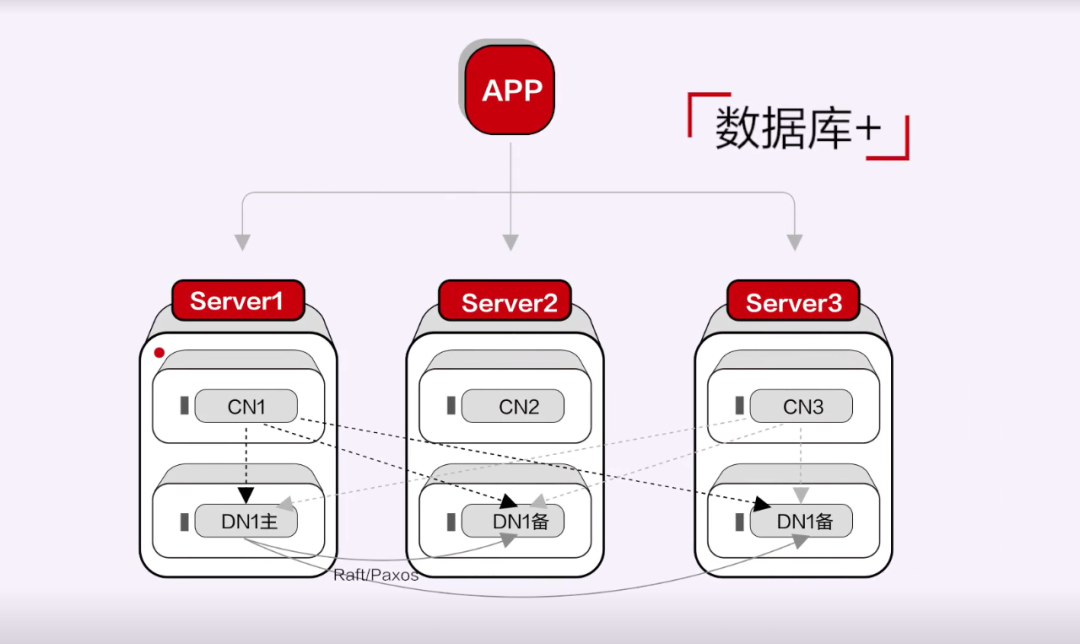
这种形态更容易在数据库本身所擅长的领域发挥优势,比如说性能、复杂SQL处理能力、企业级能力。集群的扩展和收缩对应用透明,按需扩展,支持大规模部署限制;数据一致性由事务层一致性协议保护,安全性更高;灵活部署,多活架构,对硬件的依赖低,可以通过普通服务器实现集群和高可用。
因为金融政企客户在使用分布式技术之前,往往已经有分库分表、使用分布式中间件产品的经验,所以对原生分布式架构的认可度更高,学习成本也相对较低,因此,这种形态也是国内当前被采用较多的一种。
华为云GaussDB分布式数据库就是这种形态的典型代表。GaussDB基于华为在数据库领域20多年的战略投入,已经在金融行业积累了非常丰富的实践经验,是企业数字化转型、核心数据上云、分布式改造的信赖之选。
分布式数据库需要确保异常场景下(如:节点硬件故障或者Bug宕机等)数据库系统的连续可用。

分布式数据库的挑战和关键技术
GaussDB分布式数据库研发了一系列高性能、高可用、安全特性迎接上述四大挑战,下面挑选几个有代表性的特性加以说明。
- 全密态
传统的加密方式在服务端加密,密钥管理员是可以获取的。而全密态数据库的密钥掌握在用户自己手上,数据库管理员无法获取,加解密过程仅在客户侧完成,数据在存储、传输、查询整个生命周期过程中均以密文形态存在,避免管理员恶意获取密钥解密数据。
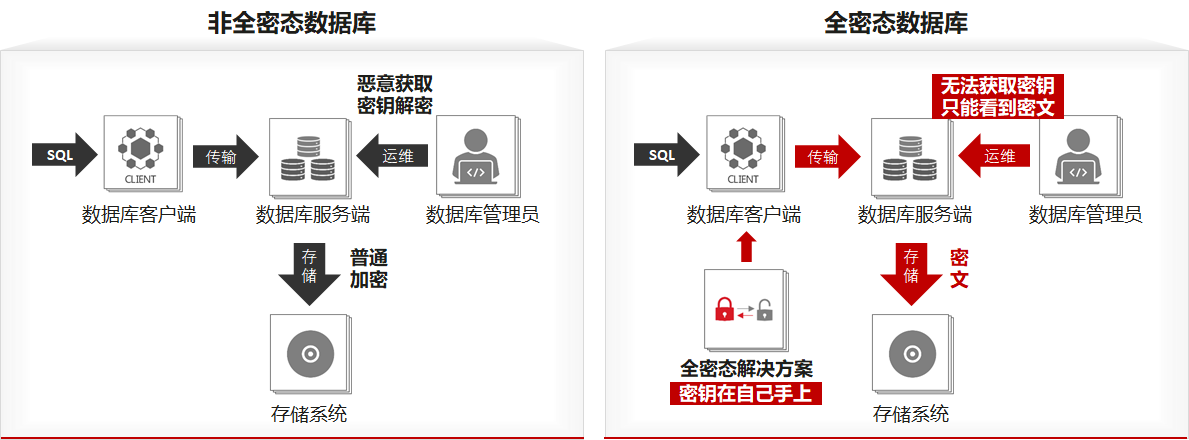
全密态数据库
- 分布式查询优化
1. 分布式执行
GaussDB是如何处理分布式数据库集群中的业务应用SQL的呢?
1)业务应用的SQL会下发给CN节点;
2)CN利用数据库的优化器生成分布式的执行计划,每个DN会按照执行计划的要求处理数据;
3)数据基于一致性Hash算法分布在每个DN,因此DN在处理数据的过程中,可能需要从其他DN获取数据,GaussDB提供三种stream流(广播流broadcast、聚合流gather和重分布流redistribute)实现数据在DN间的流动;
4)DN将结果集返回给CN进行汇总;
5)CN将汇总的结果返回给业务应用。
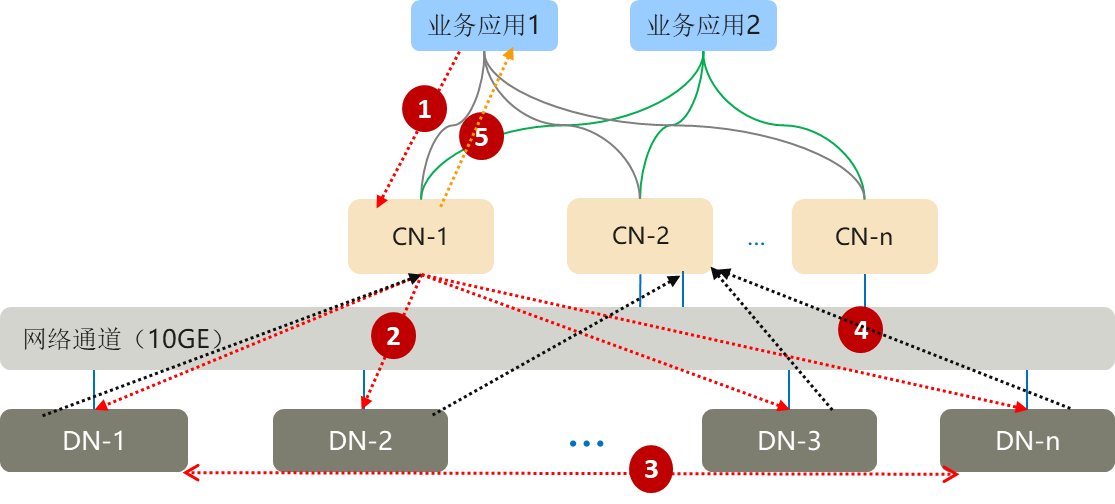
分布式查询示意
让我们展开看一下节点间的数据交换。比如某条SQL的执行逻辑如下图所示:
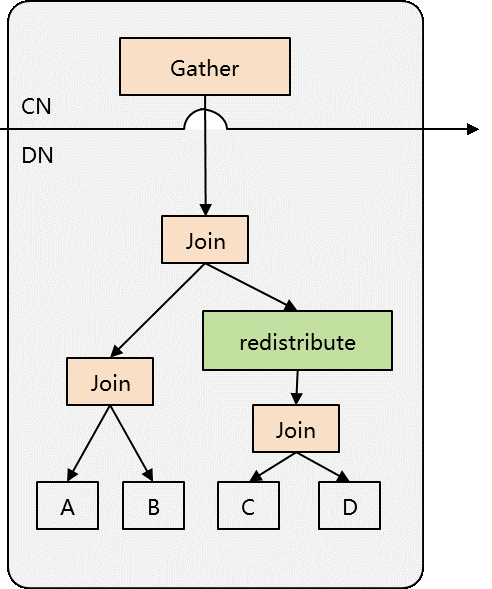
SQL执行逻辑
以两个DN为例, 在执行过程中,DN会按照redistribute键将数据发送到对应的节点。
Redistribute算子接收到C/D两表join的数据之后,根据重分布键计算将数据发给DN1还是DN2,Redistribute Collector收集到重分布之后的数据之后发给上层的Join算子再做Join计算。

CN、DN间的数据流动
另外,GaussDB的优化器会根据统计信息选取针对当前SQL性能最优的Stream流算子完成CN、DN间的数据流动。
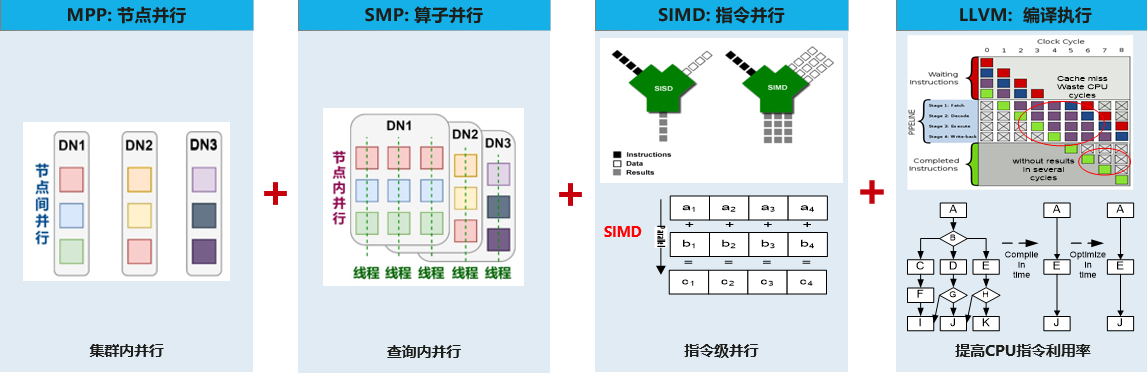
2. 全并行架构
GaussDB采用全并行架构,从MPP节点并行、SMP线程并行、到SIMD指令并行,到LLVM CodeGen技术,全面挖掘系统计算资源的潜力,提升查询性能。
- 高可用
分布式数据库技术的发展方向
基于新需求、新场景、以及全池化架构、新网络和大模型等新技术的出现,我们认为分布式数据库技术主要向以下六个方向发展。

参考:























![【Leetcode | Python】48. 旋转图像 [数组][数学][矩阵]](https://img-blog.csdnimg.cn/direct/9a2bf0ef46c74dbb89349fd044fc6472.png)