1.最简单的方法:
- 需要在 Spring Boot 主类上添加 @EnableAsync 注解启用异步功能;
- 需要在异步方法上添加 @Async 注解。
示例代码如下:
@SpringBootApplication
@EnableAsync
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
@Service
public class AsyncService {
@Async
public void asyncTask() {
// 异步任务执行的逻辑
}
}
优点:
- 简单易用,只需要在方法上添加@Async注解即可。
- 依赖Spring框架,集成度高,可以与其他Spring组件无缝协作。
缺点:
- 方法必须是public,否则异步执行无效。
- 不能直接获取异步执行结果,需要使用Future或CompletableFuture等类型。
2.基于@Async注解,自己重写线程池配置的方法
2.1、创建线程池
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.scheduling.annotation.EnableAsync;
import java.util.concurrent.Executor;
import java.util.concurrent.ThreadPoolExecutor;
@EnableAsync
@Configuration
public class ExecutorConfig {
// 获取服务器的 cpu 个数
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
@Bean("taskExecutor")
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 核心线程数
executor.setCorePoolSize(CPU_COUNT * 2);
// 最大线程数
executor.setMaxPoolSize(CPU_COUNT * 4);
// 线程空闲保持时间
executor.setKeepAliveSeconds(50);
// 队列大小
executor.setQueueCapacity(CPU_COUNT * 16);
// 线程名前缀
executor.setThreadNamePrefix("");
// 设置拒绝策略
// AbortPolicy -> 默认策略,如果线程池队列满了丢掉这个任务并且抛出 RejectedExecutionException 异常
// DiscardPolicy -> 如果线程池队列满了,会直接丢掉这个任务并且不会有任何异常
// DiscardOldestPolicy -> 如果队列满了,会将最早进入队列的任务删掉腾出空间,再尝试加入队列
// CallerRunsPolicy -> 如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 等待所有任务结束后再关闭线程池
executor.setWaitForTasksToCompleteOnShutdown(true);
executor.initialize();
return executor;
}
}
2.2、业务方法添加 @Async 注解
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.AsyncResult;
import org.springframework.stereotype.Service;
import java.util.concurrent.Future;
import java.util.concurrent.atomic.AtomicInteger;
@Service
public class TestServiceImpl {
public static volatile AtomicInteger i = new AtomicInteger(0);
/**
* 无返回结果
*/
@Async("taskExecutor")
public void test() {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("当前第" + i.incrementAndGet() + "次执行");
}
/**
* 有返回结果
*/
@Async("taskExecutor")
public Future<String> test2() {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
return new AsyncResult("当前第" + i.incrementAndGet() + "次执行");
}
}
也可以不用注解,代码如下
package com.socketio.push.config;
import org.springframework.data.redis.connection.Message;
import org.springframework.data.redis.connection.MessageListener;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
/**
* @author litong
*/
@Service
public class RedisSub implements MessageListener {
@Resource(name = "taskExecutor")
private ThreadPoolTaskExecutor taskExecutor;
@Override
public void onMessage(Message message, byte[] pattern) {
taskExecutor.execute(()->{
handleMsg(message);
});
}
/**
* 处理redis订阅消息
* @param message
*/
private void handleMsg(Message message){
}
}
注解方式失效原因
1. 注解的方法必须是 public 方法
2. 方法一定要从另一个类中调用,也就是从类的外部调用,类的内部调用是无效的。
因为 @Async 注解的实现都是基于 AOP 动态代理,所以内部调用失效的原因是由于调用方法的是对象本身而不是代理对象,没有经过 Spring 容器
3. 异步方法使用注解 @Async 的返回值只能为 void 或者 Future
3.使用 CompletableFuture 实现异步任务
CompletableFuture 是 Java 8 新增的一个异步编程工具,它可以方便地实现异步任务。使用 CompletableFuture 需要满足以下条件:
- 异步任务的返回值类型必须是 CompletableFuture 类型;
- 在异步任务中使用 CompletableFuture.supplyAsync() 或 CompletableFuture.runAsync() 方法来创建异步任务;
- 在主线程中使用 CompletableFuture.get() 方法获取异步任务的返回结果。
示例代码如下:
@Service
public class AsyncService {
public CompletableFuture<String> asyncTask() {
return CompletableFuture.supplyAsync(() -> {
// 异步任务执行的逻辑
return "异步任务执行完成";
});
}
}4.使用 TaskExecutor 实现异步任务
TaskExecutor 是 Spring 提供的一个接口,它定义了一个方法 execute(),用来执行异步任务。使用 TaskExecutor 需要满足以下条件:
- 需要在 Spring 配置文件中配置一个 TaskExecutor 实例;
- 在异步方法中调用 TaskExecutor 实例的 execute() 方法来执行异步任务。
示例代码如下:
@Configuration
@EnableAsync
public class AsyncConfig implements AsyncConfigurer {
@Bean(name = "asyncExecutor")
public TaskExecutor asyncExecutor() {
// 获取服务器的 cpu 个数
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(CPU_COUNT);
executor.setMaxPoolSize(CPU_COUNT * 2);
executor.setQueueCapacity(CPU_COUNT * 100);
executor.setThreadNamePrefix("async-");
executor.initialize();
return executor;
}
@Override
public Executor getAsyncExecutor() {
return asyncExecutor();
}
@Override
public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
return new SimpleAsyncUncaughtExceptionHandler();
}
}
@Service
public class AsyncService {
@Autowired
@Qualifier("asyncExecutor")
private TaskExecutor taskExecutor;
public void asyncTask() {
taskExecutor.execute(() -> {
// 异步任务执行的逻辑
});
}
}
手动设置线程池,就要合理设置最大线程数和核心线程数,按照网上大多数的说法,都是跟服务器的CPU有关:
一、设置核心线程数corePoolSize
1.先看下机器的CPU核数,然后在设定具体参数:
System.out.println(Runtime.getRuntime().availableProcessors());
即CPU核数 = Runtime.getRuntime().availableProcessors()
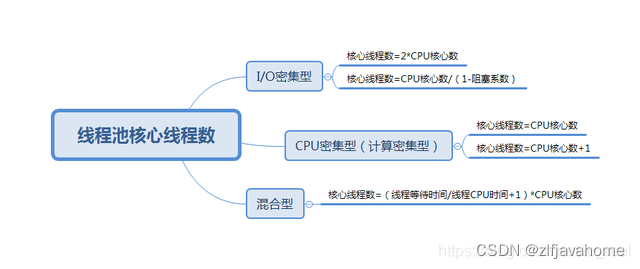
2.分析下线程池处理的程序是CPU密集型,还是IO密集型
IO密集型:大量网络,文件操作
IO密集型:核心线程数 = CPU核数 * 2
CPU 密集型:大量计算,cpu 占用越接近 100%, 耗费多个核或多台机器
CPU密集型:核心线程数 = CPU核数 + 1
注:IO密集型(某大厂实践经验)
核心线程数 = CPU核数 / (1-阻塞系数) 例如阻塞系数 0.8,CPU核数为4
则核心线程数为20
maxPoolSize:
当系统负载达到最大值时,核心线程数已无法按时处理完所有任务,这时就需要增加线程。每秒200个任务需要20个线程,那么当每秒达到1000个任务时,则需要(1000-queueCapacity)*(20/200),即60个线程,可将maxPoolSize设置为60。还有说法就是 cpuNUM*2 或者是cpuNUM*4
keepAliveTime:
线程数量只增加不减少也不行。当负载降低时,可减少线程数量,如果一个线程空闲时间达到keepAliveTiime,该线程就退出。默认情况下线程池最少会保持corePoolSize个线程。
allowCoreThreadTimeout:
默认情况下核心线程不会退出,可通过将该参数设置为true,让核心线程也退出。
queueCapacity:
任务队列的长度要根据核心线程数,以及系统对任务响应时间的要求有关。队列长度可以设置为(corePoolSize/tasktime)*responsetime: (20/0.1)*2=400,即队列长度可设置为400。
队列长度设置过大,会导致任务响应时间过长,切忌以下写法:
LinkedBlockingQueue queue = new LinkedBlockingQueue();
这实际上是将队列长度设置为Integer.MAX_VALUE,将会导致线程数量永远为corePoolSize,再也不会增加,当任务数量陡增时,任务响应时间也将随之陡增。