本篇及此系列文章只针对面试相关问题做了简单总结,后续会出比较详细的系列文章....
1. 创建Pod的底层逻辑
Pod创建过程中,Master和Node节点相关组件的交互流程如图示。

流程描述
① 客户端提交Pod的配置信息(一般是.yaml文件)到kube-apiserver;
② api-server收到指令后,通知controller-manager创建一个Pod资源 ;
③ controller-manager将创建好的Pod资源信息返回给api-server;
④ api-server将Pod资源信息存储到etcd数据中心;
⑤ kube-scheduler检测到新的Pod资源开始预选调度【先过滤掉不符合Pod资源配置要求的节点,然后开始调度调优,最后挑选出更适合运行Pod的节点】;
⑥ 将Pod的资源配置单发送给所挑选Node节点的kubelet组件;
⑦ kubelet根据kube-scheduler发来的资源配置单运行Pod;
⑧ Pod运行成功后,kubelet将Pod的状态信息返回给kube-scheduler;
⑨ kube-scheduler将Pod的状态信息更新到etcd数据中心。
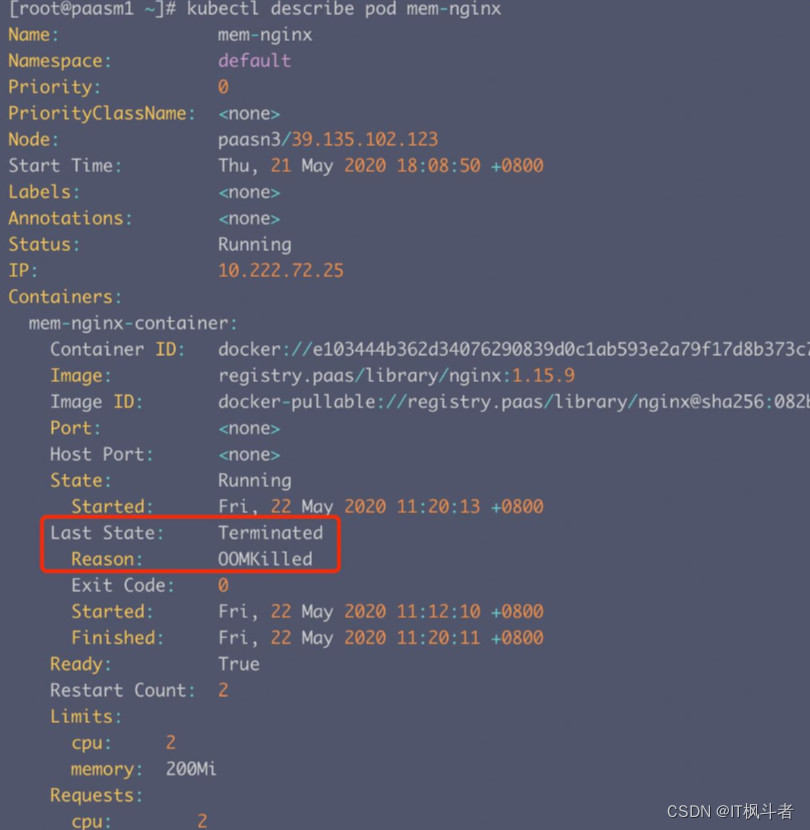
2. Pod的运行状态有哪些?
- Pending:API Server已经创建该Pod,且Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程。
- Running:Pod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。
- Succeeded:Pod内所有容器均成功执行退出,且不会重启。
- Failed:Pod内所有容器均已退出,但至少有一个容器退出为失败状态。
- Unknown:由于某种原因无法获取该Pod状态,可能由于网络通信不畅导致。
3. 什么是静态Pod?
- 由kubelet创建,存在于特定node上的无法进行健康检查的pod;
- 不能通过api-server进行管理;
- 无法与Replication Controller,Deployment或者DaemonSet进行关联
4. Pod的重启策略有哪些?
- 作用:重启策略应用于Pod内的所有容器,当pod内的某容器异常退出/健康检测失败时,kubelet会根据重启策略完成相应操作;
- 重启策略
- Always(default):当容器失效时,由kubelet自动重启该容器
- OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器;
- Never:不论容器运行状态如何,kubelet都不会重启该容器
- 重启策略与控制方式(Replication Controller,Job,DaemonSet和kubelet)关联
- Replication Controller和DaemonSet:必须设置为Always,需要保证该容器持续运行;
- Job:OnFailure或Never,确保容器执行完成后不再重启;
- kubelet:在Pod失效时重启,不论将RestartPolicy设置为何值,也不会对Pod进行健康检查。
5. Pod的健康检查方式
kubernetes提供三类Probe(探针),kubelet会定期执行探针检测Pod的健康状态。
- LivenessProbe探针:判断容器是否存活(running状态),如果LivenessProbe探针探测到容器不健康,kubelet将杀掉该容器,并根据容器的重启策略做相应处理。若一个容器不包含LivenessProbe探针,kubelet认为该容器的LivenessProbe探针返回值用于是“Success”。
- ReadineeProbe探针:用于判断容器是否启动完成(ready状态)。如果ReadinessProbe探针探测到失败,Pod的状态将被修改。Endpoint Controller将从Service的Endpoints中删除包含该容器所在Pod的Eedpoint。
- StartupProbe探针:启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被上面两类探针kill掉。
6. LivenessProbe探针的实现方式
- ExecAction:在容器内执行一个命令,若返回码为0,则表明容器健康。
- TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,若能建立TCP连接,则表明容器健康。
- HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTP-Get方法,若响应的状态码大于等于200且小于400,则表明容器健康。
7. Pod的常见调度方式
常见的Pod调度方式有以下四种:
- Deployment或Replication Controller:自动部署一个容器应用的多份副本,持续监控副本的数量,在集群内始终维持用户指定的副本数量。
- NodeSelector:定向调度,当需要将Pod调度到特定Node上时,可以通过Node的标签(Label)和 Pod的nodeSelector属性相匹配。
- NodeAffinity亲和性调度:亲和性调度机制极大的扩展了Pod的调度能力,目前有两种节点亲和力表达式。
- requiredDuringSchedulingIgnoredDuringExecution:硬规则,必须满足指定的规则,调度器才可以调度Pod至Node上(类似nodeSelector)
- preferredDuringSchedulingIgnoredDuringExecution:软规则,优先调度至满足的Node的节点,但不强求,多个优先级规则还可以设置权重值。
- Taints和Tolerations(污点和容忍)
- Taint:Node属性,表示Node拒绝特定Pod运行;
- Toleration:Pod的属性,表示Pod能容忍运行在标注了Taint的Node上。
8. kubernetes的Replication Controller机制
Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。当定义了RC并提交至k8s集群之后,master节点上的controller-manager组件得到消息,巡检系统中当前存活的目标pod,并确保目标pod的存活数量符合期望值。
上一篇: kubernetes 初探


























![[每周一更]-第91期:认识AMD的CPU](https://img-blog.csdnimg.cn/direct/4500217209e249f8ab185151d1492850.jpeg#pic_center)

