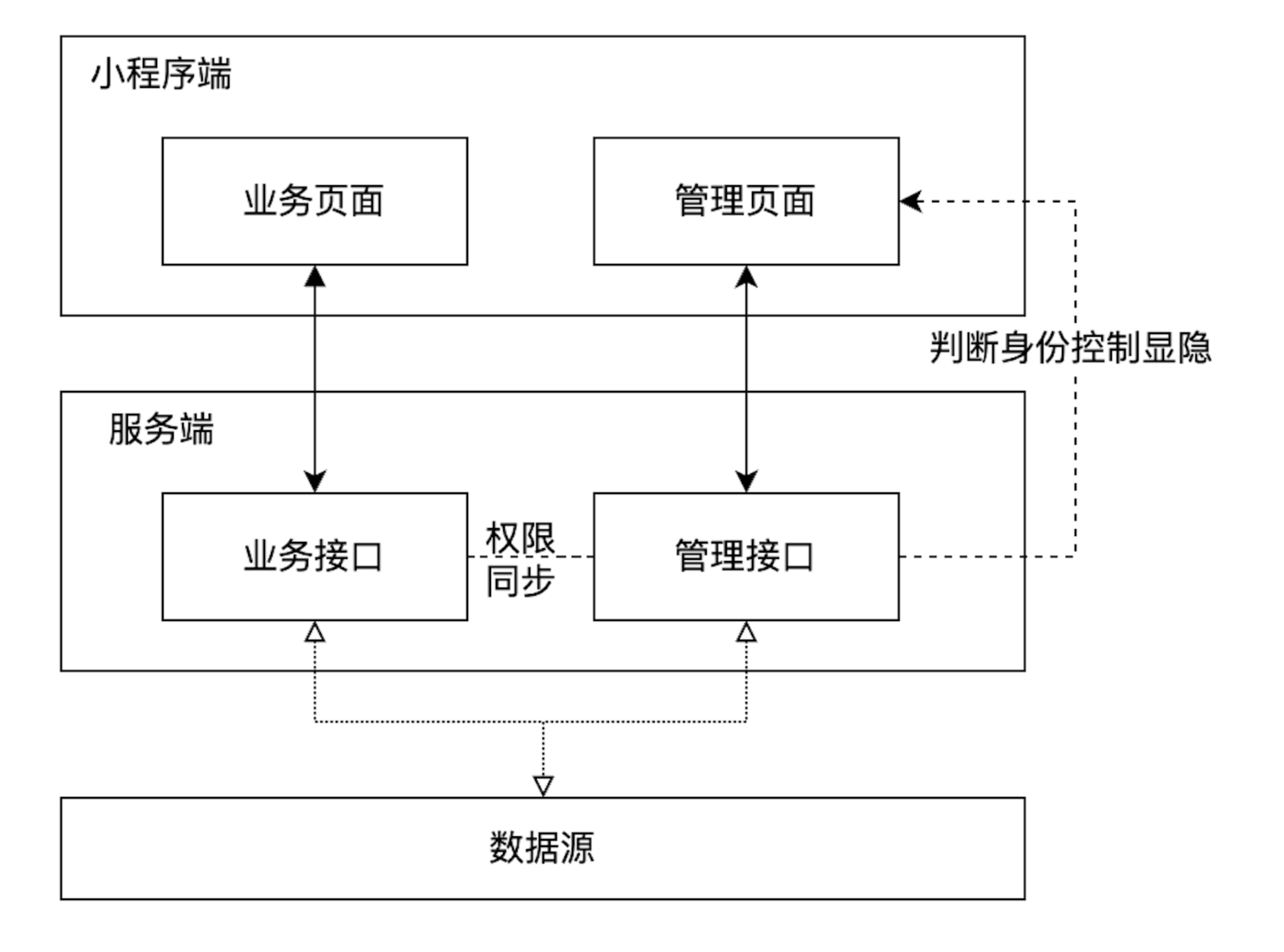
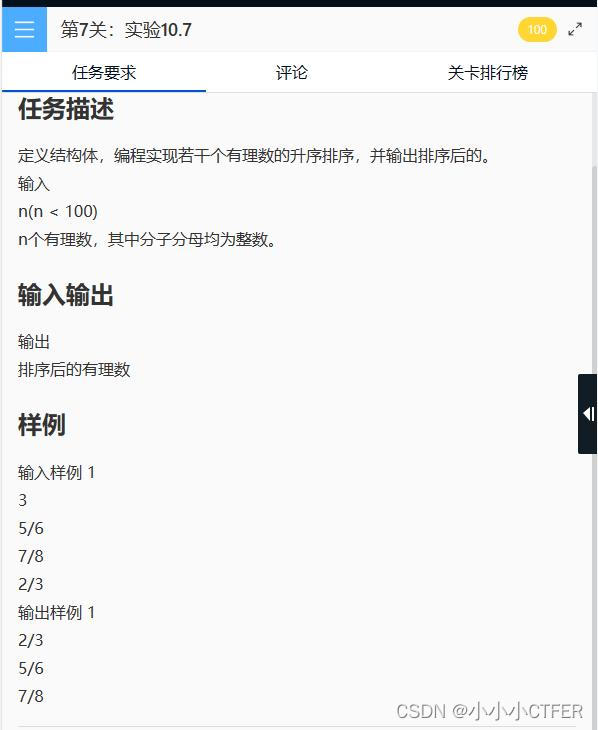
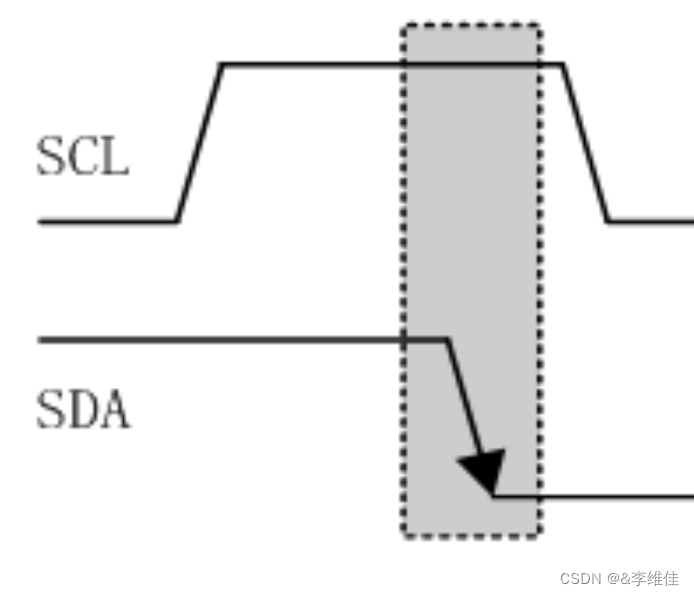
##这里下面的代码是截取url后面的文章id,然后比较小于200000的话,跳转到指定的页面
##注意 http://xxx.com/index.html 需要换成自己的页面
#set $article_id "";
#set $history_flag 1;
#set $min_article_id 10;
#
##获取url最后一个斜杠后面的内容,取到的是13562.html
#if ( $request_uri ~* ^.+/(.+)$){
# set $article_id $1;
#}
#
##获取 13562.html 中.之前部分,即文章id
#if ( $article_id ~* ^(.*)\.([^.]+)$){
# set $article_id $1;
#}
#
##只匹配数字的链接(列表等不考虑),发现这里不能使用{0,3}来匹配个数,只能折中处理,写多个或的条件,如果是5位数,直接跳转detail.html
#if ($article_id ~* ^(([1-9])|([1-9][0-9])|([1-9][0-9][0-9])|([1-9][0-9][0-9][0-9])|([1-9][0-9][0-9][0-9][0-9]))$) {
# rewrite ^/ http://xxx.com/index.html?id=$article_id last;
#}
#
##如果是6位并且以1开头(实际上匹配id是6位但是小于200000的文章),则重定向
#if ($article_id ~* ^([1][0-9][0-9][0-9][0-9][0-9])$) {
# rewrite ^/ http://xxx.com/index.html?id=$article_id last;
#}

Nginx 和 Apache 的比较
2024-03-29 09:58:03 50 阅读