需求与实现方法
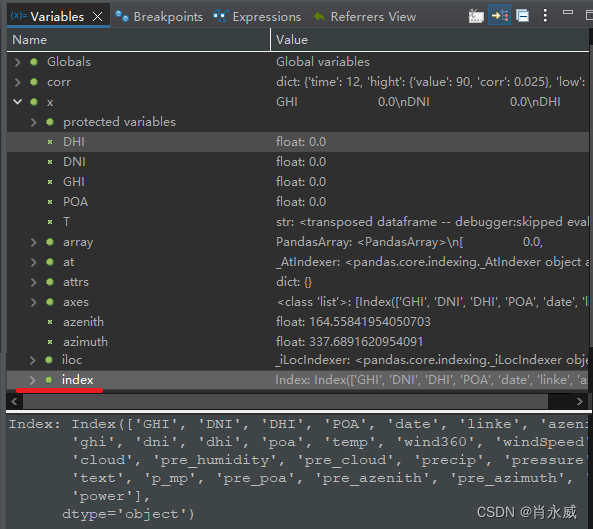
在pandas中,DataFrame的数据是时间索引,要求按时间(12点)为条件修改数据,使用apply和lambda。
pv_power['power'] = pv_power.apply(lambda x: x.ghi*0.05
if x.cloud > 25 and x.name.hour == 12 else x.power, axis=1)
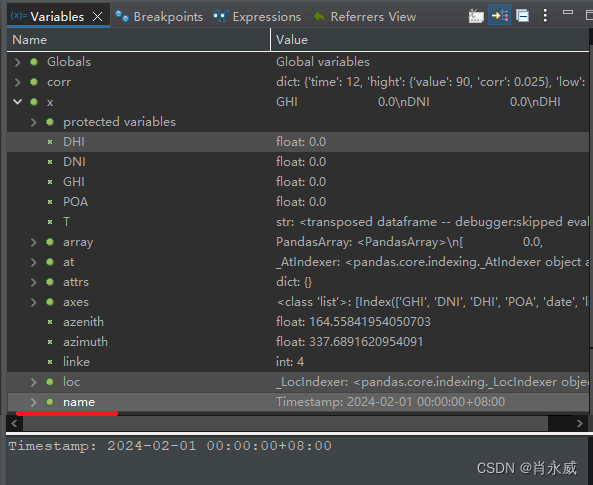
说明,这里的x是按行处理数据,这样每行就是一组Series,而Series的索引则是DataFrame的列名,DataFrame中的索引,也就我所需要的时间序列,则对应Series的name。
简明apply与lambda示例
import pandas as pd
# 创建一个简单的DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
}, index=['row0', 'row1', 'row2'])
print(df)
# 使用apply和lambda来读取行索引
df['C'] = df.apply(lambda row: row.name, axis=1)
df['D'] = df.apply(lambda row: row.index, axis=1)
df
相关知识点
apply
apply 函数是 pandas 库中 DataFrame 和 Series 对象的一个方法,它允许你对这些对象中的数据应用一个函数。下面是 apply 函数的一些常用语法和用法。
对于 DataFrame 对象,apply 函数的语法如下:
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds)
其中,各个参数的含义如下:
- func:要应用的函数。它可以是一个 Python 函数,也可以是一个字符串(例如 ‘sum’、‘mean’ 等)。
- axis:应用函数的轴。如果 axis=0(默认值),则函数将沿着列方向应用;如果 axis=1,则函数将沿着行方向应用。
- raw:是否将底层数据传递给函数。如果 raw=True,则传递底层 NumPy 数组;否则传递 Series 对象。
- result_type:结果类型。可以是 ‘expand’、‘reduce’ 或 ‘broadcast’。
- args:要传递给函数的额外参数。
- *kwds:要传递给函数的额外关键字参数。
注意事项:
l>ambda 函数通常用于简单的操作,如果需要进行复杂的操作,建议定义一个普通的函数。
apply 方法的 axis 参数用于指定函数应用的轴,axis=0 对列应用函数,axis=1 对行应用函数。
跟踪程序所看到的