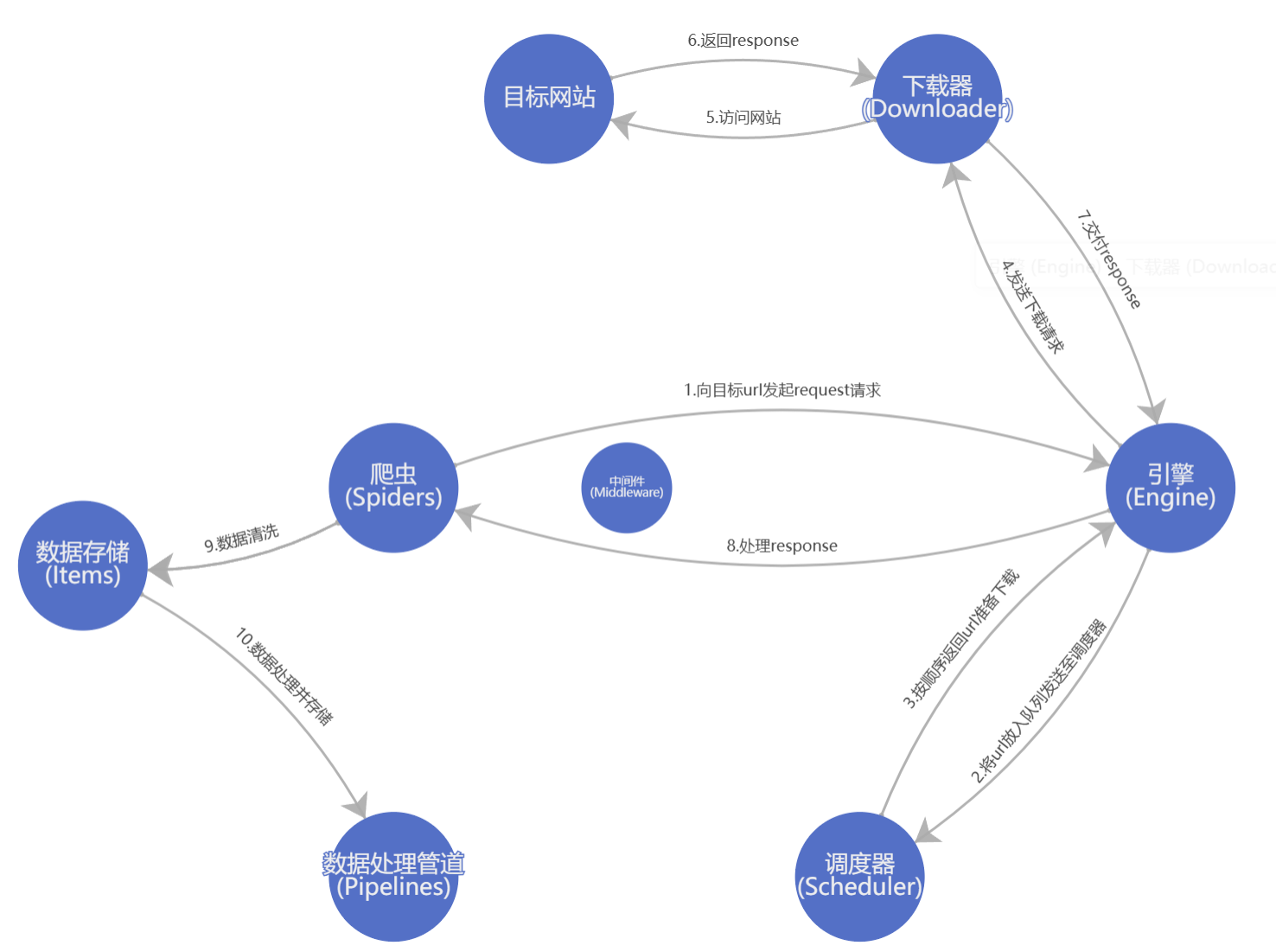
scrapy框架安装命令
1.需要安装python
链接: link
2.scrapy安装命令
python -m pip install Scrapy
3. 创建爬虫项目
scrapy startproject 项目名称
4.创建爬虫文件
scrapy genspider 爬虫名 域名
5.爬虫运行
scrapy crawl 爬虫名
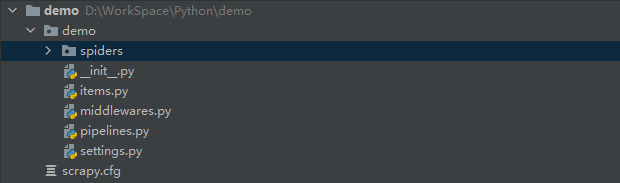
scrapy 项目目录介绍
PaC #项目文件名称
PaC #项目目录
items.py #定义数据结构
middlewares.py #中间件
pipelines.py #数据处理
settings.py #全局配置
spiders
pac.py #爬虫文件
scrapy.cfg #项目基本配置文件
settings.py 修改
# USER_AGENT = "PaMaoyan (+http://www.yourdomain.com)" 默认是注释掉的
# 写死 USER_AGENT = "Mozilla/5.0"
修改后 USER_AGENT = "Mozilla/5.0"
# ROBOTSTXT_OBEY = True 默认是True ***必须开启***
# True 是遵守 ROBOTSTXT 协议
修改后 ROBOTSTXT_OBEY = False
# 默认的最大并发量 默认16 不要设置太大
# CONCURRENT_REQUESTS = 32 默认是注释掉的
修改后 CONCURRENT_REQUESTS = 32
# 控制爬取的速度
# DOWNLOAD_DELAY = 3 默认是注释掉的
修改后 DOWNLOAD_DELAY = 0.5
# 请求头 ***必须开启***
# 可以添加 User-Agent
# DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
修改后:
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en",
}
简单试一下
1.example.py 文件中
import scrapy
class ExampleSpider(scrapy.Spider):
# 爬虫名
name = "baidu"
# 允许爬取的域名
allowed_domains = ["www.baidu.com"]
# 起始的url地址
start_urls = ["http://www.baidu.com"]
def parse(self, response):
item = response.xpath("/html/head/title/text()")
print("*"*50)
print(item)
print("*" * 50)
2.PaC项目目录 平级 创建 运行文件 run.py
# 右键 运行 run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl baidu".split())
成功运行
2024-03-27 17:03:52 [scrapy.utils.log] INFO: Scrapy 2.11.1 started (bot: PaMaoyan)
2024-03-27 17:03:52 [scrapy.utils.log] INFO: Versions: lxml 5.1.0.0, libxml2 2.10.3, cssselect 1.2.0, parsel 1.9.0, w3lib 2.1.2, Twisted 24.3.0, Python 3.12.2 (tags/v3.12.2:6abddd9, Feb 6 2024, 21:26:36) [MSC v.1937 64 bit (AMD64)], pyOpenSSL 24.1.0 (OpenSSL 3.2.1 30 Jan 2024), cryptography 42.0.5, Platform Windows-11-10.0.22631-SP0
2024-03-27 17:03:52 [scrapy.addons] INFO: Enabled addons:
[]
2024-03-27 17:03:52 [asyncio] DEBUG: Using selector: SelectSelector
2024-03-27 17:03:52 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2024-03-27 17:03:52 [scrapy.utils.log] DEBUG: Using asyncio event loop: asyncio.windows_events._WindowsSelectorEventLoop
2024-03-27 17:03:52 [scrapy.extensions.telnet] INFO: Telnet Password: addd51de00c6d2f6
2024-03-27 17:03:52 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2024-03-27 17:03:52 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'PaMaoyan',
'CONCURRENT_REQUESTS': 32,
'DOWNLOAD_DELAY': 3,
'FEED_EXPORT_ENCODING': 'utf-8',
'NEWSPIDER_MODULE': 'PaMaoyan.spiders',
'REQUEST_FINGERPRINTER_IMPLEMENTATION': '2.7',
'SPIDER_MODULES': ['PaMaoyan.spiders'],
'TWISTED_REACTOR': 'twisted.internet.asyncioreactor.AsyncioSelectorReactor'}
2024-03-27 17:03:52 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2024-03-27 17:03:52 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2024-03-27 17:03:52 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2024-03-27 17:03:52 [scrapy.core.engine] INFO: Spider opened
2024-03-27 17:03:52 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2024-03-27 17:03:52 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2024-03-27 17:03:52 [urllib3.connectionpool] DEBUG: Starting new HTTPS connection (1): publicsuffix.org:443
2024-03-27 17:03:53 [urllib3.connectionpool] DEBUG: https://publicsuffix.org:443 "GET /list/public_suffix_list.dat HTTP/1.1" 200 85074
2024-03-27 17:03:53 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.baidu.com> (referer: None)
2024-03-27 17:03:54 [scrapy.core.engine] INFO: Closing spider (finished)
2024-03-27 17:03:54 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 190,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 103543,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'elapsed_time_seconds': 1.251639,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2024, 3, 27, 9, 3, 54, 80375, tzinfo=datetime.timezone.utc),
'httpcompression/response_bytes': 405401,
'httpcompression/response_count': 1,
'log_count/DEBUG': 6,
'log_count/INFO': 10,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2024, 3, 27, 9, 3, 52, 828736, tzinfo=datetime.timezone.utc)}
2024-03-27 17:03:54 [scrapy.core.engine] INFO: Spider closed (finished)
**************************************************
[<Selector query='/html/head/title/text()' data='百度一下,你就知道'>]
**************************************************