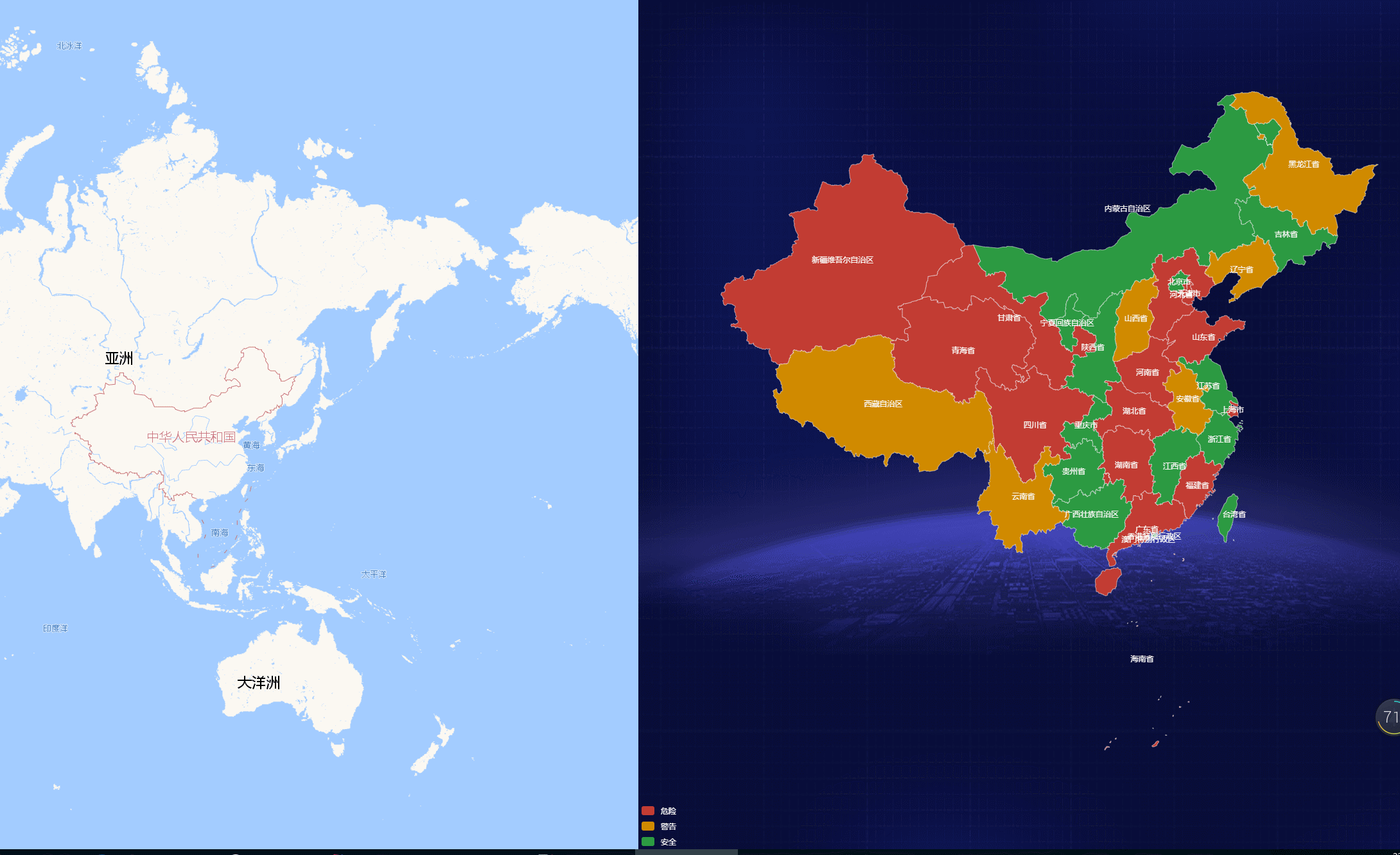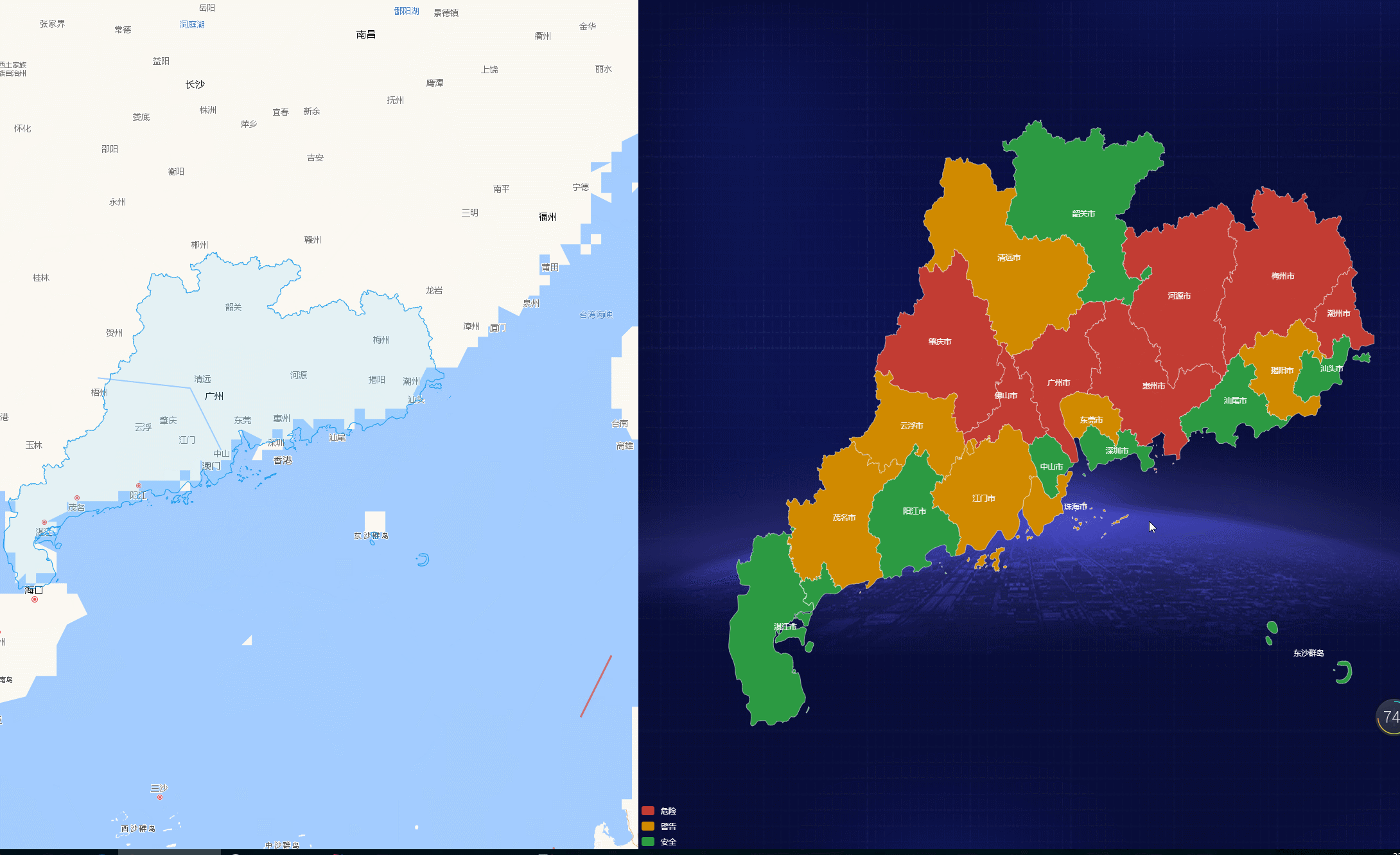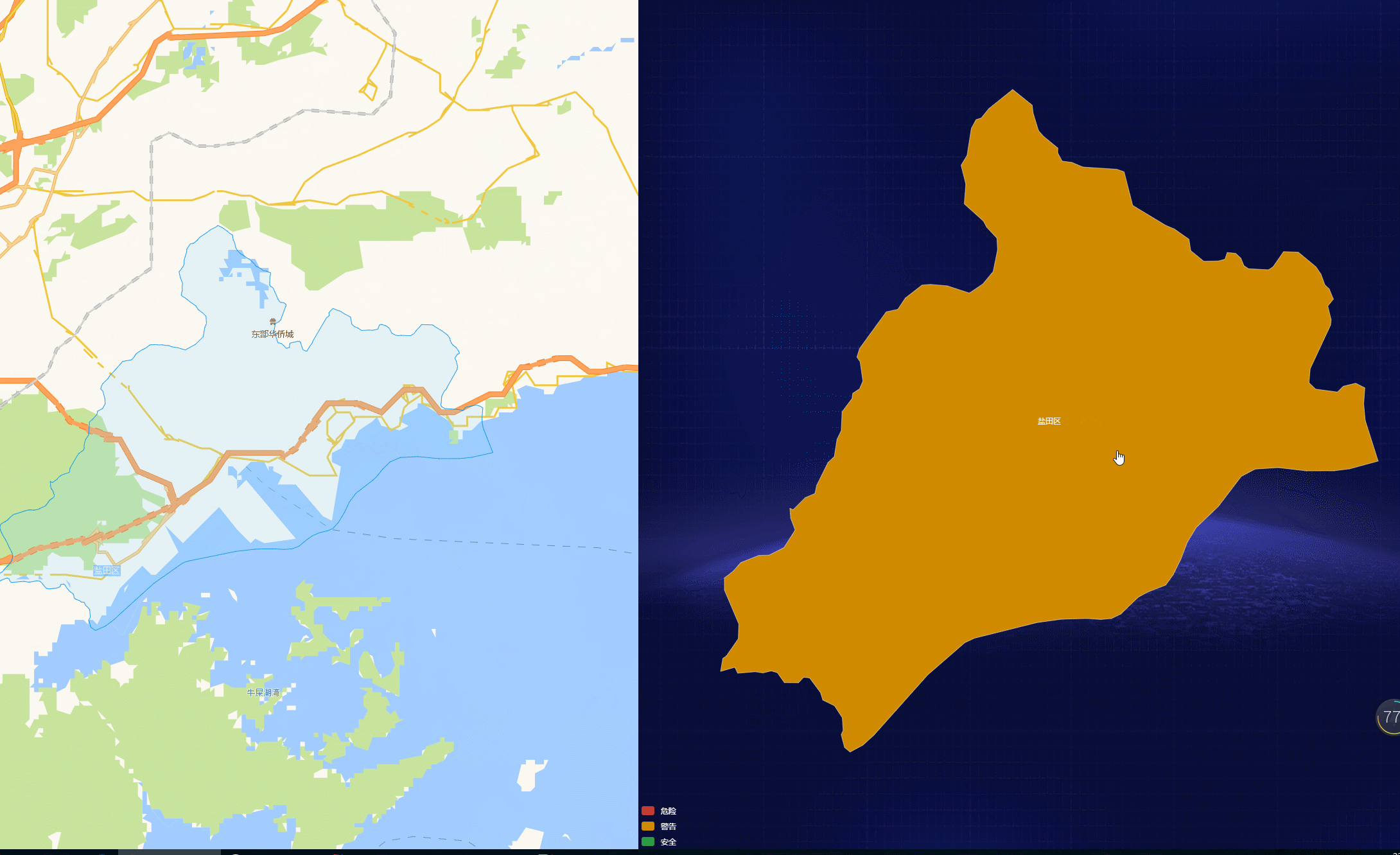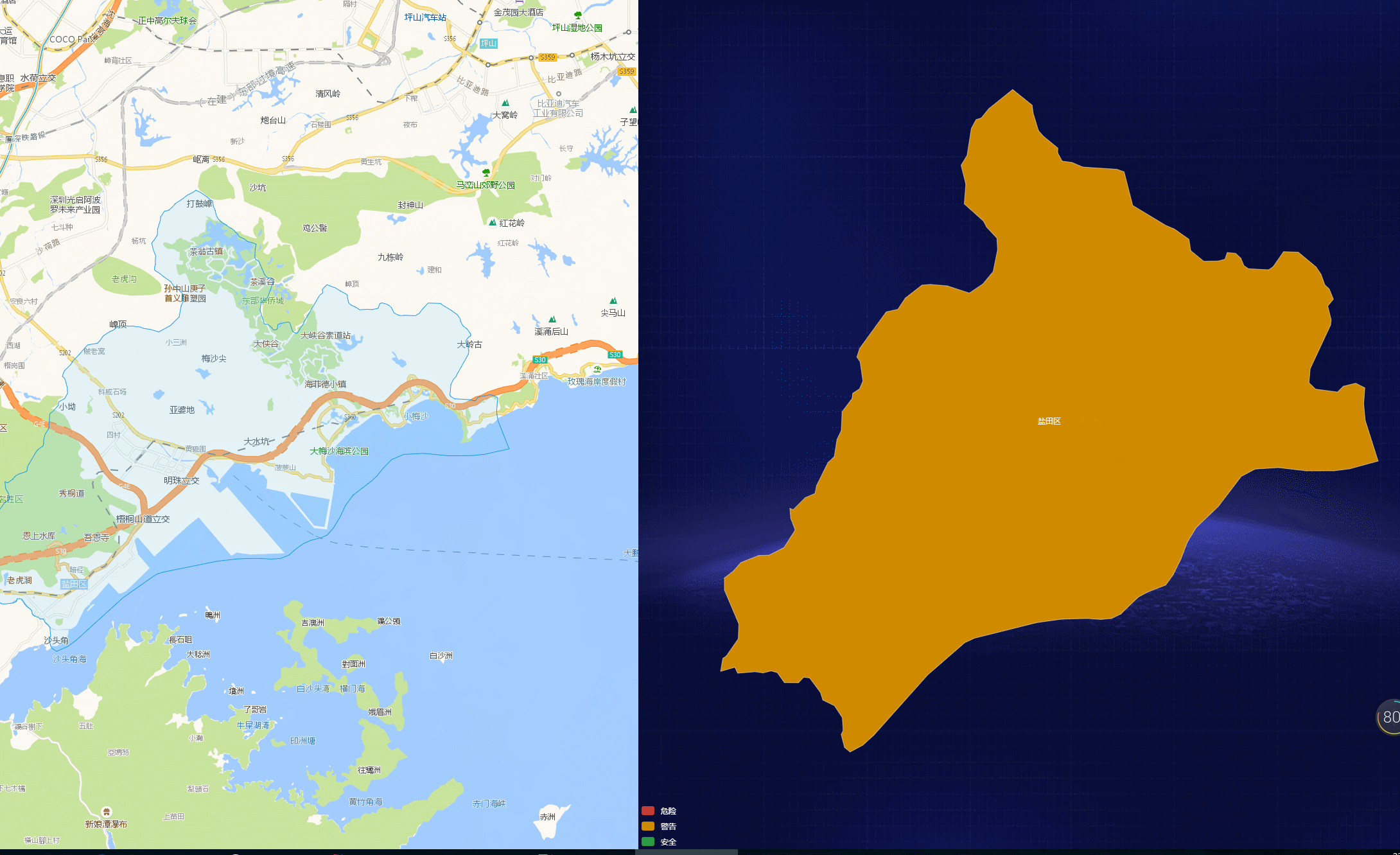
爬取地址https://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2023/
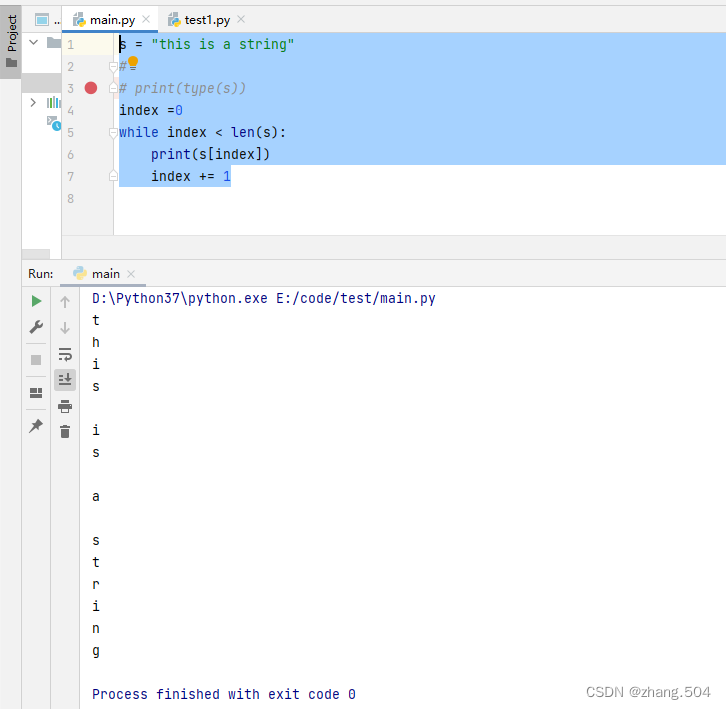
import re
import requests
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
import time
from lxml import etree
import pymysql
t ,urls ,names = [],[],[]
INDEX_URL = "https://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2023/" #初始url
# 创建连接
conn = pymysql.connect(host='127.0.0.1',
port=3306,
user='**',
passwd='**',
db='**',
charset='utf8mb4')
# 获取游标对象
cursor = conn.cursor()
insert_data_sql = "insert into region(code, name,pcode) values(%s, %s,%s);"
#row = cursor.execute(insert_data_sql, ('shark', 18))
headers = {
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
# 创建不验证证书的上下文
# context = ssl.create_default_context()
# context.check_hostname = False
# context.verify_mode = ssl.CERT_NONE
#获取省份页面
#province_response = urllib.request.urlopen(INDEX_URL + "index.html",context=context).read().decode("utf-8")
province_response = requests.get(INDEX_URL + "index.html")
province_response.encoding= 'utf-8' # 指定编码
# 获取省份列表
province_data = re.findall(r"<td><a href=\"(.*?)\">(.*?)<br /></a></td>", province_response.text)
def get_city_code(province_url,names,codes):
# 获取城市初始页
print(INDEX_URL + province_url)
print('爬取省份-----------------{}'.format(names))
global res
try:
city_response = requests.get(INDEX_URL + province_url)
city_response.encoding= 'utf-8' # 指定res的编码
#city_response = urllib.request.urlopen(INDEX_URL + province_url,context=context).read().decode("utf-8")
except Exception as a:
city_response = requests.get(INDEX_URL + "index.html")
city_response.encoding= 'utf-8' # 指定res的编码
#city_response = urllib.request.urlopen(INDEX_URL + province_url,context=context).read().decode("utf-8")
print(a)
# 获取地区名称 + 地区代码
city_data = etree.HTML(city_response.text) #etree.HTML(city_response)
for i in city_data.xpath('//tr[@class="citytr"]'):
code2 = i.xpath('td[1]//text()')[0]
name2 = i.xpath('td[2]//text()')[0]
cursor.execute(insert_data_sql, (code2, name2,codes))
conn.commit()
try:
url = i.xpath('td[1]/a/@href')[0]
get_area_code(url,code2)
except Exception as a:
print('异常url:',url)
print('异常城市:',name2)
print(f"An error occurred: {a}")
def get_area_code(city_url,codes):
# 获取区县
# print('请求城市',INDEX_URL + city_url)
try:
area_response = requests.get(INDEX_URL + city_url)
area_response.encoding= 'utf-8' # 指定res的编码
#area_response = urllib.request.urlopen(INDEX_URL + city_url,context=context).read().decode("utf-8")
# print('请求成功')
except Exception as a:
area_response = requests.get(INDEX_URL + city_url)
area_response.encoding= 'utf-8' # 指定res的编码
#area_response = urllib.request.urlopen(INDEX_URL + city_url,context=context).read().decode("utf-8") #错误后重新调用方法
# 获取街道名称 + 街道代码
area_data = etree.HTML(area_response.text)
if len(area_data)==0:
print("---------------------区县异常------------------------------",city_url)
for i in area_data.xpath('//tr[@class="countytr"]'):
code3 = i.xpath('td[1]//text()')[0]
name3 = i.xpath('td[2]//text()')[0]
cursor.execute(insert_data_sql, (code3, name3,codes))
conn.commit()
def get_street_code(area_url):
global res
# 获取街道初始页
try:
street_response = requests.get(INDEX_URL + area_url)
street_response.encoding= 'utf-8' # 指定res的编码
#street_response = urllib.request.urlopen(INDEX_URL + area_url[3:5] + "/" + area_url,context=context).read().decode("utf-8")
except Exception as a:
street_response = requests.get(INDEX_URL + area_url)
street_response.encoding= 'utf-8' # 指定res的编码
#street_response = urllib.request.urlopen(INDEX_URL + area_url[3:5] + "/" + area_url,context=context).read().decode("utf-8")
print(a)
# print(street_data)
street_data = etree.HTML(street_response.text)
if len(street_data)==0:
print("---------------------------------------------------",area_url)
# 获取街道名称 + 街道代码
for i in street_data.xpath('//tr[@class="towntr"]'):
code4 = i.xpath('td[1]//text()')[0]
name4 = i.xpath('td[2]//text()')[0]
new_row = pd.Series({'代码':code4,'区域':name4})
res = pd.concat([res,new_row.to_frame() ], ignore_index=True)
for url, name1 in province_data:
# 获取省份名称 与 代码
code1 = url.replace(".html", "") + "0" * 10
if url not in urls:
cursor.execute(insert_data_sql, (code1, name1,0))
conn.commit()
get_city_code(url,name1,code1)