文章目录
- 1. Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation
- 2. Click to Grasp: Zero-Shot Precise Manipulation via Visual Diffusion Descriptors
- 3. 【CoRL 2023】Dexterous Functional Grasping
- 4. 【CVPR2023】Affordances from Human Videos as a Versatile Representation for Robotics
1. Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation
摘要和结论
本文介绍了Robo-ABC框架,这是一个旨在提高机器人在操作任务中泛化能力的方法,特别是在面对未见过的物体时。
- Robo-ABC通过从互联网上的人类视频中提取可操作性记忆(包括接触点),使机器人能够通过检索视觉或语义上相似的物体来获取新的可操作性。(extract an affordance memory including the contact points)
- 该框架利用预训练的扩散模型 自然地 建立对应关系,从而实现跨不同物体类别的可操作性映射。Robo-ABC不需要手动注释、额外训练、部分分割、预编码知识或视角限制,就能以零样本的方式泛化操作跨类别物体。
- 实验结果表明,Robo-ABC在视觉可操作性检索的准确性上比现有最先进(SOTA)的端到端可操作性模型提高了31.6%,在跨类别物体抓取任务中实现了85.7%的成功率。
引言
- 真正的机器人,根本的挑战在于让机器人能够找到与熟悉和新颖物体的交互策略。
- 首先,我们从人类视频中提取物体的交互体验并将其存储在可供性记忆中。
- 其次,面对新奇的物体(例如螺丝刀),我们根据视觉和语义相似性从记忆中检索与目标物体相似的物体(例如刀)。
- 最后,我们利用扩散模型中的新兴语义对应能力将检索到的接触点映射到新对象
相关工作
之前的工作致力于识别人类视频中物体的接触区域,而这种端到端的可操作性预测方法受限于域内物体实例和视角。与之前的作品相比,Robo-ABC从人类视频中提取了一个小规模的物体互动经验记忆 (small-scale memory of object interaction experiences),它允许机器人面对全新的场景,并转移可操作性知识。
从扩散模型中提取的特征在跨类别映射相似点方面更加通用。由于基础模型包含对机器人任务有价值的知识,我们探索利用这些模型中嵌入的语义对应知识,消除额外训练或零件分割的需要。
一些工作专注于使用点云作为输入,识别和操作可操作的部分以实现跨类别物体操作。然而,这些方法通常需要大量的注释数据或依赖于物体的有效部分分割。最近关于通用代理和灵巧抓取的工作继续探索新的可能性。
另一系列研究利用基础模型和NeRF进行通用操作。然而,这些代理的操作技能局限于已知实例的集合,并且在遇到新奇物体实例时,它们的泛化能力不足。
相比之下,本文的主要动机是利用基础模型提取语义信息,并实现跨类别的可操作性泛化。
模型框架

3.1. Affordance collection from human videos
这部分在介绍Robo-ABC框架如何从人类视频中提取可操作性信息的过程。
- 作者将物体的可操作性定义为人类手与物体之间的接触点。(影响了后面的评价指标和实验)
- 在收集可操作性信息时,作者希望图像清晰,最好没有人类遮挡物体。但是,需要手-物体接触的帧来推断接触点。为了解决这个矛盾,作者旨在将这些接触点映射回一个物体未被遮挡的帧Fc
- Robo-ABC能够从人类视频中学习和记忆物体的可操作性信息,为后续的泛化和机器人操作任务提供基础。
3.2. The most similar object retrieval from memory
当面对一个新物体时,首先使用相机捕捉该物体的图像。然后,使用一个图像编码器(如CLIP模型)将捕获的物体图像映射到一个特征向量中。同样的,记忆中的每个物体图像也通过相同的编码器映射到特征向量。
为了衡量新物体与记忆库中物体的相似性,计算新物体特征向量与记忆库中物体特征向量的余弦相似度。根据相似性,将物体分为两类:一类是记忆中已经遇到过的同一类别的物体;另一类是完全新的物体类别。
对于已见过的物体类别,从同一类别中检索最相似的物体。对于全新的物体类别,从记忆库中的所有物体中检索最相似的物体,不考虑类别。
通过这种检索机制,Robo-ABC能够找到与新物体在视觉和语义上最接近的已知物体,
3.3. Semantic correspondence mapping for affordance generalization
检索最相似物体:在面对新物体时,首先从可操作性记忆中检索出最相似的物体,并获取其接触点信息。
利用扩散模型的能力:作者利用扩散模型中自然出现的语义对应能力,将检索到的接触点映射到新物体上。扩散模型通过向目标图像添加噪声然后去噪的过程中,同时提取中间隐藏的特征。
提取扩散特征(DIFT):通过向目标图像添加噪声并进行去噪处理,同时提取U-Net中的中间隐藏特征,生成扩散特征。这些特征对应于目标图像中的每个像素,可以用来找到与源图像中接触点最相似的像素。
处理源图像的变换:由于扩散特征对源图像和目标图像之间的方向不匹配比较敏感,作者对源图像应用了8种旋转和翻转变换,并选择所有变换中相似性最高的结果。
选择目标图像中的对应点:在目标图像的扩散特征中找到与源图像接触点最相似的像素。这一步骤涉及到在目标图像中寻找与检索到的接触点最匹配的点,以实现跨物体和类别的可操作性泛化。
我们的目标是找到目标图像中的对应点pt。我们按照[44]中描述的步骤提取源图像Is和目标图像It的扩散特征(DIFT)。扩散特征是通过首先向目标图像添加噪声,然后通过扩散过程对其进行去噪,同时从U-Net中提取中间隐藏特征来生成的。我们建议读者参考原始论文
实验


16个物品。

评价指标:

2. Click to Grasp: Zero-Shot Precise Manipulation via Visual Diffusion Descriptors
摘要和结论
- 跨场景和对象的精确操作仍然是机器人技术中持续存在的挑战。当前用于此任务的方法在很大程度上依赖于拥有大量训练实例来处理具有明显视觉和/或几何部分模糊性的对象。
- 我们通过将其构建为密集语义部分对应任务来解决该问题。
- 我们的模型返回用于操纵特定部分的抓手姿势,使用来自同一对象的视觉不同实例的源图像的用户定义的单击作为参考。
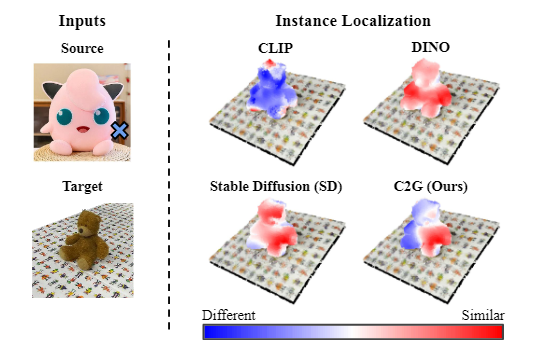
零样本定位热图,用于通过左上方源图像的单击演示来识别目标毛绒玩具的左臂。当使用自然语言提示(即“左臂”)进行查询时,CLIP 会导致不相关区域的更高激活。 DINO 在两个手臂实例上都获得了很高的相似度分数,但对左臂没有明显的偏好。 SD 特征导致左侧高度激活,但并不局限于手臂。我们的 C2G 方法正确识别左臂
引言
视觉线索比语言指令具有明显的优势,因为语言可能缺乏描述精确交互区域的粒度(图1),或者当存在通信障碍时。
以零样本方式处理相关任务的一种流行方法是将网络训练的基础模型的特征融合到场景表示中。但值得注意的限制仍然存在:派生特征的粒度通常不会扩展到对象级之外,而不是更多的局部部分(见图 1)。
最近,扩散模型已经成为文本到图像生成的主流选择。与之前的视觉模型类似,人们对利用中间特征作为下游视觉任务的表示越来越感兴趣。特别是,即使在 zeroshot 设置中,这些特征图也会导致密集语义对应任务的最佳性能 。
与我们的用例最相关的是使用来自 SD 的中间 U-Net 特征作为 2D 密集语义对应任务的视觉描述符
模型框架

A Problem Formulation
- 提供 RGB 图像和深度图,我们利用它来开发 3D 场景表示 F。我们的目标是创建一个模型 O,对于任何给定的目标场景和源图像,能够精确确定应用于机械臂末端执行器的变换 T ∈ SE(3)。
B. Scene Representation
- 我们从每个目标 It 和源 Is RGB 图像中提取特征。对于 DINO,我们遵循现有技术 [2]、[4]、[22] 保留最后一层的特征图。
- 对于 SD,我们选择通过对输入图像进行噪声处理并从 UNet 中提取中间特征图来部署反演过程,类似于 [23]。然而,我们只保留第一个时间步和第四层的输出。这种选择使我们能够保持低维表示,这对于我们的任务来说具有足够的描述性,因为已经直观地证明了 SD 中 U-Net 中间层的特征图在较低级别的概念之间提供了良好的平衡,例如如形状和轮廓,以及更高级别的,如纹理 [22]–[24]、[45]。
C. Source Image Descriptor
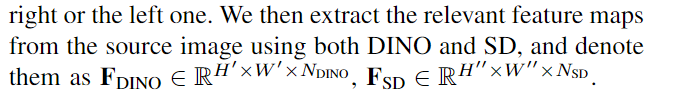
如何区分相似度高的局部细节?
- 依靠 DINO 的定位功能来识别源图像中用户定义部分的所有实例。(玩具熊的左右胳膊)
- 我们从 FDINO 和 FSD 中提取描述符 dDINO 和 dSD 作为已识别质心的坐标,并将空间上最接近用户定义的点击指定为正 (d+DINO,d+SD),将其他指定为负 (d−DINO, d−SD)。我们根据经验发现,识别正样本和负样本是必要的,这不仅是为了在场景中准确地执行部分检测,而且最重要的是,为了解决语义歧义,如下所述
D. Identifying Target Scene Area of Interaction
Part detection
d+DINO 和 d−DINO 都会导致当前零件实例的所有区域更高的激活。鉴于两个相似点之间的微小差异,DINO 未能定位出明确的候选交互区域。
因此,我们利用这些特征进行部分检测,通过将两个描述符的相似性分数相乘,增加相关区域的相似性分数,并减少其他地方的相似性分数:


Part Instance Disambiguation
然后,我们依靠 SD 特征,从 DINO 检测到的部件实例中选择最相关的部件实例。再次,我们计算 SD 描述符和 VSD 之间的余弦相似度,这会导致相对嘈杂的相似度热图。如图2(d-2)所示,在相应的用户定义实例的更广泛区域中,相似度得分通常较高,但这对于实例选择来说不够可靠,因为所有部分都存在相对较高的得分。我们发现,通过添加对比组件,分别计算 d+SD 和 d−SD 的相似度分数之间的差异,所得热图变得更适合实例消歧:

Area of Interaction
最后,我们利用所得的相似度分数 SIMDINO、SIMSD 来提出场景中的交互区域 A。我们将每个坐标乘以阈值化 SIMDINO 的最小-最大归一化相似度分数和最小-最大归一化 SIMDINO 相似度:
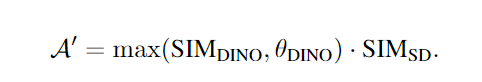
实验


3. 【CoRL 2023】Dexterous Functional Grasping

摘要和结论
灵巧的手相对于两指手的主要好处是能够拾起工具和其他物体(包括薄的物体)并牢牢抓住它们以施加力量。然而,这项任务既需要①对功能可供性的复杂理解,②也需要精确的低级控制。
虽然之前的工作从人类数据中获得了可供性,但这种方法无法扩展到低级控制。同样,模拟训练无法让机器人理解现实世界的语义。
在本文中,我们的目标是结合两者的优点来实现对广泛物体的功能性抓取。我们使用模块化方法。首先,通过匹配不同对象的相应区域来获得可供性,然后运行在 sim 中训练的低级策略来掌握它。
我们提出了一种特征抓取的新颖应用,使用少量的人类数据来减少强化学习的搜索空间。
引言
- 功能性抓取的行为几乎是人类的肌肉记忆,不仅仅是一个控制问题,而是位于感知、推理和控制的交点。
- pipeline分为三个阶段:预测预抓取、学习抓取的低级控制、抓取后轨迹视觉推理是第一阶段和第三阶段的关键部分,第二阶段只要预握姿势合理,就可以利用本体感觉盲进行。
模型框架
给定一个要抓握的物体,我们使用可供性模型来预测手的合理的功能抓握姿势。然后,我们训练盲拾取策略来拾取物体,紧紧抓住它,以便手臂执行抓取后的轨迹。
在预抓取阶段,可供性模型输出对象的感兴趣区域,我们使用该区域周围的局部对象几何形状来计算合理的预抓取姿势。
我们训练 sim2real 策略来执行强大的拾取操作。然而,与简单奖励函数就足够的两个手指操作或运动相比,在复杂的高维灵巧情况下,很容易陷入局部最小值或在模拟中执行在现实世界中无法实现的姿势。
因此,我们使用人类数据来提取完整动作空间的低维子空间,并在受限动作空间内运行强化学习。根据经验,这会导致物理上合理的姿势可以转移到真实且更稳定的强化学习训练中。总的来说,以这种方式分解管道使我们能够泛化到更广泛的对象。由于在互联网数据上训练的可供性模型,我们的盲目策略可以推广到广泛的对象,即使它在训练时只看到锤子。
2.1 Pre-grasp pose from affordances
可接近性描述了物体上与使用目的相关的区域,这通常不能仅从物体的几何形状推断出来,而是取决于物体预期的正确使用方式。
2.2 Sim2real for dexterous grasping
一旦我们的手靠近想要抓取的物体,即使闭上眼睛也能通常将其捡起。然而,挑战在于,学习这种高频闭环行为通常需要大量的交互数据。模拟器中进行RL可以弥补。
但高维动作空间中进行强化学习(RL)是不稳定的或样本效率低的。作者提出了利用少量人类数据来限制动作空间到物理上真实的姿势。
实验


不足之处
严重依赖DINOV2提供的抓取pose
- 虽然我们的方法对于预抓取姿势中的轻微错误具有鲁棒性,但如果错误很大,则盲目抓取策略无法恢复。解决这一限制的一种方法是为机器人配备手腕周围的局部视野,这样即使可供性模型不正确,它也可以微调其抓握能力。
没有指关节姿势的信息。
- 我们的方法目前不利用可供性模型中的关节姿势信息。虽然我们发现这在我们拥有的一组对象中不是必需的,但在更细粒度的操作(例如拾取硬币或信用卡等非常薄的对象)的情况下可能很有用
4. 【CVPR2023】Affordances from Human Videos as a Versatile Representation for Robotics
摘要和结论
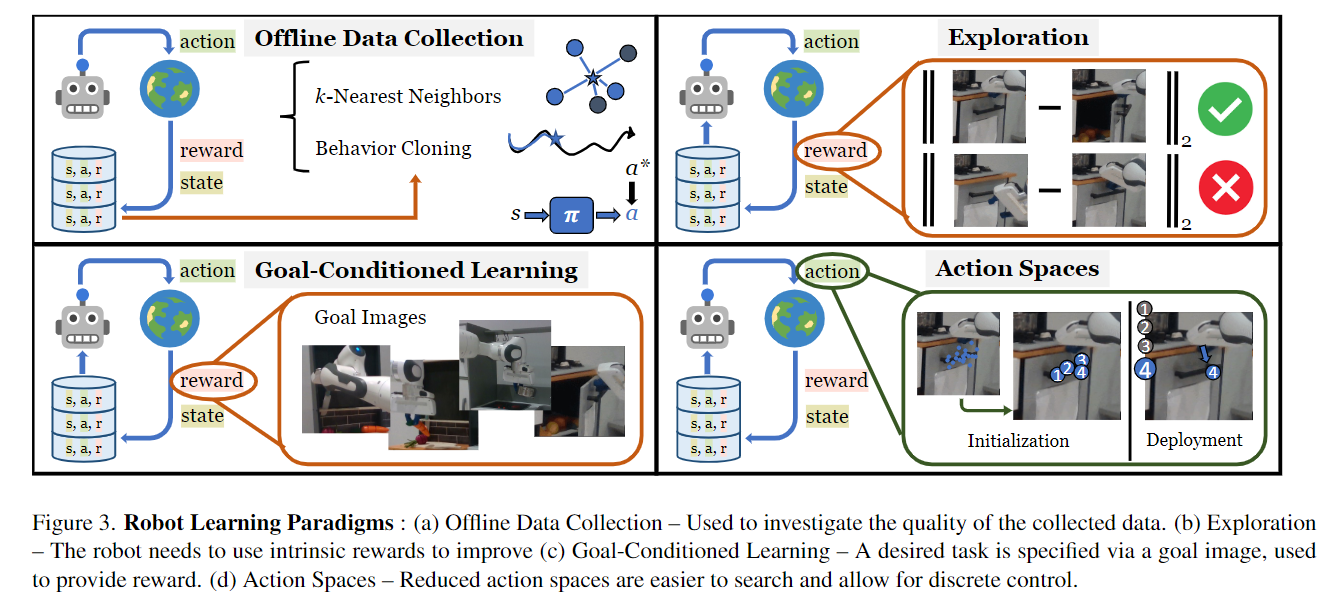
- 我们训练了一个视觉可视性模型,该模型估计人类可能交互的场景中的位置和方式。我们展示了如何将我们的可视性模型与四种机器人学习范式无缝集成。
引言
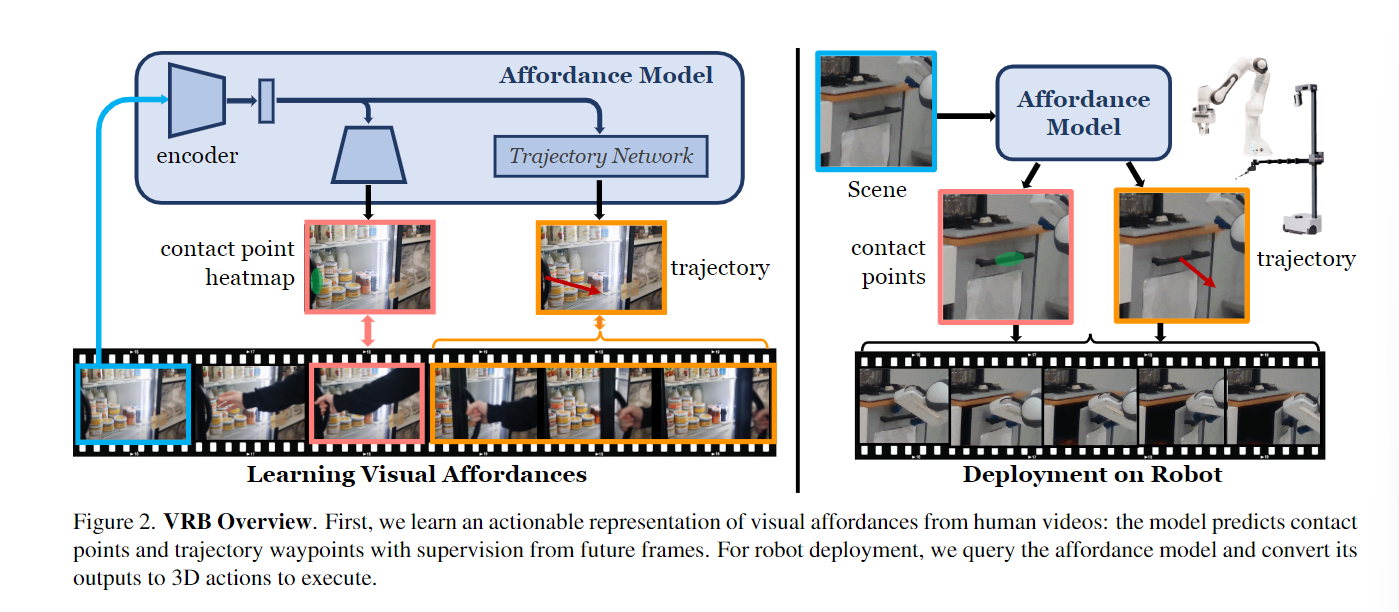
人类严重依赖对象的这种视觉可供性,以有效地跨环境执行日常任务。从视频中提取这种可操作的知识长期以来一直启发了视觉社区。
相反,大多数机器人的学习方法,无论是模仿还是强化学习,都是简单地处理新任务或新环境。在最好的情况下,视觉表示可能会在一些数据集上进行预训练。然而,视觉表现只是更大问题的一小部分。
在机器人技术中,特别是在连续控制中,状态空间复杂度随动作呈指数增长。因此,即使拥有完美的感知,知道该做什么也是困难的。给定一张图像,目前的计算机视觉方法可以标记大多数物体,甚至告诉我们它们的大致位置,但这还不足以让机器人执行任务。它还需要知道在哪里以及如何操作对象,除了最简单的任务外,在每个新环境中从头开始弄清楚这一点几乎是不可能的。我们如何缩小视觉学习和机器人之间的明显差距?
我们认为,丰富的人类交互视频数据集可以提供更多可操作的信息,而不仅仅是取代 ImageNet 作为机器人学习的预训练视觉编码器。特别是,人类交互是如何握持各种物体以及操纵其状态的有用方法的丰富来源。然而,一些挑战阻碍了视觉和机器人技术的顺利集成。
我们将它们分为三个部分。首先,什么是表示可供性的可行方法?其次,如何以数据驱动和可扩展的方式学习这种表示?第三,如何调整视觉可供性以适应跨机器人学习范式的部署?
为了回答第一个问题,我们发现接触点和接触后轨迹是视觉可供性的优秀的以机器人为中心的表示,以及对可能交互的固有多模态进行建模。我们有效地利用以自我为中心的数据集来解决第二个问题。特别是,我们重新表述数据,将重点放在没有人类的帧上,以预测接触点和接触后轨迹。为了提取对此预测的自由监督,我们利用现成的工具来估计自我运动、人体姿势和手部物体交互。最后,我们展示了如何将这些可供性先验与不同类型的机器人学习范例无缝集成。因此,我们将我们的方法称为视觉机器人桥(Vision-Robotics Bridge,VRB),因为它的核心目标是桥接视觉和机器人技术。
Affordances from Human Videos (VRB)
3.1. Actionable Representation for Affordances
作者讨论了如何从人类互动视频中提取视觉可供性(affordances)的可操作表示。这一节的核心思想是,为了使机器人能够有效地与环境互动,需要一种能够指导机器人如何操作物体的表示方法。这种表示不仅应该能够识别出物体,还应该能够指出操作的具体位置和方式。
作者提出了两个关键的概念来表示视觉可供性:
接触点(Contact Points):通过观察人类如何与物体互动,模型可以学习到在物体的哪些部位进行抓取或操作是最有意义的。接触点的预测使得机器人知道应该在哪里与物体接触,以便执行特定的任务。
接触后轨迹(Post-Contact Trajectories):一旦确定了接触点,接下来需要预测的是手在接触物体后的运动轨迹。这涉及到理解物体的操作方式,例如,打开门时手应该如何移动门把手,或者拿起杯子时手应该如何向上移动。这些轨迹提供了关于如何在接触点之后继续操作物体的信息。
3.2. Learning Affordances from Egocentric Videos
在论文的第3.2.1节 “Extracting Affordances from Human Videos” 中,作者详细介绍了如何从人类互动视频中提取视觉可供性(affordances)。这一过程是实现机器人学习的关键步骤,因为它涉及到从视频数据中学习人类如何与环境中的物体互动。以下是该过程的主要步骤:
视频帧分析、手部检测、接触点提取、处理相机运动、人-机器人视觉领域的变化。
在论文的第3.2.2节 “Training Affordance Model” 中,作者详细描述了如何训练视觉可供性模型(affordance model)。这个模型的目标是基于输入图像预测接触点和接触后轨迹,这些预测将用于指导机器人执行任务。以下是训练过程中的关键步骤:
模型架构:作者使用了一个基于ResNet的视觉编码器来提取图像的空间潜在表示。然后,通过反卷积层将这个潜在表示投影到多个概率分布或热图上。这些热图用于估计高斯混合模型(GMM)的均值,即接触点的位置。
多模态预测:由于学习问题本质上是多模态的(例如,拿起杯子和拿起桌子的方式可能完全不同),作者使用相同的模型预测多个热图来构建空间概率分布。这样做可以通过softmax函数得到GMM均值的估计值。
损失函数:为了训练模型预测接触点,作者定义了一个损失函数,该函数计算预测的接触点和真实接触点之间的均方误差。
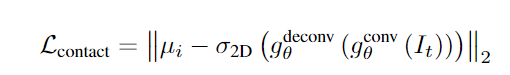
轨迹预测网络:为了估计接触后的轨迹,作者训练了一个基于潜在表示的轨迹预测网络。由于优化绝对位置比较困难,作者选择优化相对移动方向,假设第一个点是原点(即接触点)。轨迹预测网络使用自注意力块进行训练,以优化预测的轨迹和实际轨迹之间的误差。
处理不确定性:由于场景中可能包含训练数据中未出现过的物体,作者通过采样接触点周围的局部图像区域作为网络的输入,来处理这种不确定性,并避免虚假的相关性。这种方法有助于模型更好地泛化到新场景。
训练过程:模型在包含大量图像-轨迹-接触点元组的数据集上进行训练。通过这种方式,模型学习到了如何从视觉输入中预测人类可能与物体互动的方式。
通过这种训练方法,作者的视觉可供性模型能够学习到如何从人类视频中提取有用的可供性信息,并将其应用于指导机器人执行任务。这个模型为机器人提供了一种理解人类如何与环境互动的方式,并能够将这些知识转化为机器人可以执行的具体动作。
3.3. Robot Learning from Visual Affordances
作者探讨了如何将从人类视频中学习到的视觉可供性(visual affordances)应用于机器人学习。这一部分的核心是展示如何将可供性模型集成到不同的机器人学习范式中,以提高机器人在执行任务时的性能。以下是作者提出的几种机器人学习范式和相应的方法:
A. 模仿学习(Imitation Learning)
离线数据收集:使用可供性模型来引导机器人进行“有趣”的互动,从而收集数据。这些数据可以用于行为克隆(behavior cloning)或通过k-最近邻(k-NN)方法来完成特定任务。
行为克隆:通过训练一个策略网络,该网络预测给定图像的接触点和轨迹,然后在真实系统上运行该策略。
B. 无奖励探索(Reward-Free Exploration)
探索方法:使用内在奖励来引导机器人探索新技能,这些技能可能有助于解决下游任务。通过使用可供性模型,机器人可以专注于可能对人类感兴趣的场景部分。
精英拟合方案:通过拟合高探索性轨迹的分布,然后重复该过程,从而提高探索效率。
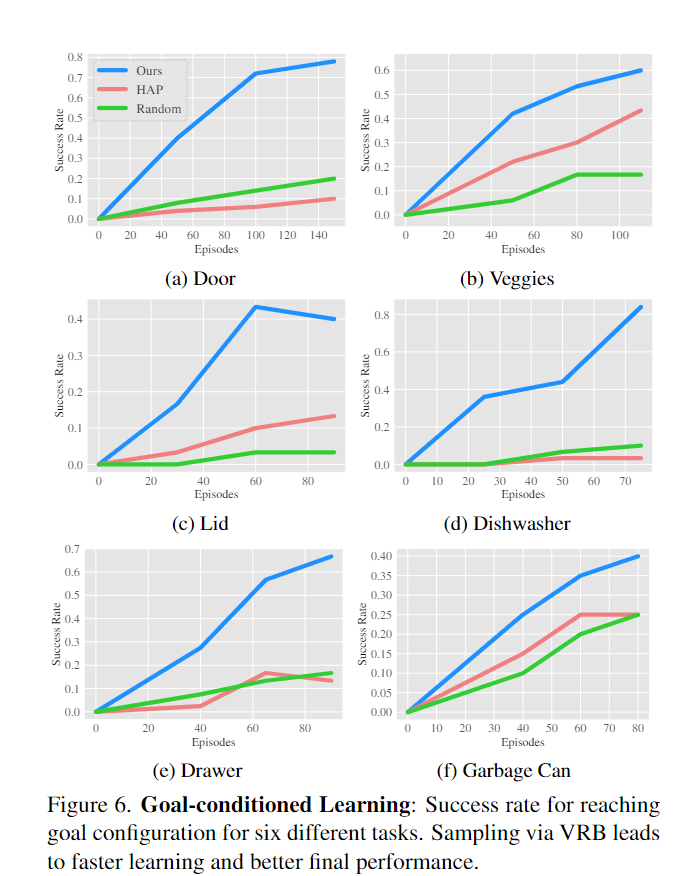
C. 目标条件学习(Goal-Conditioned Learning)
目标指导策略搜索:使用目标图像(例如,打开的门)来指导机器人的策略搜索。这允许机器人使用已知的目标来改进其行为。
最小化目标距离:通过采样目标分布并最小化与目标图像的视觉变化,来指导数据收集。
D. 可供性作为动作空间(Affordance as an Action Space)
参数化动作空间:使用可供性模型来定义一个离散的动作空间,其中每个动作对应于一个特定的接触点和轨迹。
强化学习:在这个离散的动作空间上训练一个深度Q网络(DQN),以解决目标条件学习问题。
实验





![[R] Why data <span style='color:red;'>manipulation</span> is crucial and sensitive?](https://img-blog.csdnimg.cn/direct/4718e637586c4cc5aaf05074c65a8885.png)