BiFormer图像分类实战教程
零、BiFormer介绍
标题:BiFormer: Vision Transformer with Bi-Level Routing Attention
论文:https://ieeexplore.ieee.org/document/10203555
https://arxiv.org/abs/2303.08810
GitHub:https://github.com/rayleizhu/BiFormer
模型结构
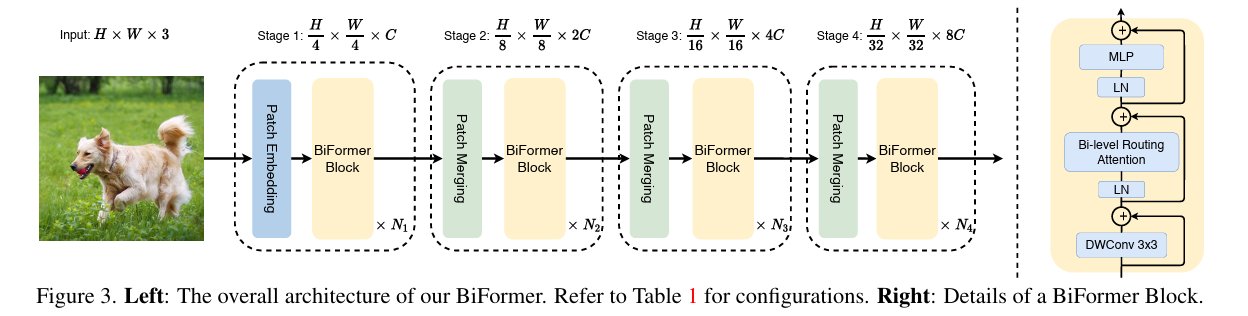
1.论文介绍:
BiFormer是一种新型的视觉Transformer架构,它通过引入一种称为Bi-Level Routing Attention(BRA)的机制来提高计算效率和性能。这种机制通过在粗粒度的区域级别上过滤掉与查询无关的键值对,然后在剩余的候选区域(即路由区域)中应用细粒度的令牌对令牌注意力。BiFormer的设计旨在使查询能够以自适应的方式关注一小部分最相关的令牌,从而在不受到其他无关令牌干扰的情况下提高性能。BiFormer在多个计算机视觉任务上进行了实证测试,包括图像分类、目标检测和语义分割,证明了其设计的有效性。
2.核心创新点:
Bi-Level Routing Attention (BRA): BiFormer的核心创新是BRA机制,它通过两级路由来实现动态、查询感知的稀疏性。在第一阶段,它在区域级别上构建一个亲和图,并通过剪枝来保留每个节点的前k个连接。这样,每个区域只需要关注前k个路由区域。在第二阶段,它应用令牌对令牌的注意力,通过聚集关键值对来实现高效的注意力计算。
内容感知的计算分配: BiFormer通过BRA机制实现了对计算的灵活分配,使得每个查询只关注与其语义上最相关的一小部分键值对,从而提高了计算效率。
GPU友好的实现: BiFormer的设计考虑到了GPU的内存操作特性,通过密集矩阵乘法而不是稀疏矩阵乘法来实现注意力机制,从而提高了模型在现代GPU上的运行效率。
3.应用效果:
BiFormer在多个计算机视觉任务上展示了显著的性能提升:
- 在图像分类任务中,BiFormer-T在ImageNet-1K数据集上达到了83.8%的top-1准确率,这是在类似计算预算下没有使用外部数据或蒸馏技术的最佳结果。
- 在目标检测和实例分割任务中,BiFormer在COCO 2017数据集上的表现超过了一些最具有竞争力的现有方法,尤其是在处理小物体时。
- 在语义分割任务中,BiFormer在ADE20K数据集上的表现也优于一些现有的方法。
一、环境配置
- 先下载源代码,我直接用的作者开源GitHub里的代码
https://github.com/rayleizhu/BiFormer - 开始时,建议使用代码给出的环境建立虚拟环境
conda env create -f environment.yaml -n biformer
如果在已经有torch的环境里,使用下面语句安装没有安装的包库
conda env update -f environment.yaml
安装.yaml环境的教程来自于:
https://blog.csdn.net/qq_42536162/article/details/134666873
(因为我使用安装好了torch和mmcv的环境,下面是我额外需要安装的。如果用上面方法安装好了环境,请跳过后面所有环境安装部分)
安装 timm,hydra,submitit,omegaconf,fvcore,einops
使用pip就行,例如安装timm命令:
pip install timm
二、训练
- 使用分布式训练
python hydra_main.py \
data_path=./data/in1k input_size=224 batch_size=128 dist_eval=true \
+slurm=${CLUSTER_ID} slurm.nodes=1 slurm.ngpus=8 \
model='biformer_small' drop_path=0.15 lr=5e-4
- 单卡训练
python main.py --data-path ./data/MRI --output_dir ./run --input-size 224 --batch-size 32 --model biformer_small
成功开始训练:
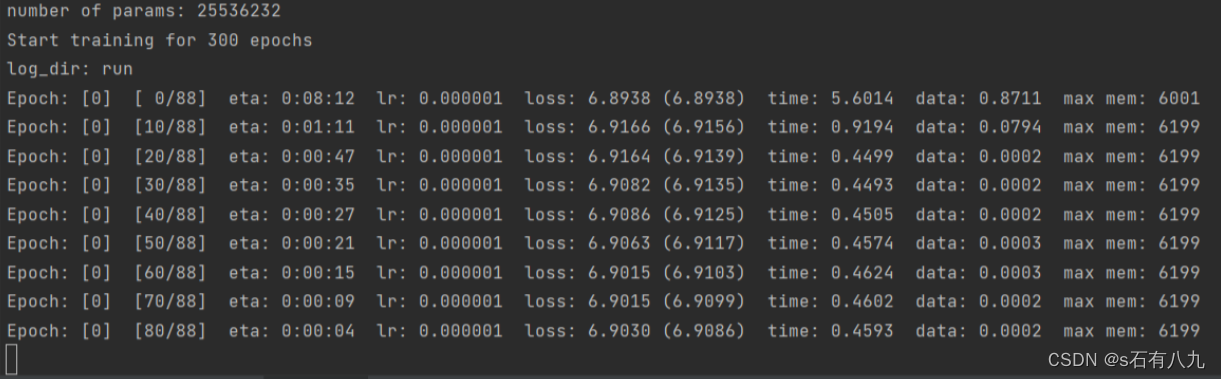
我使用了医疗肿瘤分类数据集
最终300epoch结果为:
- Acc@1 63.452 Acc@5 100.000 loss 1.052
Accuracy of the network on the 394 test images: 63.5%
Max accuracy: 65.23%
Training time 3:38:14
时间还是挺短的,确实是效率高,不过精度一般
三、报错调bug
1.报错: ModuleNotFoundError: No module named ‘hydra’
环境里输入:
pip install hydra-core --upgrade
2.报错:No module named ‘torch._six’
将 from torch._six import inf 调整为下面
from torch import inf
3.报错:Set the environment variable HYDRA_FULL_ERROR=1 for a complete stack trace.
因为GitHub里给的训练命令是分布式的,而如果只有一张卡,不使用分布式,运行就会报错。所以使用下面代码:
python main.py --data-path ./data/MRI --output_dir ./run --input-size 224 --batch-size 32 --model biformer_small
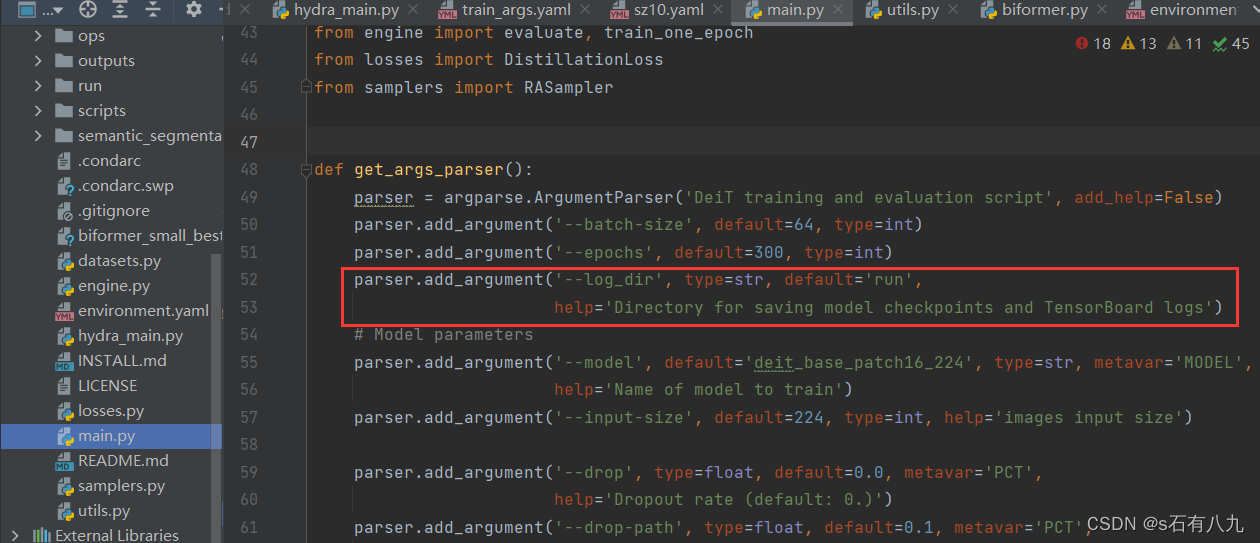
4.报错:AttributeError: ‘Namespace’ object has no attribute ‘log_dir’
在main.py添加下面语句,因为源代码里没有定义log_dir(运行结果存储位置)
parser.add_argument('--log_dir', type=str, default='run',
help='Directory for saving model checkpoints and TensorBoard logs')
如下面图所示:


























![[flask]请求全局钩子](https://img-blog.csdnimg.cn/direct/ccafdd82f1074e3db54efa20c8d2bbc6.png)