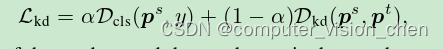Adversarial Diffusion Distillation
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
我们介绍了 Adversarial Diffusion Distillation(ADD),这是一种新颖的训练方法,可以在仅 1-4 步内高效地采样大规模基础图像扩散模型,同时保持高质量的图像。我们使用分数蒸馏(score distillation)来利用大规模现成的图像扩散模型作为教师信号,结合对抗损失来确保即使只有一到两个采样步骤,图像的保真度也很高。我们的分析表明,我们的模型在单步中明显优于现有的少步方法(GAN、Latent Consistency Models),并且在仅四步的情况下达到了最先进的扩散模型(SDXL)的性能。ADD 是第一个解锁使用基础模型进行单步实时图像合成的方法。
代码:https://github.com/Stability-AI/generative-models
模型权重:https://huggingface.co/stabilityai/
相关网站:https://stability.ai/news/stability-ai-sdxl-turbo

2. 背景
尽管扩散模型在合成和编辑高分辨率图像 [3, 53, 54] 和视频 [4, 21] 方面取得了显著的性能,但它们的迭代性质阻碍了实时应用。
- 潜在扩散模型 [54] 试图通过在更可行的潜在空间中表示图像来解决这个问题 [11],但它们仍然依赖于具有数十亿参数的大型模型的迭代应用。
- 除了利用更快的扩散模型采样器 [8, 37, 64, 74],还有越来越多的关于模型蒸馏的研究,例如渐进式蒸馏 [56] 和引导蒸馏 [43]。这些方法将迭代采样步骤减少到 4-8 步,但可能显著降低原始性能。此外,它们需要一个迭代的训练过程。
- 一致性模型 [66] 通过对 ODE 轨迹强制执行一致性正则化来解决后一个问题,并在少样本设置中对基于像素的模型展现出强大的性能。
- 潜在一致性模型(Latent Consistency Model,LCM) [38] 专注于蒸馏潜在扩散模型,并在 4 个采样步骤上取得了令人印象深刻的性能。
- 最近,LCM-LoRA [40] 引入了一种低秩适应训练 [22],以高效地学习 LCM 模块,这些模块可以插入到不同的 SD 和 SDXL [50, 54] 的检查点中。
- InstaFlow [36] 提出使用 Rectified Flows [35] 促进更好的蒸馏过程。
所有这些方法都存在共同的缺陷:在四个步骤中合成的样本通常看起来模糊,并显示出明显的伪影。在更少的采样步骤中,这个问题会进一步加剧。GAN(生成对抗网络)[14] 也可以被训练为独立的单步模型,用于文本到图像的合成 [25, 59]。它们的采样速度令人印象深刻,但性能落后于基于扩散的模型。部分原因可以归因于对稳定训练对抗目标所必需的精心平衡的 GAN 特定架构。扩展这些模型并将神经网络架构的进步整合到其中而不破坏平衡是极具挑战性的。此外,当前最先进的文本到图像 GAN 并没有像 DMs(扩散模型)中那样关键的无分类器指导方法可用。
分数蒸馏采样(Score Distillation Sampling,SDS) [51],也称为分数雅可比链(Score Jacobian Chaining) [68],是一种最近提出的方法,用于将基础 T2I 模型的知识蒸馏到 3D 合成模型中。尽管大多数基于 SDS 的作品 [45, 51, 68, 69] 将 SDS 应用于每场景优化的 3D 对象的上下文中,但这种方法也已应用于文本到 3D 视频合成 [62] 和图像编辑 [16] 的背景中。
最近,[13] 的作者已经展示了基于分数的模型和 GANs 之间的强关系,并提出了 Score GANs,它们使用来自 DM 而不是鉴别器的基于分数的扩散流进行训练。类似地,Diff-Instruct [42] 是一种将 SDS 泛化的方法,它能够将预训练的扩散模型蒸馏成一个没有鉴别器的生成器。
相反,还有一些方法旨在通过对抗训练改善扩散过程。为了加快采样速度,引入了去噪扩散 GANs [70],以实现在少步数下的采样。为了提高质量,在分数匹配目标中添加了鉴别器损失,如在 Adversarial Score Matching [24] 和 CTM [29] 中的一致性目标。
我们的方法将对抗训练和分数蒸馏结合到一个混合目标中,以解决当前性能最佳的少步生成模型中存在的问题。
3. 方法
我们的目标是在尽可能少的采样步骤中生成高保真度的样本,同时匹配最先进模型的质量 [7, 50, 53, 55]。对抗目标 [14, 60] 自然适用于快速生成,因为它训练了一个模型,在单个前向步骤中输出图像流形上的样本。然而,尝试将 GAN 扩展到大型数据集 [58, 59] 观察到,除了依赖鉴别器,使用预训练的分类器或 CLIP 网络来改善文本对齐是至关重要的。正如 [59] 中所述,过度使用鉴别网络会引入伪影,并且图像质量会受到影响。相反,我们利用预训练扩散模型的梯度,通过分数蒸馏目标来改善文本对齐和样本质量。此外,我们不是从头开始训练,而是使用预训练的扩散模型权重初始化我们的模型;已知预训练生成器网络可以显著改善带有对抗损失的训练 [15]。最后,我们不是使用仅解码器架构用于 GAN 训练 [26, 27],而是采用标准的扩散模型框架。这种设置自然地实现了迭代细化。

3.1. 训练过程
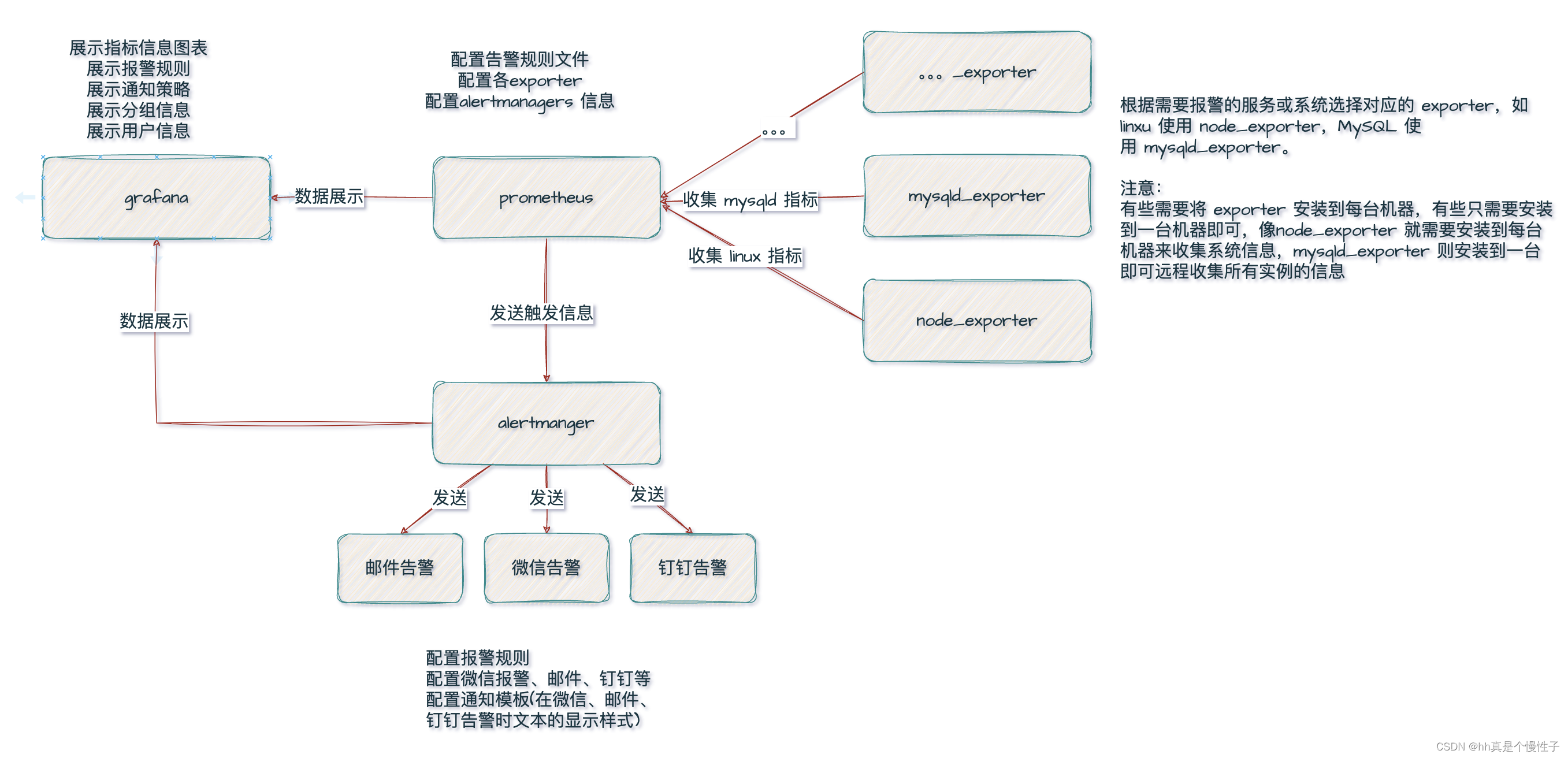
我们的训练过程如图 2 所示,涉及三个网络:ADD 学生从预训练的 UNet-DM 初始化,权重为 θ;一个具有可训练权重 ϕ 的鉴别器;以及一个具有冻结权重 ψ 的 DM 教师。在训练期间,ADD 学生从噪声数据 xs 生成样本 ˆx_θ(x_s, s)。噪声数据点通过一个真实图像 x_0 的数据集经过前向扩散过程生成 x_s = α_s·x_0 + σ_s·ϵ。在我们的实验中,我们使用与学生 DM 相同的系数 α_s 和 σ_s,并从选择的学生时间步集合 T_student = {τ_1, ..., τ_n} 中均匀地选择样本 s。在实践中,我们选择 n = 4。重要的是,我们设置 τ_n = 1000,并在训练期间强制零端信噪比(zero-terminal
SNR) [33],因为模型在推断时需要从纯噪声开始。
对于对抗目标,生成的样本 ˆxθ 和真实图像 x0 传递给鉴别器,后者旨在区分它们。鉴别器的设计和对抗损失在第 3.2 节中详细描述。为了从 DM 教师中提取知识,我们将学生样本 ˆxθ 通过教师的前向过程扩散到 ˆx_(θ,t),并使用教师的去噪预测
![]()
作为蒸馏损失 L_distill 的重构目标,见第 3.3 节。因此,总体目标是
![]()
虽然我们将我们的方法制定在像素空间中,但很容易将其调整为在潜在空间中运行的 LDM。当使用具有共享潜在空间的教师和学生的 LDM 时,可以在像素空间或潜在空间中计算蒸馏损失。我们在像素空间中计算蒸馏损失,因为这样可以在蒸馏潜在扩散模型时产生更稳定的梯度 [72]。
3.2. 对抗损失
对于鉴别器,我们遵循 [59] 中提出的设计和训练程序,我们简要总结一下;详情请参阅原始工作。我们使用一个冻结的预训练特征网络 F 和一组可训练的轻量级鉴别器头 D_(ϕ,k)。对于特征网络 F,Sauer 等人 [59] 发现视觉 Transformer (ViTs) [9] 效果很好,我们在第 4 节中消融了 ViTs 的不同选择以及模型大小。可训练的鉴别器头应用于特征网络的不同层的特征 F_k 上。
为了提高性能,鉴别器可以通过投影在额外信息上进行条件设置 [46]。通常,在文本到图像的设置中使用文本嵌入 c_text。但是,与标准 GAN 训练相反,我们的训练配置还允许以给定的图像为条件。对于 τ < 1000,ADD 学生从输入图像 x0 接收到一些信号。因此,对于给定的生成样本 ˆxθ(xs, s),我们可以将鉴别器条件设置为来自 x0 的信息。这鼓励 ADD 学生有效地利用输入。在实践中,我们使用额外的特征网络来提取图像嵌入 c_img。
遵循 [57, 59],我们使用铰链损失 [32] 作为对抗目标函数。因此,ADD 学生的对抗目标函数为

其中,鉴别器则被训练以最小化
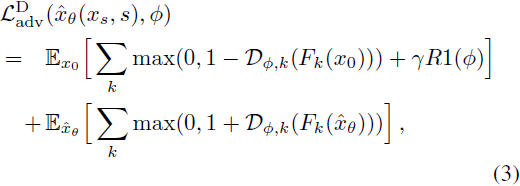
其中,R1 表示 R1 梯度惩罚 [44]。我们计算梯度惩罚时,不是针对像素值进行,而是针对每个鉴别器头 D_(ϕ,k) 的输入进行。我们发现,当在大于 128x128 像素的输出分辨率下进行训练时,R1 惩罚尤其有益。
3.3. 分数蒸馏损失
公式(1)中的蒸馏损失被表述为

其中,sg 表示停止梯度操作。直观地说,损失使用距离度量 d 来衡量 ADD 学生生成的样本 xθ 与 DM-teacher 的输出
![]()
![]()
之间的不匹配程度,该输出是在时间步 t 和噪声 ϵ′ 上平均的。值得注意的是,教师模型并不直接应用于 ADD 学生的生成 ˆxθ,而是应用于扩散输出
![]()
因为非扩散的输入对于教师模型来说是超出分布的 [68]。
接下来,我们定义距离函数
![]()
关于加权函数 c(t),我们考虑两个选项:指数加权,其中 c(t) = α_t(更高的噪声水平贡献较少),以及分数蒸馏采样(SDS)加权 [51]。在补充材料中,我们证明了当 d(x, y) = ||x − y||^2_2,并且对于 c(t) 的特定选择时,我们的蒸馏损失变得等同于 SDS 目标 L_SDS,如 [51] 中所提出的那样。我们公式的优势在于它能够直接可视化重构目标,并且自然地促进了连续几个去噪步骤的执行。最后,我们还评估了无噪声分数蒸馏(NFSD)目标,这是 SDS 的最近提出的变体 [28]。
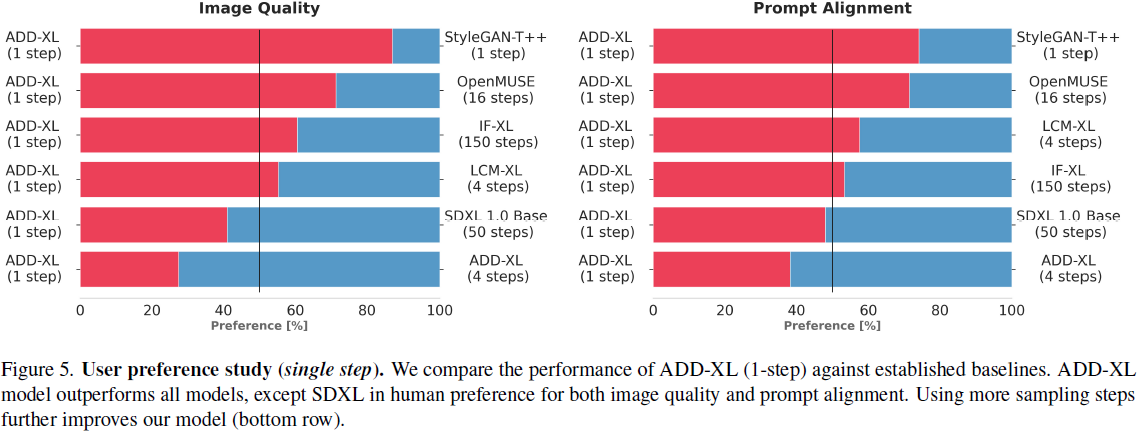
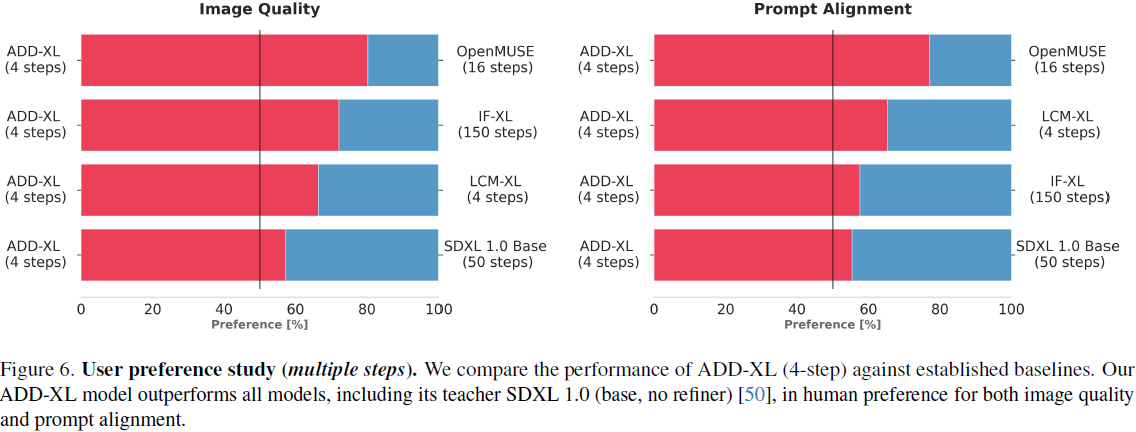
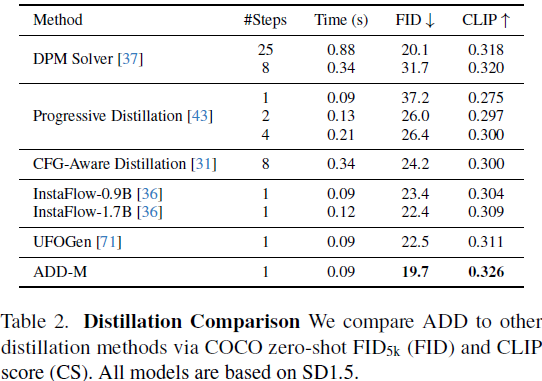
4. 实验