SpringBoot-02 | Jdk spi加载原理
原理分析
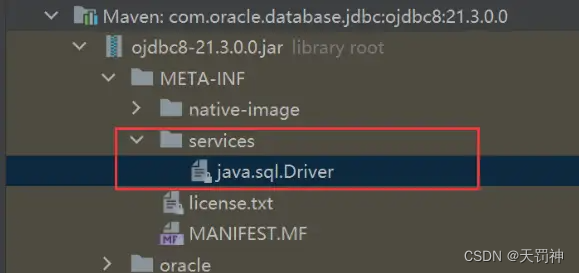
SPI的工作原理: 就是ClassPath路径下的META-INF/services文件夹中, 以接口的全限定名来命名文件名,文件里面写该接口的实现。然后再资源加载的方式,读取文件的内容(接口实现的全限定名), 然后再去加载类。
SPI可以很灵活的让接口和实现分离, 让api提供者只提供接口, 第三方来实现。

优点:
使用Java SPI机制的优势是实现解耦,使得第三方服务模块的装配控制的逻辑与调用者的业务代码分离,而不是耦合在一起。应用程序可以根据实际业务情况启用框架扩展或替换框架组件。
缺点:
虽然ServiceLoader也算是使用的延迟加载,但是基本只能通过遍历全部获取,也就是接口的实现类全部加载并实例化一遍。如果你并不想用某些实现类,它也被加载并实例化了,这就造成了浪费。获取某个实现类的方式不够灵活,只能通过Iterator形式获取,不能根据某个参数来获取对应的实现类。
多个并发多线程使用ServiceLoader类的实例是不安全的。
代码示例
定义一个接口:
package com.tope365.spi;
public interface CommandInterface {
void doCommand();
}
定义一个load加载器:
package com.tope365.spi;
import java.util.ServiceLoader;
public class CommandRegistry {
public static void init() {
scan();
}
private static synchronized void scan() {
ServiceLoader<CommandInterface> serviceLoader = ServiceLoader.load(CommandInterface.class);
for (CommandInterface temp : serviceLoader) {
System.out.println("检测到实现类:"+ temp.getClass().getSimpleName());
temp.doCommand();
}
}
}
配置设置:
\META-INF\services\com.tope365.spi.CommandInterface
com.tope365.timer.SimpleCommandImpl
启动类:
public static void main(String[] args) throws Exception {
logger.info("openai web启动中....");
SpringApplication.run(SpringAppRun.class, args);
CommandRegistry.init();
logger.info("openai web启动成功!");
System.out.println("Open your web browser and navigate to http://"+ SysUtility.getHostIp() +":" + 7778 + "/doc.html");
}
业务实现类:
package com.tope365.timer;
import com.tope365.spi.CommandInterface;
public class SimpleCommandImpl implements CommandInterface {
@Override
public void doCommand() {
System.out.println("阿里支付开始......");
System.out.println("阿里支付生成流水号......");
System.out.println("阿里支付结束......");
}
}
控制台输出:
2024-03-13 08:44:04.772 INFO 1408 --- [ main] com.tope365.SpringAppRun : Started SpringAppRun in 6.558 seconds (JVM running for 1554.99)
检测到实现类:SimpleCommandImpl
阿里支付开始......
阿里支付生成流水号......
阿里支付结束......
2024-03-13 09:03:39.719 INFO 1408 --- [ main] com.tope365.SpringAppRun : openai web启动成功!
Open your web browser and navigate to http://192.168.10.238:7778/doc.html
源码剖析
业务使用类入口,scan()方法为业务自行定义,指定接口类加载:
private static synchronized void scan() {
ServiceLoader<CommandInterface> serviceLoader = ServiceLoader.load(CommandInterface.class);
for (CommandInterface temp : serviceLoader) {
System.out.println("检测到实现类:"+ temp.getClass().getSimpleName());
temp.doCommand();
}
}
load方法内部创建ServiceLoader对象。
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(Reflection.getCallerClass(), service, loader);
}
类的静态代码块(static block)会在类加载时被执行,AccessController.doPrivileged()也会在调用时执行传入的PrivilegedAction或PrivilegedExceptionAction对象的run()方法。
AccessController.doPrivileged包起来的目的是跳过Java的安全检查,Java默认不打开安全检查,打开System.setSecurityManager(new SecurityManager());则Java程序会检验权限。更多请见AccessController的doPrivileged使用,https://blog.csdn.net/yekong1225/article/details/81011819
private static final class DetectBackend {
static final LoggingBackend detectedBackend;
static {
detectedBackend = AccessController.doPrivileged(new PrivilegedAction<LoggingBackend>() {
@Override
public LoggingBackend run() {
final Iterator<LoggerFinder> iterator =
ServiceLoader.load(LoggerFinder.class, ClassLoader.getSystemClassLoader())
.iterator();
//触发ServiceLoader的hasNext()方法
if (iterator.hasNext()) {
return LoggingBackend.CUSTOM; // Custom Logger Provider is registered
}
// No custom logger provider: we will be using the default
// backend.
final Iterator<DefaultLoggerFinder> iterator2 =
ServiceLoader.loadInstalled(DefaultLoggerFinder.class)
.iterator();
if (iterator2.hasNext()) {
// LoggingProviderImpl is registered. The default
// implementation is java.util.logging
String cname = System.getProperty("java.util.logging.config.class");
String fname = System.getProperty("java.util.logging.config.file");
return (cname != null || fname != null)
? LoggingBackend.JUL_WITH_CONFIG
: LoggingBackend.JUL_DEFAULT;
} else {
// SimpleConsoleLogger is used
return LoggingBackend.NONE;
}
}
});
}
}
默认使用newLookupIterator的这个迭代器:
public final class ServiceLoader<S> implements Iterable<S>
{
public boolean hasNext() {
checkReloadCount();
if (index < instantiatedProviders.size())
return true;
return lookupIterator1.hasNext();
}
}
newLookupIterator迭代器进一步使用ModuleServicesLookupIterator与LazyClassPathLookupIterator两种迭代器,继续判断是否有spi加载的接口,因为默认是不使用懒加载,故first.hasNext()加载生效
private Iterator<Provider<S>> newLookupIterator() {
assert layer == null || loader == null;
if (layer != null) {
return new LayerLookupIterator<>();
} else {
Iterator<Provider<S>> first = new ModuleServicesLookupIterator<>();
Iterator<Provider<S>> second = new LazyClassPathLookupIterator<>();
return new Iterator<Provider<S>>() {
@Override
public boolean hasNext() {
return (first.hasNext() || second.hasNext());
}
@Override
public Provider<S> next() {
if (first.hasNext()) {
return first.next();
} else if (second.hasNext()) {
return second.next();
} else {
throw new NoSuchElementException();
}
}
};
}
}
ModuleServicesLookupIterator属于ServiceLoader的内部实现类,loadProvider方法获取实现类,并使用Class.forName进行实例化。
public final class ServiceLoader<S> implements Iterable<S>
{
...
private final class ModuleServicesLookupIterator<T>implements Iterator<Provider<T>>
{
@Override
public boolean hasNext() {
...
//
Provider<T> next = (Provider<T>) loadProvider(provider);
//生成ProviderImpl,进行下一次的next处理
nextProvider = next;
...
}
}
private Provider<S> loadProvider(ServiceProvider provider) {
...
clazz = Class.forName(module, cn);
...
}
SPI机制在框架中的使用
市面上常见的日志框架有很多。通常情况下,日志是由一个抽象层+实现层的组合来搭建的,而用户通常来说不应该直接使用具体的日志实现类,应该使用日志的抽象层。
1、SLF4J + Logback实现
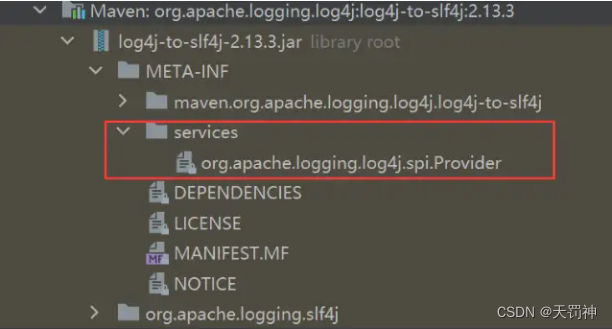
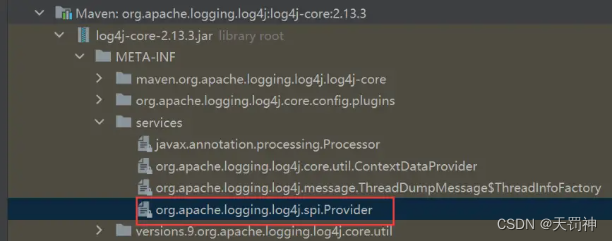
2、SLF4J + Log4j2实现
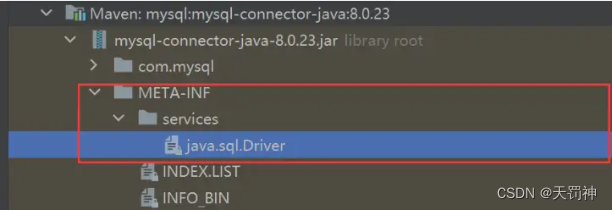
3、mysql驱动
4、oracle驱动