Hello算法2:复杂度分析
本文是基于k神的Hello 算法的读书笔记,请支持实体书。
https://www.hello-algo.com/chapter_paperbook/
算法效率
算法效率评估
设计算法时,我们追求以下两个目标:
- 找出解法
- 找出最优解
最优解通常包含两个指标:
- 时间:算法运行的时间
- 空间:算法占用的内存
评估的方法分为两种:
实际测试和理论评估
实际测试
找一台计算机实际运行代码,比较两个算法的效率。
这样虽然很直观,但是有以下缺陷
- 难以排除测试环境的干扰:两台计算机配置不同,在上面运行某算法可能会得到不同的结果
- 完整的测试很耗费资源:某些算法对于少量数据和巨量数据表现差别很大,这就需要设计测试时尽量覆盖所有情况
理论估算
也就是复杂度分析,它描述随着输入数据大小的增加,算法执行的时间和空间的增长趋势。
它客服了实际测试的缺点,体现如下:
- 无需测试环境,结果适用于各平台
- 可以体现不同数据量下的效率,特别是针对大数据
迭代和递归
在执行算法时,重复执行某个任务很常见。
迭代
常见的迭代有for循环和while循环
for循环
比如计算1+2+n的值,for循环的时间复杂度取决于n的值,它是线性相关的
while循环
初始化条件和条件更新的步骤独立于循环过程,所以while循环更自由
循环的嵌套
循环中可以嵌套循环,此时复杂度就变成了n的平方
递归
递归是指通过调用函数自身来解决问题,主要包含两个阶段
- 递:不断深入的调用自身,通常是不断传入更小的参数,直到达到终止条件
- 归:触发终止条件后,程序开始逐层返回
def recur(n: int) -> int:
"""递归"""
# 终止条件
if n == 1:
return 1
# 递:递归调用
res = recur(n - 1)
# 归:返回结果
return n + res
调用栈
每次调用自身,计算机都会开辟新的内存区域,存储局部变量、调用地址和其他变量,因此
- 递归通常比迭代更耗费内存空间
- 递归的时间效率通常更低
递归深度过多,可能会溢出
尾递归
在在返回前的最后一步才进行递归调用中调用自身,这种方式某些语言可以被编译器或解释器优化,使其在空间效率上与迭代相当。但比如python就不支持。
def tail_recur(n, res):
"""尾递归"""
# 终止条件
if n == 0:
return res
# 尾递归调用
return tail_recur(n - 1, res + n)
递归树
以“斐波那契数列”为例,将会产生如下的递归树
给定一个斐波那契数列0,1,1,2,3,5,8,13,…,求该数列的第n个数字
def fib(n: int) -> int:
"""斐波那契数列:递归"""
# 终止条件 f(1) = 0, f(2) = 1
if n == 1 or n == 2:
return n - 1
# 递归调用 f(n) = f(n-1) + f(n-2)
res = fib(n - 1) + fib(n - 2)
# 返回结果 f(n)
return res

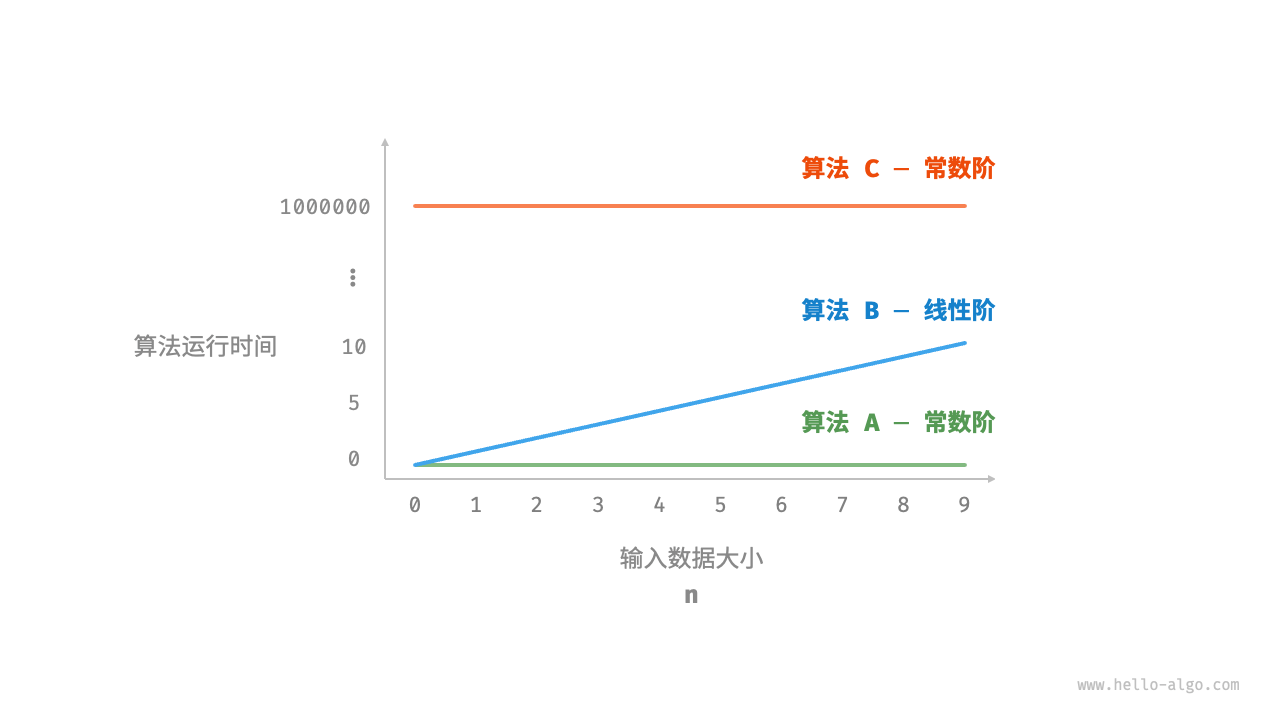
时间增长趋势
如下三个算法:
# 算法 A 的时间复杂度:常数阶
def algorithm_A(n: int):
print(0)
# 算法 B 的时间复杂度:线性阶
def algorithm_B(n: int):
for _ in range(n):
print(0)
# 算法 C 的时间复杂度:常数阶
def algorithm_C(n: int):
for _ in range(1000000):
print(0)
时间增长趋势如下:

可以看出时间复杂度有如下特点:
- 可以有效评估算法效率
- 时间复杂度的推算更简便
- 存在一定局限性
计算方式
第一步:统计操作数量,有以下技巧
- 忽略常数项
- 省略所有系数
- 循环嵌套时使用乘法
def algorithm(n: int):
a = 1 # +0(技巧 1)
a = a + n # +0(技巧 1)
# +n(技巧 2)
for i in range(5 * n + 1):
print(0)
# +n*n(技巧 3)
for i in range(2 * n):
for j in range(n + 1):
print(0)
应用上述方法后,可得操作数量是

第二步:逐渐判断上界
时间复杂度由 T(n) 中最高阶的项来决定。这是因为在 n 趋于无穷大时,最高阶的项将发挥主导作用,其他项的影响都可以忽略。
常见有如下复杂度: