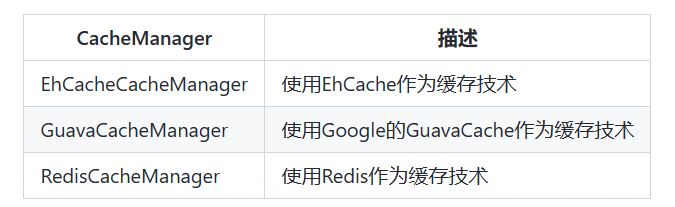
RabinKarp
RabinKarp
S:ABABAB m个
P:ABB n个
1.朴素算法,挨个匹配
2.哈希法 hash->滚动哈希 c0*31^2+c1*31^1+c2类似于进制的求法求hash值(c0*31+c1)*31+c2
hash(p)=o(n)
hash(s)=o(m*n)
private static void match(String p,String s){
long hash_p=hash(p);
int p_len=p.length;
for(int i=0;i+p_len<=s.length;i++){
long hash_i=hash(s.subString(i,i+p_len));//i作为起点,长度为length的子串的hash值
if(hash_i==hash_p){
System.out.println("match:"+i);
}
}
}
final static long seed=31;
static long hash(String str){
long hash=0;
for(int i=0;i!=str.length;i++){//(c0*31+c1)*31+c2
hash=seed*hash+str.charAt(i);
}
return hash%Long.MAX_VALUE;
}
每次求hash中间都相同的字符被计算
//n是子串的长度
//用滚动的方法求出s中长度为n的每个字串的hash求出hash数组
final static long seed=31;
static long[] hash(final String s,final int n){
long[] res=new long[s.length()-n+1];
//前n个字符的hash
res[0]=hash(s.subString(0,n));
for(int i=n;i<s.length;i++){//i的位置为新字符
char newChar=s.charAt(i);
char oldChar=s.charAt(i-n);
//前m个字符的hash*seed-n个字符的第一个字符*d的n次方
long v=(res[i-n]*seed)-NExponent.ex2(seed,n)*oldChar+newChar)%Long.MAX_VALUE;;
res[i-n+1]=v;
}//NExponent.ex2(seed,n)自己封装的工具,求seed的n次方
return res;
}
static long hash(String str){
long h=0;
for(int i=0;i!=str.length;i++){
h=seed*h+strcharAt(i);
}
}
KMP
KMP
1.暴力匹配
private static int indexOf(String s,String p){
int i=0;
int sc=i;
int j=0;
while(sc<s.length()){
if(s.charAt(sc)==p.charAt(j)){
sc++;
j++;
if(j==p.length)
return i;
}else{
i++;
sc=i;//扫描指针以i为起点
}
}
}
2.next数组的含义及应用
后缀与前缀的最长匹配长度
f(L)=k,L失配,s回溯k
不考虑第L个元素
P[0~L-1]的pre, suff最长匹配数
next数组
b a b a b b
-1 0 0 1 2 3
取该位next数组,应将该为元素排除在外
取下标为0的next,为-1,因为将排除在外
取下标为1的next,为0,将a排除在外,b没有前缀没有后缀,因为我们不包含它的整体
前两个next一般都为-1,0
取下标为2的next,为0,排除b,b a前缀后缀匹配为0
取下标为3的next,为1,排除a,b a b前缀后缀匹配为1,前缀b和后缀b匹配
如此取出所有next
3.求next数组
private static int indexOf(String s,String p){
if(s.length()==0||p.length()==0)return -1;
if(p.length()>s.length())return -1;//模式串大于原串的长度
int count=0;
int[] next=next(p);
int i=0;//s位置
int j=0;//p位置
int sLen=s.length();
int pLen=p.length();
while(i<sLen){
//如果j=-1,或者当前字符串匹配成功,即S[i]==p[i],则令i++,j++
//j=-1,因为next[0]=-1,说明p的第一位和i这个位置无法匹配,这时i,j都增加1,i移位,j从0开始
if(j==-1||s.charAt(i)==p.charAt(j)){
i++;
j++;
}else{
//如果j!=i,且当前字符匹配失败,即S[i]!=P[j],则令i不变,j=next[j]
//next[j]即为j所对应的next数组
j=next[j];
}
if(j==plen){//匹配成功了
count++;
j=next[j];//求匹配成功的次数,让i继续向下走
// return (i-j);
}
}
return count;//返回匹配成功的次数
//return -1;
}
//求next数组
j,k为上字符是否相同
如果pj==pk,next[j+1]=k+1或者k<0,next[j+1]=k+1;
否则k继续回溯,直到满足pj==pk或k<0;
//若是有一个相同,则下一个位置即j+1的next为k+1,
//即前缀后缀有一个成功匹配,到达下一个位置,
//再看当前位置+1后j的元素,与+1后的k的相比较,
//若是相同,则j+1位置的next为K+1,则证明有两个成功匹配的长度,
//若是下一个位置j与k位置的元素不同,则之前成功匹配的则作废,
//则k回溯找前面相同的继续前缀后缀匹配,
//若是找不到,即k等于-1,则下一个位置的next为0,相当于-1+1=0
private static int[] next(Strig ps){
int pLength=ps.length();
char[] p=ps.toCharArray();
next[0]=-1;
if(ps.length()==1){
return next;
}
next[1]=0;//初始化next[0]=-1,next[1]=0
int j=1;
int k=next[j];//看看位置j的最长匹配前缀在哪里
while(j<plength-1){
//现在要推出next[j+1],检查j和k位置上的关系即可
if(k<0||p[j]==p[k]){//当k回溯到-1或是p[j]和p[k]相等时
next[++j]=++k;
}
else{
k=next[k];//k回溯
}
}
return next;
}
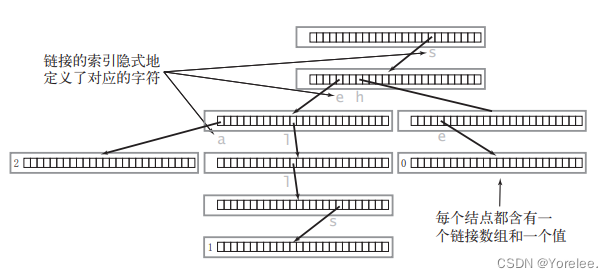
前缀树(字典树,Trie);后缀数组
1.什么是后缀数组
就是串的所有后缀子串的按字典序排序后,在数组中记录后缀的起始下标,
后缀数组就是:排名和原下标的映射,Sa[0]=5,起始下标为5的后缀在所有后缀中字典序最小
rank数组:给定后缀的下标,返回字典序,rk[5]=0;rk[sa[i]]=i
2.后缀数组有什么用
子串:一定是某个后缀的前缀
private static void match(){
String s="ABABABABB";
String p="BABB";
Match03_SuffixArray.Suff[] sa=Match03_SuffxiArray.getSa2(s);//后缀数组
int l=0;
int r=s.length()-1;
//二分查找。nlog(m)
while(r>=l){
int mid=l+((r-l)>>1);
//居中的后缀
Match03_SuffixArray.Suff midSuff=Sa[mid];
String suffStr=midSuff.str;
int compareRes;
//将后缀和模式串比较,o(n)
if(suffstr.length()>=p.length())
compareRes=suffstr.subString(0,p.length()).compareTo(p);
//若是某后缀长度大于子串的长度,则截取后缀前面子串长度的部分与子串比较
//若是后缀大于子串,则为正,r=mid-1
//若是后缀小于子串,则为负,l=mid+1
}else{
compareRes=suffstr.compareTo(p);//后缀长度小于p,若是相同则p更大,因为字符串更长的更大,若是不同,则按字典序正常比较大小
}
if(compareRes==0){
System.out.println(midSuff.index);
break;
}else if(compareRes<0){
l=mid+1;
}else{
r=mid-1;
}
}
ABABABABB
ABABABABB-0
BABABABB-1
ABABABB-2
BABABB-3
ABABB-4
BABB-5
ABB-6
BB-7
B-8
ABABABABB-0 ABABABB-2 ABABB-4.....suffix array sa
3.怎么求后缀数组
3.1 把所有的后缀放入数组,Arrays.sort();nlog(n)
//直接对所有后缀数组排序,因为字符串的比较消耗o(n)
//所以整体为n^2*log(n)
public static Suff[] getSa(String src){
int strLength=src.length();
//sa是排名到下标的映射,即sa[i]=k说明排名为i的后缀是从k开始的
Suff[] suffixArray=new Suff[StrLength];
for(int i=0;i<strLength;i++){
String SuffI=src.substring(i);//substring截取字符串,此字符串为一个子字符串,从索引位置的字符开始,直到字符串末尾
suffixArray[i]=new Suff(suffI,i);//将该子字符串与所处位置放入后缀数组
}
Arrays.sort(suffixArray);//快排
return suffixArray;
}
//面向对象,类似与c语言结构体
static class Suff implements Comparable<suff>{//Comparable接口的约定,必须实现compareTo()
String str;//后缀内容
int index;//起始下标
public Suff(String str,int index){
this.str=str;
this.index=index;
}
public int campareTo(Suff o2){
return this.str.compareTo(o2.str);
}
public String toString(){
return "Suff{"+"str'"+str+'\''+",index="+index+"}";
}
}
倍增法
3.1
1.suff[] A~0,B~1,A~1,B~3,A~4,B~5,A~6,B~7,B~8
2.Sort: A~0,A~2,A~4,B~1,B~3,B~5,B~7,B~8
3.rk r[0]-0,r[2]=1,r[4]=0,r[6]=0,r[1,3,5,7,8]=1给我下标,给你排名
1.suff[] AB~0,BA~1,AB~1,BA~3,AB~4,BA~5,AB~6,BB~7,B~8
2.Sort: A~0,A~2,A~4,B~1,B~3,B~5,B~7,B~8
3.rk r[0]-0,r[2]=1,r[4]=0,r[6]=0,r[1,3,5,7,8]=1给我下标,给你排名
int[] rk=new int[Strlength];//suffix array
Suff[] suffixArray = new Suff[strlength];
for(int k=1;k<=strlength;k*=2){
for(int i=0;i<strlength;i++){//k代for(int i=0;i<strlength;i++){//k代表取值范围,一开始只截一个字符参与排序,下次两个字符参与排序,依次乘2}
String suffI=src.substring(i,i+k>strlengthl?strelngth:i+k);
suffixArray[i] =new Suff(suffI,i);
}
if(k==1)//一个字符,直接排序
Arrays.sort(suffixArray);//nlog(n)
else{
//填充完毕,开始排序nlog(n)
final int kk=k;
Arrays.sort(suffixArray,(o1,o2)->{//简化匿名内部类,定义一个比较器
//不是基于字符串比较,而是利用之前的rank
int i=o1.index;
int j=o2.index;
if(rk[i]==rk[j]){//如果o1和o2的前半段
try{//利用上一级排名给下一级排名
//无论是rk[i]还是rk[i+kk/2]在上一级排名中都是有的
return rk[i+kk/2]-rk[j+kk/2];//若是有一个后缀字符串较短。+kk/2就会越界
//x x
//i i+k/2
//Y Y
//j j+k/2
}catch(ArrayIndexOutOfBoundsExcept e){//越界
return o1.str.length()-o2.length();//前半部分一致,谁长谁在后
}
}else{//若不相等,则排名大的在后
return rk[i]-rk[j];
}
});
}
int r=0;
rk[suffixArray[0].index]=r;
for(int i=1;i<strlen;i++){
if(suffixArray[i].compareTo(suffixArray[i-1]==0)){//内容相同
rk[suffixArray[i].index]=r;//索引->排名,给定索引,知道单个字符的排名
}else{
rk[suffixArray[i].index]=++r;//索引->排名,给定索引,知道单个字符的排名
}
}
}
return suffixArray;
}
private static void match(){
String s="ABABABABB";
String p="BABB";
Match03_SuffixArray.Suff[] sa=Match03_SuffixArray.getSa2(s);//后缀数组
int l=0;
int r=s.length();
//二分查找
while(r>=l){
int mid=l+((r-l)>>1);
//居中的后缀
Match03_SuffixArray.Suff midSuff=sa[mid];
String suffstr=midSuff.str;
int compareRes;
//将后缀和模式串比较o(n)
if(suffstr.length()>=p.length()){
compareRes=suffix.substring(0,p.length()).compareTo(p);
}else{
compareRes=suffStr.compareTo(p);
//相等了,输出后缀的起始位置
}
if(compareRes==0){
System.out.println(midSuff.index);
break;
}else if(compareRes<0){
l=mid+1;
}else{
r=mid-1;
}
}
}
3.2倍增法
k=1,一个字符,排序,得到sa,rk
k=2,利用上一轮的k快速比较两个后缀
k=4
k=8
....
public static Suff[] getSa2(String src){
int n=src.length();
Suff[] sa=new Suff(n);
for(int i=0;i<n;i++){
sa[i]=new Suff(src.charAt(i),i);//有单个字符,接下来排序
}
Arrays.sort(sa);
}
//rk是下标到排名的映射
int[] rk=new int[n];//suffix array
rk[sa[0].index]=1;
for(int i=1;i<n;i++){
rk[[sa[i].index]=rk[sa[i-1]].index;
if(sa[i].c!=sa[i-1].c)rk[sa[i].index]++;
}
//倍增法
for(int k=2;rk[sa[n-1].index]<n;k*=2){
final int kk=k;
Arrays.sort(sa,(o1,o2)->{
//不是利用字符串比较而是利用之前的rank
int i=o1.index;
int j=o2.index;
if(rk[i]==r[j]){//如果第一关键字相同
if(i+kk/2>=n||j+kk/2>=n)
return -(i-j);//如果某个后缀不具有第二关键字,那肯定较小,索引靠后的更小
return rk[i+kk/2]-rk[j+kk/2];
}else{
return rk[i]-rk[j];
}
});
//排序,end
//更新rank
rk[sa[0].index]=1;
for(int i=1;i<n;i++){
int i1=sa[i].index;
int i2=sa[i-1].index;
rk[i1]=rk[i2];
try{
if(!src.subString(i1,i1+kk).equals(src.subString(i2,i2+kk)))
rk[i1]++;
}catch(Exeption e){
rk[i1]++;
}
}
}
高度数组
height[0]=0;
height[i]=Lcp(sa[i],sa[i-1])
串 串
//Lcp最长公共前缀
0 ABCABC 0 ABC(排序后)
1 BCABC 1 ABCABC
2 CABC 2 BC
3 ABC 3 BCABC
4 BC 4 c
5 c 5 CABC
rk[0]=1 0 ABCABC-->1 ABCABC
sa[1]=0 1 ABCABC-->0 ABCABC
sa[rk[0]]=0
rk[sa[1]]=1
根据排名,求的当前串的位置和前一个串的位置,再根据位置求得两个串,在比对两个串求得最长公共前缀
//height[rk(i-1)]->height[rk(i)]
//height[rk(i)]->height[rk(i+1)]
0 ABC 2 BC
1 ABCABC 3 BCABC
就是抹了个帽子A,最长公共前缀-1
// height[rk(i+1)]>=height[rk(i)]-1
public static int[] getHeight(String src,Suff sa){
//Suff[] Sa=getSa2(src);
int strlength=src.length();
int[] rk=new int[Strlength];
//将rank表示为不重复的排名即0-n-1
for(int i=0;i<strLength;i++){
rk[Sa[i].index]=i;//index为原始的位置,i为排序后的位置
}
int[] height=new int[StrLength];
//如果已经知道后缀数组中i与i+1的lcp为h,那么i代表的字符串与i+1代表的字符串去掉首字母的lcp为h-1
//根据这个我们可以发现,如果知道i与后缀数组中在它后一个的lcp为k,那么它去掉首字母后的字符串与其在后缀数组中的后一个的lcp大于等于k-1
//例如对于字符串abcefabc,我们直达票abcefabc与abc的lcp为3
//那么bcefabc与bc的lcp大于等于3-1
//利用这一点就可以o(n)求出高度数组
int k=0;
for(int i=0;i<strLength;i++){
int rk_i=rk[i];//i后缀的排名
if(rk_i==0){
height[0]=0;//height[0]默认为0
continue;
}
int rk_i_1=rk_i-1;//前一个位置
int j=sa[rk_i_1].index;//j是i串字典序靠前的串的下标
if(k>0)k--;//利用height[rk(i+1)]>=height[rk(i)]-1,下一次只是去掉了一个帽子的公共前缀
for(;j+k<strLength&&i+k<strLength;k++){
if(src.charAt(j+k)!=src.charAt(i+k))
break;
}
height[rk_i]=k;//i是一个个递增的来的,若是这个方法是错误的,应该一个一个比对公共前缀
}
return height;
}