1.Shell概述
1.1 为什么要学习Shell
1.需要看懂运维人员编写的Shell程序
2.编写简单的Shell程序来管理集群,提高开发效率
1.2 学习目标
- 了解开发语言的分类及其区别和Shell编程的适用场景
- 掌握Bash特性、脚本规范、变量类型、变量运算
- 掌握Bash流程控制、函数、数组
- 掌握Bash的并发编程及并发控制
- 掌握Sed、Awk详细用法
- 灵活运用Bash、Sed、Awk完成自动化运维工作
1.3 核心技能
- Shell函数:定义函数,调用函数,取消函数,函数传参
- Shell数组:定义数组,查看数组,数组切片,遍历数组,关联数组
- Bash并发及并发控制
- Expect编程:功能解析,适用场景,功能详解
- grep命令解析
- 正则表达式:正则表达式定义,基本元字符,扩展元字符
- Sed精通:Sed介绍,适用常见,Sed语法,Sed选项
- Sed定址:数字定址,正则定址
- Sed子命令:a、c、i、d、s、y、r、n、N、P、D
- Sed工作模式:模式空间,保持空间,置换子命令h、H、g、G、x
- awk精通:工作流程,print语句,awk设计模式,模式匹配,记录和字段
- 表达式:常量,变量,系统变量,算术,赋值,关系,布尔操作符
- 流程控制:条件语句,循环语句,循环控制
- Shell编程初识:程序,语言,编程,Shell定义,分类,适用范围,初始化
- Shell脚本规范,Shell脚本调试,脚本运行方式
- 变量类型:自定义变量,环境变量,预定义变量,位置变量
- 变量运算,变量引用,变量长度,命令置换,变量替换
- test命令:语法,整数比较、字符串笔记,文件比较
- Shell编程之条件结构:if语句,case语句
- Shell编程之循环结构:for语句,while语句,until语句
- Shell循环控制:shift,continue,break,exit
- Bash特性:命令补全,历史命令,别名,前后台作业,重定向,管道,命令排序执行,通配符,正则表达式,脚本
1.4 学完可编写的案例(最后一章节提供脚本)
- 案例1:利用Expect编写脚本实现自动化生成OpenSSH密钥对
- 案例2:编写多并发ping服务器脚本并对其进行并发控制
- 案例3:利用sed实现网络配置,SSHD配置,Nginx配置,关闭SELinux
- 案例4:在/etc/sudoers配置文件中添加内容
- 案例5:将固定文件的内容添加到Nginx配置文件
- 案例6:Awk统计 /etc/password 各种Shell数量
- 案例7:Awk统计网站访问各种状态数量
- 案例8:Awk统计当前访问的每个IP的数量
- 案例9:统计Nginx日志中某一天的PV量
- 案例10:获取获得内容使用情况
- 案例11:基于时间戳的备份程序
- 案例12:编写系统初始化脚本
- 案例13:用shell编写LAMP环境一键部署脚本
- 案例14:用shell编写Linux系统状态收集及分析
1.5 认识Shell
Shell是一个命令行解释器,它接收应用程序/用户命令,然后调用操作系统内核。

Shell还是功能强大的编程语言,易编写、易调试、灵活性强。
1.6 Shell语言的特点
- Shell语言是指Unix操作系统的命令语言,同时又是该命令语言的解析程序的简称。
- Shell本身是一个用C语言编写的程序,它是用户使用Unix\Linux的桥梁,用户的大部分工作都是通过Shell完成
- Shell语言既是一种命令语言,又是一种程序设计语言。作为命令语言,它交互地解释和执行用户输入的命令;作为程序设计语言,它定义了各种变量和参数,并提供了许多在高级语言中才具有的控制结构,包括循环和分支。
- 它虽然不是Unix/Linux系统内核的一部分,但它调用了系统核心的大部分功能来执行程序、建立文件并以并行的方式协调各个程序的运行,深入了解和熟练掌握Shell的特性极其使用方法,是用好Unix/Linux系统的关键。
1.7 Shell用途
- 自动化批量系统初始化程序(update,软件安装,时区设置,安全策略…)
- 自动化批量软件部署程序(LAMP、LNMP、Tomcat、LVS、Nginx)
- 应用程序管理(KVM、集群管理扩容、MySQL、DELLR720批量RAID)
- 日志分析处理程序(PV、UV、200代码、!200代码、top 100、gerp/awk)
- 自动化备份恢复程序(MySQL完全备份/增量 + Croud)
- 自动化管理程序(批量远程修改密码,软件升级,配置更新)
- 自动化信息采集及监控程序(收集系统/应用状态信息,CPU,Mem,Disk,Net,TCP Status,Apache,MySQL)
- 配合Zabbix信息采集(收集系统/应用状态信息,CPU,Mem,Disk,Net,TCP Status,Apache,MySQL)
- 自动化扩容(增加运主机–>业务上线)zabbix监控CPU 80% +|-50% Python API AWS/EC2(增加/删除云主机) + Shell Script(业务上线)
2. Shell执行方式
方式一:bash test.sh
方式二:sh test.sh
方式三: . test.sh
方式四: source test.sh
演示如下:

如图可以看到,sh命令其实是一个软链接程序,在/usr/bin下的sh程序,文件类型是l,链接到了bash文件,所以这两种执行方式其实的一种。
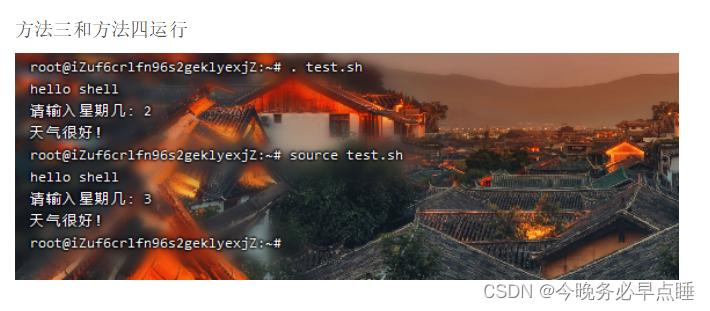
2.1 多种执行方式的区别
方式一和方式二,是子shell,一个独立环境。
方式三和方式四,是本shell,是当前环境。

演示如下
如图可以发现,方式一方式二是开了虚拟环境运行,运行之后会退出虚拟环境,不影响当前环境,
方式三和方式四是在本身的shell环境运行,运行之后会影响当前环境。
3. Shell解析器的位置

备注:因为Linux的系统类型问题,方式二不生效。CentOS里面两个方式都可运行
4.变量
4.1 什么是变量?
用一个固定的字符串去表示不固定的内容,便于修改。
4.2 自定义变量
用户自定义变量是最常用的变量类型,其特点是变量名和变量值都是由用户自由定义的
定义变量:变量名=变量值
引用变量:$变量名
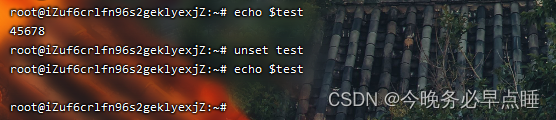
查看变量:echo $变量名;
取消变量:unset 变量名;
示例如图

变量的定义规则:
- 变量名不能以数字开头
- 等号左右两侧不能有空格
- 变量的值如果有空格,必须用引号包含
4.2.1 重复定义变量
一般情况下,重复定义变量会覆盖之前的变量值,如何进行重复定义变量值的叠加呢?

如上图所示,进行变量的叠加时,变量名需要用双引号或者${}包含。
4.3 查看所有变量
查看所有变量:
set

如图所示,会出现系统中所有的变量信息。
要查询特定变量,可以加管道查询:
set | grep 变量名

4.4 变量的删除
unset 变量名
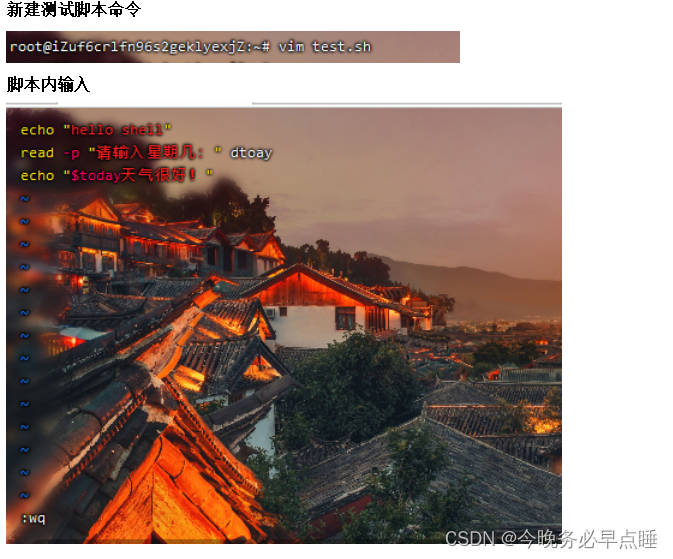
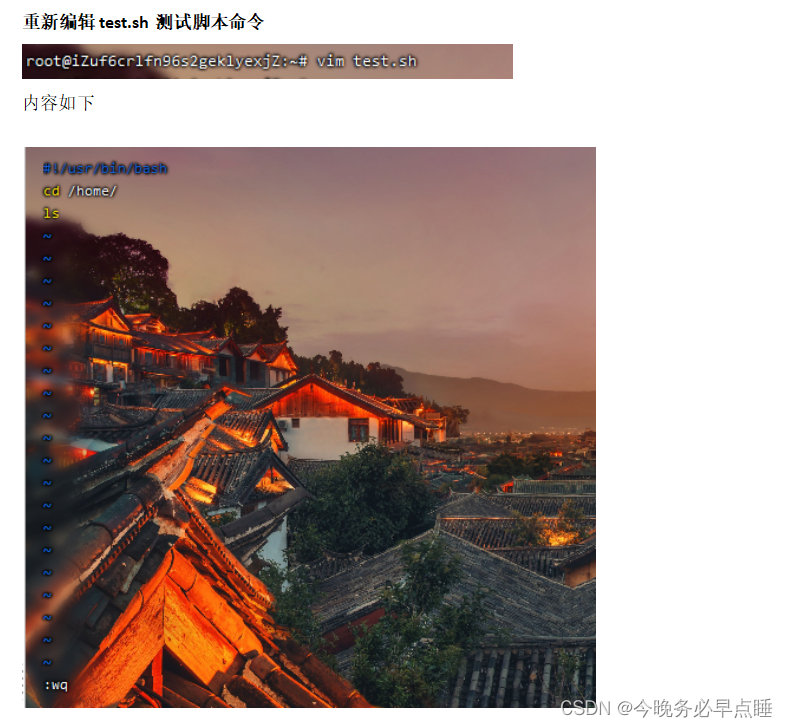
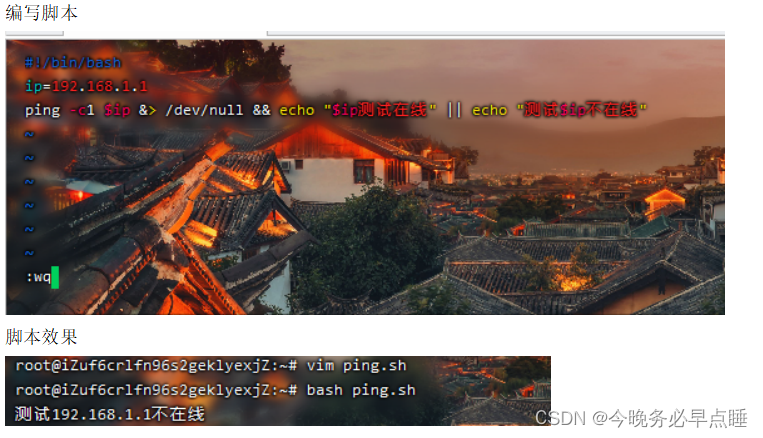
4.5 案例:测试主机在线的脚本
编写测试主机在线的脚本,当主机在线提示在线,当主机不在线提示不在线。
直接vim ping.sh,里面内容编写如下:

参数解释
ping 测试命令
-c1 c是count的缩写,次数,统计一次
$> /dev/null 输出重定向,将不想看的内容重定向到垃圾桶里
&& 上述脚本解释为前面ping命令执行成功时的操作
|| 上述脚本解释为前面ping命令执行失败的操作
补全脚本,增加变量后完整写法
4.6 交互定义变量
read 变量名
read命令指从键盘读取变量值
一般加参数-p使用,p代表print打印,后面的内容会给用户看到
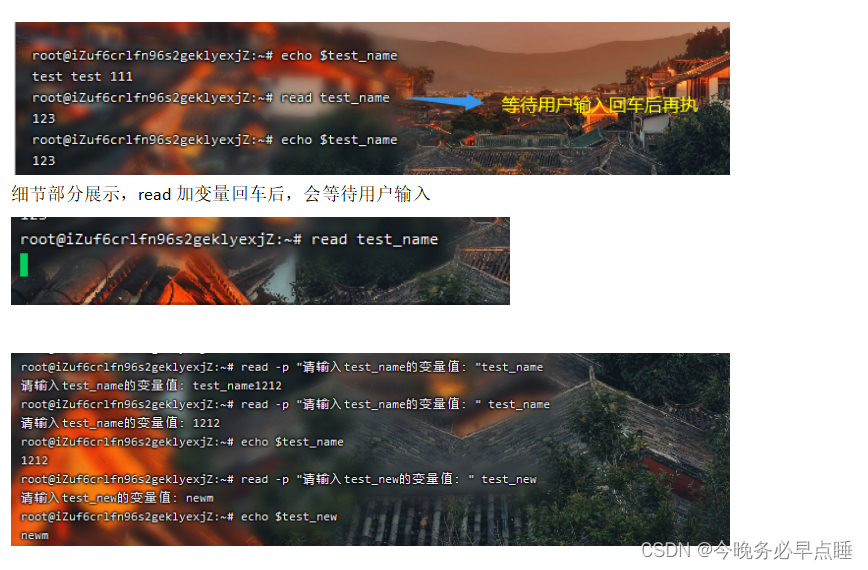
继续优化ping.sh

4.7 定义变量或者引用变量的注意事项
三种引号的区别
" " 弱引用,只能转义一些常用的空格,只是起到了一个分割的作用,$符号转义不了,比较常用
’ ’ 强引用,在单引号之内的所有特殊符号,都将失去它本身的含义
`` 优先执行,用在当我们把有些命令用在一起,希望有些命令的结果成为其他命令的参数的时候
效果展示如下

变量注意事项
变量名和等号直接不能有空格,这可能和你熟悉的所有编程语言都不一样。同时,变量名的命名须遵循如下规则:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可能使用下划线(_)。
- 不能使用标点符号。
- 不能使用bash里面的关键字(可用help命令查看保留关键字)
4.8 整数运算
方法一: expr $num1 + $num2
补充: + 加 - 减 \* 乘(*是任意字符,使用\转义一下) / 除 % 取余
方法二:$(())
方法三:$[]
方法四:let
示例如图

案例:制作脚本sum.sh,计算总成绩

参数echo -n 表示不换行输出 ,直到遇到下一个回车符才会换行
四种方法的示例
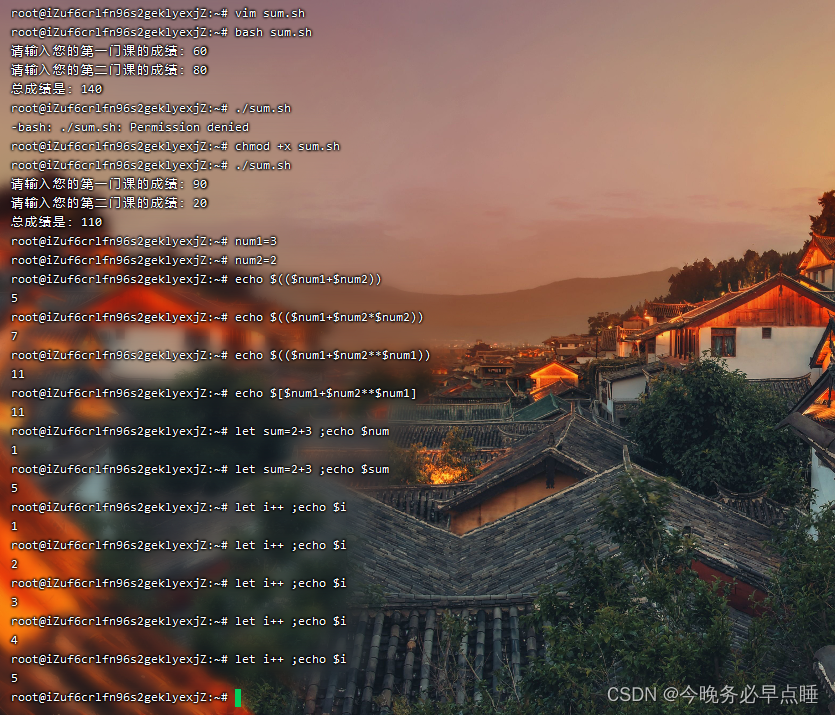
注意 i++ 表示从1开始自增,后面常用来计数
4.9 小数运算
安装计算机程序bc
计算机程序 bc 是一个用于数学计算的命令行计算器工具。它可以进行基本的数学运算(如加减乘除)、复杂的数学表达式计算、逻辑运算、函数计算等。bc 支持任意精度的数字计算,可以处理大量数据并提供高精度计算结果。
在命令行中使用 bc 可以进行各种数学运算,是一个非常方便的工具,特别适合在脚本或命令行环境下进行数学计算。通过输入表达式或者脚本文件,你可以利用 bc 进行各种数学运算,从简单的计算到复杂的数学公式都可以轻松应对。
如果是CentOS系统,可用命令
yum install -y bc
-y 选项的作用是在运行命令时自动回答 “yes”,即在安装软件包时不需要手动确认。这样可以避免在安装过程中出现需要用户确认的提示,使整个安装过程自动化,特别适用于批量安装或脚本中的使用。
如果是Debian系统,可用命令
sudo apt-get update
sudo apt-get install bc
安装如图所示
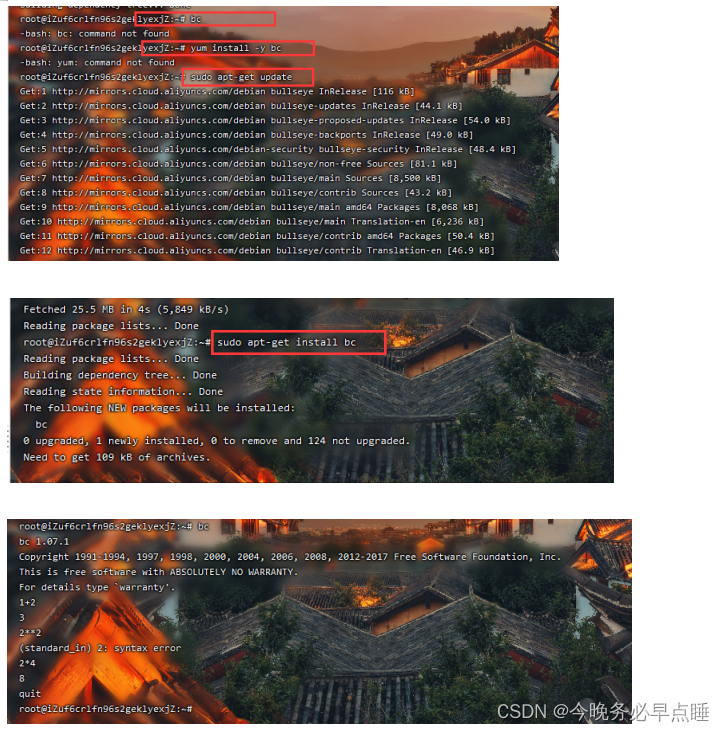
示例
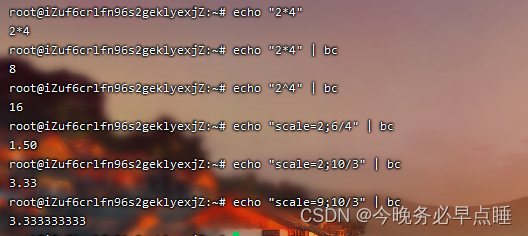
当用于shell脚本中时,可以通过将表达式传递给bc来进行数学计算。以下是一个简单的shell脚本示例,演示如何在shell脚本中使用bc执行数学计算:
#!/bin/bash
# 定义两个变量
num1=10
num2=20
# 使用bc计算两个变量的和
sum=$(echo "$num1 + $num2" | bc)
echo "Sum of $num1 and $num2 is: $sum"
在这个例子中,我们定义了两个变量 num1 和 num2,然后使用 bc 计算它们的和,并将结果存储在 sum 变量中。最后,打印出这两个数字的和。
你可以将以上代码保存到一个名为 calc.sh 的文件中,赋予执行权限(chmod +x calc.sh),然后在终端中运行 ./calc.sh 来执行这个脚本并查看计算结果。这只是一个简单示例,实际上你可以根据需要编写更复杂的脚本来使用 bc 进行各种数学计算。
4.10 环境变量

pstree
pstree 是一个用于显示进程树的命令行工具,它以树状结构的方式展示系统中运行的进程及其关系。通过 pstree 命令,你可以清晰地看到进程之间的父子关系,以及进程的层级结构。
使用 pstree 命令的基本语法是:
pstree [OPTIONS] [PID]
- OPTIONS 是一些可选参数,用于控制 pstree 的输出格式。
- PID 是指定的进程ID,如果未提供,则默认显示当前进程及其子进程的树状结构。
一些常用的 pstree 参数包括:
- -p:显示进程ID。
- -u:显示进程的拥有者。
- -n:按照进程ID排序。
- -h:高亮显示当前进程。
- -a:显示命令行参数。
例如,你可以在终端中输入 pstree -p 来显示当前进程及其子进程的树状结构,其中会包含每个进程的进程ID。你也可以查看 man pstree 获取更多关于 pstree 命令的详细信息和其他可用选项。
在CentOS中的安装办法
在 CentOS 中安装 pstree 命令也非常简单。pstree 命令通常包含在 psmisc 软件包中,因此你可以按照以下步骤在 CentOS 中安装 pstree:
- 使用 yum 命令更新软件包索引:
sudo yum check-update - 安装 psmisc 软件包(其中包含了 pstree 命令):
sudo yum install psmisc - 安装完成后,尝试运行 pstree 命令:
pstree
Debian 系统
在 CentOS 中安装 pstree 命令也非常简单。pstree 命令通常包含在 psmisc 软件包中,因此你可以按照以下步骤在 CentOS 中安装 pstree:
- 使用 yum 命令更新软件包索引:
sudo yum check-update - 安装 psmisc 软件包(其中包含了 pstree 命令):
sudo yum install psmisc - 安装完成后,尝试运行 pstree 命令:
pstree
安装后效果如下
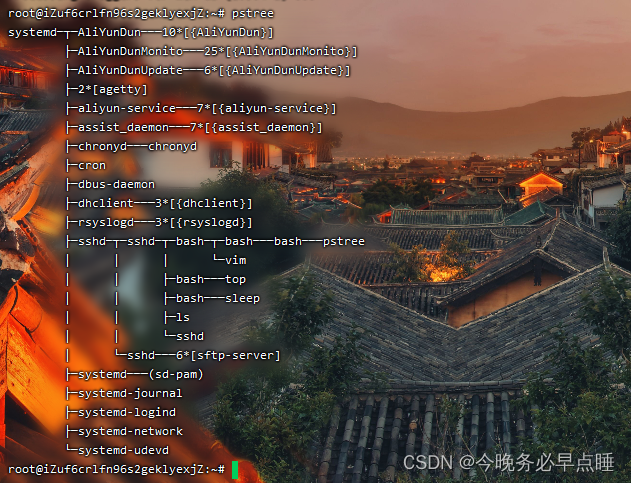
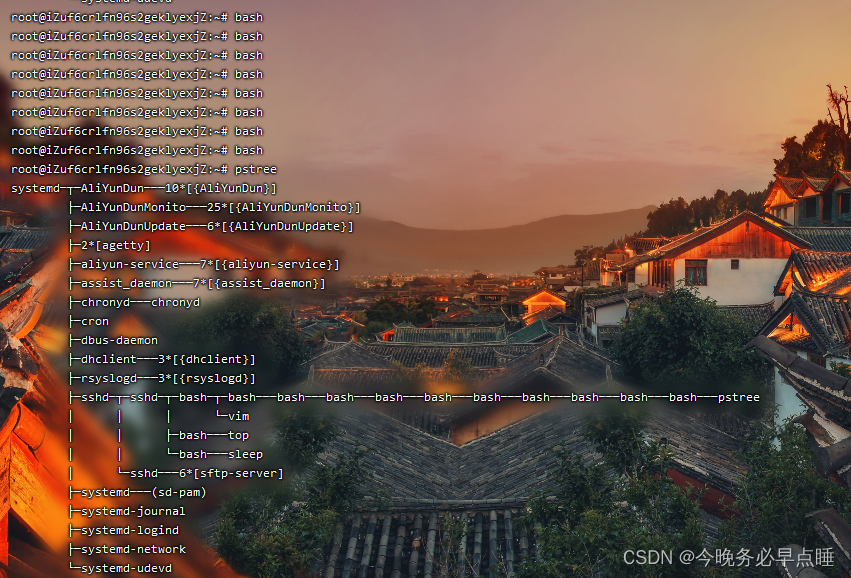
虽然bash都一样,但进程之间是有父子关系的
两种声明方式
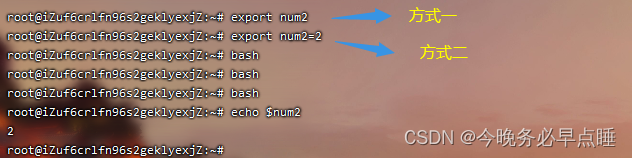
常用知识点
想使变量在当前用户登录后一直生效,可以将变量放到~/.bash_profile
想使变量在所有用户登陆后一直生效,可以将变量放到/etc/profile
不同服务器运行的bash是兄弟级别的shell,不是父子级别的shell
那么兄弟级别的shell变量如何传递?
在 Linux 系统中,如果想要设置一个变量在用户登录后一直生效,可以按照以下方式进行设置:
- 对于当前用户,在 ~/.bash_profile 文件中添加变量设置。打开 ~/.bash_profile 文件(如果不存在则可以新建),然后在文件中添加类似如下的语句:
export YOUR_VARIABLE=your_value - 对于所有用户,在 /etc/profile 文件中添加变量设置。打开 /etc/profile 文件,然后在文件中添加类似如下的语句:
export YOUR_VARIABLE=your_value
这样设置的变量会在用户登录后一直生效,对于当前用户放在 ~/.bash_profile,对于所有用户放在 /etc/profile。记得在设置完毕后,要重新加载配置文件或者注销再登录才能使变量生效。
常用场景
设置环境变量在用户登录后一直生效的常用场景包括:
- 自定义环境变量:你可以在 ~/.bash_profile 中定义自己的环境变量,比如指定特定程序的路径、配置文件的位置等等。
- 修改路径:通过修改 PATH 环境变量,你可以添加自定义的程序路径,使得系统可以直接识别并执行这些程序。
- 设置代理:如果需要在用户登录后一直使用代理,你可以将代理配置信息写入 ~/.bash_profile。
对于在所有用户登录后一直生效的场景,通常用于设置系统范围的环境变量,比如:
- 全局路径设置:将常用程序的路径添加到 PATH 环境变量中,让所有用户都可以直接执行这些程序。
- 系统级代理设置:对于需要整个系统使用代理的情况,可以在 /etc/profile 中进行代理配置。
- 全局配置:设置全局的环境变量,用于系统级的配置需求。
总之,通过在 ~/.bash_profile 和 /etc/profile 中设置环境变量,你可以确保这些变量在用户登录后一直生效,为用户和系统提供统一的环境。
操作演示,效果如下

因为系统版本不同,CentOS叫做.bash_profile文件,Debian里面是.profile文件
在 CentOS 中,用户的环境变量通常可以在 ~/.bash_profile 文件中进行设置,全局的环境变量则可以在 /etc/profile 文件中进行设置。这两个文件对应的路径如下:
- 用户级配置文件:~/.bash_profile
- 系统级配置文件:/etc/profile
通过编辑这两个文件,你可以设置用户级和系统级的环境变量,以确保它们在用户登录后一直生效。
在 Debian 系统中,用户级和系统级的环境变量设置方式与 CentOS 稍有不同。在 Debian 系统中,你可以按照以下方式设置环境变量:
- 用户级环境变量:
- 对于单个用户,可以在 ~/.bashrc 或 ~/.profile 文件中设置用户级环境变量。
- 如果希望环境变量对所有交互式 shell 都可用,通常建议将其添加到 ~/.bashrc 文件中。
- 系统级环境变量:
- 在 Debian 系统中,全局环境变量通常被设置在 /etc/environment 文件中。
- 你也可以在 /etc/profile 或 /etc/bash.bashrc 中设置系统级环境变量。
因此,在 Debian 系统中,你可以根据需要选择合适的文件来设置用户级和系统级的环境变量。记得在修改配置文件后,需要重新登录用户或重新加载配置文件才能使环境变量生效。
查看系统自带的环境变量
env

4.11 位置变量和预定义变量
在 Shell 脚本中,位置变量(Positional Parameters)和预定义变量(Predefined Variables)是很常用的概念,它们可以帮助你在脚本中处理参数和获取系统信息。
- 位置变量(Positional Parameters):
- 位置变量是指在执行脚本时传递给脚本的参数,在脚本内部可以通过 $1、$2、$3 等方式来引用这些参数。
- $1 表示第一个参数,$2 表示第二个参数,依此类推。
- 如果参数超过 9 个,需要使用花括号将数字包裹,如${10}。
- 使用 “$@” 可以引用所有的位置变量。
示例:
#!/bin/bash
echo "The first parameter is: $1"
echo "The second parameter is: $2"
echo "All parameters are: $@"
- 预定义变量(Predefined Variables):
- 预定义变量是指在 Shell 中预先定义好的一些特殊变量,包括但不限于:
- $0:脚本本身的名称。
- $$:当前脚本的进程 ID。
- $*:当前脚本的所以的参数。
- $#:当前脚本的参数的个数。
- $?:上一个命令的退出状态(返回值)(0是成功,非零是失败)。
- $USER:当前用户的用户名。
- $HOME:当前用户的主目录路径等等。
- 这些变量提供了访问脚本运行环境和系统信息的便利方式。
- 预定义变量是指在 Shell 中预先定义好的一些特殊变量,包括但不限于:
示例:
#!/bin/bash
echo "The script name is: $0"
echo "The process ID is: $$"
echo "The exit status of last command is: $?"
echo "The current user is: $USER"
echo "The home directory is: $HOME"
通过合理地使用位置变量和预定义变量,你可以更灵活地处理参数、获取系统信息,提升 Shell 脚本的功能和效率。
4.12 案例:用户制作输入成绩脚本
案例1

案例2

可以看出,read和位置变量场景都可以通用,没有优先级的区别。位置变量不是程序设计的唯一方法,比如read也可以。
优化sum.sh脚本


4.13 变量章节重点案例脚本
1.用于自动创建用户并设置初始密码的脚本
你可以使用以下 Shell 脚本编写一个用于自动创建用户并设置初始密码的脚本。在这个脚本中,我们将使用 useradd 命令来创建用户,并结合 echo 和 passwd 命令来设置用户的初始密码。
#!/bin/bash
# 提示输入新用户的用户名
read -p "请输入要创建的新用户的用户名: " username
# 使用 useradd 命令创建新用户
useradd $username
# 提示输入初始密码,并使用 passwd 呑令设置密码
read -s -p "请输入初始密码: " password
echo -e "$password\n$password" | passwd $username
echo "用户 $username 创建成功,并已设置初始密码。"
这个脚本的工作流程如下:
- 提示用户输入要创建的新用户的用户名。
- 使用 useradd 命令创建新用户。
- 提示用户输入初始密码,并使用 passwd 命令设置密码给新创建的用户。
- 最后输出提示信息表示用户创建成功并设置了初始密码。
使用上述脚本,你可以方便地自动创建用户并设置初始密码。记得在运行脚本之前确保脚本有执行权限(可以使用 chmod +x script.sh 给予执行权限),然后在终端中运行该脚本即可。
2.CentOS系统编写脚本,配置本地yum源
要编写一个脚本来配置本地的 YUM 源,你可以创建一个 Shell 脚本,其中包含添加、启用和更新 YUM 源的步骤。以下是一个简单的示例脚本:
#!/bin/bash
# 备份原始yum源配置文件
cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
# 创建新的yum源配置文件
cat > /etc/yum.repos.d/local.repo <<EOF
[local]
name=Local Yum Repository
baseurl=file:///path/to/your/local/repo
enabled=1
gpgcheck=0
EOF
# 清除旧的yum缓存
yum clean all
# 更新yum源
yum makecache
在这个脚本中:
- 首先备份了原始的 CentOS yum 源配置文件(假设你使用的是 CentOS 操作系统)。
- 创建了一个新的 YUM 源配置文件 local.repo,其中包含了本地 YUM 源的信息,你需要将 /path/to/your/local/repo 替换为你实际的本地 YUM 源路径。
- 清除了旧的 yum 缓存。
- 最后更新了 yum 源。
记得在运行脚本之前,将脚本中的 /path/to/your/local/repo 替换为你实际的本地 YUM 源路径,并确保脚本有执行权限(可以使用 chmod +x script.sh 给予执行权限),然后在终端中运行该脚本即可。
- Debian 系统编写脚本,配置本地yum源
如果你想在 Debian 系统上配置本地的 APT 源,你可以使用以下类似的 Shell 脚本来实现:
#!/bin/bash
# 备份原始的源列表文件
cp /etc/apt/sources.list /etc/apt/sources.list.bak
# 创建新的源列表文件
cat > /etc/apt/sources.list <<EOF
deb file:///path/to/your/local/repo/ buster main
EOF
# 更新软件包列表
apt update
在这个脚本中:
- 首先备份了原始的 APT 源列表文件。
- 创建了一个新的源列表文件 sources.list,其中包含了本地 APT 源的信息,你需要将 /path/to/your/local/repo/ 替换为你实际的本地 APT 源路径和版本信息(比如 buster 是 Debian 10 的代号)。
- 使用 apt update 命令更新软件包列表。
记得在运行脚本之前,将脚本中的 /path/to/your/local/repo/ 替换为你实际的本地 APT 源路径和版本信息,确保脚本有执行权限(可以使用 chmod +x script.sh 给予执行权限),然后在终端中运行该脚本即可。
下一节讲流程控制