目录
教程专栏前文传送门:
前言:
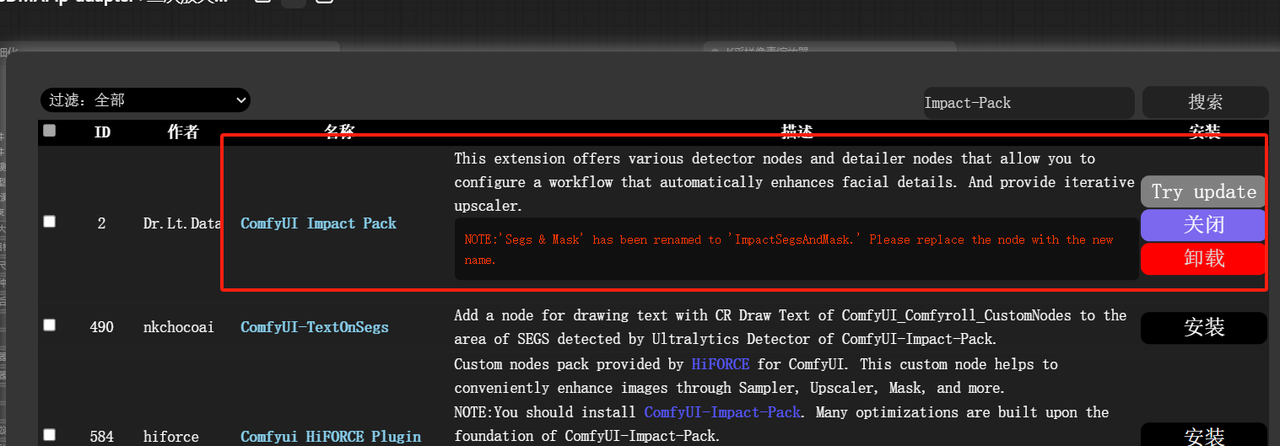
当我们在comfyUI中想将多个条件联结输入,有Concat,Combine,Average三种节点可选:


可以看到他们都是输入两个条件整合后输出一个条件,那么他们都如何使用,在原理上他们有什么区别,各自的适合场景有哪些呢?
节点使用说明
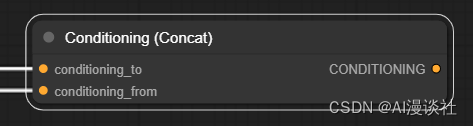
Conditioning(Concat)
原理和场景
串联联结节点,如果你使用中文插件你会发现这个节点被翻译成了“条件联结”

这个词不太能明确的感受他的原理。他的作用是将两组条件串联后发送到潜空间内:
{条件A}{条件B} -> 生成原始噪音 -> 绘画采样流程
用做蛋炒饭来比喻,就像是先将蛋放锅里,然后再加入饭翻炒一样。他更适合将画面中不同的部分拆分出来分成多个提示框再合并输入,比如让人物和背景,上衣和裤子等。
比如 “一个男人穿着白色外套和黑色帽子” 提示词,这样我们可以分开提示,然后修改下面的不同帽子来达到出图效果的改变:

同理,我们在实际使用中可以将背景提示词放到下面的提示框中,这样可以在完整流程中不停的抽卡生成想要的背景
注意点和小技巧:
虽然节点上分为了from和to两个入口,但是任意交换条件生成的图片不会有任何区别:

将提示词拆分隔离串联,不但可以对生成流程这种业务上的优化,且对实际出图的可以稍微减轻“串色”的问题,如果我们只使用一个提示框去生成图片:

可以看到,帽子的颜色受到了前面白色外套提示词的影响更明显了。
Conditioning(Combine)
原理和场景
混合联结节点

他的工作原理如下
{条件A} -> 生成原始噪音A => 绘画采样流程 {条件B} -> 生成原始噪音B
用做蛋炒饭来比喻,就像是先炒蛋,再用一个锅炒饭,然后再拌到一起。他在融合时会更好的将提示中不同的风格特征混合保留。
比如 “一个男人穿着红色外套 ” 和”一个女人穿着白色外套“提示词,通过此节点我们混合后可以得到不男不女的人物和红白夹杂的外套:
如果我们使用Conditioning(Concat)节点会得到什么呢?
答案是 红色外套,白色外套,男人,女人 这四种元素的任意组合

从这可以看出他们在应用上,Concat 侧重于提示的组合,Combine侧重于结果的混合
注意点和小技巧:
如果你想要融合的特征差距过于巨大。比如“一只兔子”和“一个女孩”。一只兔子的噪声提示过于突出会彻底压倒关于人类的噪声,导致融合结果大部分时候彻底偏向兔子。而且这个节点也没有可以设置噪声比例的控制,so,不建议用这个节点融合特征差距过于巨大的两个事物。

Conditioning(Average)
原理和场景
平均联结节点

他的工作原理如下
{x% * 条件A + (1-x%) * 条件B } -> 生成原始噪音A -> 绘画采样流程
用做蛋炒饭来比喻,就像是先按照比例将蛋液和米饭混合,然后再下锅炒。他在当比例设置为0.5时,结果有点类似于Conditioning(Concat),但是他可以精准控制每个部分的比例
比如 “一个男人穿着红色外套 ” 和”一个女人穿着白色外套“提示词,通过此节点我们混合后可以得到的是
还是红色外套,白色外套,男人,女人 这四种元素的任意组合
注意点和小技巧:
前面我们提到过Conditioning(Combine),在特征差距很大时,混合效果会彻底偏向某一个特征。
那么我们能不能利用Conditioning(Average)的强度比例设置达成这一目标呢?
先说结论:可以也不可以
为什么不可以?
让我们回顾原理,他的作用有点类似于将两组提示词按比例写在同一个框中。而我们知道AI绘画的流程实际上是将成百上千的图打上标签喂给AI,让他记住什么样的提示词对应什么样的图像特征。
大部分模型所训练的数据来源很少有图片的标注是(男&女),这种也许会更精准的标注"跨性别者",所以一个男人和一个女人的组合提示词,或者一个人和一个兔子的提示词无论怎么调整比例都很难生成你想要达到的半男半女或半人半兽的状态,如下图所示:
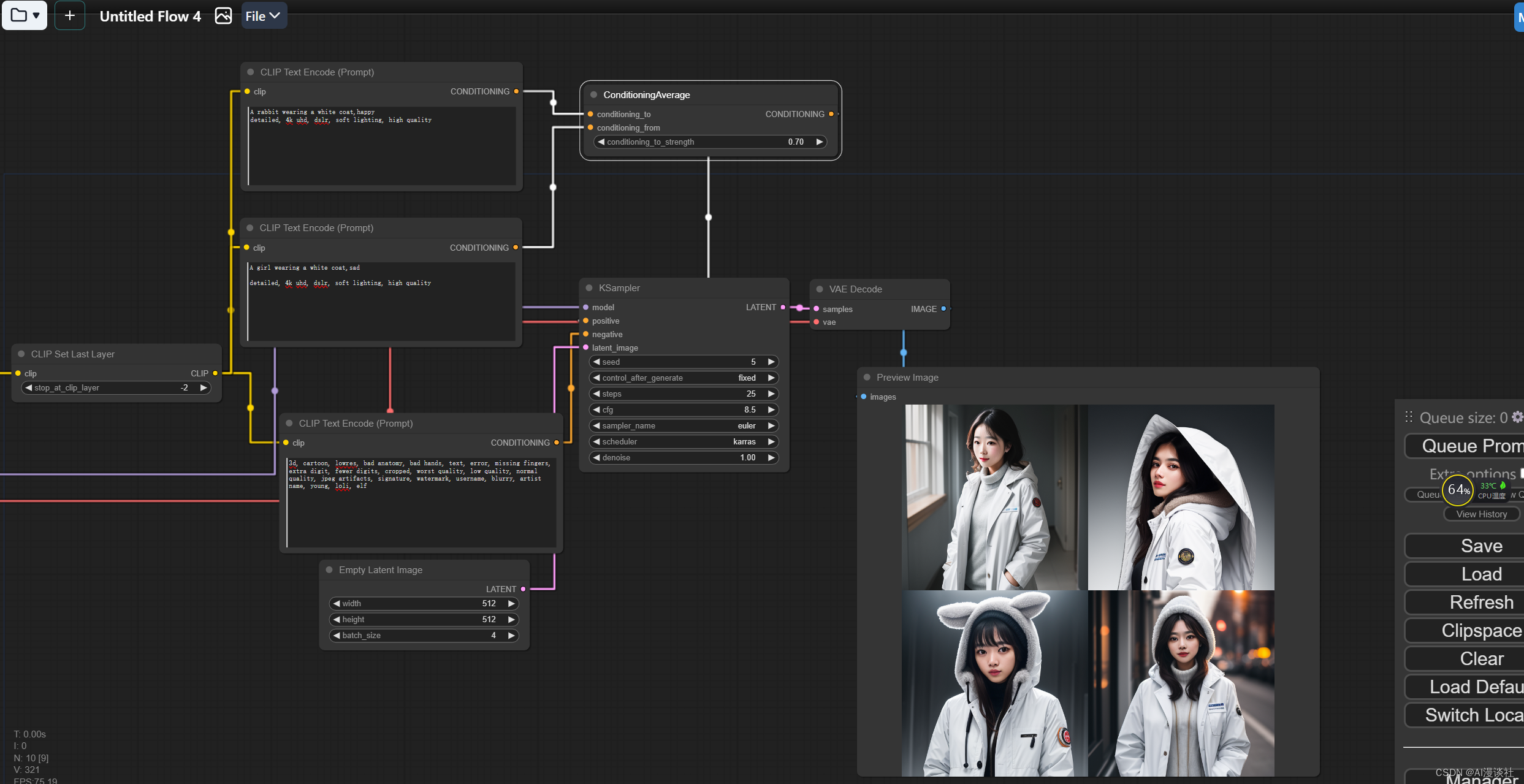
我尝试过0.75,0.725,0.775的比例,结果都不太好~
那为什么又说可以呢?
比如(女孩,兔子)在偏真实系的模型中,确实不会有这种特殊的标注,但是如果你所用的模型本身有这种训练,或者你的提示词就是幻想风格的,那么这个节点完全能达成你的期望!比如我是用二次元漫画风格的模型:
这个节点我认为最适合的地方,在于可以在主体图片不变的情况下细腻的控制局部的风格:
比如我想生成同一个女孩从悲伤到开心不同比例的图片:

总结:
Conditioning(Concat) 是将两个条件节点串联投入,生成噪声和图像。适合对图画中不同的部分分开表述组合到一起。
Conditioning(Combine)是两个不同条件分别生成噪声在融合采样成图像。适合对两个特征不十分冲突的条件效果进行融合。
Conditioning(Average)是两个不同条件按照比例融合成一个条件,再生成噪声和图像。适合细腻的控制局部的风格
最后:
本文主体来源是ComfyUI官方社区文档页面,由AI漫谈社整理翻译。由于官方文档还在更新,尤其缺少很多节点的详细使用说明、解释,场景样例和常见其他自定义节点的补充说明。我也会在接下来在本专栏持续翻译整理并补充这部分内容。点赞加速更新!
如果觉得网页浏览效果不好,
也可以查看我的公众号,回复“官方文档”获取完整中英PDF版本(持续更新),还有更多工作流分享!
——AI漫谈社
































![[0-1Django] Core.Management 模块](https://img-blog.csdnimg.cn/direct/f80b00ca2eff4a9ab1f8f8551da3429f.png)

![[实践经验]: visual studio code 实用技巧](https://img-blog.csdnimg.cn/direct/8f4c856c3be84d0fa42b6fa983788438.png)
