“空虚敲打着意志,仿佛这时间已静止。”
TCMalloc简介与使用

TCMallo其全称为 —— “Thread-Cache Malloc”是由Google工程师开发的一种内存分配算法库,最初作为Google的性能工具库perftools的一部分发布。TCMalloc主要是用于替代传统的malloc内存分配函数,从而减少内存分配产生的碎片问题,提高内存分配效率,满足、适用于多核和更好的并行性支持等特性。
TCMalloc在实际的测试中,与glibc 2.3 malloc(其内核采用的是ptMalloc)进行性能测试,在使用同一CPU下,实验数据表面前者比后者进行malloc\free所花费的时间要少得多。
TCMalloc体现其高速获取、分配内存块,既有其为采用"池化技术"缓存常用对象(内存块),还因其在每个线程(ThreadCache)独立设置缓存分配策略,真正意义上实现了获取小对象的无锁竞争,降低了锁竞争带给内存管理的性能损耗。当然,这是本文的核心所在,也是后面所要详解的。
TCMalloc使用
下载tcmalloc源码
TCMalloc属于gperftools,gperftools项目包括heap-checker、heap-profiler、cpu-profiler、TCMalloc等组件。如果想定制化安装,请自行参阅gperftools的安装文档,即源码包中的INTALL文件....
所以要使用TCMalloc,我们就得去下载gperftools,我们可以渠道gperftools源地址。从git仓库clone版本的gperftools的安装依赖autoconf、automake、libtool:
# 获取源码
git clone https://gitcode.com/gperftools/gperftools.git
# 安装依赖
sudo yum install -y autoconf automake libtool
# 生成configure等一系列文件
./autoge.sh
# 生成makefie
./configure
# 编译 安装
make && make install
# 默认安装在/usr/local/下的相关路径bin、lib、share,可在configure时以–prefix=PATH指定其他路径获取tcmalloc库~

tcmalloc库加载到Linux系统中
🏀 以动态库的方式运行
# 编译源文件
g++ -O0 -g -ltcmalloc tcmalloc.cc -o tcmalloc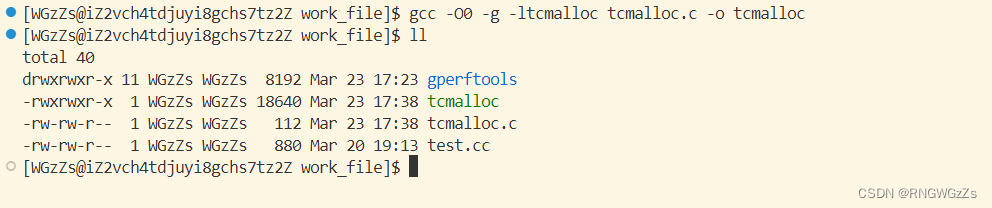
这个可能找不到咱们的动态库:

🏀 以静态库的方式运行
$ g++ -O0 -g -pthread test.cc /usr/local/lib/libtcmalloc_and_profiler.a
TCMalloc源码剖析
TCMalloc架构

🌏 Front-end(前端): 负责提供快速分配和重分配内存给应用,由Per-thread \ Per-cpu组成.
🌏 Middle-end(中间件): 为Front-end提供缓存。Front-end内存块不足时,会找Middle-end.
🌏 Back-end(后端): 负责从操作系统获取内存,并给Middle-end提供缓存使用.
在TCmalloc极大的应用缓存技术,使用三层缓存减少对内存频繁的申请。
TCMalloc内存申请流程:

🕋ThreadCache: 每一个线程独享一个ThreadCache,线程的任何内存请求会转发给它.
🕋CentralCache: 一旦ThreadCache没有 "需求"内存块,就会去找CentralCache.
🕋PageHeap: 当CentralCache的内存块也消耗告罄,就会找到最终的PageHeap申请.
PageHeap不够用就会向OS操作系统申请。
TCMalloc分配单位扫盲:
🍊 Page是操作系统对内存管理的单位:
. 在TCMalloc中以Page为单位管理内存块(Page默认大小为8KB),通常为Linux系统中Page大小的倍数关系,我们可以通过编译选项 "--with-tcmalloc-pagesize"。
🍊 Span是PageHeap中管理内存Page的单位:
当"User Code"首次申请内存,ThreadCache、CentralCache、PageHeap都是没有挂载任何内存块的!这个时候PageHeap会一次性申请较大的内存块,假设Page=128,这肯定用不完,可能只需要取2~3page就行了,那么剩下的Page如何管理呢?该怎样放置呢?
由此,引入了Span —— 本质就是一个类,用于管理向系统申请的大块内存块,由一个或多个连续的Page组成。 
Span需要包含的信息就十分多了,它需要记录所指内存块的起始ID,以及Page包含的数量,这我们之后细说~
🍊 Size Class:
TCMalloc定义了很多个size class,每个size class都维护了一个可分配的FreeList。FreeList中的每一项称为一个object,同一个size-class的FreeList中每个object大小相同。

在申请小内存时(小于256K),TCMalloc会根据申请内存大小映射到某个size-class中。至于映射的规则是什么,能映射出多少来也是放在之后来细说~
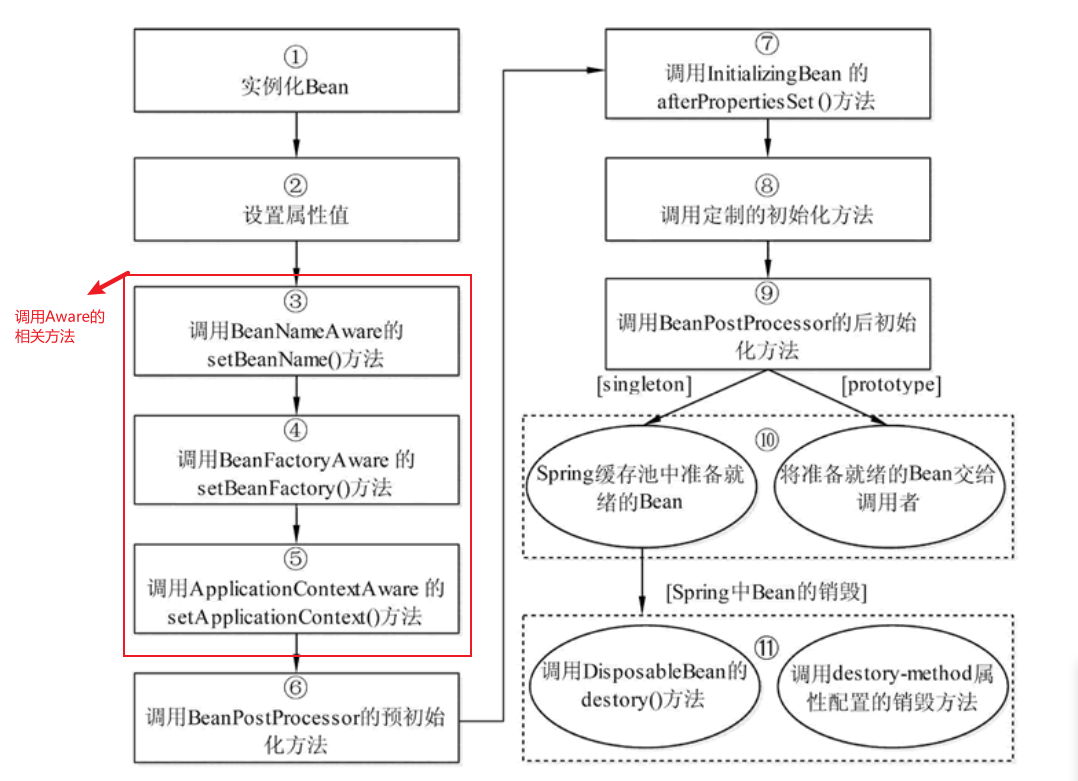
TCMalloc初始化
⛳ 何时初始化?
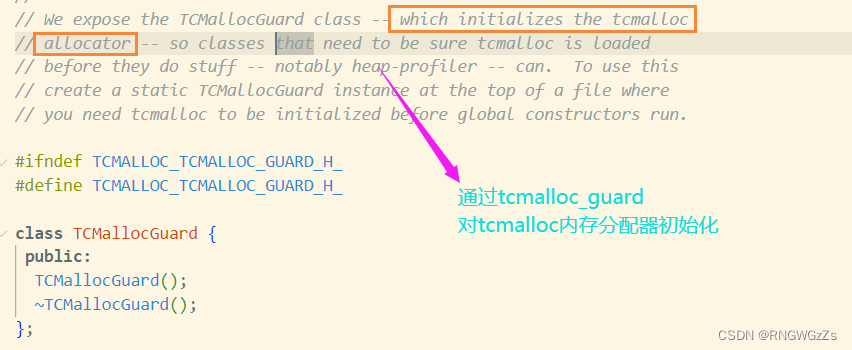 这一个类存在于 "tcmalloc.cc",用于保证TCMalloc在main()函数之前,完成基本构造~
这一个类存在于 "tcmalloc.cc",用于保证TCMalloc在main()函数之前,完成基本构造~
static TCMallocGuard module_enter_exit_hook;⛳ 如何初始化?
// tcmalloc.cc
static int tcmallocguard_refcount = 0; // no lock needed: runs before main()
TCMallocGuard::TCMallocGuard() {
if (tcmallocguard_refcount++ == 0) {
ReplaceSystemAlloc(); // defined in libc_override_*.h
tc_free(tc_malloc(1));
ThreadCache::InitTSD();
tc_free(tc_malloc(1));
// Either we, or debugallocation.cc, or valgrind will control memory
// management. We register our extension if we're the winner.
#ifdef TCMALLOC_USING_DEBUGALLOCATION
// Let debugallocation register its extension.
#else
if (RunningOnValgrind()) {
// Let Valgrind uses its own malloc (so don't register our extension).
} else {
MallocExtension::Register(new TCMallocImplementation);
}
#endif
}
}我们可以看到TCMalloc在初始化时会调用两次 "tc_malloc()",并立马释放掉。这里的 "InitTSD()"(这个会在之后再次提及)就是ThreadCache为什么能实现无锁竟争的缘故,跟随源码跳转,我们会在pthread.h中看到其声明:
// Thread_Cache.cc
void ThreadCache::InitTSD() {
ASSERT(!tsd_inited_);
perftools_pthread_key_create(&heap_key_, DestroyThreadCache);
tsd_inited_ = true;
// ....
}
// pthread.h
extern int pthread_key_create (pthread_key_t *__key,
void (*__destr_function) (void *))
__THROW __nonnull ((1));当然,在TCMalloc启动时,不会只初始化这一出,如下部分也会进入初始化:
🎨初始化SizeMap
🎨初始化各种Allocator
🎨初始化CentralCache
🎨 创建PageHeap
三层缓存概述及其功能
ThreadCache:
TCMalloc中,为小对象内存块预备了几块缓存,即ThreadCache。每一个ThreadCache中所对应的Size-Class都会拥有一个单独的_freeList,上面用链表维护了一段 未被使用的空闲对象~

每一个线程都对应着一个独立的ThreadCache。因此从ThreadCache中取用或回收内存是不需要加锁的,速度很快。
小对象的分配直接从对应的_free_list中获取一个空闲对象,小对象内存块归还,也是找到对应的_free_list将该内存块归还其中。
ThreadCache的创建与销毁:
当某一个线程第一次申请内存分配时,TCMalloc为该线程申请了一份专属ThreadCache.
inline ThreadCache* ThreadCache::GetCache() {
#ifdef HAVE_TLS
ThreadCache* ptr = GetThreadHeap();
#else
ThreadCache* ptr = NULL;
if (PREDICT_TRUE(tsd_inited_)) {
ptr = GetThreadHeap();
}
#endif
if (ptr == NULL) ptr = CreateCacheIfNecessary();
return ptr;
}当一个ThreadCache要销毁时,会用 TSD在ThreadCache模块初始化设定的回调函数,完成对ThreadCache对象的清理:
void ThreadCache::DestroyThreadCache(void* ptr) {
#ifdef HAVE_TLS
threadlocal_data_.heap = NULL;
threadlocal_data_.fast_path_heap = NULL;
#endif
DeleteCache(reinterpret_cast<ThreadCache*>(ptr));
}
void ThreadCache::InitTSD() {
ASSERT(!tsd_inited_);
perftools_pthread_key_create(&heap_key_, DestroyThreadCache);
tsd_inited_ = true;
// ....
}SizeClass小对象内存对齐:
如何定义小对象呢?
TCMalloc对待大的内存(文章说大于32K,但其实看代码应该是大于256K的内存)的分配是直接从central heap中使用页层级的分配器(一页内存就是按照 4K 向上对齐)。该对象总是页面对齐,并占据完整的页面。
static const size_t kMaxSize = 256 * 1024;
Size-class的映射对齐都被统一封装在了 "SizeMap"这个类之中。我们现目前存在两个需要解决的问题:
🍔 小对象是如何划分的
🍔 对于任意一个 < KmaxSIze 如何映射到某一种缓存对象上?
// 源码中的kMaxSize设置的 256KB 并非原文中的32KB
static const size_t kMaxSize = 256 * 1024;我们窥测定位到 "SizeMap"类中,寻找蛛丝马迹:
// 对应映射转换规则的界限值
static const int kMaxSmallSize = 1024;
// 计算出"s"在 class_array[]中的映射下标
static inline size_t ClassIndex(size_t s) {
// Use unsigned arithmetic to avoid unnecessary sign extensions.
ASSERT(0 <= s);
ASSERT(s <= kMaxSize);
if (PREDICT_TRUE(s <= kMaxSmallSize)) {
// 映射规则 --> Index Function
return SmallSizeClass(s);
} else {
return LargeSizeClass(s);
}
}
// 获取到size 在 class_array中的index
inline int SizeClass(size_t size){ return class_array_[ClassIndex(size))]; }
// 从size-class 映射的可存储的最大大值
int32_t class_to_size(uint32_t cl) { return class_to_size_[cl]; }ClassIndex:

原来咱们的 "SizeClass(size_t)" 仅仅是返回的是 class_array_的下标。这个Size的索引是由IndexFunction计算的。这个映射转换规则也是十分简单:
当Size ≤ 1024 时,此时的对齐数 alignment ≥ 8.
当Size > 1024 时,此时的对齐数 alignment ≥ 128.
这样,如果我们计算从 [1~1024] 范围内的下标index,这个index的范围就会在 0~ceil(size/8),即: 0~128。对于 [ 1025 ~ KMaxSize ],就会映射成[8,9,..,2,048]。不过 [1~1024] 已经占据了[ 0 ~ 128]的下标,所以我们得在后一组增添一个base值(128), [ 1024~KMaxSize] 就会映射为 [ 129,130,....,2168],这样我们就可以让两个数组合并了~ 同样,关于这部分,我们在源码中也可以得到一定的表示:
// 若KMaxSize = 256 * 1024 kClassArraySize = 2,176
static const size_t kClassArraySize = ((kMaxSize + 127 + (120 << 7)) >> 7) + 1;
unsigned char class_array_[kClassArraySize];根据上述的映射规则,我们也能开始逐渐理解如下 Index Function工作的原理:
当size ≤ 1024,:(size + 7) / 8 转换为 (s + 7) >> 3
同理当 size>1024:(size + 127) / 127 转换为 (size + 127 + (120 << 7)(加上base)) >> 7
static const int kMaxSmallSize = 1024;
if (PREDICT_TRUE(s <= kMaxSmallSize)) {
// 映射规则 --> Index Function
return SmallSizeClass(s);
} else {
return LargeSizeClass(s);
}
static inline size_t SmallSizeClass(size_t s) {
return (static_cast<uint32_t>(s) + 7) >> 3;
}
static inline size_t LargeSizeClass(size_t s) {
return (static_cast<uint32_t>(s) + 127 + (120 << 7)) >> 7;
}class_to_size_
"ClassIndex(size_t)"算是搞清楚了,它仅仅是计算出了size所在的class_array中索引值,而class_array的索引即是 class_to_size(对齐后)大小。该数组大小为 KClasSizesMax。
static const size_t kClassSizesMax = 128;
// cl是通过 SizeClassIndex计算后的
int32_t class_to_size(uint32_t cl) { return class_to_size_[cl]; }
// Mapping from size class to max size storable in that class
// 从size-class 建立 最大存储大小的映射
int32_t class_to_size_[kClassSizesMax];class_array_和class_to_size_是简单的数组,它们都会在模块加载时,在SizeMap::Init()中得到初始化~
static const size_t kAlignment = 8;
static const size_t kMaxSize = 256 * 1024;
void SizeMap::Init() {
// ...
// other inital steps
int sc = 1; // 下一个要分配的 size-class
int alignment = kAlignment;
CHECK_CONDITION(kAlignment <= kMinAlign);
for (size_t size = kAlignment; size <= kMaxSize; size += alignment) {
alignment = AlignmentForSize(size);
CHECK_CONDITION((size % alignment) == 0);
/* .. 关于page的部分
int blocks_to_move = NumMoveSize(size) / 4;
....
*/
if (sc > 1 && my_pages == class_to_pages_[sc-1]) {
const size_t my_objects = (my_pages << kPageShift) / size;
const size_t prev_objects = (class_to_pages_[sc-1] << kPageShift)
/ class_to_size_[sc-1];
if (my_objects == prev_objects) {
// Adjust last class to include this size
class_to_size_[sc-1] = size;
continue;
}
}
}
// other inital steps
class_to_pages[sc] = my_page;
class_to_size[sc] = size;
sc++;
}
该代码还包含了其他的成员初始化,我们并不关心这些,只截取了有关class_to_size初始化的过程。
代码中,class_to_size_很直观地能够分析出,class_to_size_是按照不同的size累加alignment实现的映射。
至于这个alignment的值是取多少,是由如下一对儿函数决定:
// Note: the following only works for "n"s that fit in 32-bits, but
// that is fine since we only use it for small sizes.
// 这个函数只适用于工作在 n(32-bit),不过因为我们申请的都是小块内存 并不影响
static inline int LgFloor(size_t n) {
int log = 0;
for (int i = 4; i >= 0; --i) {
int shift = (1 << i);
size_t x = n >> shift;
if (x != 0) {
n = x;
log += shift;
}
}
ASSERT(n == 1);
return log;
}
#if defined(TCMALLOC_ALIGN_8BYTES)
static const size_t kMinAlign = 8;
#else
static const size_t kMinAlign = 16;
#endif
static const size_t kAlignment = 8;
static int AlignmentForSize(size_t size) {
int alignment = kAlignment;
if (size > kMaxSize) {
// Cap alignment at kPageSize for large sizes.
alignment = kPageSize;
} else if (size >= 128) {
// Space wasted due to alignment is at most 1/8, i.e., 12.5%.
alignment = (1 << LgFloor(size)) / 8;
} else if (size >= kMinAlign) {
// We need an alignment of at least 16 bytes to satisfy
// requirements for some SSE types.
alignment = kMinAlign;
}
// Maximum alignment allowed is page size alignment.
if (alignment > kPageSize) {
alignment = kPageSize;
}
CHECK_CONDITION(size < kMinAlign || alignment >= kMinAlign);
CHECK_CONDITION((alignment & (alignment - 1)) == 0);
return alignment;
}LgFloor是个二分法求Size 二进制的最高位。对齐方式可以简化成如下的公式:

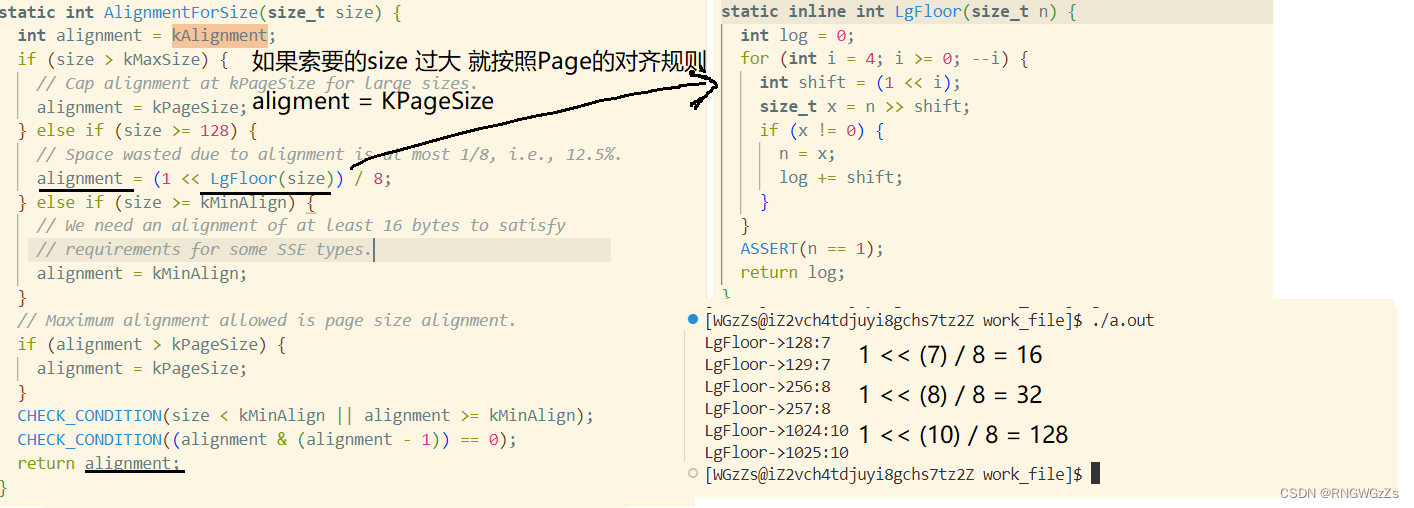
这样,我们可以通过这些函数剖析出class_to_size的分类规则如下:
🎨 [0,16] 按照 8types 对齐.
🎨 [16,127] 按照16bytes 对齐.
🎨 [128,KMaxSize] 按照 (1 << LgFloor(size)) / 8 对齐。当然你也可以理解为这样,“ ( 2^(n+1) - 2^n) / 8 ” ,n取值范围为: 7 ~ 18.

它们将剩余的空间划分成:
[128+16,128 + 2*16, ...,128+8*16,256 + 32,256+32*2,...,256+8*32, ..., 1024 + 128]
{
"128~255": 7
"256~511": 16
"512~1023": 8
"1024~2047": 8
.....
}
ClassIndex计算出来的对齐值太过于密集总共可以映射出2000多个值出来,所以在此多封装了一层class_array完成二次映射,从而找到真正对齐的值~
🎨 256*1024的部分,则按照Page对齐的方式.
class_array_
class_array_的初始化在class_to_size_之后:
// Initialize the mapping arrays
int next_size = 0;
// num_size_classes 其实就是初始化class_to_size数组时的大小
for (int c = 1; c < num_size_classes; c++) {
const int max_size_in_class = class_to_size_[c];
for (int s = next_size; s <= max_size_in_class; s += kAlignment) {
// 映射到这个 size-class 其对应的 size是多少呢? 通过class_to_size填充
class_array_[ClassIndex(s)] = c;
}
next_size = max_size_in_class + kAlignment;
} 所以,最终我们可以得出这样的更迭过程,得到我们需求的old size 内存对齐后的 new size
例如: 我们向TCMalloc申请 size = 25bytes,我们先通过ClassFuncTion: (25+7) / 8 = 4(idx)
再根据这个index=4,get_class_to_size(index-1): 最终得到size = 32;
ThreadCache中的TLS
为什么在ThreadCache中获取小对象是无锁的?这是如何实现的?
这依赖于两种技术: Thread-Local-Storage(TLS) 和 Thread-Specific-Data(TSD)。这两者的功效都是一样的,都是为线程提供存储,只有本线程能够访问。
🎃 TLS使用起来更加地轻便,数据读取更快,但在线程销毁时TLS无法执行清理操作。尽管一些编译器和连接器是支持TLS的,但并不表示某些操作系统是支持的:
🎃 反观TSD则可以,TCMalloc中使用TSD为每一个线程提供一个ThreadCache。不过,如果你设置了TLS可用,那么则同时使用TLS保存一份拷贝,以加速数据访问~
实现方式:
🎃 TLS: 通过__thread关键字定义一个静态变量
🎃 TSD: 通过pthread_key_create,pthread_setspecific,pthread_getspecific来实现
// 定义初始化TSD
static ATTRIBUTE_HIDDEN bool tsd_inited_;
static pthread_key_t heap_key_;
void ThreadCache::InitTSD() {
ASSERT(!tsd_inited_);
perftools_pthread_key_create(&heap_key_, DestroyThreadCache);
tsd_inited_ = true;
// ...
}
// 如果声明了TLS
#ifdef HAVE_TLS
struct ThreadLocalData {
ThreadCache* fast_path_heap;
ThreadCache* heap;
bool use_emergency_malloc;
};
static __thread ThreadLocalData threadlocal_data_
CACHELINE_ALIGNED ATTR_INITIAL_EXEC;
#endif
慢启动算法对Freelist的控制
控制ThreadCache中各个FreeList中元素的数量是很重要的:
如果太少,一旦申请都会去找 "CentralCache",压根发挥不出ThreadCache无锁获取小对象的优势.
如果太大,太多对象在空闲链表之中,反而是一种资源闲置造成的浪费.
不仅是内存分配,对于内存释放来说控制FreeList的长度也很重要:
太少: 将小对象归还 "centralcache"太频繁,访问是需要锁竞争的~
太多: 资源闲置,而导致无法将空闲的小对象规划进行合并出更大内存空间~
类似TCP中的拥塞控制,TCMalloc采用了慢启动(slow start)的方式来控制FreeList的长度:
如果该_free_list使用得越频繁,其上限长度应该提升.
如果_free_list更多的用于释放而不是分配,则其最大长度将仅会增长到某一个点,以有效的将整个空闲对象链表一次性移动到CentralCache中
分配内存时的慢启动代码:
if (list->max_length() < batch_size) {
list->set_max_length(list->max_length() + 1);
} else {
// Don't let the list get too long. In 32 bit builds, the length
// is represented by a 16 bit int, so we need to watch out for
// integer overflow.
int new_length = min<int>(list->max_length() + batch_size,
kMaxDynamicFreeListLength);
// The list's max_length must always be a multiple of batch_size,
// and kMaxDynamicFreeListLength is not necessarily a multiple
// of batch_size.
new_length -= new_length % batch_size;
ASSERT(new_length % batch_size == 0);
list->set_max_length(new_length);
}🏉 max_length即为FreeList的最大长度,初始值为1.
🏉 batch_size是size class一节提到的一次性移动空闲对象的数量,其值因size class而异.
只要max_length没有超过batch_size,每当FreeList中没有元素需要从CentralCache获取空闲对象时max_length就加1.
一旦max_length达到batch_size,接下来每次FetchFromCentralCache就会导致max_length增加batch_size.
但并不会无限制的增加,最大到kMaxDynamicFreeListLength,以避免不会因为释放而长时间占用"centralCache"锁.
再来看内存回收时的情况:
inline ATTRIBUTE_ALWAYS_INLINE void ThreadCache::Deallocate(void* ptr, uint32 cl) {
if (PREDICT_FALSE(length > list->max_length())) {
ListTooLong(list, cl);
return;
}
}如果超长,则执行以下逻辑:
void ThreadCache::ListTooLong(FreeList* list, uint32 cl) {
size_ += list->object_size();
const int batch_size = Static::sizemap()->num_objects_to_move(cl);
ReleaseToCentralCache(list, cl, batch_size);
//. .. 将小对象内存块扔给 "CentralCache"
}ThreadCache申请内存块流程:
🍦 分配小对象:
(1) 根据索要size的大小,得到从size-class哪里取内存块的index.
inline ATTRIBUTE_ALWAYS_INLINE void* ThreadCache::Allocate(
size_t size, uint32 cl, void *(*oom_handler)(size_t size)) {
FreeList* list = &list_[cl];
// ....
}(2) 在线程本地的cache中,通过index访问size-class,寻找可用内存块.
如果当前size-class的 freelist不为空,就将单链表中的头节点弹出并返回它. 这个过程是完全在无锁的状态下进行的。这有助于显著加快分配速度.
// 这个内敛函数是用来 取一块内存中的 首地址(信息)
inline void *SLL_Next(void *t) {
return *(reinterpret_cast<void**>(t));
}
inline bool SLL_TryPop(void **list, void **rv) {
// 首地址
void *result = *list;
if (!result) { // 判空
return false;
}
void *next = SLL_Next(*list);
// list就是_free_list的头节点 这里的操作是头删pop
*list = next;
// 获取内存
*rv = result;
return true;
}
uint32_t length_; // Current length.
uint32_t lowater_; // Low water mark for list length.
bool TryPop(void **rv)
{
// rv输出输入型参数 为了获取内存块首地址
if (SLL_TryPop(&list_, rv)) {
length_--;
if (PREDICT_FALSE(length_ < lowater_)) lowater_ = length_;
return true;
}
return false;
}
inline ATTRIBUTE_ALWAYS_INLINE void* ThreadCache::Allocate(
size_t size, uint32 cl, void *(*oom_handler)(size_t size)) {
// ...
void* rv;
if (!list->TryPop(&rv)) {
// ...
}
// ...
}
(3) size-class.empty() 或者 没有空闲的内存块?
如果size-class是空的:
1. 需要去寻找 CetralCache 获取一堆内存对象.
2. 将这些对象push进当前为空的size-class中.
3. 再返回头上新获取一个内存对象给上级.
// Allocate
if (!list->TryPop(&rv)) {
return FetchFromCentralCache(cl, size, oom_handler);
}
// threadCache.cc
void* ThreadCache::FetchFromCentralCache(uint32 cl, int32_t byte_size,
void *(*oom_handler)(size_t size))
{
// 这里略过 等CentralCache
}ThreadCache垃圾回收流程:
🏆 当ThreadCache中所有的对象超过2MB时,就会触发GC操作 (ThreadCache::Scavenge()),将其中小部分对象归还给CentralList。触发这个机制条件难度,会随着线程的增加而降低.
🏆 我们遍历ThreadCache中的_free_list并将其中一些适合的内存块,归还给CentralCache层.
🏆 使用 "低水位标志lowater_"来衡量到底要归还多少给CentralCache
这里我们并非是将所有的_free_list下所挂的内存块返还,而是根据以上次的垃圾回收线为标准,也许是 L / 2的长度。 这么做有一个好处是,如果当前的线程不用这个特定的obj了,那么将其返还给CentralCache,其他线程可以从CentralCache 获得并使用批内存块~
🍦 归还小对象
(1) 根据归还的小对象size,找到其对应归还到哪个 _free_list之中,并进行插入
uint32_t Push(void* ptr)
{
uint32_t length = length_ + 1;
// 进行头插
SLL_Push(&list_, ptr);
length_ = length;
return length;
}
inline ATTRIBUTE_ALWAYS_INLINE void ThreadCache::Deallocate(void* ptr, uint32 cl) {
ASSERT(list_[cl].max_length() > 0);
FreeList* list = &list_[cl];
ASSERT(ptr != list->Next());
uint32_t length = list->Push(ptr);
// ...
}(2) 当ThreadCache中_free_list悬挂的节点个数过多,或者是某一个object对象大小超过了(max_size) 则会触发 Scavenge()。为什么需要归还??主要是为了解决 内存碎片(外碎片)问题,或者是将收回来的内存块 合并成更大的Span供应内存需求..
inline ATTRIBUTE_ALWAYS_INLINE void ThreadCache::Deallocate(void* ptr, uint32 cl)
{
// ...
if (PREDICT_FALSE(length > list->max_length())) {
ListTooLong(list, cl);
return;
}
if (PREDICT_FALSE(size_ > max_size_)){
Scavenge();
}
}
void ThreadCache::ListTooLong(FreeList* list, uint32 cl) {
size_ += list->object_size();
const int batch_size = Static::sizemap()->num_objects_to_move(cl);
ReleaseToCentralCache(list, cl, batch_size);
// ... 这后面是更新 _length链表长度 我们并不关心
}CentralCache:
ThreadCache为什么能够那么悠哉游哉地使用着 “无尽的,被切好的“内存块?!我们一定不能忘记CentralCache在其中的作用 —— 所有线程的一个公用缓存~
CentralCache是逻辑上的概念,所以在TCMalloc中并没有为CentralCache独立地实现出类似于 "ThreadCache"、"PageHeap"那样的类对象出来~
🐟 与ThreadCache类似,CentralCache中也有也必须有Size-Class的概念,并且一定拥有一个单独_free_list 控制被切块好的内存.
是的!感谢复用,CentralCache 与 ThreadCache的映射规则完全一样,两者借用SizeMap完成映射
🐟 因为CentralCacahe都能被进程内的所有线程访问,所以它是一个”共享资源“ —— 即它本质就应该是"临界资源",需要互斥地(加锁)访问.
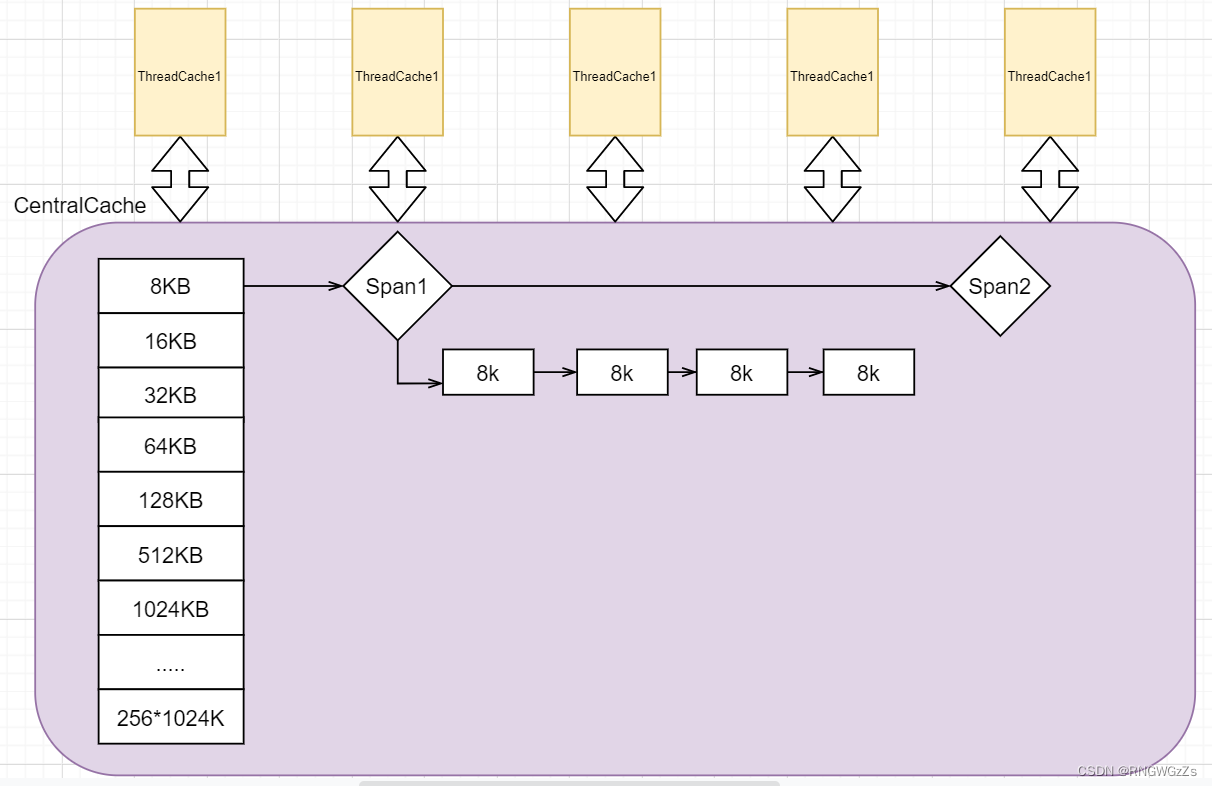
中对象分配:
超过256KB但不超过1MB的内存属于中对象内存,采取了与小对象不同的分配策略~
👑 首先,TCMalloc会将所申请内存大小 按照Page页对齐向PageHeap申请一个指定page数量的span并返回其起始地址:
const size_t npages = Static::sizemap()->class_to_pages(size_class_);
Span* span = Static::pageheap()->NewWithSizeClass(npages, size_class_);Span 与 CentralCache
Span是TCMalloc内存管理极为重要的核心部件:,我们先来简单看看其内部重要的成员变量或函数:
// Information kept for a span (a contiguous run of pages).
struct Span {
PageID start; // Starting page number
Length length; // Number of pages in span
Span* next; // Used when in link list
Span* prev; // Used when in link list
union {
void* objects; // Linked list of free objects
// ...
};
// ...
// What freelist the span is on: IN_USE if on none, or normal or returned
enum { IN_USE, ON_NORMAL_FREELIST, ON_RETURNED_FREELIST };
};Span的三种状态:
💎 IN_USE:
这个比较好理解,就是指的是这个Span正在被是使用。这个状态要么是该Span已经被分配给CentralCache 或者 ThreadCache 或者应用程序。不管是被谁使用,站在PageHeap角度来看,一旦Span被创建,就是处于被使用的状态~
💎 ON_NORMAL_FREELIST || ON_RETURNED_FREELIST:
这两者都可以被认为是空闲状态,区别在于 “ON_RETURNED_FREELIST” 指的是该Span已经被PageHeap归还给OS了,即进行了free\delete.
注: 所谓的free\delete不是真的释放了,只是将物理内存地址与这个虚拟内存地址“去关联”。其虚拟地址仍然是可以访问的~
CentralCache && Span 大致结构图示:

CentralCache 与 ThreadCache的交互
申请:
当"ThreadCache"中_free_list上没有空闲的内存块时,就会向 "central data structures"获取Object(即Span)以供需求 ....
(1) 根据size-class 直接使用在ThreadCache中得到的映射值cl,找到要从CentralCache哪个_free_list的哪个Span拿:
void* ThreadCache::FetchFromCentralCache(uint32 cl, int32_t byte_size,
void *(*oom_handler)(size_t size))
{
// 这里的FreeList 其实访问到了 ThreadCache中
FreeList* list = &list_[cl];
// ..
}(2) 到底向CentralCache要多少个内存块呢? 这里给定了一系列的函数和参数来控制:
const int batch_size = Static::sizemap()->num_objects_to_move(cl);
const int num_to_move = min<int>(list->max_length(), batch_size);(3) 确定需要多少块了,我们开始真正从 Span中获取:
struct TCEntry {
void *head; // Head of chain of objects.
void *tail; // Tail of chain of objects.
};
// 注意这里一定是需要加锁的!! 因为CentralCache是共享资源
int CentralFreeList::RemoveRange(void **start, void **end, int N)
{
ASSERT(N > 0);
lock_.Lock();
if (N == Static::sizemap()->num_objects_to_move(size_class_) &&
used_slots_ > 0) {
int slot = --used_slots_;
ASSERT(slot >= 0);
TCEntry *entry = &tc_slots_[slot];
*start = entry->head;
*end = entry->tail;
lock_.Unlock();
return N;
}
// 输入输出型参数
void *start, *end;
int fetch_count = Static::central_cache()[cl].RemoveRange(&start, &end, num_to_move);这个TCEntry是存在于 ThreadCache 和 CentralCache之间的优化措施。它通过定义了首位两个指针,表示一段 个数为 batch_size的小对象,当我们要操作这批小对象时,仅仅使用这两个指针即可~
(4) 我们实际想要x块,但访问的Span真的有x块吗?
// start成为该list的新头
inline void SLL_PushRange(void **head, void *start, void *end) {
if (!start) return;
SLL_SetNext(end, *head);
*head = start;
}
void PushRange(int N, void *start, void *end) {
SLL_PushRange(&list_, start, end);
// _free_list的长度
length_ += N;
}
{
// 压根获取不到任何的内存块了! 这是下一步 --> PageHeap
if (fetch_count == 0) {
ASSERT(start == NULL);
return oom_handler(byte_size);
}
// Span中的内存块很多 我用多少 算多少
if (--fetch_count >= 0) {
// 这次切分 总共获取的总字节数
size_ += byte_size * fetch_count;
// 切分好了
list->PushRange(fetch_count, SLL_Next(start), end);
}
}归还:
同样,“Thread-local cache” 也需要周期性地进行垃圾(返还内存块)回收、清理,并在收集到一定数量后从"Thread-local cache",归还至 "central data structures"中 ...
(1) 我们将目光转会到 "list_too_long":
void ThreadCache::ListTooLong(FreeList* list, uint32 cl) {
size_ += list->object_size();
const int batch_size = Static::sizemap()->num_objects_to_move(cl);
// 真正意义上地 归还 归还多少呢? batch_size
ReleaseToCentralCache(list, cl, batch_size);
//....
}(2) 在归还给CentralCache之前,做一些初始化:
void ThreadCache::ReleaseToCentralCache(FreeList* src, uint32 cl, int N) {
// src指向_free_list的head
ASSERT(src == &list_[cl]);
if (N > src->length()) N = src->length();
// 这里根据cl 获取对齐地址
size_t delta_bytes = N * Static::sizemap()->ByteSizeForClass(cl);
// 将正确大小的与包装链 打回
int batch_size = Static::sizemap()->num_objects_to_move(cl);
//..
}(3) 从ThreadCache中的_free_list取出 这份批量小对象:
{
// 这里我们只关心 ThreadCache <-> CentralCache
int batch_size = Static::sizemap()->num_objects_to_move(cl);
// 将一部分 N - batch_size 调用InsertRange --> 这里实质真正向pageHeap进行归还
while (N > batch_size) {
void *tail, *head;
src->PopRange(batch_size, &head, &tail);
Static::central_cache()[cl].InsertRange(head, tail, batch_size);
N -= batch_size;
}
// 剩余N == batch_size 调用InsertRange ---> 这里实质是向CentralCache释放
void *tail, *head;
src->PopRange(N, &head, &tail);
Static::central_cache()[cl].InsertRange(head, tail, N);
size_ -= delta_bytes;
}CentralCache 与 PageHeap的交互
申请:
如果连咱们的CetralCache.empty() ?
void* ThreadCache::FetchFromCentralCache(uint32 cl, int32_t byte_size,
void *(*oom_handler)(size_t size))
{
// ...
void *start, *end;
int fetch_count = Static::central_cache()[cl].RemoveRange(
&start, &end, num_to_move);
// ...
}
int CentralFreeList::RemoveRange(void **start, void **end, int N)
{
// 正常pop
lock_.Lock();
// 找到对应的 size-class映射
if (N == Static::sizemap()->num_objects_to_move(size_class_) && used_slots_ > 0) {
int slot = --used_slots_;
ASSERT(slot >= 0);
// 通过TCEntry这个调优类 可以直接通过首尾指针操作 这批内存
TCEntry *entry = &tc_slots_[slot];
*start = entry->head;
*end = entry->tail;
lock_.Unlock();
return N;
}
// 不满足条件了 需要找PageHeap
int result = 0;
*start = NULL;
*end = NULL;
// TODO: Prefetch multiple TCEntries?
result = FetchFromOneSpansSafe(N, start, end);
// ...
}1. 我们从Pageheap分配一系列页面.
void CentralFreeList::Populate() {
// 这里的解锁针对的是谁?? 当然是CentralCache~ 因为你在向其申请内存块时
// 已经加了锁,当你要访问 最后一层PageHeap了 没理由继续占用锁
lock_.Unlock();
// 计算出 size-class 能得到多少的页数 --> 到PageHeap后的单位变为了Page
const size_t npages = Static::sizemap()->class_to_pages(size_class_);
// ... 在PageHeap处会再来回看细节
// 这里指向span中的 _free_list 准备链接
void** tail = &span->objects;
// 记录起始地址start
char* ptr = reinterpret_cast<char*>(span->start << kPageShift);
// end地址
char* limit = ptr + (npages << kPageShift);
// 到底按照什么大小切分呢? 计算出这个size
const size_t size = Static::sizemap()->ByteSizeForClass(size_class_);
for(;;){
// ...
*tail = ptr;
tail = reinterpret_cast<void**>(ptr);
num++;
ptr = nextptr;
}
// ...
// 访问到了最后一个内存块 置空
*tail = NULL;
span->refcount = 0; // 记录这个Span目前还没有给出任何小内存块
// 此时要进入CentralCache 加锁
lock_.Lock();
// ...
}
int CentralFreeList::FetchFromOneSpansSafe(int N, void **start, void **end) {
int result = FetchFromOneSpans(N, start, end);
if (!result) {
// 如果申请不到空闲的Span 就会使用populate()从PageHeap中申请 Span
// 并再次调用 FetchFromOneSpans 将该Span进行小对象切分
Populate();
result = FetchFromOneSpans(N, start, end);
}
return result;
}// 专门维护了这么一段空闲的Span
Span nonempty_; // Dummy header for list of non-empty spans
int CentralFreeList::FetchFromOneSpans(int N, void **start, void **end) {
if (tcmalloc::DLL_IsEmpty(&nonempty_)) return 0;
Span* span = nonempty_.next;
ASSERT(span->objects != NULL);
// ..
}2. 将新申请的Page切等分为size-class大小.
span->objects; // 链接了 空闲对象块
{
// ...
int result = 0;
void *prev, *curr;
curr = span->objects;
do {
// prev标记着 真实切块位置
// *(reinterpret_cast<void**>(prev) == cur
// 当条件不满足时 prev一定指向的是 最后的内存块
prev = curr;
curr = *(reinterpret_cast<void**>(curr));
} while (++result < N && curr != NULL); // 迭代条件: 获得块数不超过N && 该_free_list不为空
if (curr == NULL) {
// 如果该span为空了
tcmalloc::DLL_Remove(span);
tcmalloc::DLL_Prepend(&empty_, span);
}
// 指派给咱们的输入输出型参数
*start = span->objects;
*end = prev;
// end头上 sizeof(pointer) 的空间仍然保存着下一个地址块的信息 注意需要置空
SLL_SetNext(*end, NULL);
}3. 将切分好的Page放回到CetralCache之中.
// 这是用 位端 记录的是 非空闲小对象
unsigned int refcount : 16; // Number of non-free objects
// Number of free objects in cache entry
size_t counter_;
{
// 跳出迭代条件的cur指向新的位置
span->objects = curr;
span->refcount += result;
counter_ -= result;
return result;
}4. 这样之后,我们就可以像之前一样,对这个新的对象进行分配.
{
// reslute
int fetch_count = Static::central_cache()[cl].RemoveRange(
&start, &end, num_to_move);
}释放:
当ThreadCache中_free_list挂的小对象个数too_long,或者 整个缓存中的小对象内存块大小超过了其承受限制 ≥ kMaxSize(256*1024 ) 就会触发垃圾回收 —— “ReleaseToCentralCache”
inline ATTRIBUTE_ALWAYS_INLINE void ThreadCache::Deallocate(void* ptr, uint32 cl)
{
// ...
if (PREDICT_FALSE(length > list->max_length())) {
ListTooLong(list, cl);
return;
}
// ...
if (PREDICT_FALSE(size_ > max_size_)){
Scavenge();
}
}
void ThreadCache::ListTooLong(FreeList* list, uint32 cl) {
// ...
ReleaseToCentralCache(list, cl, batch_size);
// ...
}
void ThreadCache::Scavenge() {
// ....
ReleaseToCentralCache(list, cl, drop);
}(1) 我们将目光拉回到 "ThreadCache::ReleaseToCentralCache",此时我们需要向中央缓存归还数据~
void ThreadCache::ReleaseToCentralCache(FreeList* src, uint32 cl, int N)
{
// ...
while (N > batch_size) {
// ...
src->PopRange(batch_size, &head, &tail);
Static::central_cache()[cl].InsertRange(head, tail, batch_size);
}
// ...
src->PopRange(N, &head, &tail);
Static::central_cache()[cl].InsertRange(head, tail, N);
// ...
}(2) 这两批内存块具体是怎样的归还?
void CentralFreeList::InsertRange(void *start, void *end, int N) {
// 不解释自旋锁
SpinLockHolder h(&lock_);
// 也就是当 N == batch_size 时,这部分批量对象交由归还给 CentralCache
if (N == Static::sizemap()->num_objects_to_move(size_class_) &&
MakeCacheSpace()) {
int slot = used_slots_++;
ASSERT(slot >=0);
ASSERT(slot < max_cache_size_);
TCEntry *entry = &tc_slots_[slot];
entry->head = start;
entry->tail = end;
return;
}
// 若 N > batch_size 直接向PageHeap归还
ReleaseListToSpans(start);
}(3) 彻底归还给PageHeap:
// 我们可以看到这个函数是将 这些内存块 一个一个地进行释放
void CentralFreeList::ReleaseListToSpans(void* start) {
while (start) {
void *next = SLL_Next(start);
ReleaseToSpans(start);
start = next;
}
}
void CentralFreeList::ReleaseToSpans(void* object)
{
// 我们通过内存块地址,可以计算出其PageID,这个PageId是一个Span的标识
// 不过这 会在之后细说
const PageID p = reinterpret_cast<uintptr_t>(object) >> kPageShift;
Span* span = Static::pageheap()-> Descriptor(p);
// ...
counter_++;
span->refcount--; // 归还-- 拨给++
// 说明该Span的所有内存块都已经被释放归还了
if (span->refcount == 0) {
counter_ -= ((span->length<<kPageShift) /
Static::sizemap()->ByteSizeForClass(span->sizeclass));
tcmalloc::DLL_Remove(span);
--num_spans_;
// Release central list lock while operating on pageheap
// 这里仍然是细节~ 你进入CentralCache加的锁还没有被释放
lock_.Unlock();
Static::pageheap()->Delete(span);
// 当你从PageHeap返回时 仍然需要加锁
lock_.Lock();
}
else {
// 如果没有全部释放完全,将该object 进行头插链入
*(reinterpret_cast<void**>(object)) = span->objects;
// 成为新的头节点
span->objects = object;
}
}PageHeap
当线程向 "ThreadCache"层申请内存块,却被告知没有空闲内存块可供分配时,“ThreadCache”会告诉该线程,“我这里虽然没有空闲的block了,但是我知道你该去CentralCache那里看看有没有~”
于是乎,该线程跌跌撞撞找到 “CentralCache” 的办公大楼,前台的小妹似乎知道此时面红耳赤的线程要些什么,不过它也告诉 该线程, "咱们这栋大楼的每一个Span都被使用了,你应该去向PageHeap,为你单独造一个Span" ……
是的~ PageHeap才是真正的内存申请层,直接与操作系统的内存管理 打交道。
PageHeap内部根据内存块大小采取了两个不同的策略:
💰 page <= 128
128个page以内的Span,每个大小都会有特定的链表来 维护。
💰 page > 128
超过128Page的Span,存储于一个有序的set。
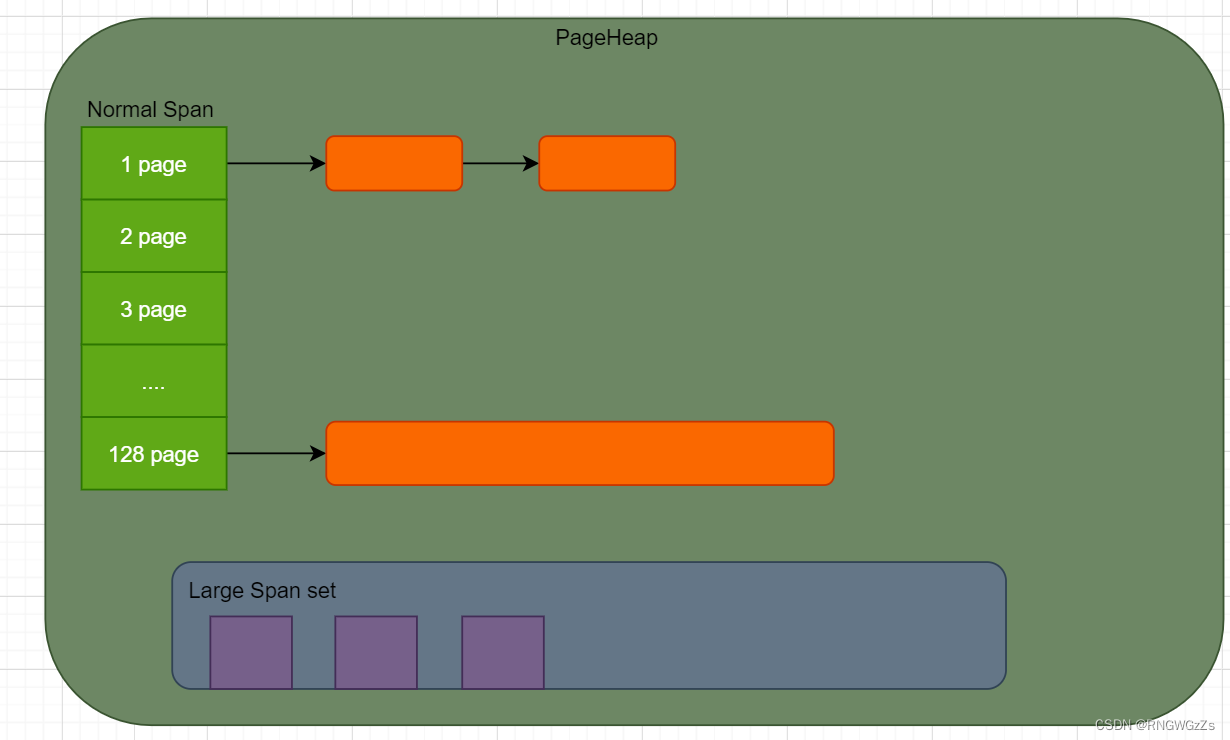
大对象分配对齐
根据每页按照8KB来计算,128Page = 1MB~ 当我们需求超过1MB(128Page)时,就被认为大内存对象分配,此时缓存内存块的不是链表,而是按Span大小排序的set容器。
假设,要分配超过1MB的内存,那么至少需要将字节 向上对齐至 Kpage (Kpage > 128),否则对象的分配策略是按照 “中对象分配”。但,无论是哪种情况,当缓存中没有任何大的Span时,都会向 “set span”中取得一个大小为 k(k>128)的span,分配的策略很简单:
🧬 搜索set中不小于k个的 最小span,假设该span为n(n>k):
将span 拆分成两部分,一部分为k,另一部分为 n -k.
一个大小为k的span直接作为结果返回.
剩下的大小为 n-k的Span,如果n-k > 128 则会继续放入set容器中,反之就会进入PageHeap的缓存链表中.
🧬 如果找不到合适的Span:
直接调用OS底层的动态内存资源申请接口 windows下为 "SystemAlloc" 、 Linux下为 "mmp\brk".
Page 与 PageID
Page作为TCMalloc 内存分配管理模块的基本单位,其默认的大小为8K,不过可以在./configure时,通过选项进行调整: "--with-tcmalloc-pagesize=32 (or 64)"
#if defined(TCMALLOC_PAGE_SIZE_SHIFT)
static const size_t kPageShift = TCMALLOC_PAGE_SIZE_SHIFT;
#else
static const size_t kPageShift = 13;
#endif
static const size_t kPageSize = 1 << kPageShift;PageID是TCMalloc管理Span中内存块的标识,我们可通过PageID找到对应Span,同样也可以找到其内存块起始地址~
static const size_t kPageShift = 13; // page大小:1 << 13 = 8KB
const PageID p = reinterpret_cast<uintptr_t>(ptr) >> kPageShift;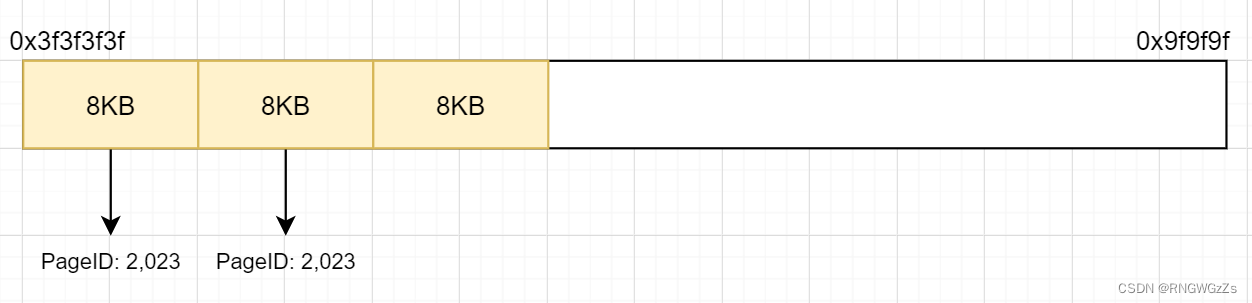
由此,(void*)start / page_size == PageId、PageId * page_size = (void*)start.
Span 与 Page
一个Span是由多个连续的Page组成,TCMalloc按照Span来申请内存空间,也按照Span来管理这些大的内存块~

🔮 一个Span记录了起始page的PageID ,以及所包含page的数量.
🔮 一个Span中的Page内存块,可以被拆分成多个相同的 size-class 用于小对象分配.
🔮 Span中还存在前驱后后继指针,用于管理多个映射至相同size-class的 Span
PageMap:
当我们获取到一个内存块时,用其内存块起始地址(void*) 初始化Span,并填充PageId字段。当我们得到从 “CentralCache” 归还的内存块 (void*)start,我们能够转化得到PageID,它标识着一个Span,然而,到底标识的哪个Span呢?我们是不知道的,难道我们需要拿着这个PageID,去遍历SpanList,找到与这个PageID相符合的Span? 显然,这样的效率十分低下!
我们在初始化时,就要将PageID 与 Span进行“绑定”,这让我们想到了什么? 哈希思想~
🎈 PageMap缓存了PageID 到 Span对应的映射关系.
如果想要简单地实现这个功能,我们完全可以使用 std::unordered_map<PageId,Span*>,不过STL容器为了效率,是不保证线程安全的,所以需要考虑 互斥锁带来的性能损耗~
所以,在TCMalloc中采用的映射算法为 —— 基数树。
基数树: 是一种压缩前缀树,更节省空间,通常使用基数树可用来构建关联数组.
在基数树中,对于每一个节点,如果该节点是确定的子树,就会与父节点合并,利用基数树可以根据一个长整型快速查找到其对应的对象指针。
🎈 32位系统、x86-64、arm64使用两级PageMap
在64位系统中"BITS"的值通常为35。这是因为x86_64架构下的虚拟地址只使用了低48位。PageMap2管理的是Span的地址,而一个Span默认按照8字节对齐,所以低13位地址是不用着了,所以真正需要使用的是后35位(48-13)地址。
这样的设计允许PageMap2有效地利用地址空间,同时减少了不必要的计算和内存开销,从而提高了内存分配的效率。
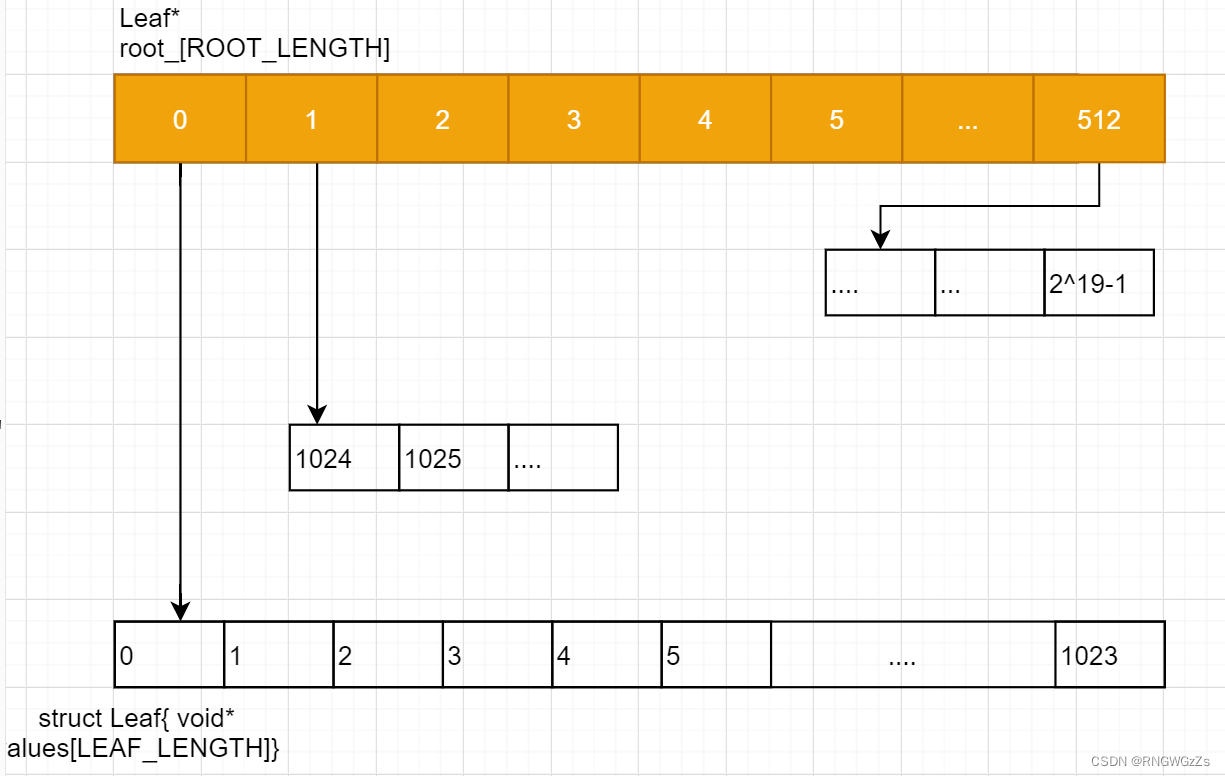
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
// BITS = 32位 - PAEG_SHIFT
template <int BITS>
class TCMalloc_PageMap2 {
static const int LEAF_BITS = (BITS + 1) / 2; // 10
static const int LEAF_LENGTH = 1 << LEAF_BITS; // 1024
static const int ROOT_BITS = BITS - LEAF_BITS; // 9
static const int ROOT_LENGTH = 1 << ROOT_BITS; // 512
Leaf* root_[ROOT_LENGTH];
}
为什么基数树可用?
为什么不用unordered_map?这个在之前说过,MapToSpan()需要加锁,频繁地锁竞争是十分损耗性能的,甚至不如malloc..
为什么基数树可用?
🥌 当我们插入PageID与Span的映射时,不会改变其数据结构,因为在TCMalloc启动前,就已经构架好了.
🥌 只有两个函数FetchNewSpan和ReleaseSpanToPageCache会使用_pageMap建立映射此时PageHeap外已经有一把大锁了,其次,多个线程不可能对同一个位置进行写.
🥌 读写是分离的,不可能读的时候在写.
PageHeap 与 CentralCache的交互
Span创建:
我们回到源码中,查看当CentralCache终归的缓存,满足不了N时,会做些啥:
int CentralFreeList::RemoveRange(void **start, void **end, int N)
{
if (N == Static::sizemap()->num_objects_to_move(size_class_) && used_slots_ > 0)
{
//..
}
int result = 0;
*start = NULL;
*end = NULL;
// 安全获取一个新的Spa
result = FetchFromOneSpansSafe(N, start, end);
// ...
}(1) 根据size_class_ 计算出需要多少内存页:
// Fetch memory from the system and add to the central cache freelist.
void CentralFreeList::Populate() {
// 解锁 CentralCache
lock_.Unlock();
// 获取对齐后npages
const size_t npages = Static::sizemap()->class_to_pages(size_class_);
// 向pageHeap申请
Span* span = Static::pageheap()->NewWithSizeClass(npages, size_class_);(2) 获取一个新的Span:
Span* New(Length n) {
return NewWithSizeClass(n, 0);
}
Span* NewWithSizeClass(Length n, uint32 sizeclass)
{
// ...
LockingContext context{this, &lock_};
Span* span = NewLocked(n, &context);
return span;
}先去预装大Span容器查找想要的Span:
Span* PageHeap::NewLocked(Length n, LockingContext* context)
{
n = RoundUpSize(n);
Span* result = SearchFreeAndLargeLists(n);
if (result != NULL)
return result;
// ...
}"Span* PageHeap::SearchFreeAndLargeLists(Length n) {}"
搜索空闲Span,按照以下顺序,找出第一个不小于k的span:
🏀 从大小为k的span的链表开始依次搜索
🏀 对于某个大小的span,先搜normal链表,再搜returned链表
// Find first size >= n that has a non-empty list for (Length s = n; s <= kMaxPages; s++) { Span* ll = &free_[s - 1].normal; if (!DLL_IsEmpty(ll)){ // 这个不为空 直接就可以进行返回~ return Carve(ll->next, n); // Carve包含了切分和将剩余部分重新放回PageHeap } // 找returned表 ll = &free_[s - 1].returned; if (!DLL_IsEmpty(ll)) { ASSERT(ll->next->location == Span::ON_NORMAL_FREELIST); return Carve(ll->next, n); } }没有搜索到,我们就会去存储大Span的Set:
// No luck in free lists, our last chance is in a larger class. return AllocLarge(n); // May be NULL🏀 这里的搜索,采用的是迭代器,遍历容器中的Span
🏀 同样先搜normal 再 returned
🏀 优先使用长度最小,起始地址最小的Span
// First search the NORMAL spans.. SpanSet::iterator place = large_normal_.upper_bound(SpanPtrWithLength(&bound)); if (place != large_normal_.end()) { best = place->span; best_normal = best; ASSERT(best->location == Span::ON_NORMAL_FREELIST); } // Try to find better fit from RETURNED spans. place = large_returned_.upper_bound(SpanPtrWithLength(&bound)); if (place != large_returned_.end()) { Span *c = place->span; ASSERT(c->location == Span::ON_RETURNED_FREELIST); if (best_normal == NULL || c->length < best->length || (c->length == best->length && c->start < best->start)) best = place->span; }如果通过以上两步找到了一个大小为m的span,则将其拆成两个span,并将n返回
Span* PageHeap::Carve(Span* span, Length n) { // 记录原始信息 const int old_location = span->location; RemoveFromFreeList(span); // 将该Span移除 span->location = Span::IN_USE; // 该Span正在被使用 const int extra = span->length - n; // 分为 span->length=n span->length = extra if (extra > 0) { Span* leftover = NewSpan(span->start + n, extra); // 构建一个新的Span leftover->location = old_location; // 这个未拆分的span记录原始信息 RecordSpan(leftover); // 建立映射: < PageID : Span> } // ... return span; }如果仍然是没有找到合适的Span,则只能向操作系统申请:
bool PageHeap::GrowHeap(Length n, LockingContext* context) { // ... void* ptr = NULL; if (EnsureLimit(ask)) { ptr = TCMalloc_SystemAlloc(ask << kPageShift, &actual_size, kPageSize); } // ... }
(3) 得到的新Span,我们将每个page中obj的大小做一个映射,使得CentralCache在内存申请时,更快找到合适的Span
// 这里是该Span中的每一页 都对应映射为 size_class
for (int i = 0; i < npages; i++) {
Static::pageheap()->SetCachedSizeClass(span->start + i, size_class_);
}Span删除:
我们再次将目光移至 "ThreadCache::ReleaseToCentralCache"内,此时它要将" N - batch_size"个内存块 归还给 PageHeap:
void ThreadCache::ReleaseToCentralCache(FreeList* src, uint32 cl, int N)
{
int batch_size = Static::sizemap()->num_objects_to_move(cl);
while (N > batch_size){
Static::central_cache()[cl].InsertRange(head, tail, batch_size);
}
}
void CentralFreeList::InsertRange(void *start, void *end, int N) {
SpinLockHolder h(&lock_);
if (N == Static::sizemap()->num_objects_to_move(size_class_) &&
// ...
}
// 归还Span
ReleaseListToSpans(start);
}我们得到内存块的起始地址,就可以转换计算出PageId,我们根据这个PageID 去PageMap中寻找其对应的Span:
inline ATTRIBUTE_ALWAYS_INLINE Span* GetDescriptor(PageID p) const {
return reinterpret_cast<Span*>(pagemap_.get(p));
}
void CentralFreeList::ReleaseToSpans(void* object) {
// 获取PageID
const PageID p = reinterpret_cast<uintptr_t>(object) >> kPageShift;
// 获取Span
Span* span = Static::pageheap()-> Descriptor(p);
// 真正属于PageHeap的 释放
Static::pageheap()->Delete(span)
}我们将要删除 Span传给pageHeap()->Delete:
void PageHeap::Delete(Span* span) {
SpinLockHolder h(&lock_);
DeleteLocked(span);
}
void PageHeap::DeleteLocked(Span* span) {
ASSERT(lock_.IsHeld());
ASSERT(Check());
ASSERT(span->location == Span::IN_USE);
ASSERT(span->length > 0);
ASSERT(GetDescriptor(span->start) == span);
ASSERT(GetDescriptor(span->start + span->length - 1) == span);
// 获取span长度
const Length n = span->length;
// 将该要归还的Span信息清空~
span->sizeclass = 0;
span->sample = 0;
span->location = Span::ON_NORMAL_FREELIST;
// 将Span进行合并~ 这是很重要的操作
MergeIntoFreeList(span); // Coalesces if possible
IncrementalScavenge(n);
ASSERT(stats_.unmapped_bytes+ stats_.committed_bytes==stats_.system_bytes);
ASSERT(Check());
}删除的操作非常简单,不过大多数Span的删除是为了触发合并span的操作,以及释放内存到系统的操作;
Span合并
合并规则:
只有当Span是连续的才可能合并.
只有相同状态下的Span才能继续合并.

当我们对一个Span进行删除时,我们需要注意到这个函数:
void PageHeap::DeleteLocked(Span* span) {
// ...
const Length n = span->length;
MergeIntoFreeList(span); // Coalesces if possible
// ...
}MergeInfoFreeList既可能将Span释放给OS.
也会通过前后也合并成 管理更大内存空间的Span.

TCMalloc性能图示
我们根据官方文档的测试,可以分析tcmalloc在不同场景下的性能指数:
TCMalloc vs PTMalloc2:
测试环境: 2.4GHz双核至强系统\glibc-2.3.2 from RedHat 9\每个测试中每个线程有一百万次操作
如下的图示分别表现了在不同的线程数量下运行的性能指标:

在绝大多数情况下,TCMalloc比PTMalloc2快,特别是对于小分配。
不过更多的研究数据敬请查阅官方~~
本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~