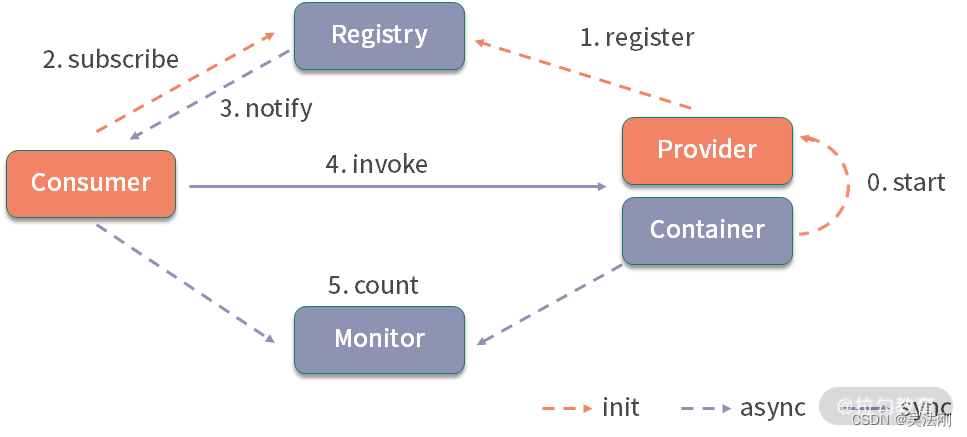
Chapter5:设计数据库之外部模式:数据库的应用
笔记来源:《漫画数据库》—科学出版社
设计数据库的步骤:
概念模式
概念模式(conceptual schema)是指将现实世界模型化的阶段进而,是确定数据库理论结构的阶段。
概念模式的设计是通过E-R模型把握现实世界,进而规范化表格来实现的。
内部模式
内部模式是从计算机内部看到的数据库,是确定数据库物理构造的阶段。
内部模式的设计通过设计数据库高速检索方法来实现。
外部模式
外部模式是从用户和应用的角度来观察的数据库。
外部模式的设计是通过设计应用程序所必要的数据来实现的。
5.1 基础概念
什么是事务?
用户的一个连贯操作我们称之为数据库事务(Transaction)

读取数据作业和加法写入作业统归为一个事务
A进行的操作为一个事务,B进行的操作也是一个事务。

事务的性质

提交
各种事务的操作正确完成时,要确认对数据库
的处理,这个确认处理过程我们称之为“提交”(commit)。

什么是锁?
为了使多个用户同时访问数据库时不会发生问题,自然要控制这些操作。控制的方法我们通常称之为“锁”(LOCK)
A在进行自己的一系列操作前先上锁的话,B即便是想进行操作也要等到A的操作完成之后才能开始。

锁的粒度(加锁的范围)

不过,虽然使用了锁,但由于数据库是多人共享数据,非常频繁上锁是不太好的。通常会根据情况分开使用锁。
共享锁
用户仅进行读取操作时,使用共享锁。
上共享锁期间,其他用户能够读取数据,但是不能写入。
独占锁
用户想要进行写入操作时,就上独占锁。上独占锁时,其他用户既不能读取也不能
写入。

使用锁控制多个事务我们称之为同时执行控制
通过锁来控制操作进程,是为了同时执行多个事务。但是,使用锁来进行同时执行控制,存在管理锁的负担。另外,还有可能出现死锁的现象。
那么,在事务数很少的情况下或读取行为多的情况下,可以使用更为简洁的方法进行同时执行控制。这种方法有以下几种控制方式。
时间戳控制(Timestamp control)
数据库事务给每一个被访问的数据打上了一个“时间戳”的时间印记。
时间戳控制法是指某个事务要读写这个数据时,比这个事务拥有更早时间戳的事务更新了数据的情况下,不允许读写数据的方法。不许读写的情况下,回滚此事务。
乐观控制(Optimistic control)
是一种暂时允许各事务读取的处理方法。从写入点开始,确认是否由其他的事务更新了数据。若其他事务更新了数据,则回滚。
什么是回滚?
A给苹果数据上了独占锁,同时B给草莓数据上了独占锁。
接下来,A想给草莓数据上独占锁,B想要给苹果数据上独占锁。
由于任何一方都要等对方解除锁,处理就进行不下去了,为了解决这个问题,就必须先解除其中一方的锁,即取消某一方的事务。
取消事务我们称之为回滚(rollback)。
事务执行的过程中发生问题不能确认的情况下,不会提交而是进行回滚。

为了使数据库操作中不发生矛盾,数据库事务必须由提交或回滚中的任意一个指令来结束。

隔离级别
在现实的数据库中,同时执行的事务不断增加,因此能够逐渐控制事务之间互相干涉的级别。这叫做隔离级别(isolation level)。

下图来自:事物级别,不可重复读和幻读的区别是什么

脏读(dirty read) 是指事务1在提交前事务2读取该行,在事务1回滚的情况下,事务2读取了不存在的行这种现象。
无论是脏写还是脏读,都是因为一个事务去更新或者查询了另外一个还没提交的事务更新过的数据。但由于另外一个事务还没提交,所以他随时可能会反悔会回滚,那么必然导致你更新(查询)的数据就没了。—引自:五分钟了解Mysql脏读、幻读、不可重复读、mvcc
非重复读(non-repeatable read) 是指事务1读取行时,事务2在更新该行并提交时,事务1再一次读取该行时发生数值不一致的现象。
虚读(phantom) 是指事务1进行检索,获得多行结果,事务2追加了符合该条件的行,事务1第二次检索的结果发生不同的现象。
索引
为什么需要索引?

数据库的规模变得更大,更多的人使用数据库时,检索商品可能会变得很慢,通过设定索引能够很快找到目标内容。使用索引功能的话,可以减少访问硬盘的次数,可以提高访问速度

B树索引

散列索引

索引可能会引发的问题
如果过分生成索引的话反而会降低效率。
数据频繁更新的话,每次都要更改索引,还是会耽误更新速度的。
下图来自:索引设计

最优化查询
在进行查询时,要解析查询内容,按照适当的顺序操作。相同的查询,根据投影、选择、连接等的不同,运行顺序也不同,处理的时间也不同。
一般地按照:
1.先行执行选择减少行数
2.再执行投影减少与结果无关的列
3.最后执行连接
这样的标准确定查询顺序
5.2 数据库安全问题
若所有人均能访问数据库并修改数据,可能会出现数据被恶意篡改

为避免所有人均可对数据库数据进行读取和修改而造成混乱
第一、我们要控制能够访问数据库的人,要访问数据库必须输入用户名和密码,即限制能够使用数据库的用户
第二、对能够访问数据库的用户进行操作权限的设定,即限制用户操作

5.3 数据库的故障恢复
故障种类
事务故障是指因为事务不完备而导致事务不能结束的情况。在事务故障中,发生故障的事务将被回滚。
系统故障是指因为停电等原因造成系统停运的情况。在系统故障中,重新启动后进行故障恢复处理。通常,对故障发生时未提交的事务进行回滚,对故障发生时已提交的事务进行前卷。
介质故障是指硬盘损伤的情况。发生介质故障时,可以基于备份文件进行故障恢复。对备份后提交的事务进行前卷处理。
在数据库中,正在处理数据时会生成一个叫做日志的记录,它记录了用户对数据所进行的变更等操作。最重要的是在更新数据库时,记录了更新前和更新后的值。
系统发生故障时首先要重新启动系统,然后利用日志恢复数据库。
恢复的方法根据事务是否提交而不同。
故障发生时事务已提交的恢复方法:前滚
前滚指的是将数据库系统恢复到某一时刻之后的状态,前滚则是将数据库恢复到之后的状态。—引自:数据库操作必备技能:前滚与回滚详解

故障发生时事务未提交的恢复方法:回滚
回滚是将数据库恢复到某一时刻之前的状态。当一个事务出现错误或者被撤销时,我们需要将数据库回滚到之前的状态。回滚操作会撤销之前的事务操作,将数据库恢复到之前的状态,确保数据的一致性。—引自:数据库操作必备技能:前滚与回滚详解

5.4 数据库的应用
银行储蓄账户管理系统

火车票预订系统

web与数据库
web上输入关键词

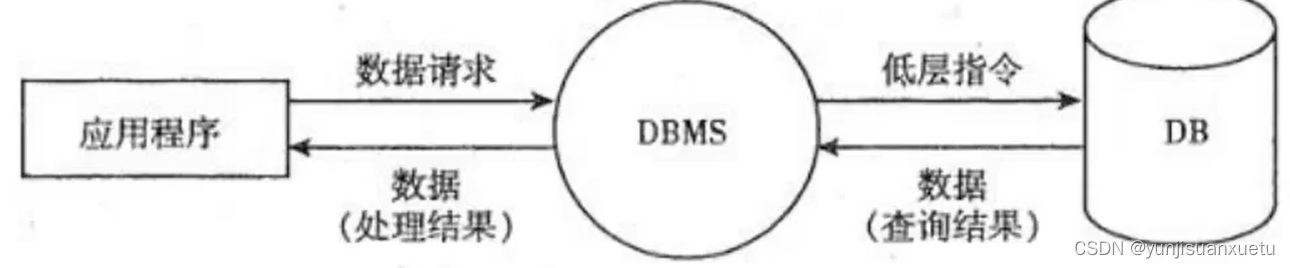
这个搜索关健词将作为HTTP请求被送出,接受请求并进行处理的电脑叫做服务器(sever),在服务器上生成SQL,然后将此SQL命令发送至数据库进行查询

最后数据库将检索结果发回

存储程序和触发器
在这样一个系统中,网络上流动数据的通信量还是个问题。数据库中由于有存储程序等功能,所以能够在数据库服务器中配置预先查询等程序。由于数据库服务器中配置了程序,因此没有必要频繁发送SQL查询命令,存储程序能够减少网络的负荷。
在数据更新的时候存储程序就会自动启动,这就叫做触发器(trigger)。也就是说某人发出订单更新了数据库时,能自动减少库存进行配送处理。

三层客户端服务器系统由表示层、功能层和数据层构成
表示层接受用户的输入、获取对数据库的检索条件等。另外,表示层还会对数据库进
行查询后获得的结果进行显示。通常由Wb浏览器实现表示的功能。
功能层进行数据加工。该层对SQL命令进行整合。这些处理由各种程序语言等记述。
根据处理的内容和负荷,也可由应用服务器、Web服务器等多个服务器分担处理。
数据层由数据库服务器处理。数据库服务器管理数据库。根据SQL等的查询要求,检
索结果从数据库返回。

分布式数据库
由多个服务器来管理数据库,但是必须把它们当做一个整体的数据库来处理。

分布式数据库的构成方式:水平分布、垂直分布
水平分布是指使用多个同级别的数据库服务器的方法,水平分布式数据库中即便一个服务器发生故障,数据库仍能正常工作。对故障有很强的抵御功能。

垂直分布是数据库服务器具有不同功能的分布方式。由承担主要任务的主服务器和承担其他处理任务的服务器构成。
各服务器可以使用主服务器的数据库,但是主服务器不使用其他服务器的数据。
因此,在垂直分布式数据库中,主服务器易于管理的背后是主服务器集中承担通信任务。
这种分布方式多用于数据库由整个组织的主服务器和各部门服务器构成的情况。

分布式数据库的分配方法:水平分配、垂直分配
水平分配是将数据按照行的方向进行分割。分割后的行分别配置给各服务器。
例如,相同类型的数据分地域管理时,就会采用这种方式。

垂直分配是将数据按照列的方向进行分割。分割后的列分别配置给各个服务器。
例如,在希望将商品部、出口部和外国部等独立部门的数据库按照分布式数据库进行管理时多采用这种方式。

分布式数据库中表格的连接
分布式数据库增加了网络间的通信量,从而增大了网络的负荷。特别是在服务器之间连接表格的情况下,必须注意数据的通信量。
分布式数据库连接表格的方法有以下几种:
嵌套循环
将服务器A中表格的某一行发送至服务器B,与服务器B中表格的每一行进行比较之后连接。将服务器A中表格的每一行都按照此程序反复操作

分类合并
分类合并是一种将各服务器表格预先分类的方法。
将服务器A的表格和服务器B的表格各自分类。之后将服务器A的表格发送至服务器B。因为表格事前已经分类,因此能够通过一个方向的读取进行连接。

半连接
半连接是一种仅将与连接相关的列发送至与之连接的服务器,在减少行之后进行连接的方法。
例如,首先将服务器A的商品编码列发送至服务器B。之后抽取服务器B中相应的商品编码。再将抽取的行发送回服务器A,根据这些行进行连接处理。因为减少了行,所以可能减少了网络的通信量。

散列半连接
在散列半连接过程中,先求取服务器A中列的散列值,并发送至服务器B。在服务器B中也求取散列值。通过散列值之间的检查进行连接。

分布式数据库中数据的复制
在分布式数据库中,为了减少网络的负荷,数据库设置了复制的功能,我们称之为复制。
通过重复使用数据的复制,减少了网络中传送的数据。
我们将主要的数据库称为主数据库。复制称为replica,复制的方式有以下几种。
读取专用
是一种生成并下载从主服务器的主数据库中读取专用复制的方法。复制是在主服务器连接时生成的。复制仅可读取。

可更新主服务器
从主服务器生成复制。该复制能够更新。更新复制时被反映在主服务器的主数据库中。

可更新各个服务器
各服务器之间拥有相同主服务器的方法。在各个服务器中更新后,可反映在其他服务器的数据库中。