基于联合概率分布角度的深度学习方法风险浅析
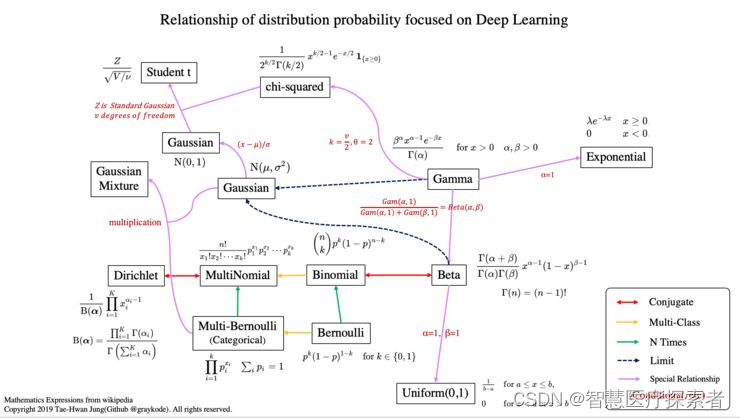
1. 什么是联合概率分布
联合概率分布(Joint Probability Distribution)描述了两个或多个随机变量在同一个试验中的联合概率。
例子:
假设X和Y都服从正态分布,那么P{X<4,Y<0}就是一个联合概率,表示X<4,Y<0两个条件同时成立的概率。表示两个事件共同发生的概率。A与B的联合概率表示为 P(AB) 或者P(A,B),或者P(A∩B)。
2. 联合概率分布如何影响深度学习模型安全性?
2.1 发展历程
深度学习的崛起: 自从华裔科学家李飞飞建立了一个有1500多万张标注好的图片的巨大数据库,全世界搞图像识别的人可以用这个数据库对AI进行训练,然后进行识别。最初这个比赛表现最好的五个团队,平均错误率达到28%,然后逐年下降。作为对比,人类识别的误差率在5%-10%之间。到了2012年 、2013年的时候,GPU技术的发展已经能够支撑深度学习模型的训练。一些深度模型模式崩塌等理论性问题也被解决 就此AI就逐步逼近了人类的水平。这个进步,科学家依赖的是一种叫做深度神经网络的算法。从那以后,所有最好的团队都用深度神经网络,很快就突破了人类界限,错误率直逼3%以下。这一巨大的成功使得图像识别变成了第一项成熟的人工智能应用,人工智能从论文和实验室走到了我们的生产和生活之中。
chatGPT的出现: 2022年11月30日发生了一件事情,OpenAI宣布他们的一个产品诞生,这个产品叫ChatGPT,我们现在把它称为生成式的人工智能。它可以模仿人类生成文本、剧本、图像、视频,以及程序的代码。这是一个重要的进步,我们认为它开创了人工智能发展的新阶段。从技术上看,这个新阶段是由于有巨大参数的大模型同一系列其他技术相结合,实现了对语意的基本掌握。我们知道,所有的人类语言中用了很多词汇,但是同一个词汇在不同的上下文之间,可以表达不同的语意。这个大训练模型利用了很长的文本,使得每一个词的语意得到相对比较准确的表达。从应用上看,chat也是非常重要的。在这之前比较有名的AI有Deep Blue(深蓝),是下国际象棋的。后来出现下围棋的AlphaGo。在中国,下国际象棋的人不多,下围棋的可能多一点,但依然不是所有人都下围棋。现在到了chat,everyone chats,所有人都会聊天,通过聊天把人工智能推向了所有的人。我想这是在应用上一个重大的进步。
大模型的几项核心技术: (1)**Word Embedding **: ChatGPT一系列的技术里面,有几项特别值得一提的技术,其中一项叫 Word Embedding ,翻译成中文叫词嵌入。这是比较难懂的一个词,是把一个词嵌入到一个矢量的空间里面。这里面矢量的维数可以非常多,每一维以0或者1代表一个矢量的性质。比方说第一个维度以0和1代表它是个生物还是非生物;如果是生物,下一维度,这是动物还是植物;如果是动物,下一维度判断这是哺乳动物还是非哺乳动物;如果是哺乳动物,是地上跑的还是天上飞的……在一个高维矢量空间里,把一个词意给它确定下来,这就叫做 Word Embedding。(2)Transformer与attention: GPT的T是Transformer的首字母。Transformer我们翻译成变换器。这个变换器是干什么的?是做编码和解码用的。编码和解码会产生另一个概念,我们叫做 attention,翻译成注意力,它可以在很长的上下文中找到关键词。人看文章的时候,不是在每一个词上都平均用力的,而是迅速抓住关键词,这对AI来说也是一个重要的功能。
2.2 安全性问题的思考
2.2.1 概率导致的问题
它存在风险的一个最根本的原因在于,它在推测答案的时候,用的是概率,叫做联合分布概率。给它输入一个问题,它判断哪些词与输入的词组合形成的概率最高,那就是它选择的输出。既然它是通过概率来判断的,就不可能100%正确,总有出错的时候。人也会出错,只不过我们可以通过长期的实践、根据民主决策的程序、通过专家咨询等,来尽量减少人的错误。而对大模型,现在还存在不可解释性,还不能清晰地说明在什么样的条件下可以影响它的概率分布。也就是数据驱动的智能模型很可能在某一细分领域,由于样本量不足和质量问题,导致其性能出现严重的偏差,这一点是亟待解决的。
2.2.2 现有深度学习模型中的概率分布模型
- 清华大学的Unidiffuser
针对概率建模框架,研究团队提出 UniDiffuser,一个基于扩散模型的概率建模框架。UniDiffuser 能够**显示地建模多模态数据中包括边缘分布、条件分布、联合分布在内的所有分布。**研究团队发现,关于不同分布的扩散模型学习都可以统一成一个视角:首先向两个模态的数据分别加入某种大小的噪声,然后再预测两个模态数据上的噪声。其中两个模态数据上的噪声大小决定了具体的分布。例如,将文本的噪声大小设置为 0,则对应了文生图的条件分布;将文本噪声大小设置为最大值,则对应了无条件图像生成的分布;将图文噪声大小设置为相同,则对应了图文的联合分布。根据该统一的视角,UniDiffuser 只需要将原始扩散模型的训练算法做少许的修改,便能同时学习上述的所有分布 — 如下图所示,UniDiffuser 同时向所有模态加噪而非单个模态,输入所有模态对应的噪声大小,以及预测所有模态上的噪声。 - 迁移学习-联合分布适配(JDA)方法
合分布适配方法(joint distribution adaptation,JDA)解决的也是迁移学习中一类很大的问题:domain adaptation。关于domain adaptation的介绍可以看我之前的介绍。简单概括就是,如何用有标注的源域数据来标定完全无标注的目标域。先来简单普及一下知识:边缘概率、条件概率和联合概率。对于一个随机变量 X X X,是它的元素 x x x,对于每一个元素,都对应一个类别 y ∈ Y y\in Y y∈Y。那么,它的边缘概率为 P ( X ) P(X) P(X), 条件概率为 P ( y ∣ X ) P(y|X) P(y∣X),联合概率为 P ( X ∣ y ) P(X|y) P(X∣y)。JDA方法就是要适配源域和目标域的边缘概率分布和条件概率分布(此处存在歧义,或者是数据的联合概率分布)。