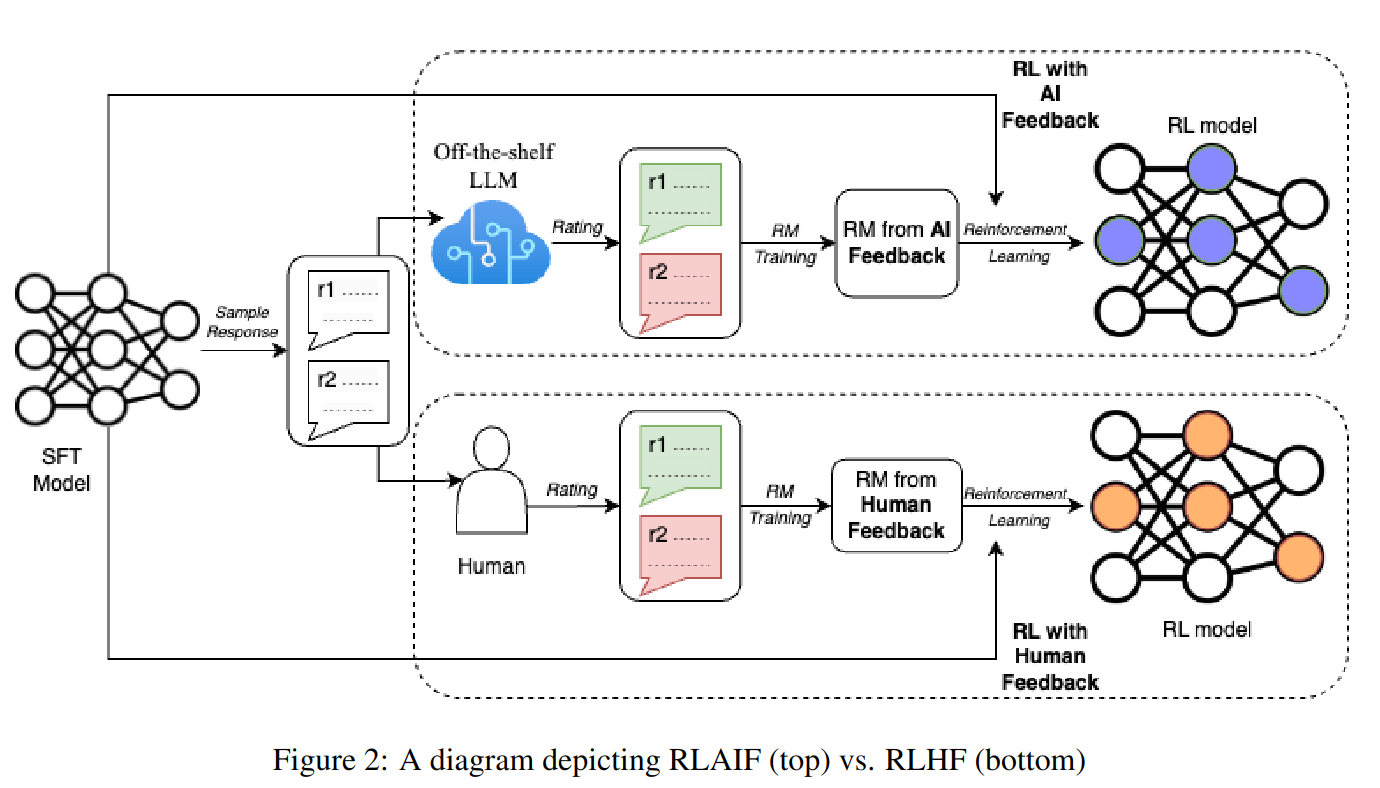
给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1 。
示例 1:
输入: s = "leetcode"
输出: 0
示例 2:
输入: s = "loveleetcode"
输出: 2
示例 3:
输入: s = "aabb"
输出: -1
提示:
1 <= s.length <= 10^5s只包含小写字母
思路
方法1:两次遍历
第一遍先统计每个字符出现的次数,第二遍再次从前往后遍历字符串s中的每个字符,如果某个字符出现一次直接返回,原理比较简单,看下代码
public int firstUniqChar(String s) {
int count[] = new int[26]; //
char[] chars = s.toCharArray();
//先统计每个字符出现的次数
for (int i = 0; i < s.length(); i++)
count[chars[i] - 'a']++;
//然后在遍历字符串s中的字符,如果出现次数是1就直接返回
for (int i = 0; i < s.length(); i++)
if (count[chars[i] - 'a'] == 1)
return i;
return -1;
}
方法2:使用HashMap解决
public int firstUniqChar(String s) {
Map<Character, Integer> map = new HashMap(); //!!!
char[] chars = s.toCharArray();
//先统计每个字符的数量
for (char ch : chars) {
map.put(ch, map.getOrDefault(ch, 0) + 1); //!!!
}
//然后在遍历字符串s中的字符,如果出现次数是1就直接返回,由于是从小开始遍历的,第一个字符的个数为1,就会被返回
for (int i = 0; i < s.length(); i++) {
if (map.get(chars[i]) == 1) {
return i;
}
}
return -1;
}
方法3:使用Java的api
一个从前查找,一个从后查找,如果下标相等,说明只出现了一次
public int firstUniqChar(String s) {
for (int i = 0; i < s.length(); i++)
if (s.indexOf(s.charAt(i)) == s.lastIndexOf(s.charAt(i)))
return i;
return -1;
}



![[力扣]——<span style='color:red;'>387</span>.<span style='color:red;'>字符串</span><span style='color:red;'>中</span><span style='color:red;'>的</span><span style='color:red;'>第一</span><span style='color:red;'>个</span><span style='color:red;'>唯一</span><span style='color:red;'>字符</span>](https://img-blog.csdnimg.cn/direct/9121aa197197402cb95c3cb53b9afab4.png)