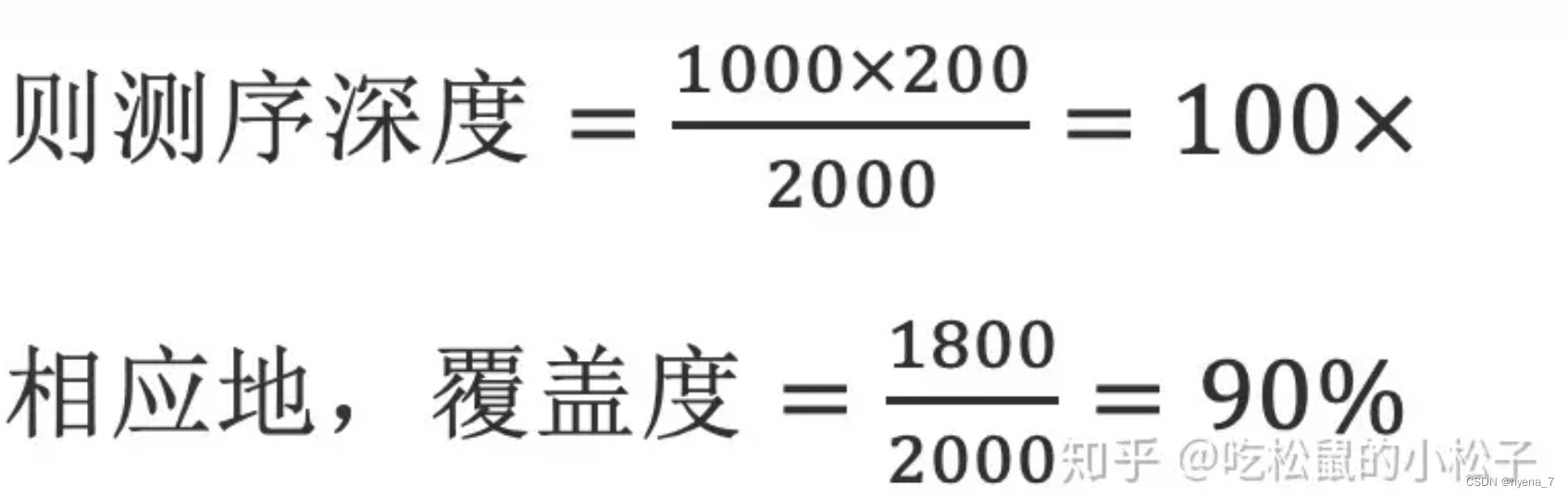我们在得到一组或几组测序数据后,比如从测序公司拿到的测序数据为fastq.gz格式,首先我们需要对它们进行MD5检验,确保数据没有问题后才可进入以后的程序。(MD5可以进行测序数据完整性验证:MD5可以用于验证数据在传输或存储过程中是否发生了变化。发送方可以计算原始数据的MD5值并将其随数据一起发送给接收方,接收方在接收数据后再次计算MD5值,如果两个MD5值一致,则说明数据在传输过程中没有被篡改。)
假如我们得到的是MD5.txt,在正确的目录下输入命令 md5sum -c MD5.txt,#显示FASTq文件一切OK,说明数据没有问题。
接下来我们需要堆测序数据进行质量评估:包括测序读长、碱基质量分布、测序错误率、测序深度等方面的统计和图表展示,帮助研究人员了解测序数据的质量情况。同时识别异常情况:F如过低的碱基质量、过高的测序错误率、测序适配污染等问题,有助于及时发现数据质量异常并采取相应的处理措施。常用的软件经常用的有FastQC等,今天我们就使用fastqc。
现在我们有经过MD5检验的测序数据 a1.fq.gz,a2.fq.gz。
conda activate dna #激活环境。
conda install -c bioconda fastqc -y #安装软件
conda install -c bioconda fmultiqc -y
fastqc -h
fastqc -h
FastQC - A high throughput sequence QC analysis tool
SYNOPSIS
fastqc seqfile1 seqfile2 .. seqfileN
fastqc [-o output dir] [--(no)extract] [-f fastq|bam|sam]
[-c contaminant file] seqfile1 .. seqfileN
DESCRIPTION
FastQC reads a set of sequence files and produces from each one a quality
control report consisting of a number of different modules, each one of
which will help to identify a different potential type of problem in your
data.
If no files to process are specified on the command line then the program
will start as an interactive graphical application. If files are provided
on the command line then the program will run with no user interaction
required. In this mode it is suitable for inclusion into a standardised
analysis pipeline.
The options for the program as as follows:
-h --help Print this help file and exit >>>>>>>
出现这些即可应用。
mkdir fastqc #创建目录。
第一种方法 fastqc a1.fq.gz -o fastqc #需要fastqc目录提前存在。这是一个一个检测。
第二种方法 ls *fq.gz | xargs fastqc -t 10 -o fastqc/ #这个可以同时检测同一目录下的所有fq.gz文件。还有其它方法,这里就不列举了,道理都一样。
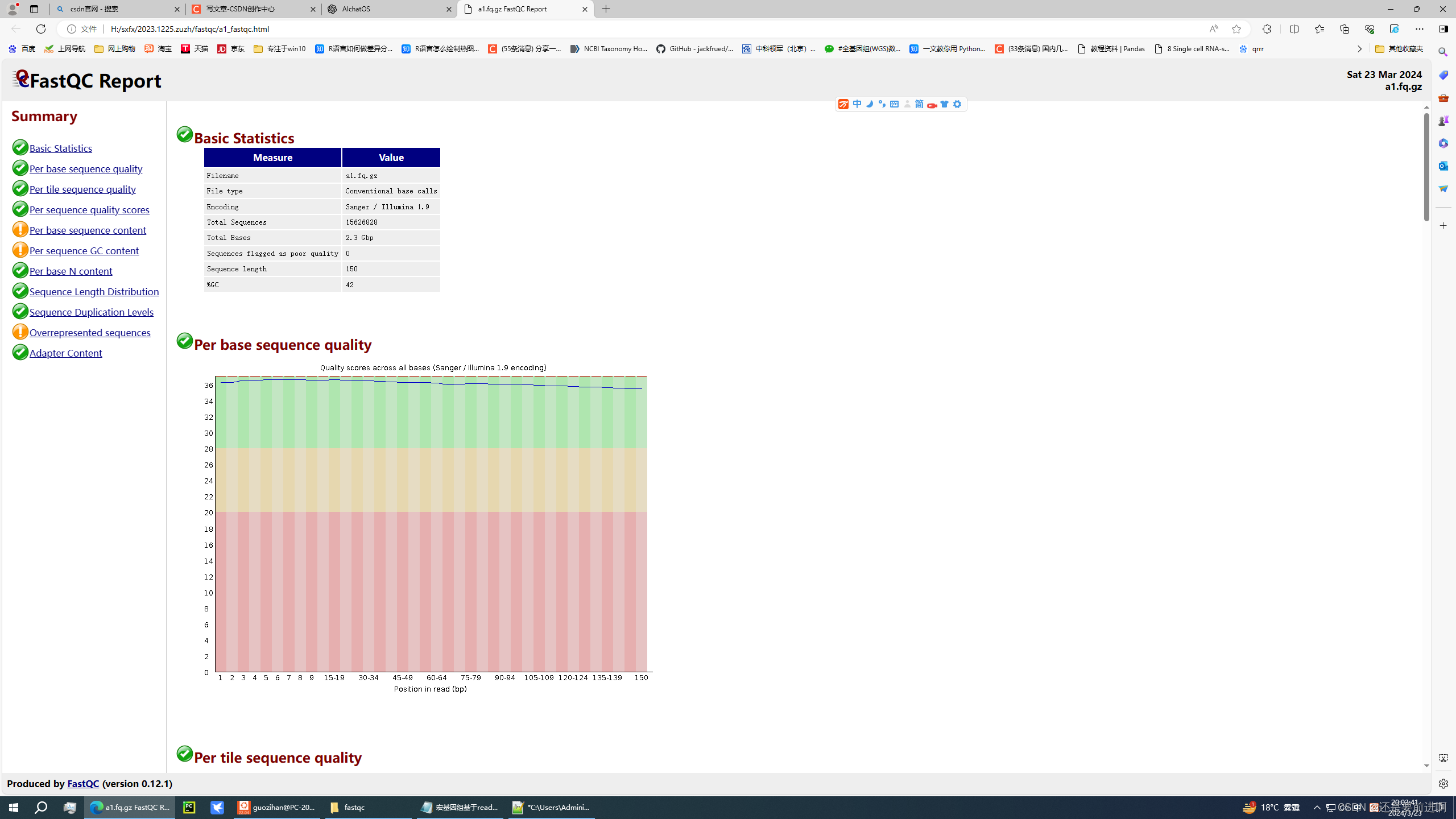
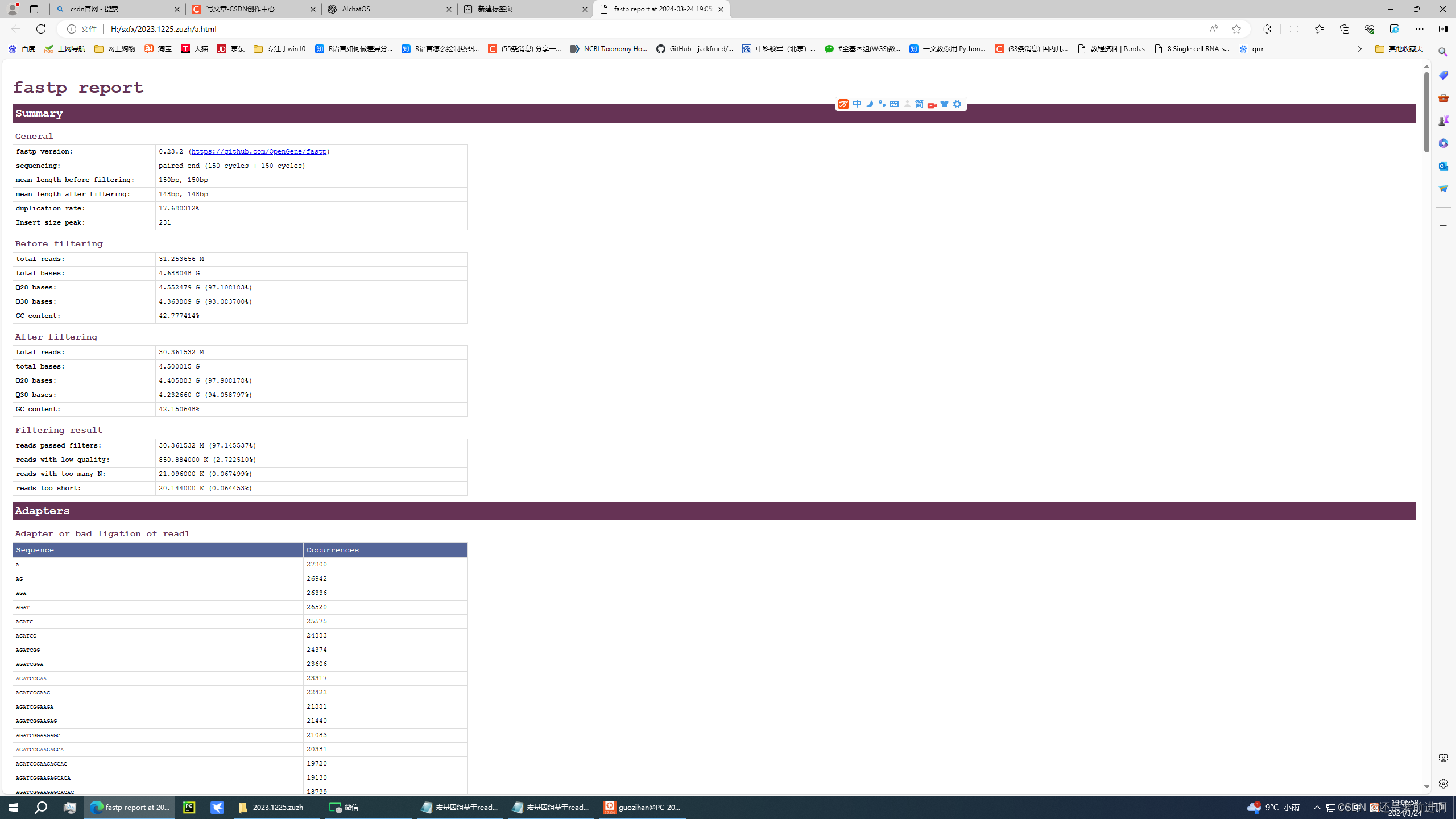
FastQC生成的结果主要包括以下内容:
根据你提供的FastQC报告结果,这些内容的含义如下:
Basic Statistics:基本统计信息。通过这一项可以获得关于测序数据的总序列数、总碱基数、平均序列长度、GC含量等基本统计信息。
Per base sequence quality:每个碱基的质量分布情况。这一项检查每个碱基位置的碱基质量分数,以评估测序数据的质量是否均匀。
Per tile sequence quality:每个(tile)的序列质量。用于评估不同区域的测序质量是否存在变化。
Per sequence quality scores:每个序列的质量分数。这一项分析每个序列的平均质量得分,帮助评估整体序列质量。
Per base sequence content:每个碱基的序列内容分布。警告表示可能存在异常的碱基组成情况。
Per sequence GC content:每个序列的GC含量。警告表示可能存在异常的GC含量情况。
Per base N content:每个碱基的N含量。用于检测测序数据中N的分布情况。
Sequence Length Distribution:序列长度分布情况。用于分析不同长度序列的数量分布情况。
Sequence Duplication Levels:序列重复水平。用于检测测序数据中的序列重复情况,帮助识别PCR重复扩增或其他潜在问题。
Overrepresented sequences:过度表示的序列。用于检测是否有某些序列在数据中过度表示,可能是适配序列或污染序列。
Adapter Content:适配器含量。通过这一项可以检测测序数据中是否包含有适配器序列,需要注意是否需要进行适配器去除的处理。
根据报告中的结果,PASS表示通过检测,而WARNING表示有一些值或特征略微异常,需要进一步关注和处理。,同时也会出现FAIL的结果,表示某一项不及格。
cd fastqc , multiqc ./ #可以对fastqc的结果进行合并。
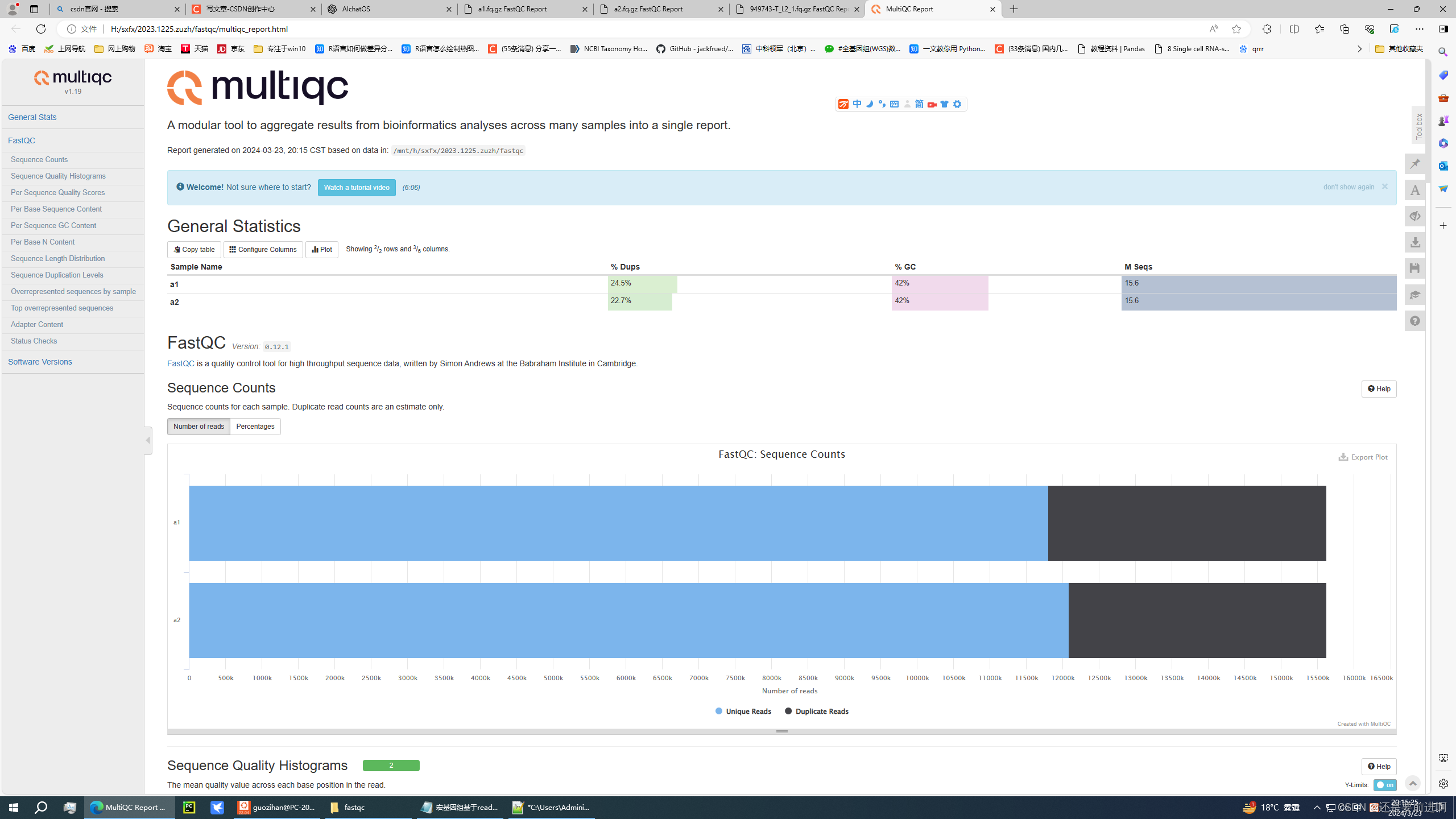
大家可以从Sra网站下载数据跑一下。