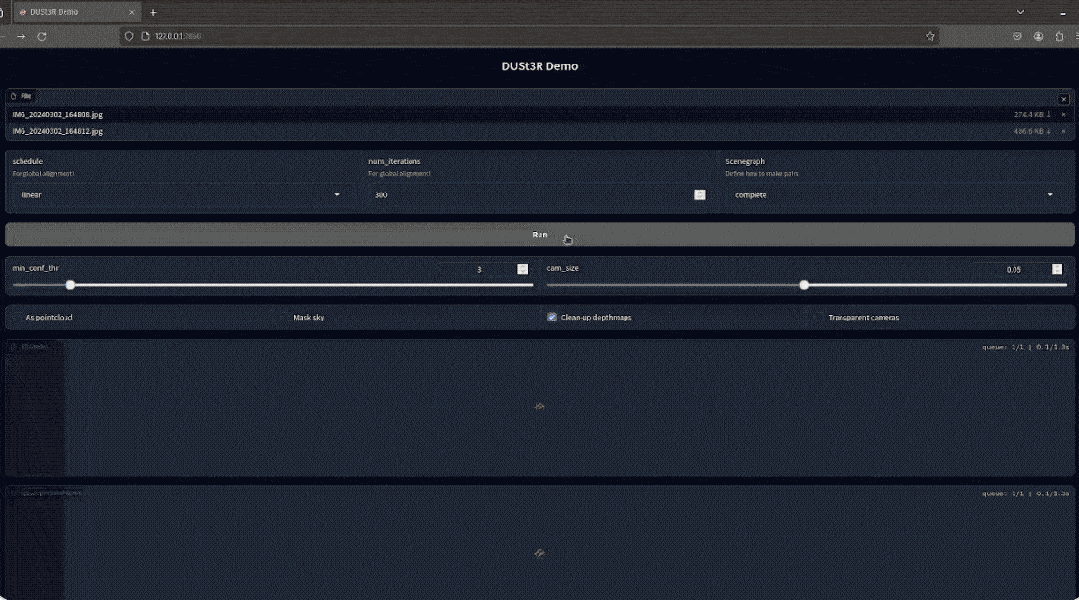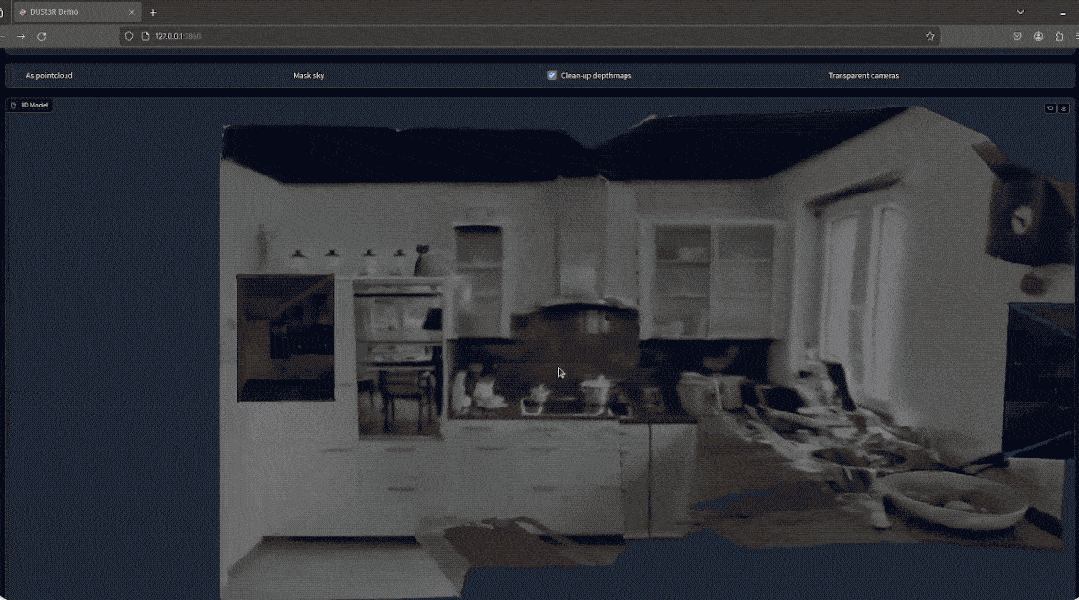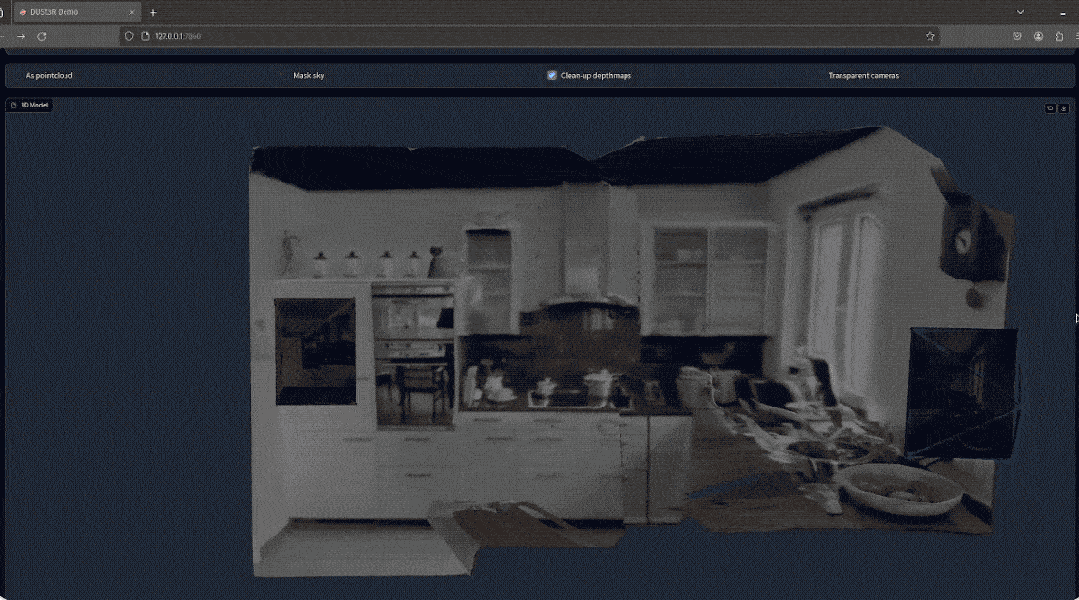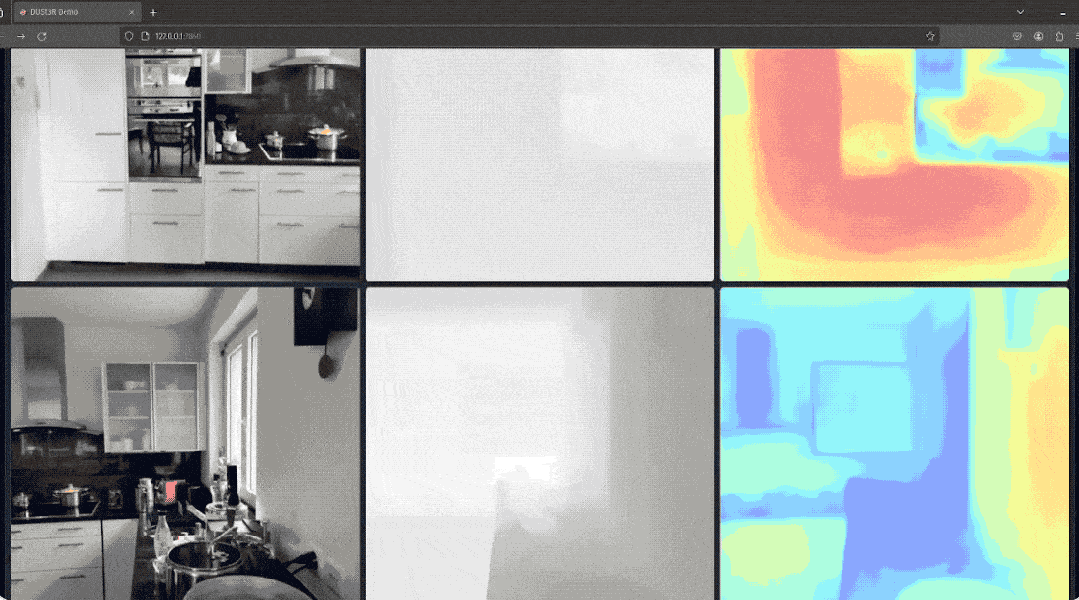
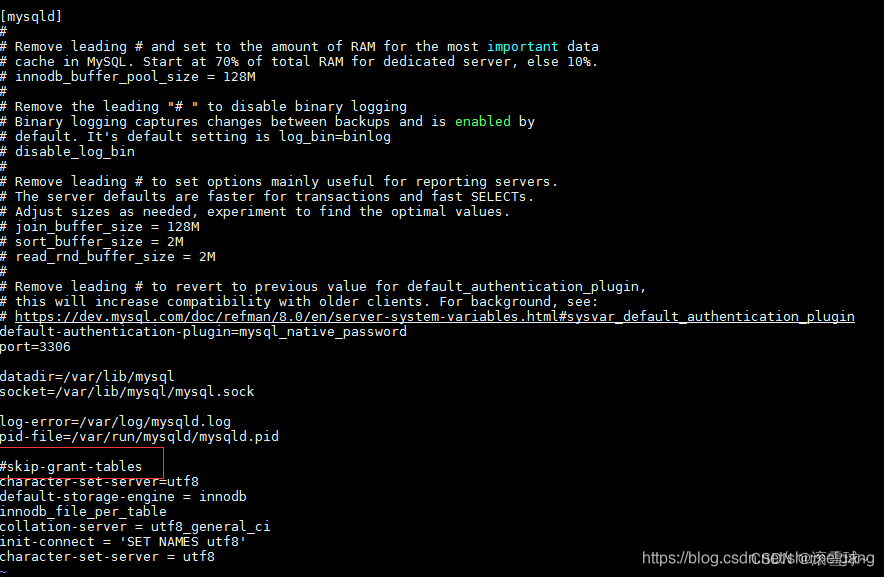
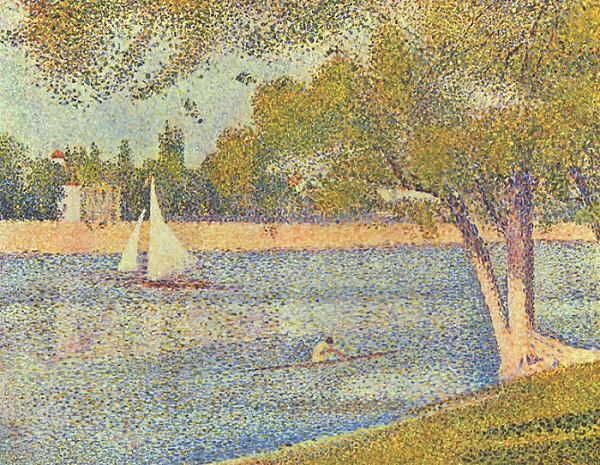3D 重建是从二维 (2D) 图像创建对象或场景的 3D 虚拟表示的任务,可用于模拟、可视化或本地化等多种目的。 它广泛应用于计算机视觉、机器人和虚拟现实(VR)等多个领域。 在基本设置中,3D 重建方法输入一对图像 I1 和 I2,并输出两个图像的深度图 D1 和 D2,以及它们之间的相对姿态 P,如下图 1 所示。

图 1:以 4 个图像作为输入的 3D 重建,以输入图像的姿势作为输出的重建 3D 场景。
如果两个图像的相机参数(内在参数)已知,则当前最先进的多视图立体重建 (MVS) 方法(例如 DeMoN [1] 和 DeepV2D [2])可以完成此任务,如视频 1 所示。 ,不仅需要提供内在函数,而且做出良好估计的过程相当繁琐,并且经常容易出错。
视频 1:一种 3D 重建方法,以一对图像 I1 和 I2 作为输入,以深度图 D1 和 D2 作为输出,加上它们之间的相对姿态 P。
如果相机参数未知或估计不当,则 3D 重建会失败,如视频 2 所示。

视频 2:如果相机内在参数未知或估计不当,现有最先进的方法将无法重建 3D 场景。
DUSt3R方法更简单的主要优点是,通过直接对图像内容进行操作,它可以估计图像深度D1、D2和姿态P,并在不知道相机参数的情况下生成完整的3D重建。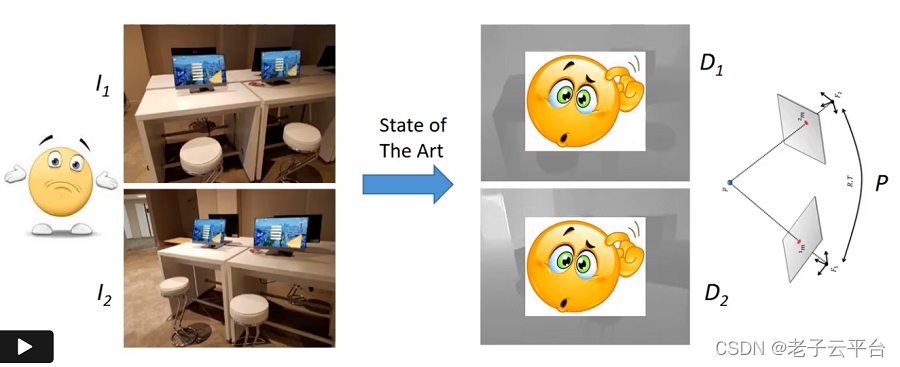
视频 3:说明 DUSt3R 在不了解相机参数的情况下如何工作,这与现有的最先进方法相反
1、DUSt3R 的工作原理
DUSt3R 不受约束,因为它解决了在没有相机参数或视点姿势信息的情况下从图像进行 3D 重建的挑战。 该系统的工作原理是将成对重建制定为点图回归,这使其与标准投影相机模型有很大不同。 该网络有效地从图像对中解码出具有丰富几何细节的点图,从而简化了提取详细场景几何图形的过程。
网络架构基于标准 Transformer 编码器和解码器,这意味着我们可以利用现有强大的预训练模型。 我们的公式直接提供场景的 3D 模型以及深度信息,但我们还可以无缝恢复像素匹配以及相对和绝对相机姿势。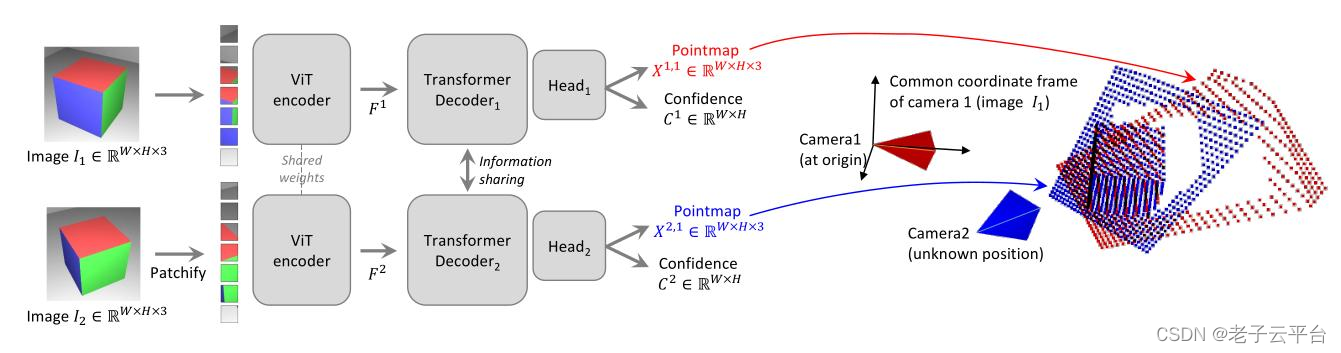
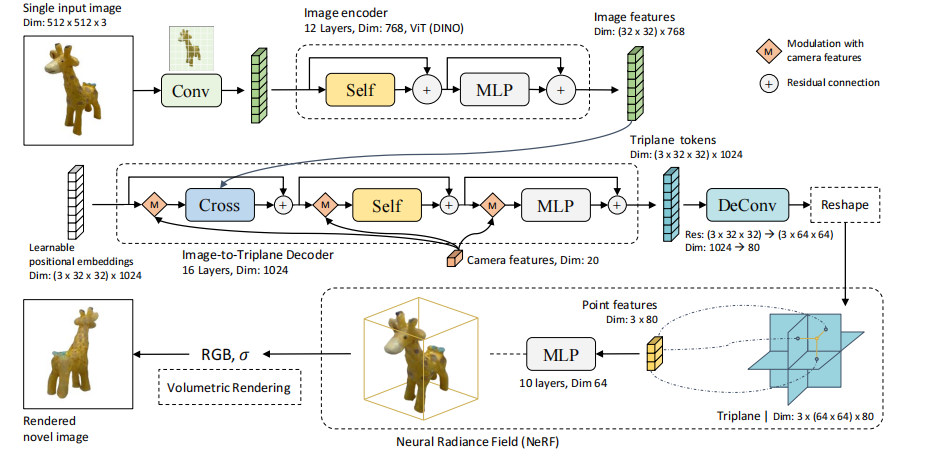
图 2:DUSt3R 架构显示了如何首先使用共享 ViT 编码器以连体方式对场景的两个视图(I1、I2)进行编码。 然后将生成的 token 表示 F1 和 F2 传递给两个 Transformer 解码器,它们通过交叉注意力不断交换信息。 最后,两个回归头输出两个相应的点图和相关的置信度图。 重要的是,这两个点图在第一图像 I1 的相同坐标系中表示。 使用简单的回归损失来训练网络。
2、从两个相反的图像重建
下面是从物体几乎相反的视点进行 3D 重建的几个示例。 对于每种情况(长凳、摩托车和烤面包机),我们都会显示两个输入图像和动画可视化视频。 即使图像之间几乎没有重叠的视觉内容:

DUSt3R 也能轻松处理剧烈的视点变化,例如摩托车:


视频 4:左侧是来自几乎相反视点的物体的 2 个输入图像,右侧是 DUSt3R 生成的 3D 可视化输出。
3、从一张图像重建
DUSt3R 甚至能够从单个图像重建 3D 场景,如下图 3 所示:

图 3:使用 DUST3R 从单个图像进行 3D 重建。 这张图片是一幅 17 世纪荷兰画作“圣杰罗姆在他的书房中,小亨德里克·范·斯滕韦克在橡木上的油画,1630 年”(维基共享资源)。
4、多视角全局优化
在提供多个视图的情况下,DUSt3R 提出了一种简单而有效的全局优化策略,该策略在公共参考系中表达所有成对点图:
视频 5:全局优化过程的动画,在公共参考系中表达所有成对点图。
5、将多个任务集成到单个管道中
DUSt3R 最重要的功能是能够将传统上单独处理的各种 3D 视觉任务统一到一个简化的管道中。 DUSt3R 架构利用预训练模型和完全数据驱动的方法来学习强大的几何和形状先验。 此过程会产生场景的直接 3D 模型,这些模型也适用于深度和姿态估计、视觉定位和多视图 3D 重建等任务。
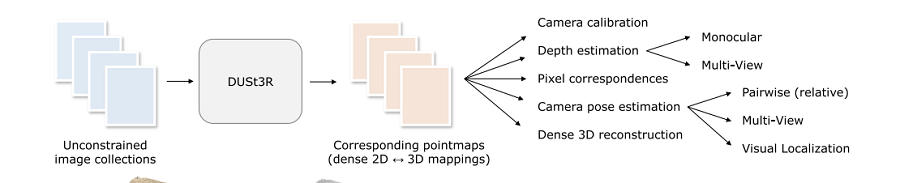
图 4:DUSt3R 方法输出 3D 模型,这些模型适用于单个管道中的许多不同任务,到目前为止,这些任务都是单独处理的。
6、评价结果
DTU、Tanks and Temples 和 ETH3D 等数据集的实验结果表明,DUSt3R 在相机参数未知的情况下也能工作。 该网络可以处理单眼重建并在公共参考系中对齐多个图像对。 评估将 DUSt3R 定位为设定新标准,在包括多视图/单目深度估计和相机姿态估计在内的一系列任务中实现最先进的结果。 下面的表 1 将 DUSt3R 与 CO3Dv2 和 RealEst10K 数据集上的多视图姿态回归任务中最先进的方法进行了比较(详细信息请参阅论文 [3])。
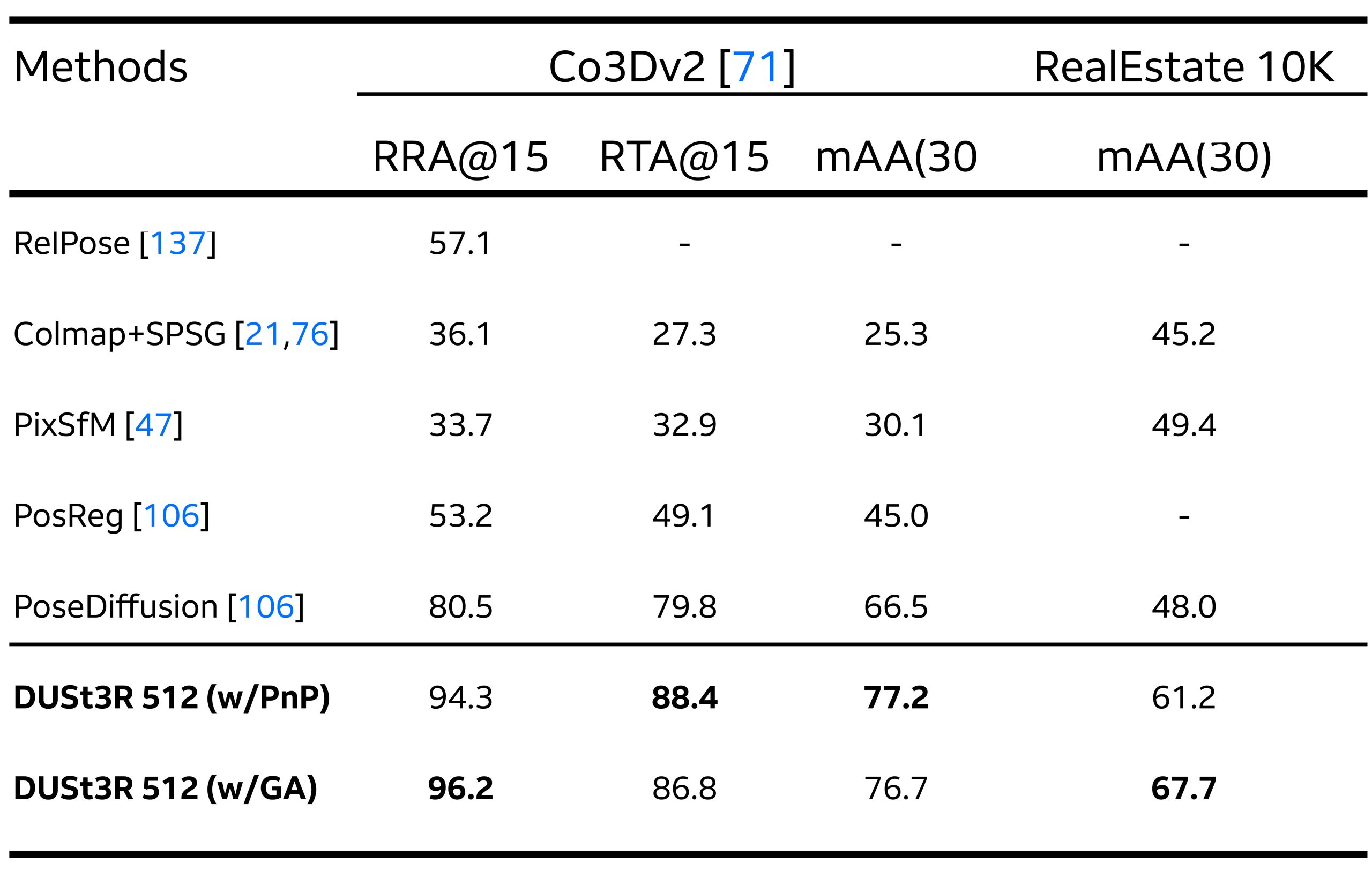
表 1:该表比较了从 PnP-RANSAC (w/PnP) 或全局对齐 (GA) 获得的 DUSt3R 姿态估计结果与基于学习的 RelPose、Colmap+SPSG、基于结构的 PixSFM、PoseReg 和 PoseDiffusion。
7、结束语
DUSt3R 代表了 3D 几何视觉的重大进步,比传统方法有了显着的简化。 结果强调了其在处理各种 3D 视觉挑战方面的潜力和多功能性,而无需进行详尽而细致的估计和校准相机参数的步骤,这代表着 3D 重建领域的未来发展向前迈出了重要一步。